- The paper introduces a quotient-based framework for Euclidean latent space models that bypasses reference dependency by employing a centered Gram matrix.
- It provides canonical posterior summaries and robust uncertainty quantification, validated through simulations and applications to network data.
- The method enhances inference in weakly identified and multimodal settings, setting a new standard for uncertainty analysis in latent space models.
Quotient-Based Posterior Analysis in Euclidean Latent Space Models
Background and Motivation
Euclidean latent space models (LSMs) are central to statistical network analysis, positing that each node is associated with an unobserved position in a latent Euclidean space, such that edge probabilities are deterministic functions of pairwise distances. Despite their utility, LSMs feature inherent nonidentifiability: the likelihood and thus the posterior are invariant under rigid motions (rotations, reflections, translations) of the latent space. Conventional practice aligns posterior samples via Procrustes methods to a reference embedding for visualization or summary statistics; however, this approach produces reference-dependent and non-canonical summaries, especially problematic in weakly identified regimes or multimodal posteriors.
This paper presents a mathematical and computational framework for mitigating these issues by transferring posterior analysis to a quotient space, wherein only identifiable, relational structure — specifically, the collection of pairwise distances — is retained. The proposed approach utilizes the centered Gram matrix, mapping latent positions to a rigid-motion-invariant representation. Canonical, stable, and interpretable posterior summaries arise as functionals on this quotient metric space, ensuring intrinsic objectivity and interpretability in both inference and uncertainty quantification.
Quotient Geometry and Intrinsic Summaries
The core methodological innovation is the adoption of the centered Gram matrix Φ(X)=HXX⊤H, where H is the centering matrix, for every posterior sample of latent positions X. This matrix is invariant under any translation or orthogonal transformation, and it encodes all pairwise Euclidean distances, the model's true inferential target. Thus, the set of possible B=Φ(X) forms a closed set of centered, low-rank positive semidefinite matrices, up to rank r (the latent dimensionality).
Posterior samples are thus mapped to this quotient space, and all subsequent analysis — including point estimation, dispersion, credible regions, and diagnostic indices — is conducted intrinsically, without further reference to any arbitrary alignment or coordinate system. The quotient distance between two embeddings is realized as the Procrustes Frobenius norm between their centered factors, minimized over the orthogonal group.
Intrinsic Posterior Summaries
Canonical summaries in this framework are defined as follows:
- Quotient Posterior Mean (Fréchet Mean): The barycenter (mean) in quotient space is the minimizer of the sum of squared quotient distances to posterior samples. This mean is guaranteed to exist (by virtue of working on a closed set) and is canonical.
- Posterior Dispersion and Credible Regions: Intrinsic global variation is measured as the average squared distance to the mean in quotient space. Credible regions are intrinsic balls centered at the mean, with radius determined by the posterior empirical quantiles.
- Dyad-Level Inference: Pairwise distances are summarized by their posterior distribution, and uncertainty in these distances is evaluated by empirical or delta-method-based variances.
- Node-Level Uncertainty: For each node, a diagnostic index Ui measures the average posterior variance in distances to all other nodes, pinpointing regions of weak identification.
All algorithms are implementable via post hoc processing of MCMC draws from standard LSM fitting procedures.
Theoretical Guarantees
The quotient-based approach comes with strong mathematical guarantees:
- Canonicality: All summaries are functionals of the induced posterior law on the quotient space, ensuring invariance to all rigid motions of the latent space.
- Existence and Consistency: The Fréchet mean and variance always exist under mild moment conditions. If posterior mass concentrates in the quotient space, all distance-based summaries are consistent for the underlying relational geometry.
- Stability: Posterior summaries vary continuously under perturbations of the posterior distribution (quantified via the Wasserstein metric), ensuring that empirical summaries derived from finite MCMC samples closely approximate their population analogs, provided Monte Carlo error is controlled.
- Asymptotic Behavior: As sample size or information increases, dyad-level errors and node-level uncertainty indices Ui vanish, indicating reliable recovery of the underlying geometric structure.
Empirical Demonstrations
Simulation Study
The quotient framework was benchmarked against conventional fixed-reference Procrustes summaries in both well- and weakly-identified regimes.
In cases of weak identification, Procrustes means based on arbitrary references yielded highly variable, distorted summaries, while the quotient-based mean consistently captured the relational geometry (three-group structure) and its inherent uncertainty.
