- The paper presents FT–MDN–Transformer, a novel tabular transformer model that integrates token-level feature handling with a mixture density network for multimodal loan recovery predictions.
- The model transfers learning across datasets with heterogeneous features by employing schema-aware attention masking and fine-tuning on both shared and domain-specific features.
- Empirical results reveal that pretraining on shared features significantly boosts performance, especially in low-data regimes affected by distribution shifts.
Transfer Learning for Loan Recovery Prediction under Distribution Shifts with Heterogeneous Feature Spaces
Introduction and Motivation
The estimation of loan recovery rates (RR) is crucial for credit risk modeling, regulatory capital, provisioning, and strategic pricing. The challenge is compounded in settings with infrequent default events, leading to limited labeled data per portfolio. Classic RR models typically struggle to capture the complex, often multimodal conditional distributions of recoveries and are further hampered by data scarcity. Transfer learning (TL) presents a viable path to mitigate data limitations by leveraging information from related source domains, but faces notable challenges due to possible distributional shifts (covariate, conditional, and label shift) and mismatched, heterogeneous feature spaces between domains.
The paper introduces the FT–MDN–Transformer (FT–MDN–T), a tabular transformer architecture tailored for transfer learning in loan recovery forecasting under distribution shifts and incomplete feature overlap. Its design combines transformer encoders for tabular data, feature-wise tokenization to handle variable feature sets, and a mixture density network (MDN) head for full conditional density prediction.
Each tabular feature is tokenized independently, including categorical embeddings and learnable transformations for numerics, enabling dynamic masking of absent or domain-specific features at the token level. The model backbone applies schema-aware attention masking, ensuring that only available features in a domain contribute to representation learning. The MDN output layer parameterizes the conditional distribution p(R∣X) as a mixture of Gaussians, explicitly modeling multimodality and heteroscedasticity seen in empirical recovery distributions.
Figure 1: Architecture of the FT–MDN–Transformer with distributional RR predictions.
Empirical Setting and Data Heterogeneity
Empirical analysis is built around two distinct datasets: Global Credit Data (GCD), a large loan dataset with high feature richness, and UP5, a bond dataset with fewer defaults and broader feature coverage. These domains present marked heterogeneity: only 37 features overlap between 73 (GCD) and 164 (UP5) after cleaning, with substantial differences in RR distribution structure and feature types.
