- The paper introduces a novel two-stage transformer-based pipeline that uses BoxMesh as an intermediate representation for recovering sewing patterns from 3D garment surfaces.
- It employs compressive tokenization and semantic parsing to disentangle draping deformations, predict panel layouts, and generate stitching instructions.
- Experiments show significant improvements over baselines, with enhanced structural fidelity and robust generalization across diverse datasets.
Problem Overview and Motivation
The recovery of sewing patterns from draped 3D garment geometry constitutes a fundamentally ill-posed inverse problem in digital human modeling. While forward simulation—mapping 2D sewing patterns to 3D garments via mature physics-based engines—is well established, inferring editable, parametric 2D patterns directly from arbitrarily deformed 3D scans or meshes is underdetermined by nature. Existing approaches are largely constrained by template reliance, limited garment typology, or fail to generalize to complex, real-world scans. Direct end-to-end models entangle structural, semantic, and deformation ambiguities, resulting in poor generalization.
InverseDraping (2604.02764) addresses these limitations by introducing a physically grounded, structured intermediate representation—BoxMesh—that separates draping-induced deformations from intrinsic garment structure. The work establishes a two-stage, autoregressive, transformer-based pipeline that bifurcates geometric inversion and pattern inference, and robustly generalizes across diverse simulated and real-world garment configurations.

Figure 1: Examples of sewing pattern reconstruction from 3D garments obtained via multi-view capture with smartphones and single-view reconstruction; each triplet shows the input, clothed human from input, and predicted sewing pattern.
Methodology
BoxMesh encodes garments as 2D flat panels arranged in 3D space, along with explicit stitching topologies, mapped onto a canonical rest-pose body. This representation aims to mirror the physical garment assembly process. Critically, BoxMesh disentangles the intrinsic geometry and connectivity from draping artifacts, enabling tractable downstream inference.
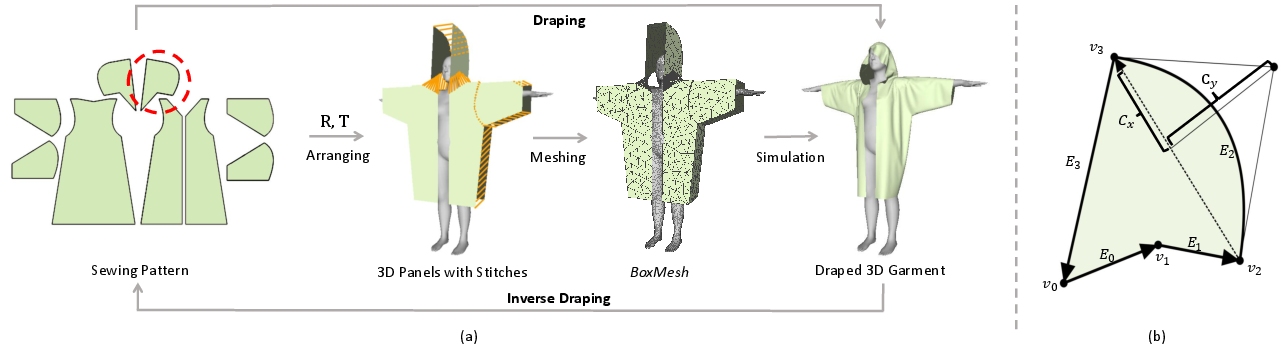
Figure 2: (a) Recovering sewing patterns from a 3D garment mesh conceptualized as the inverse problem of garment draping. (b) Example parameterization of a hood panel.
Two-Stage Pipeline
The inverse draping pipeline consists of:
Stage I—Inverse Simulation: Given a scanned/draped 3D garment mesh, a geometry-driven autoregressive transformer predicts the BoxMesh. Compressive Tokenization [weng2024scaling] is employed to decorrelate the input and output spatial dependencies, improving handling of spatially misaligned meshes and preserving sharp garment features and structural details better than direct tokenization.
Stage II—Sewing Pattern Parsing: A semantic-aware autoregressive transformer parses the BoxMesh into a sequence of sewing pattern tokens, including panel geometry, 3D placement, and stitching instructions. The tokenization strategy compresses complex panel and stitch information into a sequential format suitable for structured sequence modeling.

Figure 3: Method overview—input mesh to BoxMesh prediction (geometry-oriented model), followed by sewing pattern generation (semantic-aware model) enabling drapable output.
