- The paper introduces a taxonomy categorizing 2D-to-3D adaptation into data-, architecture-, and hybrid-centric methods to bridge the dimensionality gap.
- It analyzes trade-offs, such as geometric fidelity versus computational efficiency, across applications like autonomous driving and medical imaging.
- The study highlights open challenges in developing scalable 3D foundation models and integrating self-supervised learning for enhanced 3D representation.
Bridging the Dimensionality Gap: Taxonomy and Survey of 2D Vision Model Adaptation for 3D Analysis
Introduction and Motivation
The adaptation of 2D vision architectures, notably CNNs and Vision Transformers (ViTs), to 3D spatial analysis has become a principal challenge in computer vision. The underlying issue is the structural divergence between regular 2D image grids and the irregular, sparse nature of 3D data formats such as point clouds and meshes. The surveyed paper establishes the "dimensionality gap" as the primary obstacle, motivating a systematic taxonomy of adaptation strategies for leveraging the robust visual priors from 2D models in the context of 3D analysis.
Taxonomy of Adaptation Strategies
A central contribution of the paper is the introduction of a taxonomy categorizing 2D-to-3D adaptation methods into three families: Data-centric, Architecture-centric, and Hybrid. This classification provides a unified analytical framework for organizing the literature and dissecting core trade-offs.
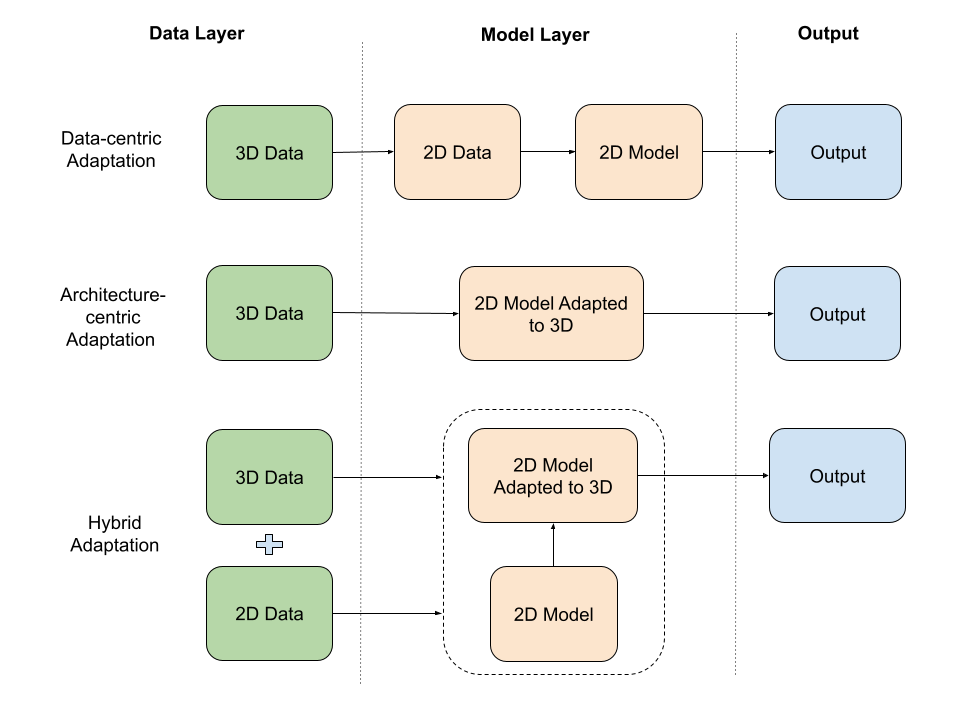
Figure 1: Illustration of the taxonomy of 2D-to-3D adaptation strategies, depicting the hierarchical organization of adaptation paradigms.
Data-Centric Methods
Data-centric adaptation operates by transforming 3D inputs into 2D or 2D-like representations, facilitating the direct reuse of mature 2D models and pre-trained weights. Methods in this category include:
- Multi-View Rendering: Render multiple 2D projections of 3D objects; aggregate features via pooling or graph-based strategies. Successors to MVCNN introduced graph-based aggregation (View-GCN) and ViT backbones (MVT).
- Voxelization and Projection: Discretize 3D data into voxel grids or project point clouds onto BEV maps for CNN processing. Sparse convolutions (SECOND) and pillar encoding (PointPillars) address cubic scaling inefficiency.
