- The paper demonstrates that fine-grained, utterance-level domain adaptation significantly improves labeling accuracy (Cohen’s κ up to 0.743) in educational dialogue.
- It introduces a retrieval-augmented pipeline that assembles few-shot demonstrations using dense retrieval for enhanced pedagogical annotation.
- The method reduces complexity by isolating domain adaptation to retrieval, enabling scalable and cost-effective annotation across tutoring datasets.
Domain-Adapted Retrieval for In-Context Annotation of Pedagogical Dialogue Acts
Introduction
Automated annotation of pedagogical dialogue acts is critical for scaling educational research and intelligent tutoring systems, yet existing LLM-based approaches suffer from insufficient domain grounding, impaired further by the context-dependent and abstract nature of educational dialogue moves. This work introduces a retrieval-augmented pipeline that prioritizes domain-adapted retrieval, rather than model fine-tuning, to achieve high-fidelity annotation of pedagogical acts in real-world tutoring scenarios. The method is evaluated across the TalkMoves (classroom) and Eedi (tutoring chat) datasets, leveraging GPT-5.2, Claude Sonnet 4.6, and Qwen3-32b as frozen, general-purpose LLMs.
Retrieval-Augmented Annotation Pipeline
The core pipeline comprises three stages: (i) fine-tuning a sentence embedding model on a pedagogical dialog corpus to yield domain-adapted representations; (ii) constructing a dense retrieval index at the utterance level that maintains label-specific signal; and (iii) assembling few-shot demonstrations for in-context classification by retrieving similar labeled utterances, which, together with the annotation codebook, are presented to the LLM for final annotation.
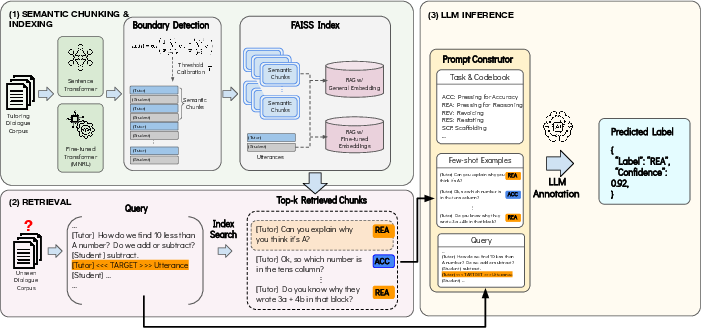
Figure 1: Overview of the proposed RAG-based annotation pipeline.
The domain adaptation is localized entirely to the retrieval component. Chunking is adaptive and semantic, partitioning dialogues at boundaries of topic/pedagogical function, further improving retrieval focus. Utterance-level indexing proves crucial, as averaged chunk-level representations dilute the labeling signal vital for accurate annotation.
Experimental Results and Analysis
On both TalkMoves and Eedi, domain-adapted retrieval using utterance-level indexing significantly outperforms both codebook-only prompting and general-purpose retrieval across all tested LLM backbones. The Cohen's κ reaches 0.526–0.580 (TalkMoves) and 0.659–0.743 (Eedi) under the best configuration, compared to 0.275–0.413 and 0.160–0.410 with the baseline. Notably, retrieval-augmented Qwen3-32b achieves performance on par with or exceeding that of baseline GPT-5.2, substantiating the portability claim of the pipeline.
Matched label rates for retrieved demonstrations jump from 39.7% to 62.0% on TalkMoves, and from 52.9% to 73.1% on Eedi with domain adaptation, explaining the observed performance improvements.
Ablation results show that the performance gain arises almost exclusively from fine-grained (utterance-level) indexing, not from improved embedding quality per se, and this is robust across LLM architectures. Per-label analysis indicates the largest gains for rare and context-dependent categories, with retrieval correcting strong systematic label biases (such as the over-prediction of "Pressing for Reasoning" on Eedi in zero-shot settings).