Experimental Evaluation
Datasets and Experimental Setup
The primary benchmark is GarmentCodeData (GCD), which offers >132k garments with corresponding sewing patterns, encompassing both default and randomly sampled body shapes. Crucially, evaluation is extended to real-world scans (THuman2.0, RenderPeople), and to in-the-wild multi-view and single-view data, rigorously assessing generalization.
Quantitative Results
- Stage I (Garment→BoxMesh): Compressive Tokenization achieves lower Chamfer and Hausdorff Distances compared to direct tokenization, yielding sharper, more accurate BoxMesh geometry.
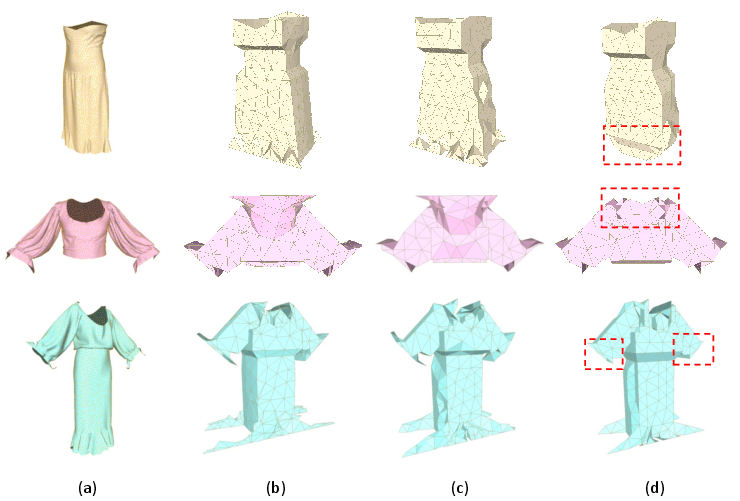
Figure 4: Evaluation of Stage I—input garment, ground truth BoxMesh, prediction with Compressive Tokenization, and with Direct Tokenization.
- Stage II (BoxMesh→Pattern): Fine-tuning on predicted (imperfect) BoxMeshes, as opposed to ground-truth only, improves robustness to upstream distribution shifts. The full model demonstrates substantial improvements in metrics such as Panel IoU, L2 distances on panel geometry and placement, stitch prediction accuracy, and 3D structural-fidelity (BoxMesh Chamfer Distance).
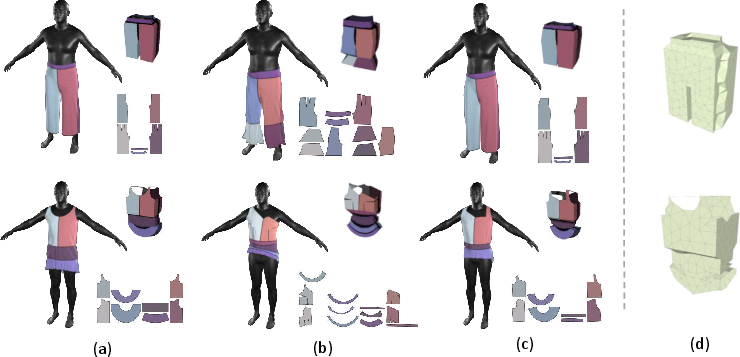
Figure 5: Stage II qualitative results—draped garment with ground truth, predictions using different BoxMeshes, and corresponding pattern visualizations.
When benchmarked against NeuralTailor [korosteleva2022neuraltailor], InverseDraping achieves large gains (e.g., from 51.9% to 71.4% Panel IoU and from 18.7% to 63.5% Sewing Stitch Precision).
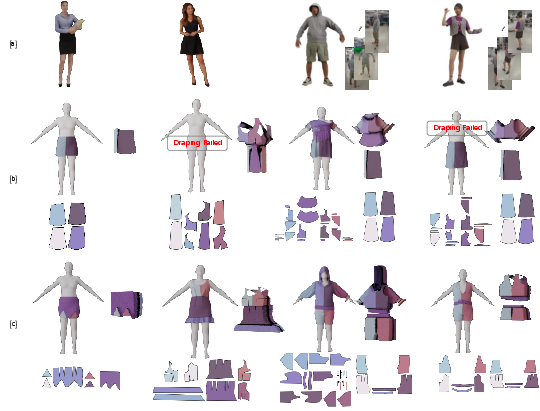
Figure 6: Qualitative comparisons to NeuralTailor on real-scan data showing superior structural faithfulness and stitch prediction.
Ablation and Generalization
Multiple ablations (e.g., skipping BoxMesh, using fixed body shape, altering point encoding) demonstrate that intermediate structuring and body-shape-diverse training are critical for performance and robustness.