- Geometric Unfolding and Spherical Projection: Reproject 3D geometry onto 2D domains preserving topology (geodesic patches or sensor-centric spherical projections), optimizing for semantic segmentation on structured surfaces or sensor data.
Architecture-Centric Methods
These methods develop intrinsically 3D architectures, circumventing the need for grid regularity:
- 3D Convolutions on Voxel Grids: Extend CNNs to operate on volumetric data; sparse convolutions alleviate computational bottlenecks and enable high-resolution processing.
- Point-Based Networks: Directly learn from unordered point sets. PointNet and successors introduce permutation invariance and hierarchical local feature extraction. KPConv and DGCNN incorporate learnable kernels and dynamic graphs for enhanced geometric reasoning.
- Graph-Based Networks: Leverage explicit or constructed graph topologies from meshes and point clouds; message passing and attention mechanisms (MeshCNN, GAT, DGCNN) support expressive feature aggregation.
- 3D Transformers: Adapt self-attention to capture context within point neighborhoods; stratified attention and masked modeling techniques (Point-BERT, Stratified Transformer) provide scalability and data efficiency.
Hybrid Methods
Hybrid approaches combine the strengths of data-centric and architecture-centric paradigms:
- 2D-Guided 3D Feature Learning: Fuse pre-trained 2D features into 3D point processing pipelines; semantic enrichment via image-derived features improves downstream tasks.
- Cross-Modal Knowledge Distillation: Transfer knowledge from 2D foundation models (DINOv2, CLIP) to 3D networks; distillation enables semantic transfer with limited 3D data.
- Multi-Modal Fusion Architectures: Design explicit fusion modules integrating 2D and 3D feature streams at multiple network depths; cross-attention-based fusion enables richer co-dependent representations.
Critical Analysis of Trade-offs
The taxonomy enables a focused analysis of core trade-offs across the methods:
- Geometric Fidelity vs. Computational Efficiency: Architecture-centric models yield superior geometric fidelity but incur significant resource demands (e.g., O(N3) scaling for dense 3D convolutions, quadratic attention complexity). Data-centric approaches offer rapid inference but at the cost of information loss via projection or rendering.
- Inductive Bias vs. Pre-Training Leverage: Intrinsic 3D networks embed strong geometric priors at the expense of lacking large-scale semantic pre-training. Data-centric and hybrid methods trade geometric purity for semantic richness by leveraging the extensive priors distilled from large 2D datasets.
- Application Suitability: The appropriateness of each method is task-dependent:
- Shape analysis and mesh reasoning: architecture-centric models dominate.
- Autonomous driving: hybrid and BEV-based methods are optimal for multi-modal sensor fusion and real-time inference.
- Medical volumetric imaging: 3D convolutions are canonical.
- Isolated object classification: multi-view data-centric models are sufficient.
Open Challenges and Future Directions
The paper delineates unresolved challenges and trajectories for future research:
- 3D Foundation Models: The absence of massive, standardized datasets and backbone architectures hinders the transferability and generalization possessed by 2D counterparts.
- Self-Supervised Learning (SSL): Advancements in SSL, including masked region modeling and cross-modal contrastive objectives, are critical for label-efficient 3D pre-training.
- Deeper Multi-Modal Fusion: Existing fusion strategies are shallow or late-stage; future architectures should integrate cross-modal features at multiple granularity levels and modalities, including language.
- Scalability to Dynamic Scenes: The current focus on static data limits applicability; efficient attention and convolution mechanisms are needed for dynamic, city-scale, or temporally-evolving environments.
- Integration of Implicit Representations: Alignment of NeRFs and SDFs for scene synthesis with recognition-driven architectures remains an open technical frontier.
Conclusion
The surveyed work synthesizes a comprehensive taxonomy and survey of 2D-to-3D adaptation strategies, systematically dissecting the dimensionality gap in vision model transfer. It exposes the persistent tension between geometric fidelity, computational efficiency, and semantic pre-training in 3D analysis, and provides actionable insights for the engineering and deployment of future 3D vision systems. The intellectual framework outlined in the paper is foundational for future research in 3D foundation models, SSL for geometric data, and deep multi-modal integration architectures (2604.03334).

