- The paper presents GTC, which uses interaction-guided diffusion for user-aware content denoising to overcome the universal relevance assumption.
- It introduces a variational lower bound of total correlation to align visual, textual, and interaction modalities holistically, significantly improving recommendation metrics.
- Evaluation on Amazon datasets shows that combining denoising with total correlation objectives outperforms state-of-the-art methods in multi-modal recommendation.
User-Aware Conditional Generative Total Correlation Learning for Multi-Modal Recommendation
Introduction and Motivation
Multi-modal recommendation (MMR) leverages heterogeneous content—primarily visual and textual item attributes—to supplement sparse user-item interaction data and thereby enrich item representations. The critical challenge in MMR is effective cross-modal alignment: integrating modality-specific features with implicit user preference signals from interactions. Prior art, dominated by disentangled representation learning (DRL), assumes universal preference relevance for item content and separately aligns modalities via pairwise contrastive losses. This paradigm has two significant deficiencies:
(1) Universal Relevance Assumption: Previous DRL methods erroneously model feature relevance as invariant across users, ignoring user-conditional preference structures.
(2) Pairwise Alignment Limitation: They optimize only pairwise contrastive objectives, neglecting the higher-order dependencies inherent in multi-modal interactions.
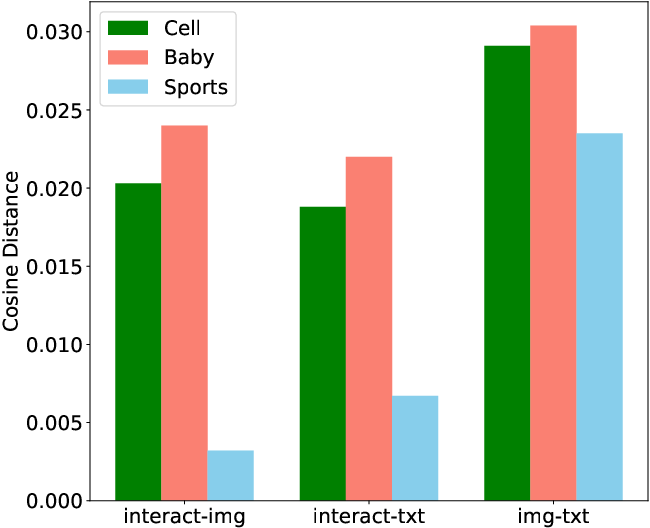
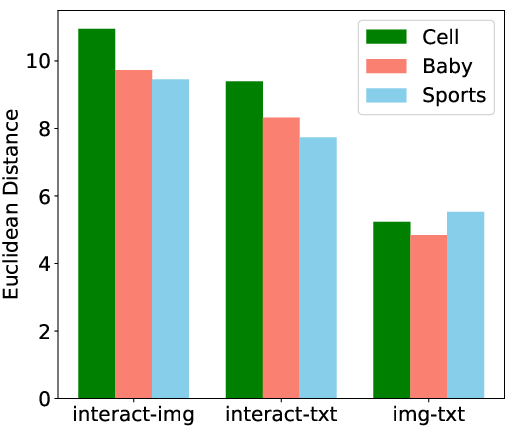
Figure 1: User-item interaction representations are poorly aligned with visual and textual content modalities, as indicated by low cosine similarity and high Euclidean distance; the latter two modalities are substantially more coherent.
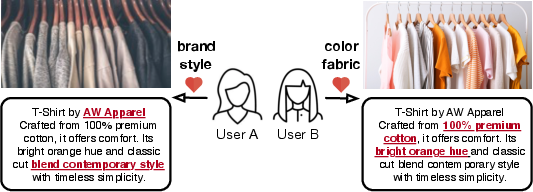
Figure 2: The preference-driving features in item content are user-conditional: "orange" and "cotton" may be critical cues for one user, while "brand" and "style" are salient for another.
Proposed Framework: GTC
To address these core limitations, the paper introduces GTC (Generative Total Correlation), a framework that explicitly models user-aware content feature filtering and holistic, higher-order cross-modal alignment.