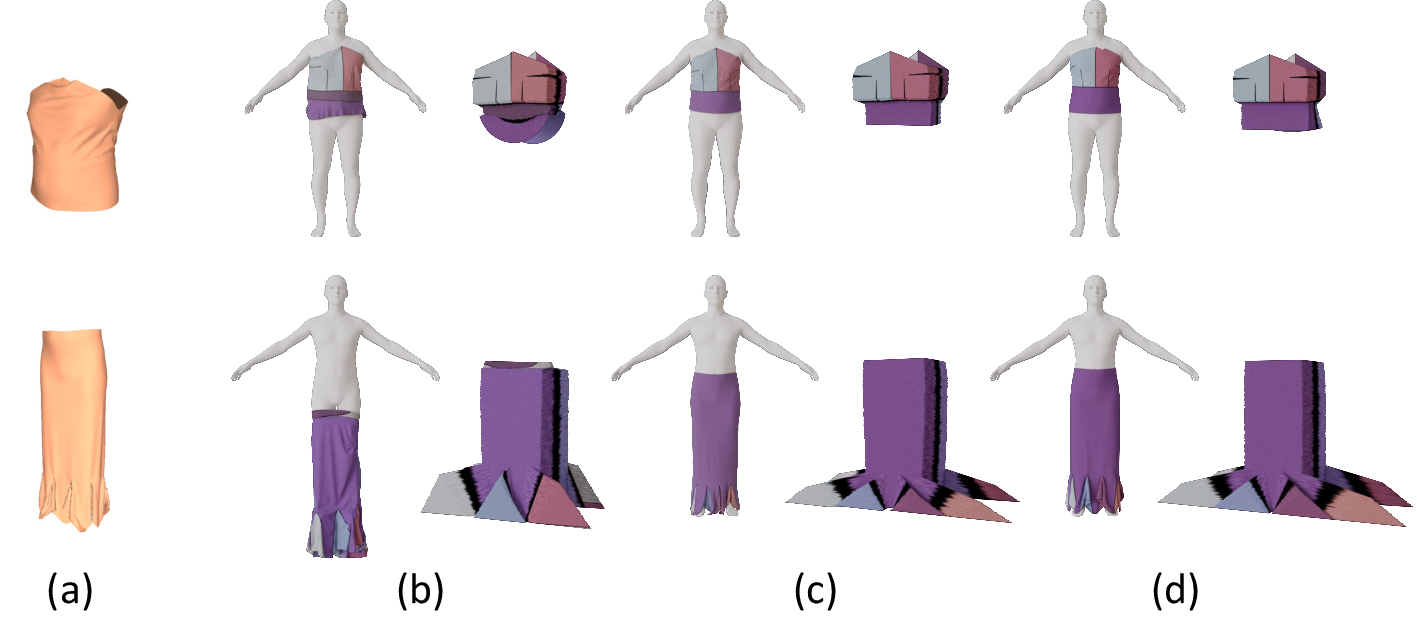
Figure 7: Ablation showing Baseline (no BoxMesh) vs. Full system—demonstrates sharpness and fidelity gains from BoxMesh usage.
Further experiments confirm importance of random-body-shape training (Figure 8), improved mesh-based over point-based BoxMesh generation (Figure 9), and ineffective joint learning without explicit intermediate usage (Figure 10).
Single-view garment reconstruction is enabled by coupling with 3D generative foundation models such as Hunyuan3D [zhao2025hunyuan3d], achieving competitive geometric accuracy and structure preservation compared to large-scale multimodal models (AIpparel [nakayama2024aipparel], ChatGarment [bian2024chatgarment]).
