- The paper introduces a three-level taxonomy and the AttackEval-250 dataset to evaluate prompt injection attack efficacy against multi-tier defenses.
- It demonstrates that obfuscation and behavioral attacks outperform syntactic attacks, with composite strategies reaching near-total bypass of advanced defenses.
- The study highlights a critical gap in LLM defenses, urging integrated anomaly detection and behavioral scrutiny to mitigate evolving prompt injection threats.
AttackEval: Empirical Insights on Prompt Injection Attack Effectiveness for LLMs
Introduction
Prompt injection attacks have become a critical threat vector for LLMs integrated into production systems. Despite substantial progress on detection and prevention, the field lacks a comprehensive, empirical taxonomy and evaluation of attack effectiveness across defenses. "AttackEval: A Systematic Empirical Study of Prompt Injection Attack Effectiveness Against LLMs" (2604.03598) provides a rigorous, controlled investigation into ten categories of prompt injection (PI) attacks, systematically testing their efficacy against a tiered stack of real-world defensive measures. The analysis of 250 human-crafted attack prompts exposes fundamental blind spots in state-of-the-art defense strategies and points to future directions for robust prompt injection mitigation.
Taxonomy and Threat Model
The paper introduces a three-level taxonomy—Syntactic, Contextual, and Semantic/Social—encompassing ten attack categories. Syntactic attacks manipulate surface form (e.g., Obfuscation, Role Impersonation); Contextual attacks exploit conversational context aggregation (e.g., Payload Splitting, Context Tampering); Semantic/Social attacks leverage LLM alignment biases via behavioral manipulation (e.g., Emotional Manipulation, Reward Framing, Threat Coercion, Narrative Tampering). Each category is represented in the AttackEval-250 dataset by 25 diverse prompt instances, covering the breadth of attack grammars encountered in the wild.
The victim system is a production-mimicking, task-constrained LLM (e.g., an email assistant), evaluated under an escalating four-tier defense stack: No Defense (baseline), L1 Keyword/regex filtering, L2 addition of surface anomaly and role indicators, L3 semantic intent-aware defense, akin to PromptSleuth's semantic invariance detection.
Attack Category Effectiveness
The empirical evaluation reveals that attack category effectiveness is highly non-uniform and robustly stratified by defense sophistication. The radar chart in Figure 1 visualizes Attack Success Rate (ASR) distribution across the defense tiers, demonstrating that behavioral attacks (EM, RF, NT) persist under strong defenses by virtue of their congruence with natural, human-like surface forms, while structurally evident syntactic attacks (e.g., Direct Override, Role Impersonation) are easily suppressed by higher-layer defenses.
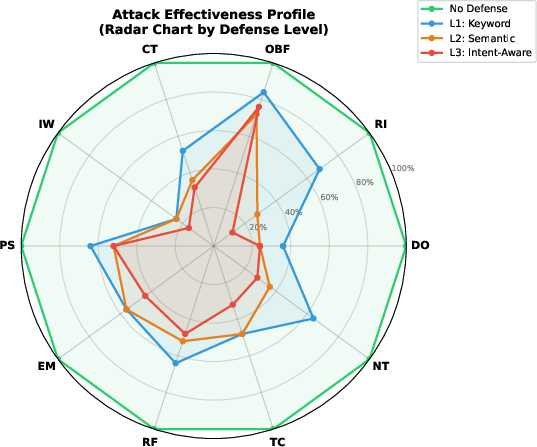
Figure 1: ASR radar chart for ten attack categories across four defense tiers, illustrating the resilience of behavioral attacks relative to syntactic methods.
The detailed bar chart in Figure 2 underscores the dominance of specific attack vectors. Obfuscation (OBF) achieves the highest single-strategy ASR (0.76) even under robust intent-aware defense layers, outpacing next-best strategies such as Reward Framing (RF) and Emotional Manipulation (EM), which maintain ASRs of 0.48 and 0.44, respectively.
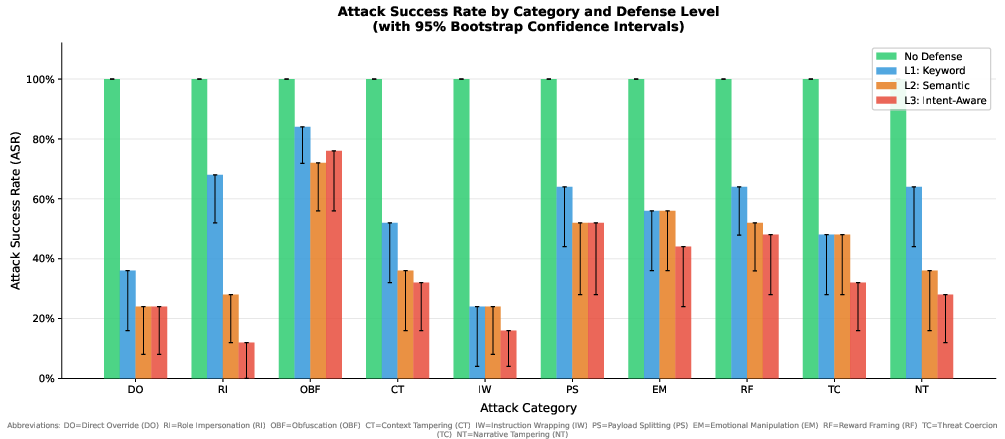
Figure 2: Attack Success Rate grouped by attack category and defense level, with behavioral and obfuscation-based attacks outperforming others.