User-Aware Content Feature Generation
GTC’s first component leverages a diffusion model conditioned on user interaction embeddings to perform preference-driven content denoising for each user, mitigating the universal relevance assumption and preserving only features correlated with the individual’s observed behavior. Visual and textual item features—pre-encoded via ResNet-50 and sentence-transformers—are refined through interaction-guided diffusion, producing user-conditional denoised representations.
Holistic Cross-Modal Alignment via Total Correlation
Recognizing the incompleteness of pairwise alignment, GTC directly optimizes a variational lower bound of the total correlation (TC) among interaction, visual, and textual modalities. By adopting a multi-modal InfoNCE loss, GTC encourages not only pairwise but also higher-order mutual information, reflecting the full dependency structure of modalities. Symmetrization ensures that all anchor-modal perspectives are covered.
Fused Representation and Recommendation
The denoised, aligned content features are fused with interaction-derived embeddings using similarity-based gating and residual connections. A standard BPR loss is adopted for learning-to-rank, combined with content denoising and total correlation terms.
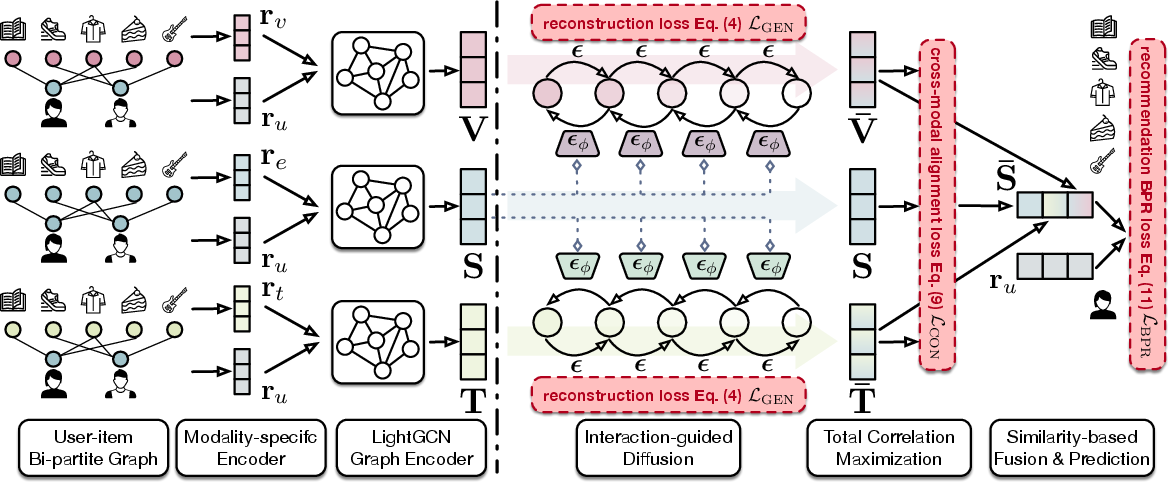
Figure 3: The GTC architecture: multi-modal LightGCN encoding, interaction-guided diffusion, holistic TC alignment, and gating-based fusion prior to recommendation scoring.
Experimental Evaluation
Datasets and Baselines
GTC is evaluated on Amazon Sports, Baby, and Cell datasets, each with differing interaction sparsity. It is benchmarked against state-of-the-art fusion-based and disentanglement-based MMR algorithms.
Quantitative Results
GTC achieves substantial improvements over all baselines, with +28.3% NDCG@5 observed in the Sports dataset—accentuating the cost of neglecting higher-order modal dependencies.
Key empirical findings:
- Simple fusion of modalities is fragile to noise and inconsistency, underperforming methods that apply denoising or alignment.
- Pairwise contrastive objectives, while effective, plateau in performance due to their inability to capture triadic or higher-order dependencies.
- GTC’s combination of user-aware denoising and total correlation-driven alignment consistently delivers superior results.