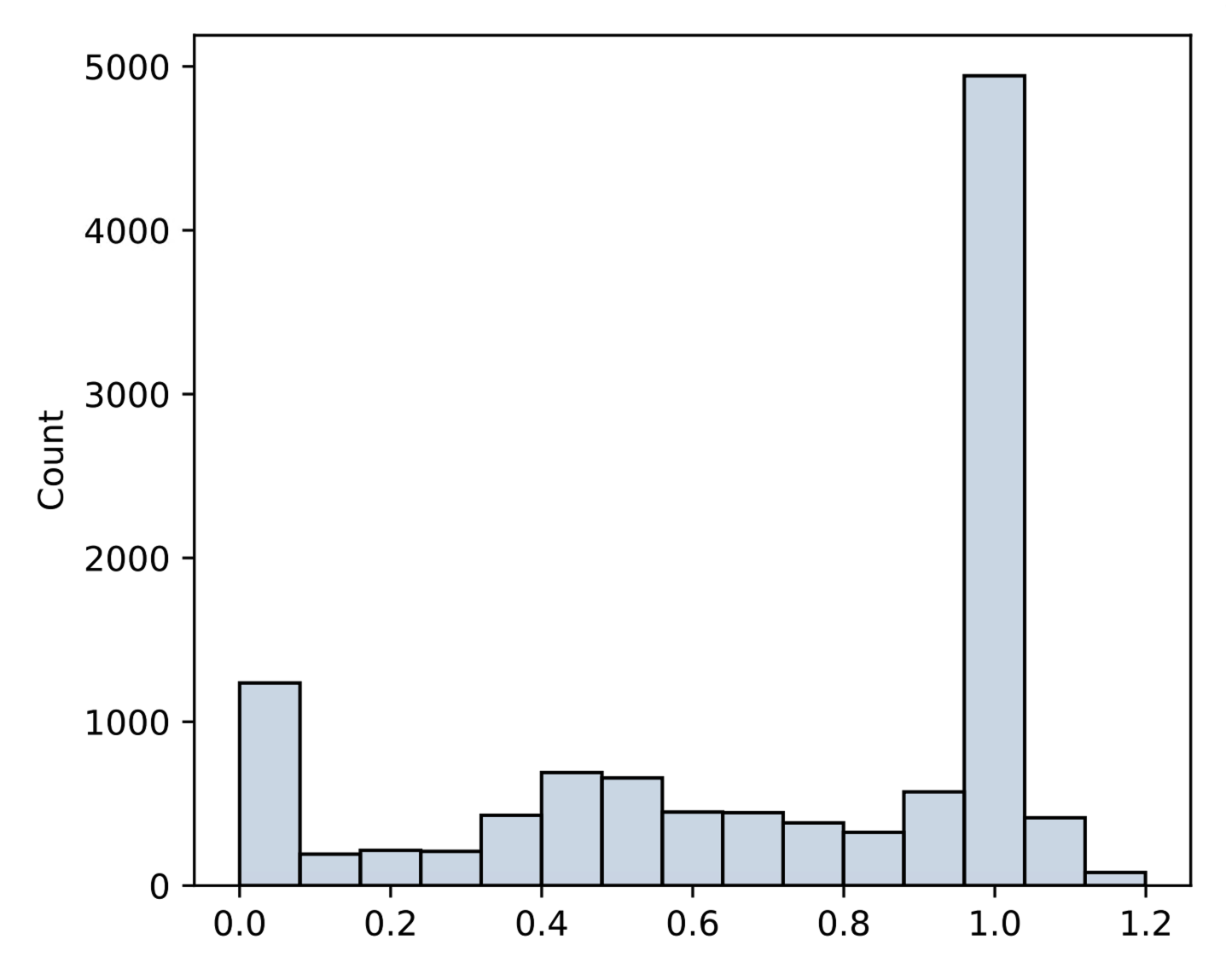
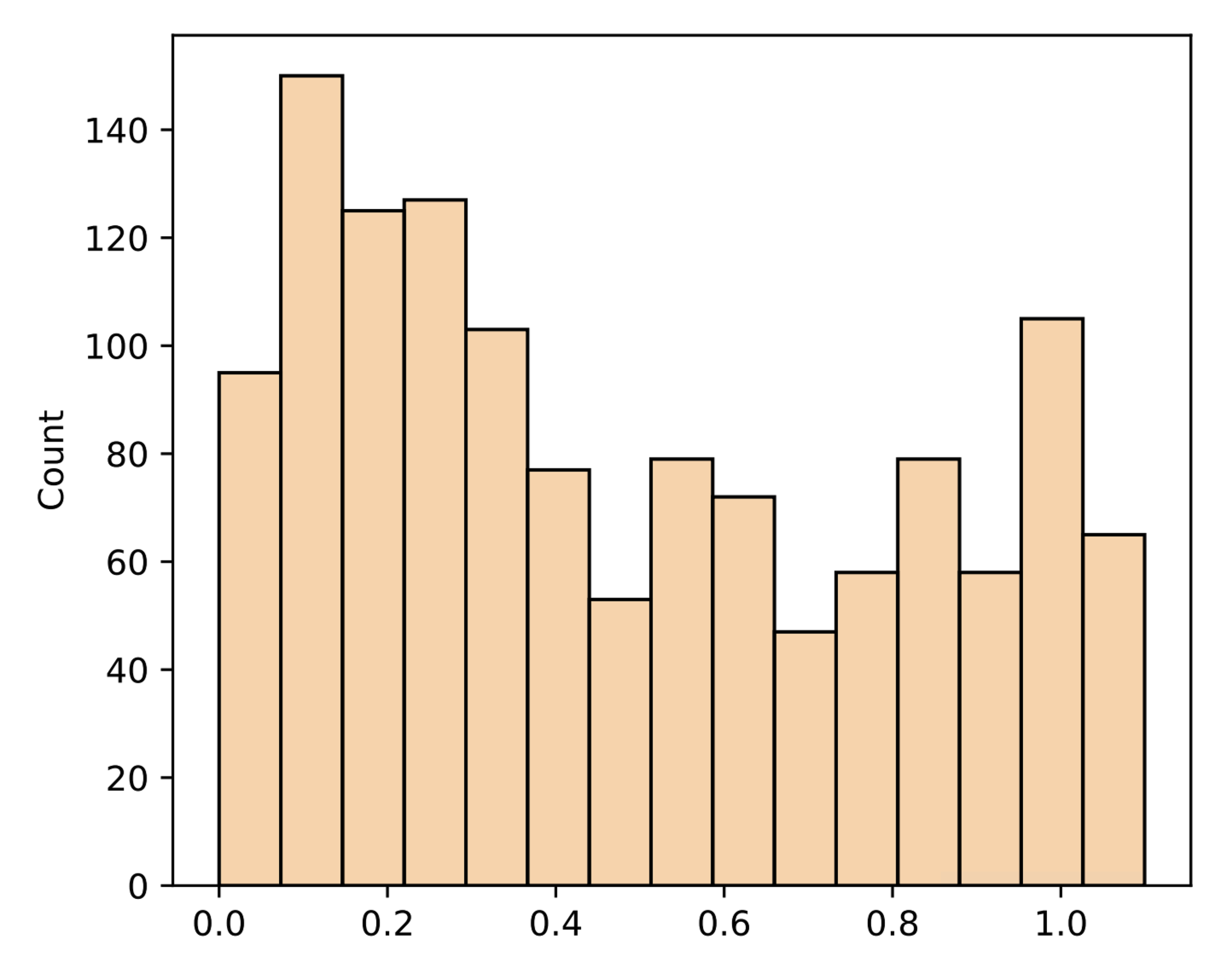
Figure 3: Comparison of recovery rate distributions for GCD and UP5 and the limited (37-feature) overlap between domain schemas.
FT–MDN–T explicitly addresses this heterogeneity by supporting both shared- and domain-exclusive features during pretraining and fine-tuning. New target-only features are trainable from scratch upon transfer, while source-only features are masked out and replaced with a PAD token during target fine-tuning.
Distributional Modeling: Capturing Multimodality
Distributional modeling is central in this setting, as classic regression collapses information in inherently multimodal RR distributions. FT–MDN–T, trained solely on UP5, produces mixture-based predictive densities that encode the multiple recovery regimes observed at the loan level.
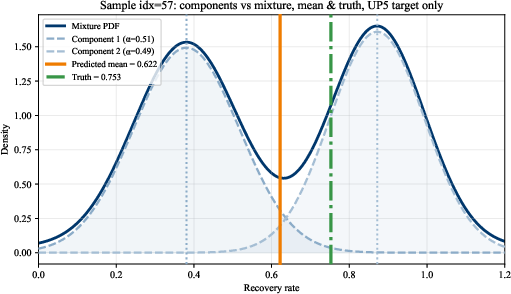
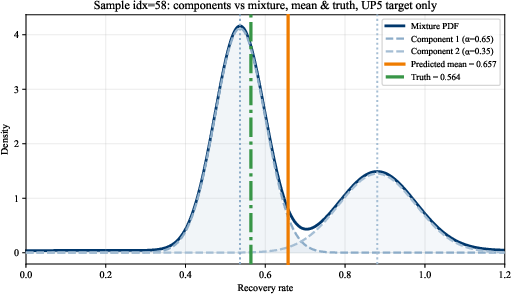
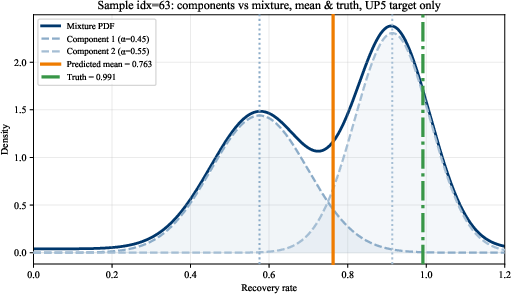
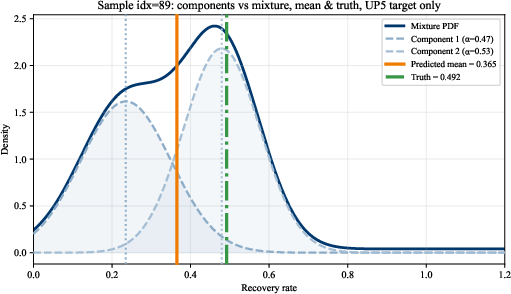
Figure 5: Single-loan RR distributions predicted by FT–MDN–T for UP5; mixture components represent underlying multimodal structure.