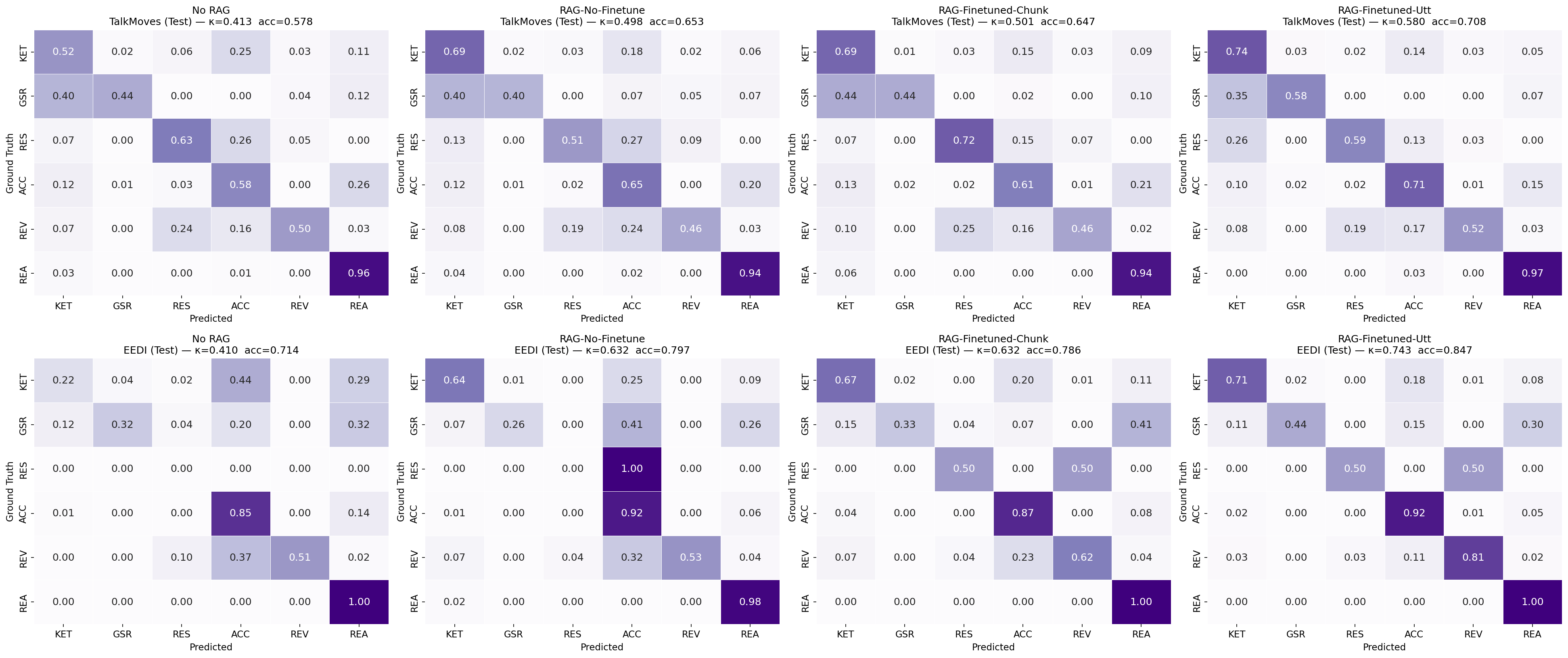
Figure 2: Confusion matrices reveal that domain-adapted retrieval tightens label assignment along the diagonal and ameliorates class-specific bias.
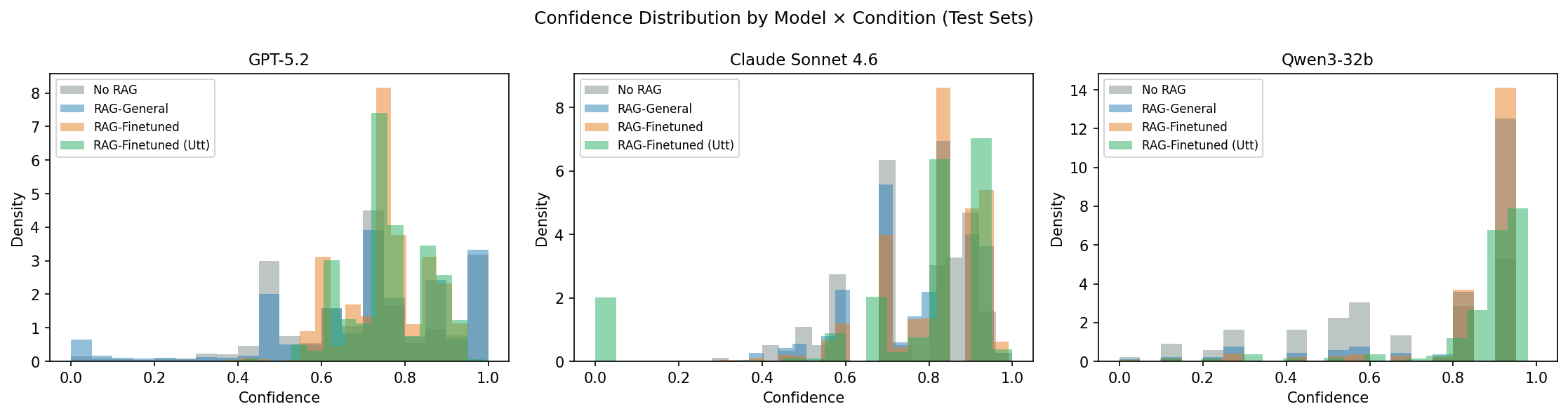
Figure 3: Confidence is strongly right-shifted under domain-adapted retrieval, concentrating high-confidence predictions and promoting reliable triage.
