- The paper presents a hybrid approach combining static analysis with LLMs to improve algorithm recognition accuracy and runtime performance.
- The methodology rigorously benchmarks multiple prompting strategies on the BigCloneEval dataset, showing up to 4–8% F1-score gains with two-shot in-context learning.
- Lightweight static filters reduce LLM invocations by up to 97%, significantly lowering processing times while enhancing precision.
Introduction and Motivation
Automating algorithm recognition within source code remains an active research problem with significant implications for program comprehension, maintenance, and quality assurance. While static code analysis and heuristic pattern matching have historically dominated this space, the recent proliferation of LLMs for code-related tasks introduces new opportunities for semantic reasoning and flexible classification. This paper provides the first rigorous empirical evaluation of hybridizing static analysis—through both syntactic and structural filter patterns—with LLM-based algorithm recognition, including a systematic comparison of prompting strategies and an investigation into the influence of identifier names on LLM performance.
Experimental Setting
The empirical study employs the BigCloneEval (BCEval) dataset, focusing on a subset of seven diverse algorithms (e.g., Bubble Sort, Binary Search, GCD) sourced from real-world Java code bases. The study benchmarks three state-of-the-art LLMs—GPT-4o mini, Llama 3.1 Instruct 70B, and Mixtral 8x22B Instruct—with a rigorous hyperparameter and prompting protocol. Macro-averaged F1-score is the primary metric to counter skewed positive/negative class imbalance across functionalities. The evaluation is repeated in multiple controlled settings: varying prompt styles (binary, score-based, in-context learning, chain-of-thought), presence/absence of static filtering, and with/without systematic identifier obfuscation.
A comprehensive benchmarking of prompting techniques revealed that both simple binary (Yes/No) and fine-grained score prompting yield comparable F1-scores, but score-based prompts enable customizable recall/precision trade-off via adjustable thresholds, as depicted in the following experimental results.
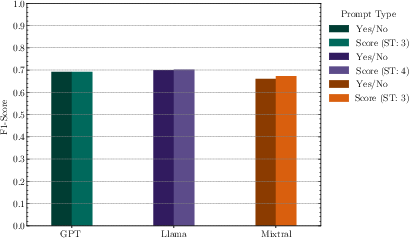
Figure 1: Average F1-score for Yes/No and Score prompting.
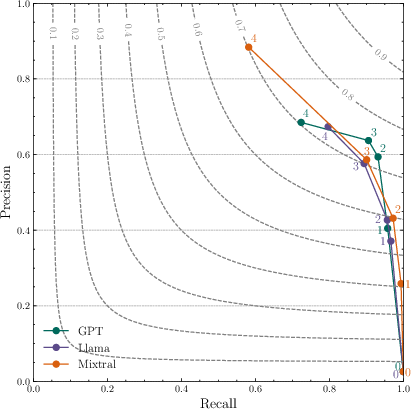
Figure 2: Precision and Recall for different score thresholds.
Critically, in-context learning (ICL) with two positive examples consistently provides a strong performance boost—raising F1-score by 4–8 percentage points with only moderate runtime cost. Increasing the number of positive/negative demonstrations beyond two delivers diminishing returns and linearly increases inference latency, making (2P+0N) a practical sweet spot.
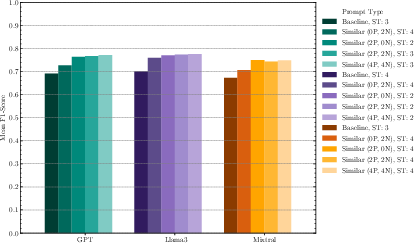
Figure 3: Average F1-score of in-context learning with varying numbers of examples vs the baseline.
Chain-of-Thought (CoT) prompting, while influential in other reasoning domains, fails to surpass ICL in both accuracy and efficiency; performance of CoT is limited, presumably due to model size or the domain-specific reasoning required in algorithm detection.