At the portfolio level, the aggregated predictive density from FT–MDN–T matches the empirically observed RR bimodality, unlike point-estimation baselines which fail to recover this structural detail.
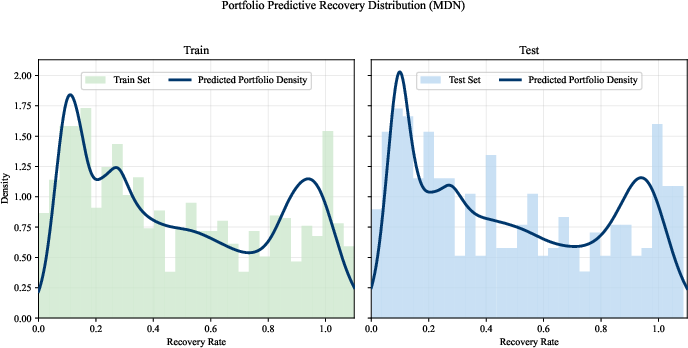
Figure 2: FT–MDN–T captures the bimodal shape of the UP5 RR distribution at the portfolio level—point-prediction baselines cannot.
Representation and Schema Transfer Mechanisms
Handling categorical features robustly is critical for tabular TL. FT–MDN–T uses learned categorical embeddings, which outperforms dummy/one-hot encoding (commonly required by tree models) on both predictive performance and convergence stability.
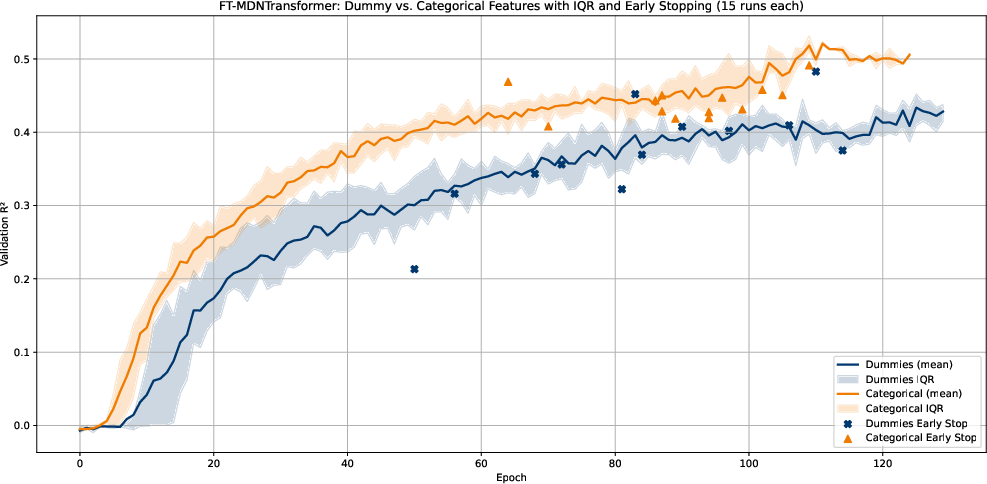
Figure 8: Native categorical embeddings consistently outperform dummy-coded representations for UP5 in FT–MDN–T.