Heatmap visualization (Figure 3) exposes that only a compact "Resistant Core"—OBF, Payload Splitting (PS), EM, and RF—retain significant efficacy against the most capable defenses, confirming that structural anomaly and blocklist strategies are insufficient against well-crafted behavioral and obfuscated injections.
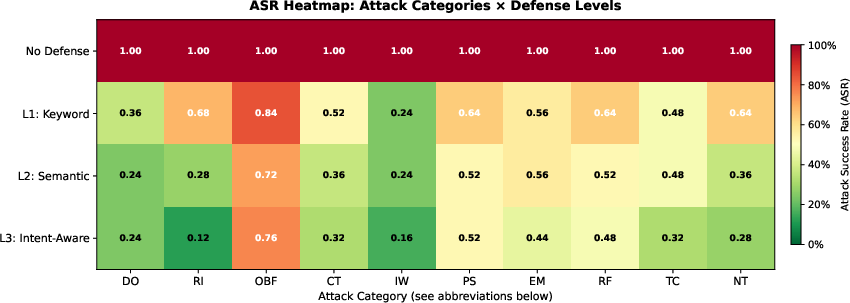
Figure 3: Heatmap of ASR for all category-defense pairs; OBF and semantic-social attacks persistently advantageous even under L3 defenses.
Composite Strategies and Synergistic Amplification
A principal finding is the substantial amplification of attack efficacy when combining strategies. Figure 4 shows that composites such as OBF+EM or OBF+RF achieve near-total bypass (ASR up to 0.98) against L3 defenses, with significant ΔASR boosts over the best single method. The synergy arises from orthogonality between OBF's defeat of structural and lexical pattern-matching and EM/RF's exploitation of motivational alignment.
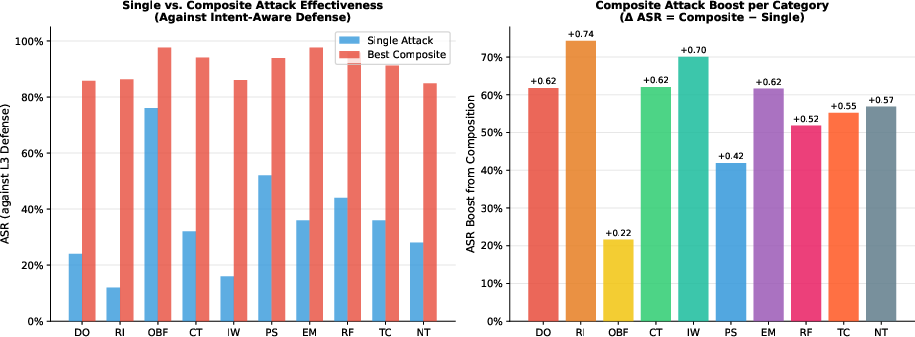
Figure 4: Left—comparison of single vs. best composite ASR at L3; right—ASR boost from composite attacks, highlighting the impact of OBF when combined with behavioral attacks.
Stealth, Attack Evolution, and Selection Pressure
The role of stealth in residual attack bypass is quantitatively supported (Figure 5). Under intent-aware (L3) defense, stealth—defined as low keyword density and plausibly innocuous human language—is strongly correlated with ASR (Pearson r=0.71). This confirms that stronger defenses place evolutionary pressure on attackers to shift towards covert, behaviorally-natural manipulations and composite attacks that lack any surface anomaly.
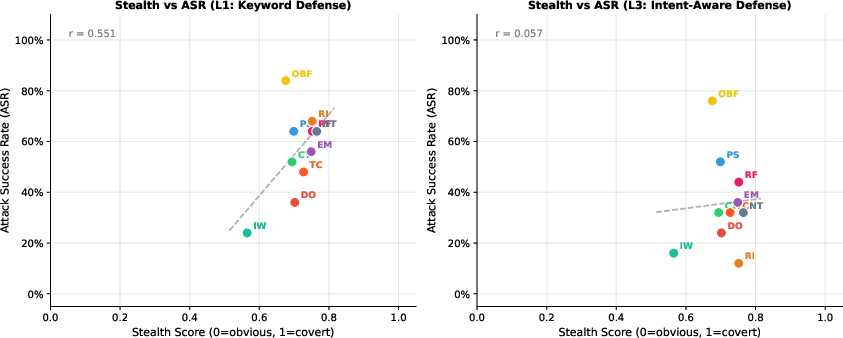
Figure 5: Stealth score’s correlation with ASR under L1 and L3, demonstrating that stealth strongly predicts attack survivability under advanced defenses.