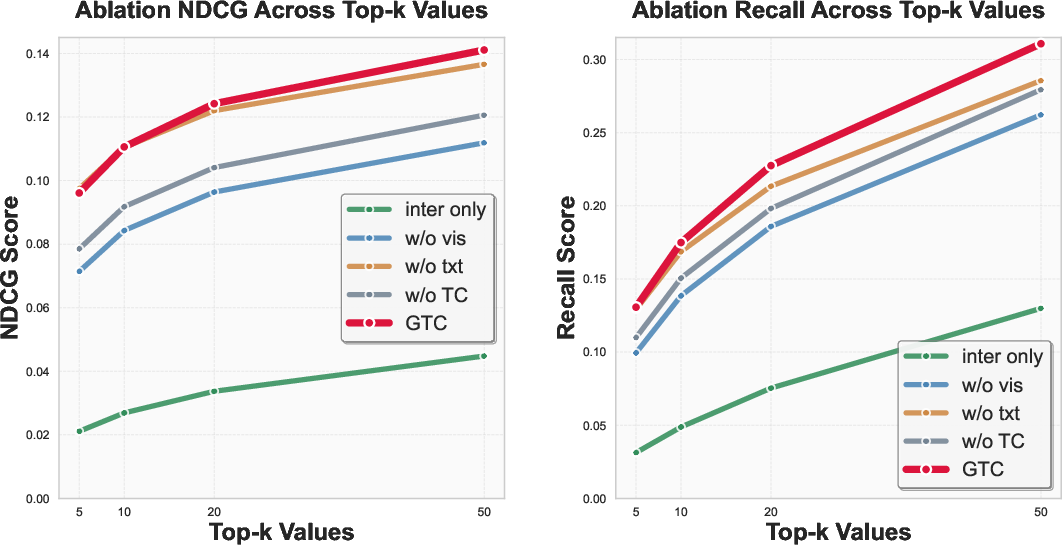
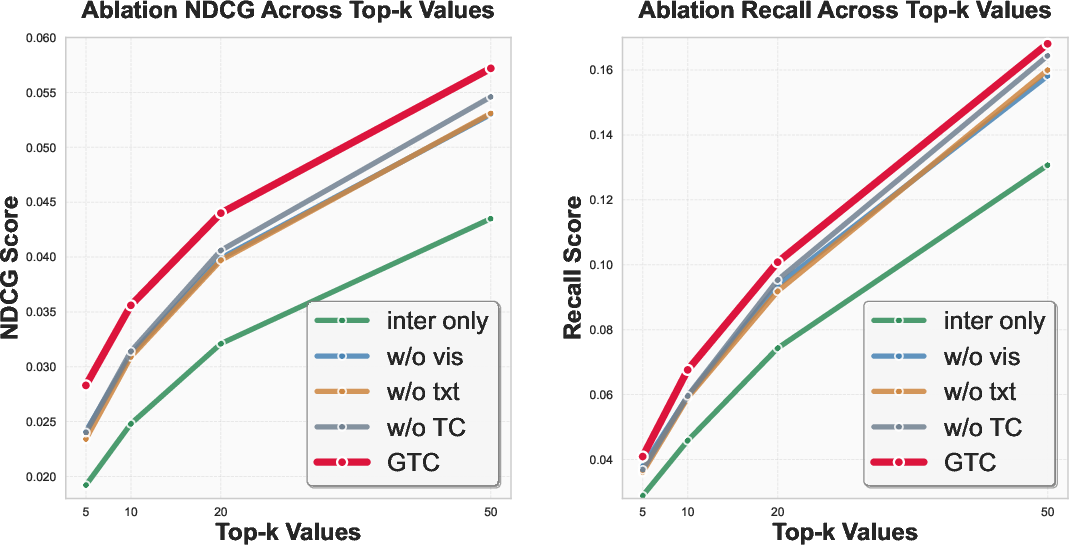
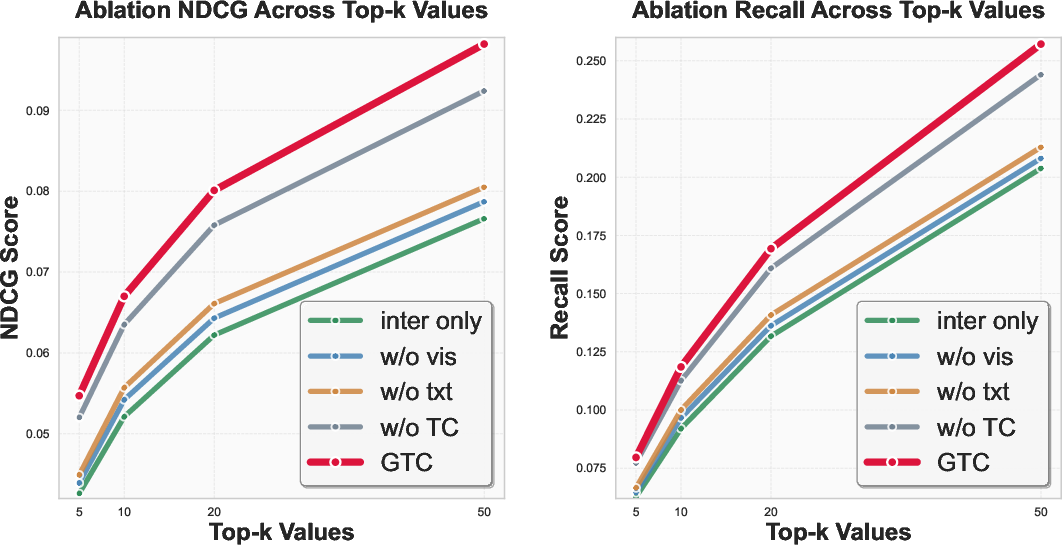
Figure 4: Inclusion of visual/textual modalities and the use of TC-based alignment synergistically improve NDCG and recall compared to unimodal or pairwise approaches across datasets.