A controlled in-domain experiment on UP5 further demonstrates the ability of FT–MDN–T to warm-start fine-tuning on expanded target schemas. The model pretrained on shared features immediately benefits from additional features upon schema expansion, with accelerated convergence and higher asymptotic accuracy compared to scratch training.
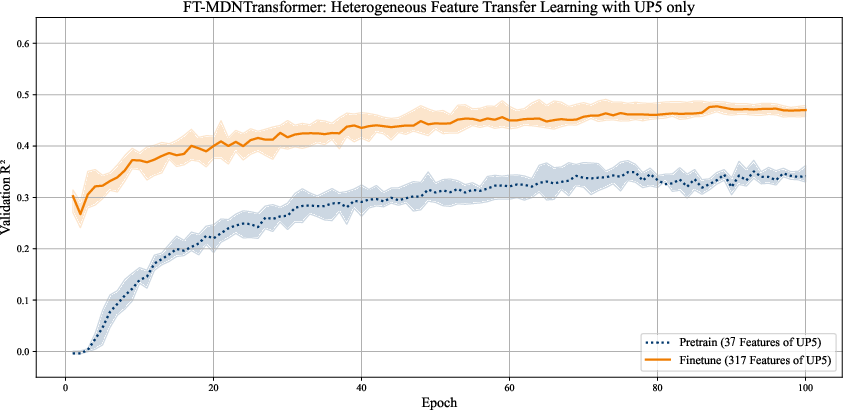
Figure 4: Expanding to full feature schema (from 37 to 317 features) yields faster and better learning via pretraining and fine-tuning.
Real-World and Simulated Transfer Experiments