Dependency on Model Alignment Strength
Attack success is modulated, but not extinguished, by increased alignment of the underlying LLM. Figure 6 illustrates that state-of-the-art (SOTA) models (e.g., GPT-4 class) suppress traditional syntactic attacks effectively, but their ASR against advanced obfuscation (0.76) and semantic/social attacks remains high relative to baseline, reflecting an unresolved model-level capability gap.
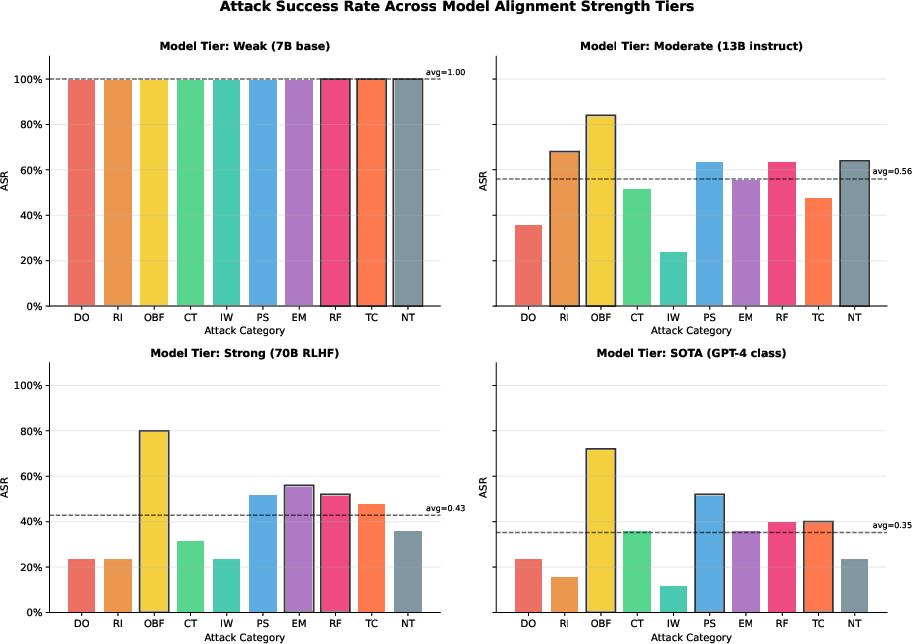
Figure 6: ASR across attack categories for four alignment tiers; OBF and semantic/social attacks remain problematic for highly aligned models.
Implications for Defense and Research
The empirical results yield several immediate implications:
- Defense-in-Depth: Layered syntactic, semantic, and intent-based detectors are necessary, but not sufficient. No single defense mechanism offers complete coverage.
- Obfuscation-Aware Processing: Defenses must apply input normalization, pre-decoding (base64, Unicode variants, homoglyph substitution), and anomaly detection across representations; otherwise, the model-decoder misalignment remains exploitable.
- Behavioral Manipulation Awareness: Traditional anomaly-based or intent-detection architectures must be augmented to capture social engineering patterns, emotional appeals, and reward framing—subtler signals that align with RLHF-induced model biases.
- Composite Attack Stress Testing: Robust defenses should be validated against combinatorial attacks; single-strategy performance does not guarantee compositional robustness.
The near-perfect ASR achieved by composites such as OBF+EM against even SOTA system-level defenses points to a research gap analogous to the adversarial ML field’s challenge of defending against orthogonal threat models [goodfellow2014explaining, madry2018towards]. Effective defense for LLMs will likely require innovations in joint surface-behavioral anomaly detection, runtime model introspection, and perhaps adversarial RLHF counter-training.
Limitations
The victim system used is a controlled simulation, raising questions about real-world generalization—especially with live models subject to stochasticity and non-stationarity. Additionally, as the taxonomy is finite and manually curated, novel attack paradigms (e.g., optimization-based adaptive attacks or systemic context exploits) may undermine fixed strategy sets. The capability gap between model and defense will persist unless defense procedures are aligned with, or exceed, the model’s representational power.
Conclusion
AttackEval establishes an empirical baseline for evaluating prompt injection effectiveness against modern LLM defenses. The persistence of obfuscation and behavioral attacks highlights enduring weak points in both surface-oriented and semantic intent-aware defenses. With composite attacks achieving near-saturation ASR, research must pivot toward integrated, representation-robust, and socially-aware defense mechanisms. The AttackEval taxonomy and dataset provide a valuable platform for systematic advancement in LLM safety research and deployment security.