Ablation Analysis
Ablations demonstrate the necessity and complementarity of GTC’s two main innovations:
- Interaction-Guided Denoising sharply improves performance over GCN+concatenation or even DRL without denoising.
- Total Correlation Objective (vs. pairwise contrastive loss) provides a further consistent gain, highlighting the impact of higher-order dependency modeling.
Cross-Modal Balance and Consistency
During training, GTC progressively enhances modality balance scores, indicating more coherent, equally weighted integration of all modalities.
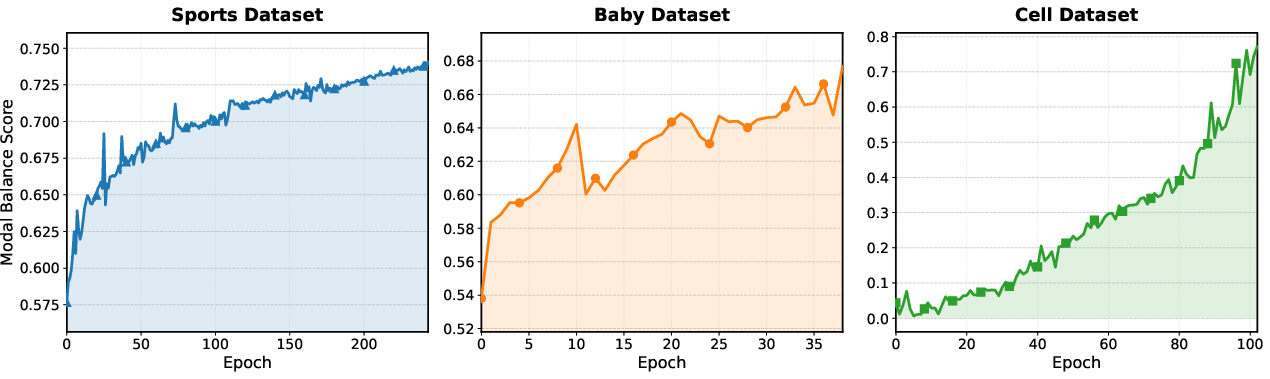
Figure 5: GTC closes the inter-modal representation gap during training, as measured by consistently increasing modality balance scores.
User preference consistency, measured by dot products of user and modality embeddings, increases steadily and more equitably for all modalities under GTC compared to DRAGON and MGCN, whose modality contributions remain imbalanced.