Retrieval Depth and Demonstration Selection
Increasing the retrieval depth k further enhances annotation agreement, with domain-adapted retrieval benefiting more than general-purpose retrieval at greater k values across all LLMs, emphasizing the value of high-precision, label-relevant example selection in ICL settings.
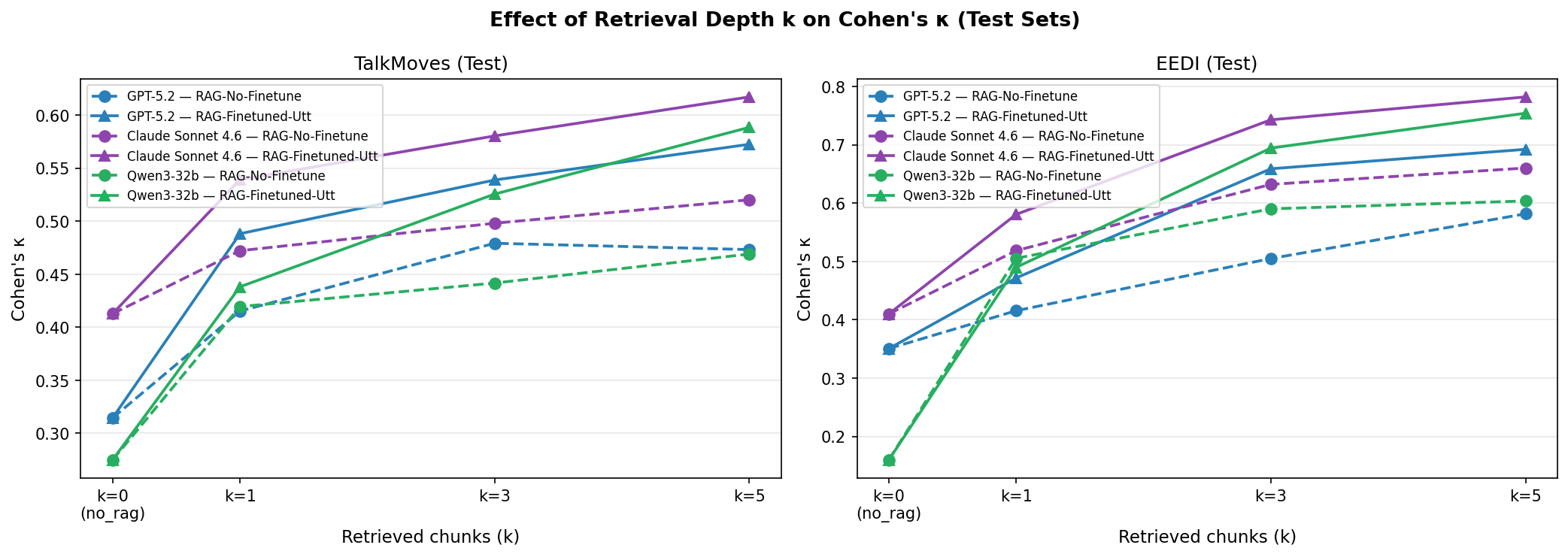
Figure 4: Cohen's κ as a function of retrieval depth shows consistent superiority of domain-adapted retrieval across backbones and tasks.
Implications and Future Directions
Practical Impact
By keeping adaptation orthogonal to the generative model, this retrieval-focused pipeline allows for seamless upgrades to future LLMs, reduces infrastructure and data curation complexity, and lowers costs by forgoing expensive model fine-tuning. The strong performance and reliability of high-confidence predictions offer a pathway to human-in-the-loop annotation workflows suitable for high-stakes educational settings. The demonstrated improvements for rare, context-dependent categories directly support better reward modeling and instructional analytics.
Theoretical Significance
The pronounced impact of utterance-level indexing validates the hypothesis that retrieval granularity, not merely embedding model sophistication, is paramount for complex, nuanced labeling tasks. This finding generalizes recent work documenting the centrality of demonstration selection precision in ICL for classification and may prompt revision of RAG architectures in dialog and discourse-level applications.
Open Problems and Paths Forward
Key open questions include generalization across taxonomies, annotation schemes, and subject domains beyond mathematics; the integration of active or continual learning for dynamic retriever improvement; and the development of training objectives enforcing explicit inter-label separation in the embedding space. Multi-turn annotation and modeling of higher-level pedagogical strategies could further expand the scope and effectiveness of automated annotation systems in education.
Conclusion
This work conclusively demonstrates that domain-adapted, utterance-level retrieval is the primary lever for achieving expert-level automated annotation of pedagogical dialogue acts when using frozen LLMs. Adaptation localized to the retriever delivers substantial gains over both prompt-only and general-purpose retrieval strategies, yielding strong empirical performance across tasks, categories, and LLM backbones. The approach offers a modular, scalable, and highly effective paradigm for advancing educational data annotation, paving the way for richer and more reliable analytics in AI-powered learning environments.