Cross-portfolio transfer from GCD (loans) to UP5 (bonds) elucidates the impact of domain and schema mismatch. TL significantly boosts predictive accuracy and lowers error in small target data regimes. The best results are obtained by pretraining on the shared feature subset and then fine-tuning on all available UP5 features, highlighting the importance of strict schema alignment at pretraining for optimal transfer.
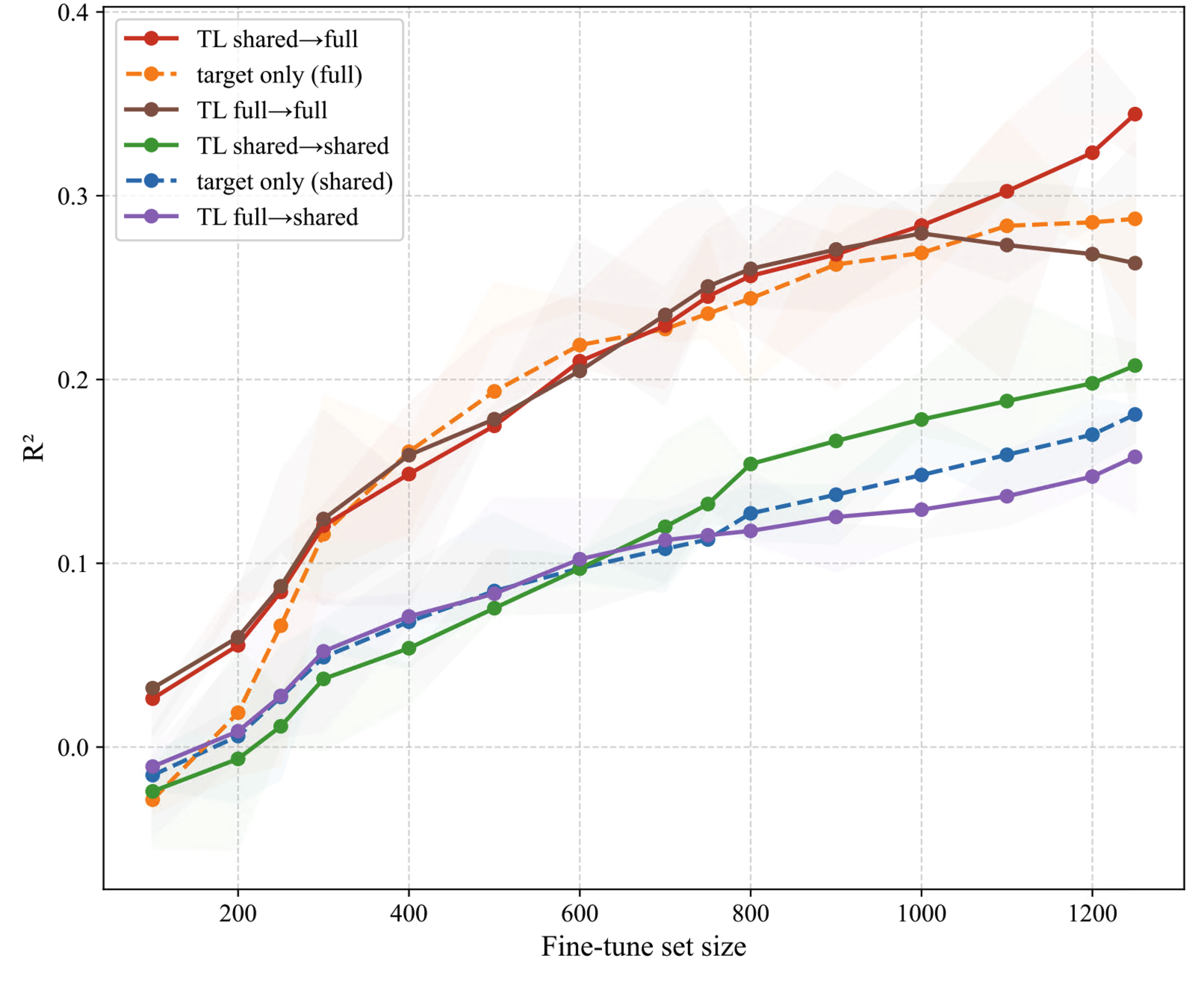
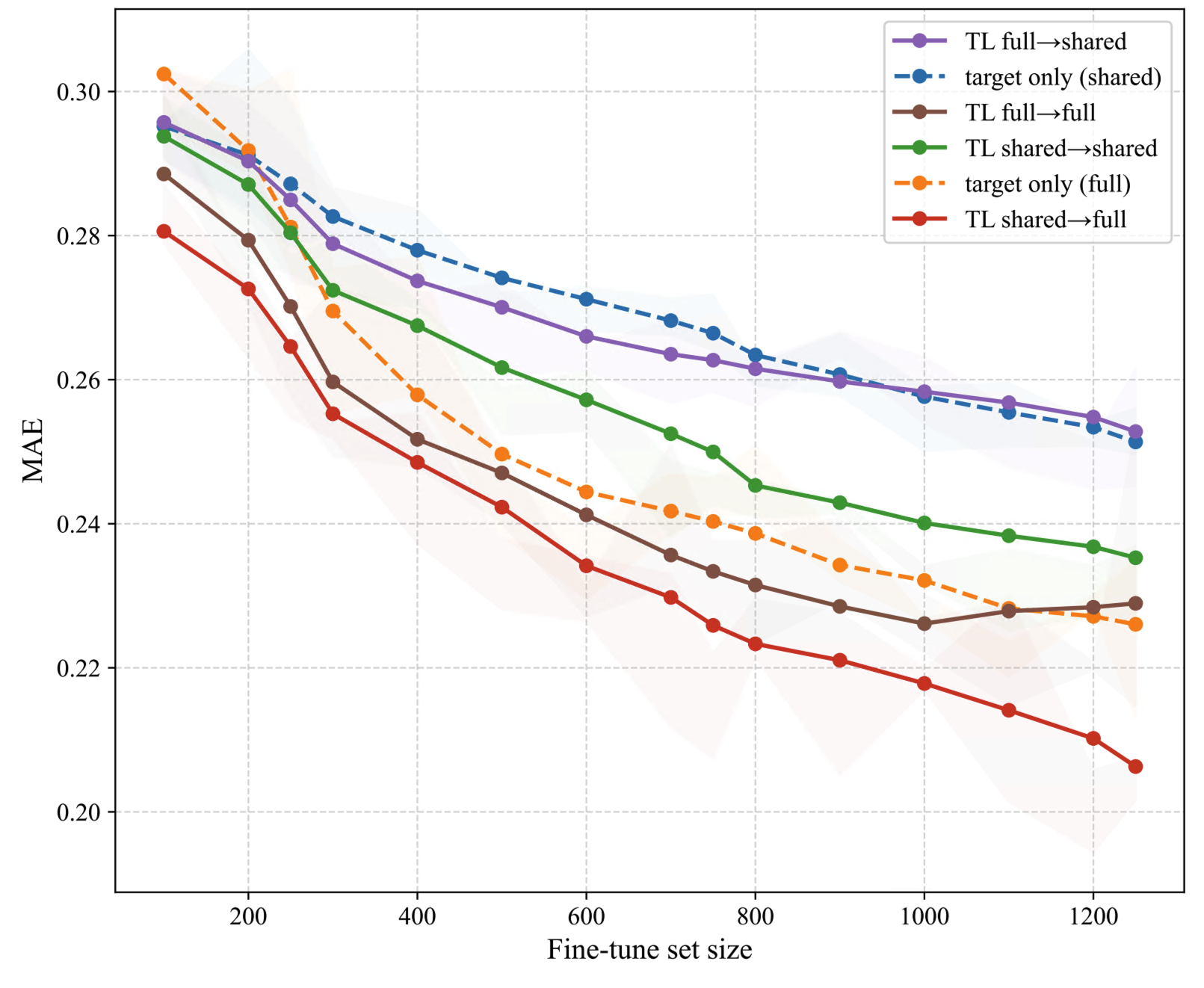
Figure 6: Cross-portfolio GCD→UP5 transfer—TL (shared→full) achieves highest R2 and lowest MAE in sparse-target regimes.