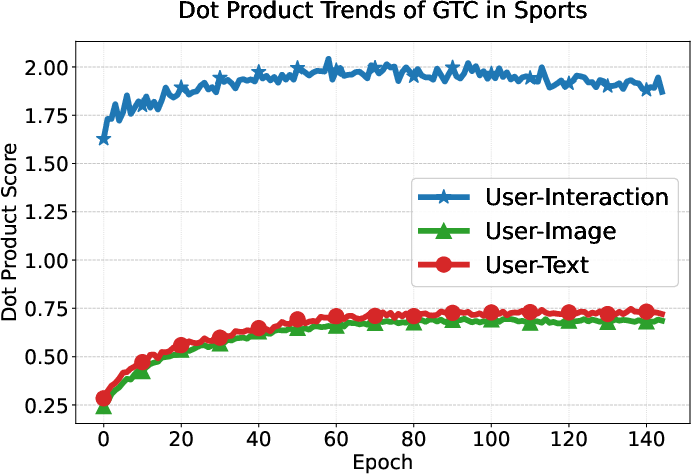
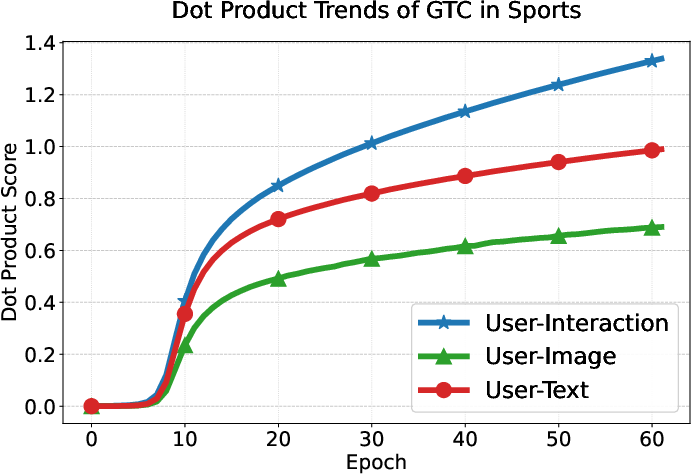
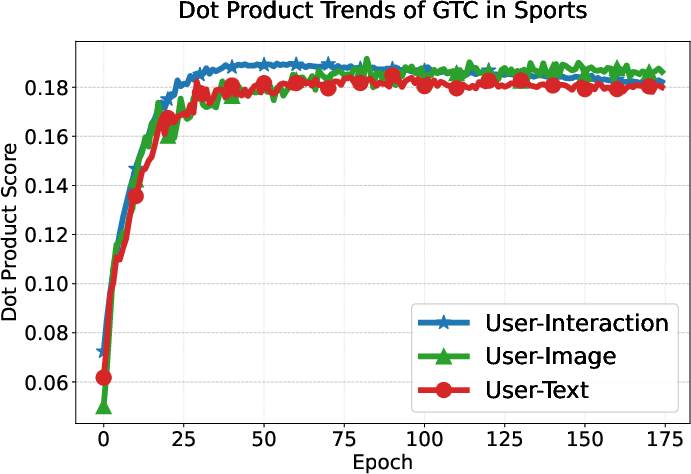
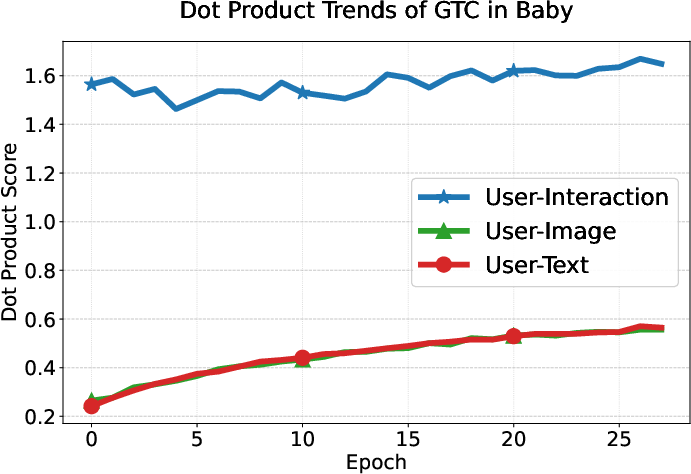
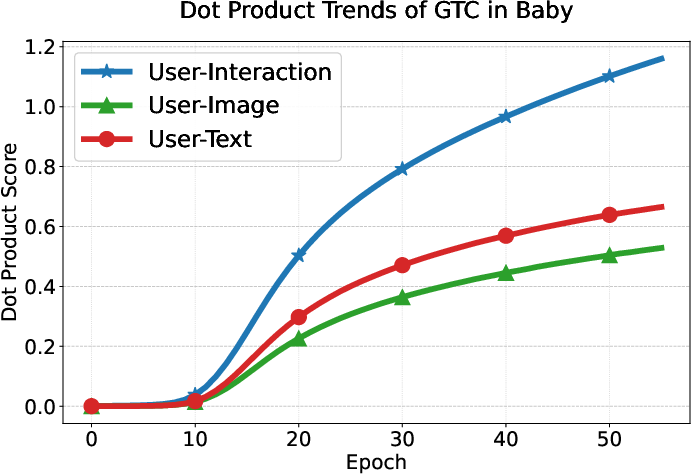
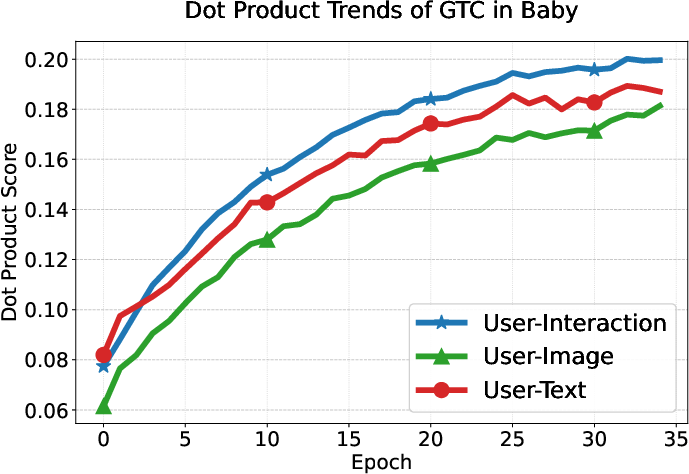
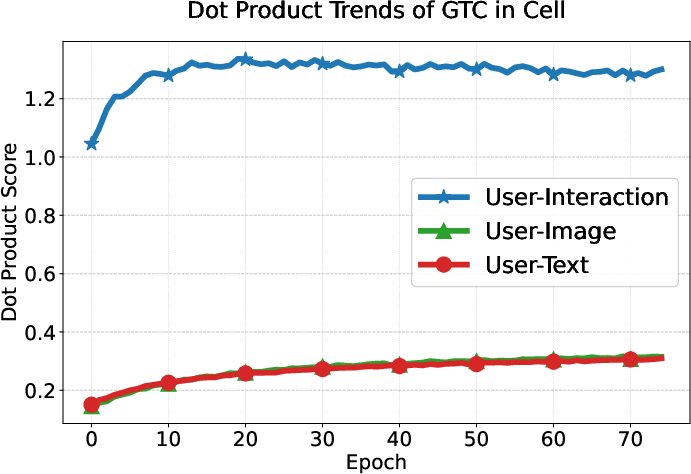