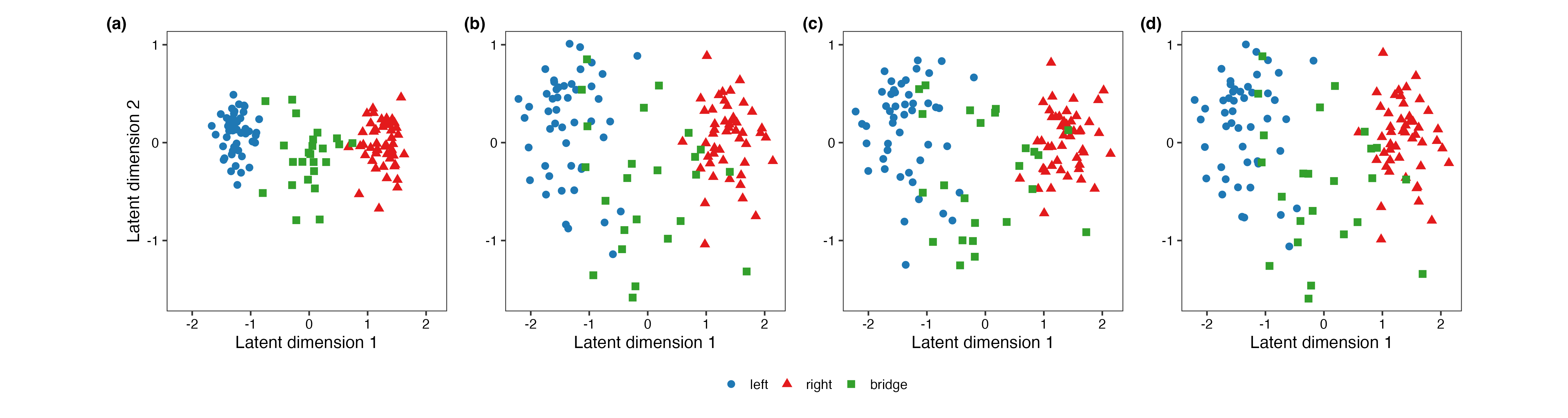
Figure 1: Representative embeddings from the weakly identified regime, showing that only the quotient mean reliably recovers group structure.
Reference sensitivity encountered by Procrustes summarization was quantified and shown to escalate sharply under weak identification, as measured by a reference-sensitivity index.
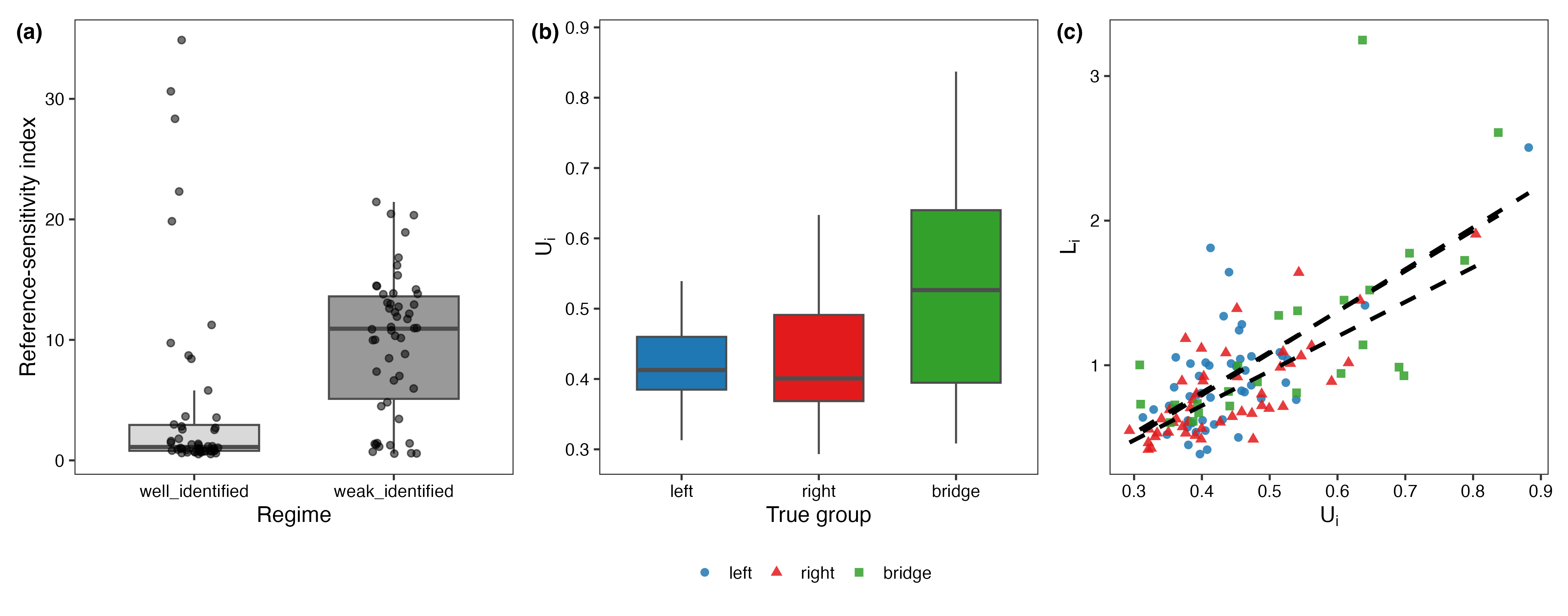
Figure 2: (a) Reference-sensitivity in Procrustes summaries. (b) Node-wise uncertainty Ui by group. (c) Correlation between Ui and estimation error.