Extensive controlled Monte Carlo simulations allow systematic variation of shift intensity, target sample size, and schema overlap. FT–MDN–T is robust to covariate and conditional shifts but is challenged by strong label shift, where RR marginal distributions diverge substantially between domains. The model is consistently sample-efficient: pretraining accelerates downstream performance and is especially critical when target-labeled data is severely limited.
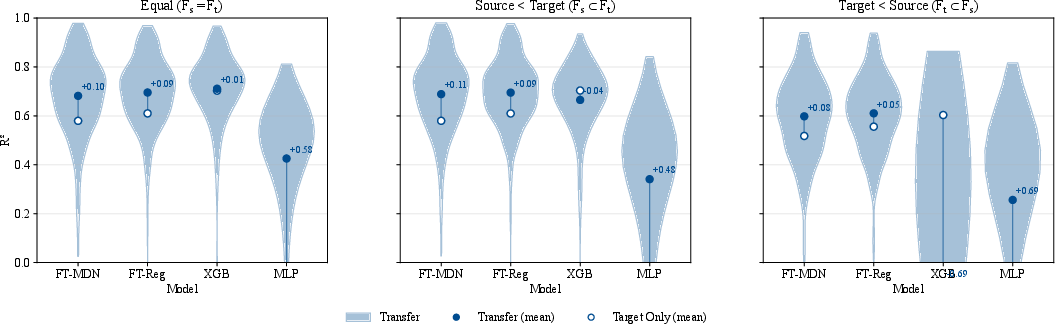
Figure 7: FT–MDN–T provides transfer benefits across all heterogeneity regimes; XGBoost is unstable under feature schema mismatch.