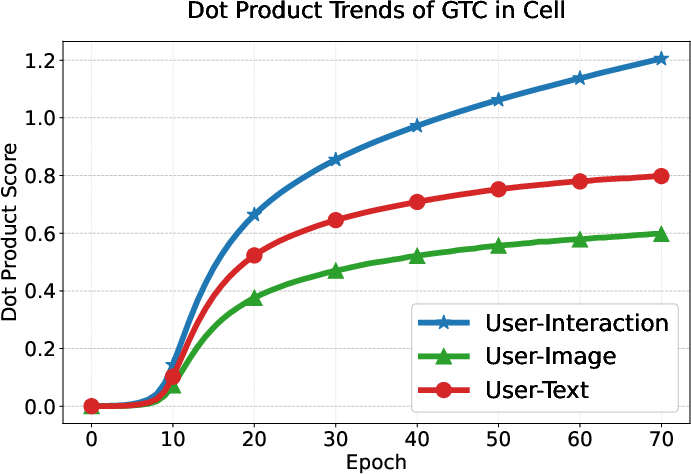
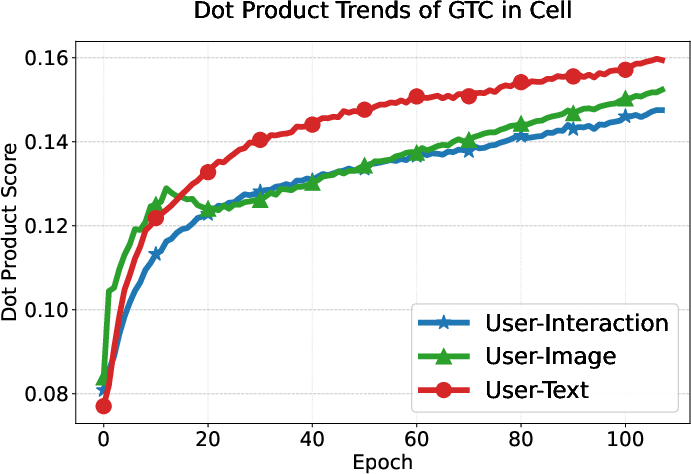
Figure 6: GTC yields balanced and steadily increasing alignment of user embeddings with all three modality-specific item representations, unlike baselines where interaction signals dominate.