Furthermore, node-level uncertainty diagnostics pinpointed nodes in bridge groups as the most weakly identified, aligning with the ground-truth design and estimation error, thus validating Ui as a meaningful diagnostic.
Florentine Marriage Network
Application to the canonical Florentine marriage network demonstrated that quotient-based mean embedings recover familiar family clusters, while node-level uncertainty displayed specific families (e.g., Pucci) as highly ambiguous despite central locations in point estimates. These uncertainty displays went beyond what standard centrality measures conveyed.
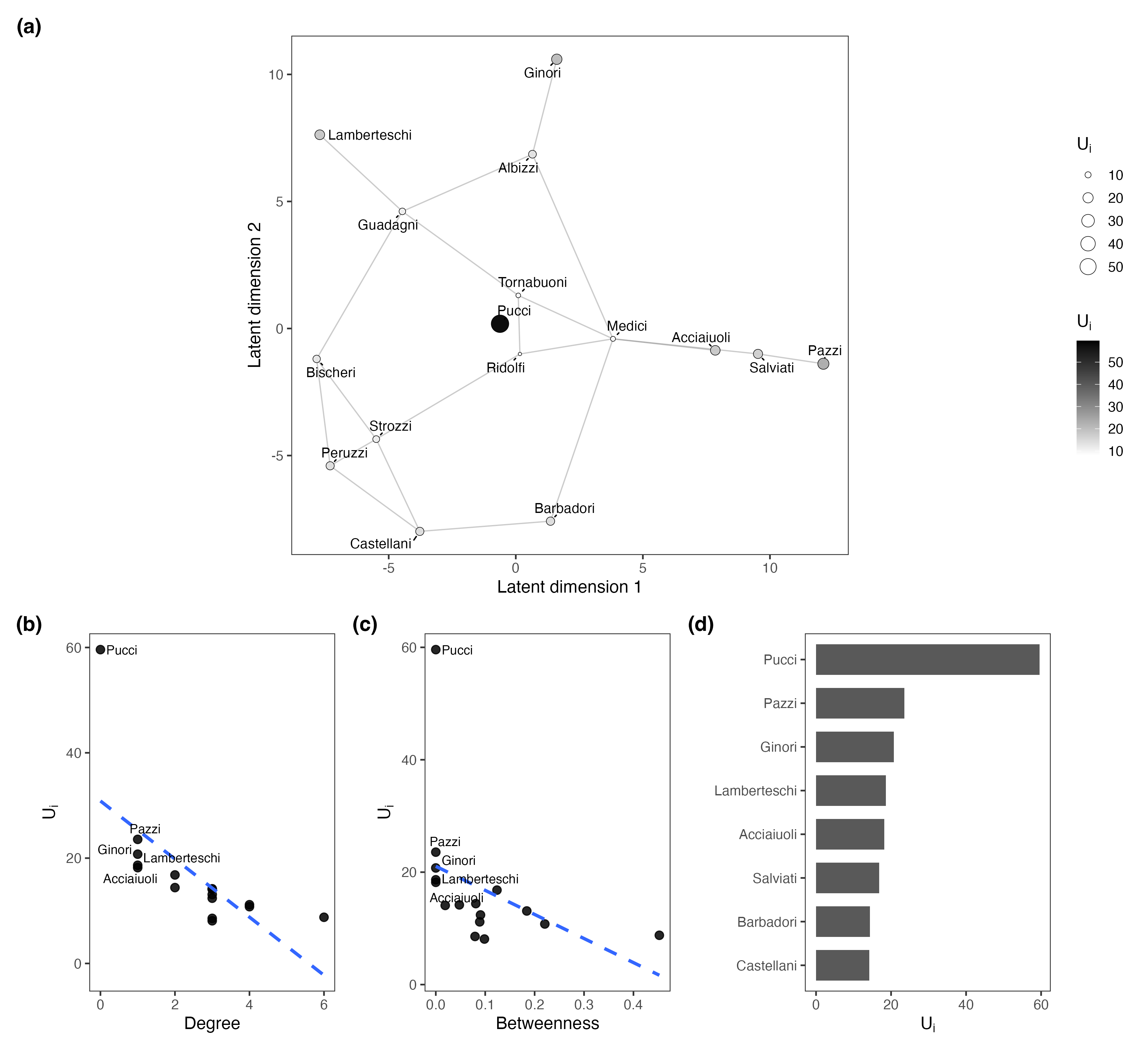
Figure 3: Posterior mean embedding and node-level uncertainty diagnostics for the Florentine marriage network.
Dyad-level summaries further distinguished between marriage ties, business-only ties, and non-ties, revealing that business-only relationships—unused in model fitting—often correspond to small inferred latent distances, exposing potential unobserved affinity structure.
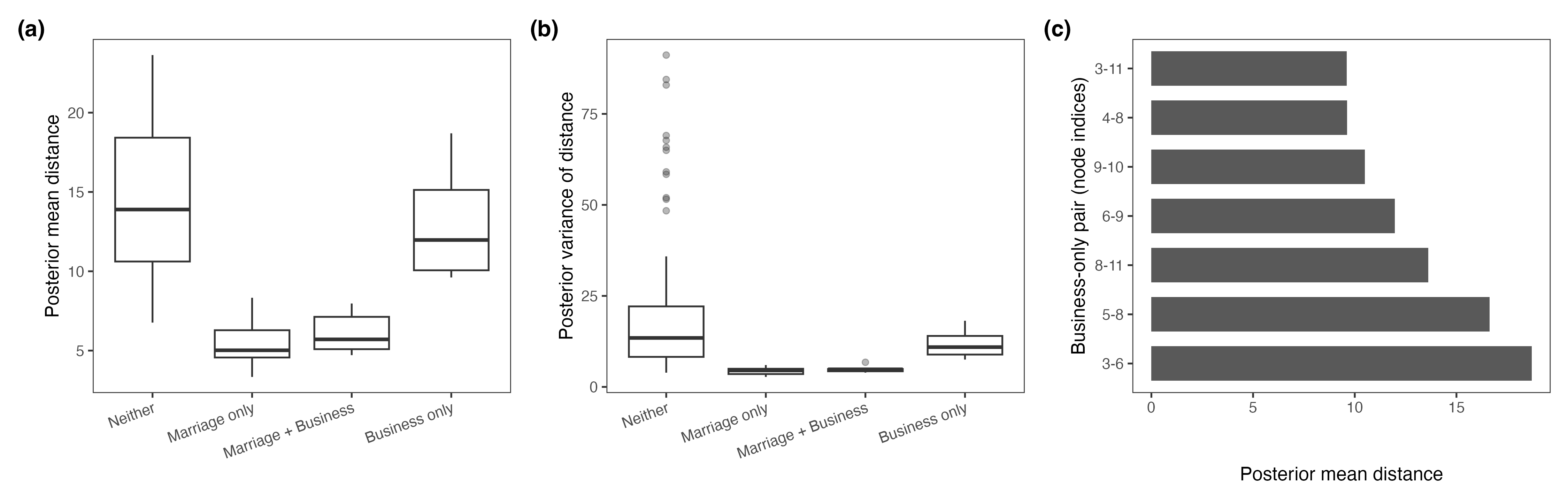
Figure 4: Dyad-level posterior summaries for the Florentine marriage network, highlighting uncertainty structure by dyad type.