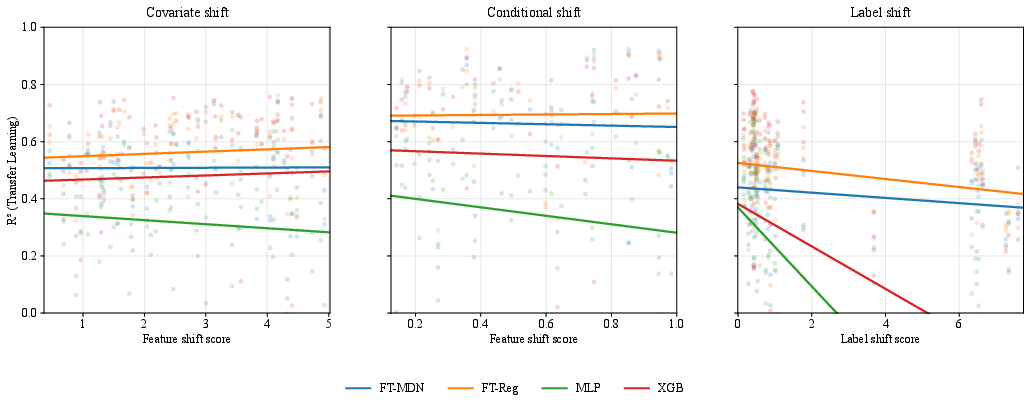
Figure 9: R2 degrades only mildly under covariate/conditional shift, but label shift severely impacts all models, with FT–MDN–T most robust.
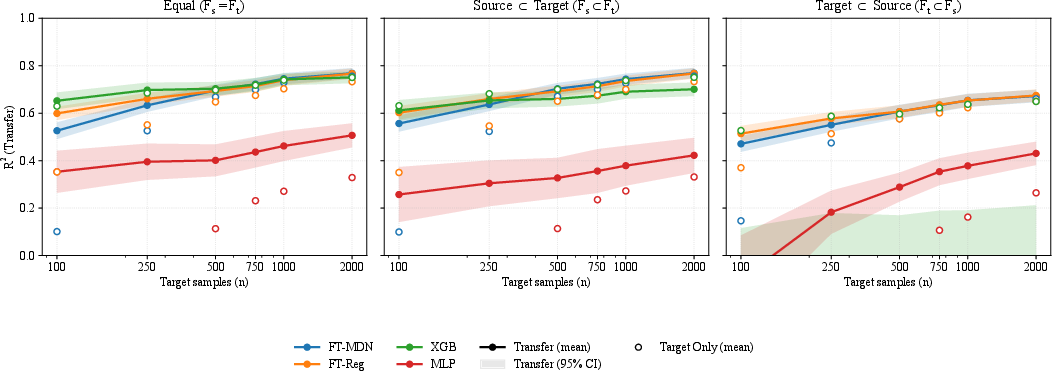
Figure 10: Pretraining significantly boosts performance when target data is scarce, but benefits diminish as nt increases.
Practical and Theoretical Implications
The results provide strong evidence for the value of feature-aware, distributional TL architectures in credit risk applications. Practitioners should leverage TL chiefly when target data is limited, feature overlap is moderate, and label distributions are not heavily divergent. The integration of categorical embeddings and token-level masking allows for practical deployment in environments characterized by ad hoc, evolving feature schemas—an omnipresent reality in operational lending systems.
FT–MDN–T's capacity for full conditional density estimation is particularly salient in applications like stress-testing and tail-risk analysis, where accurate modeling of multimodal and heavy-tailed RR distributions is non-negotiable.
From a theoretical stance, the findings delineate the operational boundaries of TL under heterogeneous schema and distributional shift, underscoring that label shift remains the limiting factor for effective model reuse. The approach provides a foundation for extending transformer-based tabular TL beyond the credit domain, especially in structured data environments where missingness and heterogeneity are normative.
Directions for Future Research
Explicit integration of label-shift correction—potentially via domain-adversarial training or semi-supervised techniques—remains an open direction. Evaluations that emphasize calibration and risk-distribution alignment, beyond mean and R2, will further improve risk-sensitive applications. Moreover, deploying FT–MDN–T within test-time adaptation regimes could address settings with dynamic or unobserved target shifts.
Conclusion
FT–MDN–Transformer advances transfer learning for RR prediction by supporting heterogeneous feature spaces, explicitly modeling recovery distribution shape, and offering robust performance under a spectrum of distributional and schema shifts. TL delivers its strongest gains in the low-data regime and with moderate feature and label alignment. However, substantial label shift remains the primary challenge, and schema-aligned pretraining is often superior to full-feature pretraining when domain gaps are large. These insights inform both applied risk management and further methodological development in TL for tabular structured data, with implications for any domain facing distributional heterogeneity and data scarcity.