Hyperparameter and Sensitivity Analysis
Performance is sensitive to the diffusion noise schedule and the relative weighting of denoising and TC objectives. Moderate noise injection and balanced objective weights yield optimal results, with dataset-specific tuning required.
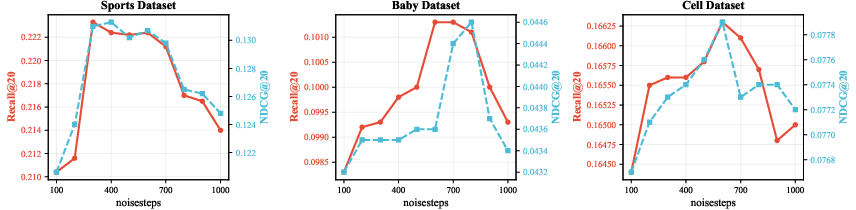
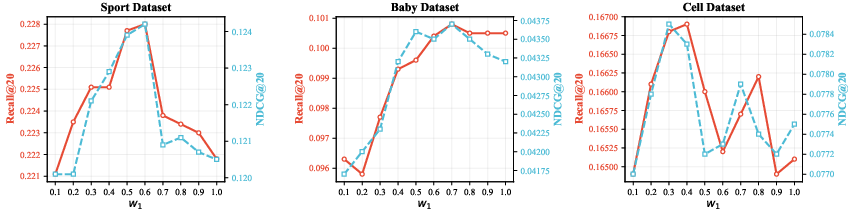
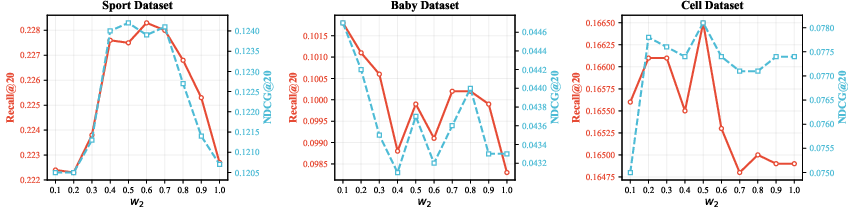
Figure 7: GTC hyperparameter sweeps reveal the effect of noise steps and loss weighting across datasets; optimal values vary by domain.
Implications and Future Directions
By formalizing user-conditional preference denoising, GTC dissolves the restrictive assumption of universal content feature relevance. Its holistic approach to cross-modal alignment, manifested through total correlation optimization, exposes and exploits latent dependency structures ignored in prevailing models. This enables coherent multi-modal item representations that more faithfully reflect personalized user preference.
Practically, GTC sets a new state-of-the-art for MMR, particularly in domains where user interests are highly heterogeneous or item content is noisy. Theoretically, it demonstrates the viability of generative modeling (via diffusion) and high-order information-theoretic objectives for advanced recommendation problems.
Future work may extend GTC to more complex user and interaction dynamics (e.g., sequential/temporal models), accommodate emerging modality types (e.g., audio, video), or further generalize the conditional generative alignment paradigm to address explainability and fairness in recommendation.
Conclusion
GTC redefines multi-modal recommendation by explicitly addressing neglected deficiencies in user awareness and cross-modal dependency modeling. By conditioning generative denoising on user preferences and maximizing total correlation across all modalities, this framework produces highly personalized and coherent item representations, outperforming existing methods by a substantial margin and advancing both the empirical capability and conceptual understanding of MMR systems.