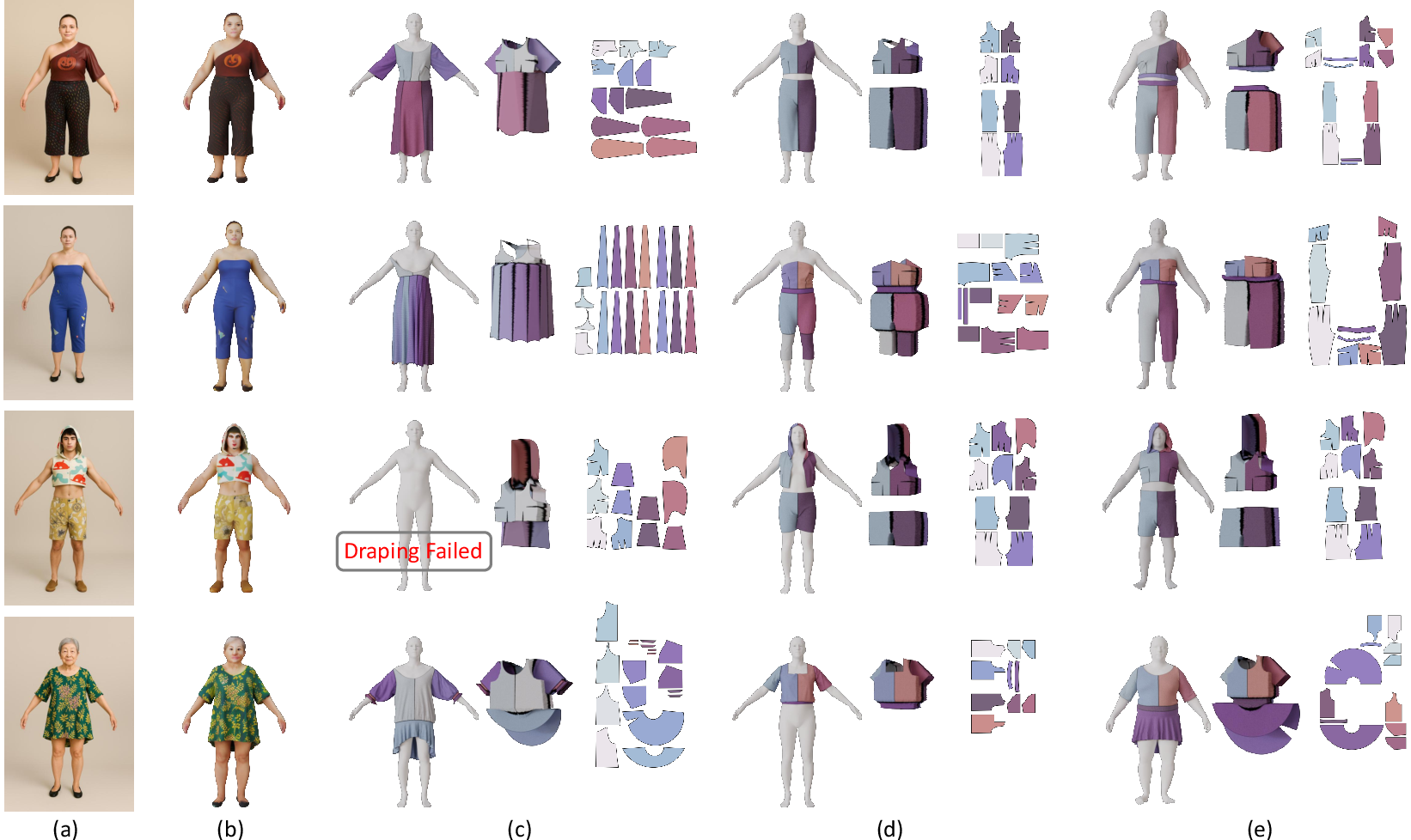
Figure 11: Single-view reconstruction comparisons—input image, 3D human, and draped/predicted sewing pattern results across methods.
Analysis, Limitations, and Implications
InverseDraping robustly generalizes to scans and unconstrained photographs, outperforming direct sequence-to-pattern baselines and previous neural architectures both numerically and structurally. The explicit BoxMesh intermediate and comprehensive body-shape conditioning are key to disambiguation, noise tolerance, and superior recovery of both panel geometry and sewing semantics. Limitations arise in cases of severe input noise (e.g., occlusion in long robes) or lack of dataset coverage (e.g., pleated garments not present in synthetic data).

Figure 12: Failure analysis—(left) noisy scanned geometry; (right) non-covered garment types.
Qualitative breadth is further demonstrated over various real and synthetic inputs, indicating future applicability in digital wardrobe editing, asset standardization, and virtual try-on pipelines.

Figure 13: More results—application to diverse scans and images, seamless garment recovery and simulation-ready patterns.
Conclusion
InverseDraping advances the state of sewing pattern recovery by leveraging structured intermediate BoxMesh representations integrated into a two-stage, autoregressive, transformer-driven pipeline. Empirical results reflect significant improvements in both recovery fidelity and generalization, validated through controlled benchmarks, real-world data, and comparative analysis. The approach establishes a new technical paradigm, separating geometric inversion from sewing semantics, and opens prospective directions for combining structured intermediates with large vision-LLMs in garment and asset digitization workflows.