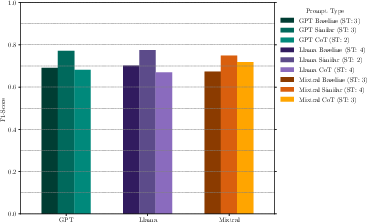
Figure 4: Average F1-scores for the Baseline, (4P+4N) as the best performing ICL combination and CoT.
Hybridization with Static Analysis
The integration of lightweight filter patterns—either keyword-based or AST-derived structural descriptors—prior to the LLM classification phase reduces the number of LLM invocations by 72–97%, depending on filter specificity. This delivers dramatic reductions in end-to-end runtime (e.g., a 19.3-hour process compresses to 33 minutes with Mixtral) and, crucially, often amplifies precision and F1-score, surpassing both isolated LLM and filter-based approaches. The improvement reflects the synergy between high-recall static exclusions and LLM’s downstream semantic reasoning.
- Keyword-based “Recall Focused” patterns achieve ~72% method exclusion with minimal true positive loss.
- Structural “Prominent Feature” patterns (via a domain-specific AST query language) achieve >97% exclusion while maintaining or improving F1-scores.
- Manual effort increases with pattern complexity; the most comprehensive patterns (cf. Neumüller et al. [Neumueller2024]) further tailor precision and recall, but with marginal method reduction gains over lighter heuristics.
The impact of filter pattern strictness, as well as the induced shift in optimal LLM decision thresholds post-filtering, is empirically quantified.
LLM Reliance on Identifier Names
The ablation via systematic identifier obfuscation reveals only modest F1-score degradation, with a paradoxical increase in precision offsetting reduced recall. This indicates that while LLMs do exploit surface-level name features when available, their semantic generalization capacity enables recognition even with anonymized code. Mixtral and Llama exhibit slightly higher dependence on names than GPT-4o mini, but none collapses under obfuscation.
Practical and Theoretical Implications
Practical: The hybrid methodology enables scalable, high-precision, automated algorithm recognition suitable for continuous integration, automated code review, and pedagogical assessment—avoiding the prohibitive compute cost of naïvely applying LLMs across massive codebases. The flexibility of the filtering strategy allows practitioners to fine-tune recall/precision for diverse downstream use cases.
Theoretical: Results challenge the assumption that LLMs behave solely as pattern-matching engines; the demonstrated resilience to identifier obfuscation suggests an emergent form of semantic abstraction. The failure of CoT to materially aid this task calls for further research into the intersection of prompt-based reasoning dynamics and the code domain, possibly requiring larger models, task-specific tuning, or richer context engineering.
Future Developments: Further research directions include automating both the generation of filter patterns and the mining of robust ICL exemplars, scaling to composite or cross-function algorithm recognition, integrating with IDEs as developer-assistive plugins, and extending the evaluation to polyglot settings and more complex algorithm families.
Conclusion
This paper systematically demonstrates that coupling lightweight static analysis with LLM-based classification results in substantial accuracy and computational efficiency gains for the algorithm recognition task. Two positive-shot ICL outperforms more elaborate prompting, while static pre-filtering magnifies both speed and correctness. LLMs, while not insensitive to lexical cues, maintain robust recognition capability under identifier transformation, highlighting a nontrivial semantic reasoning component. The hybrid pipeline sets a practical baseline for automated code intelligence tools, warranting further development and domain extension.
References
- Neumüller et al., "Combining Static Code Analysis and LLMs Improves Correctness and Performance of Algorithm Recognition" (2604.03048)
- Neumüller et al., "Exploring the Effectiveness of Abstract Syntax Tree Patterns for Algorithm Recognition" [Neumueller2024]
- Wei et al., "Chain-of-thought prompting elicits reasoning in LLMs" [Wei2022]
- Brown et al., "LLMs are few-shot learners" [Brown2020]
- Khajezade et al., "Investigating the Efficacy of LLMs for Code Clone Detection" [Khajezade2024]