Statisticians' Coauthorship Network
A large-scale coauthorship network (statisticians) highlighted the method's scalability and interpretive power. Unlike the Florentine case, quotient mean embeddings showed extensive intermixing of labeled communities, and node- and dyad-level uncertainties revealed substantial posterior ambiguity, especially in boundary nodes.
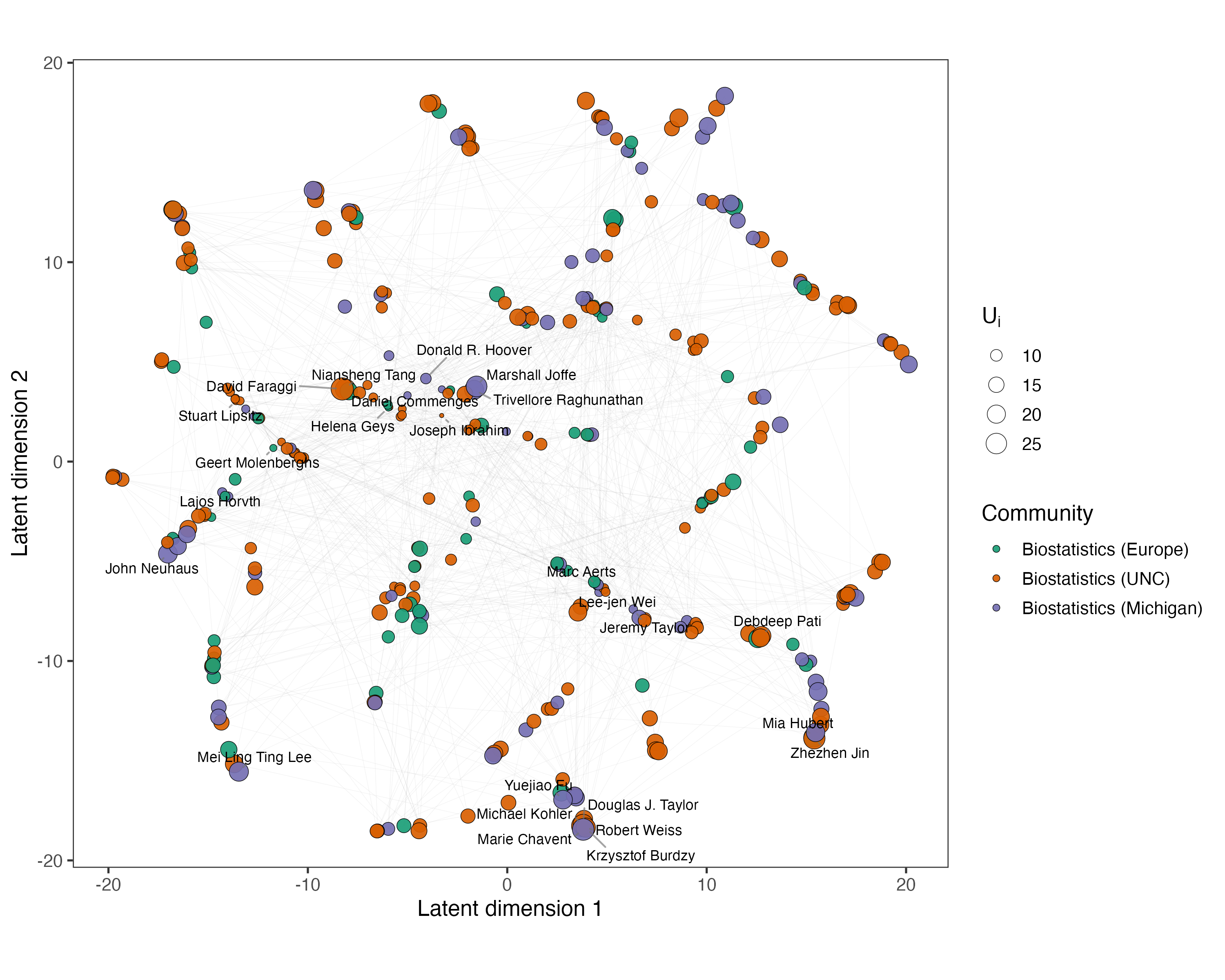
Figure 5: Quotient mean embedding for the coauthorship network, with uncertainty indexed by node size.
Figures relating node-level uncertainty to standard measures indicated only partial association, emphasizing that H0 captures model-based posterior ambiguity, not merely topological centrality.
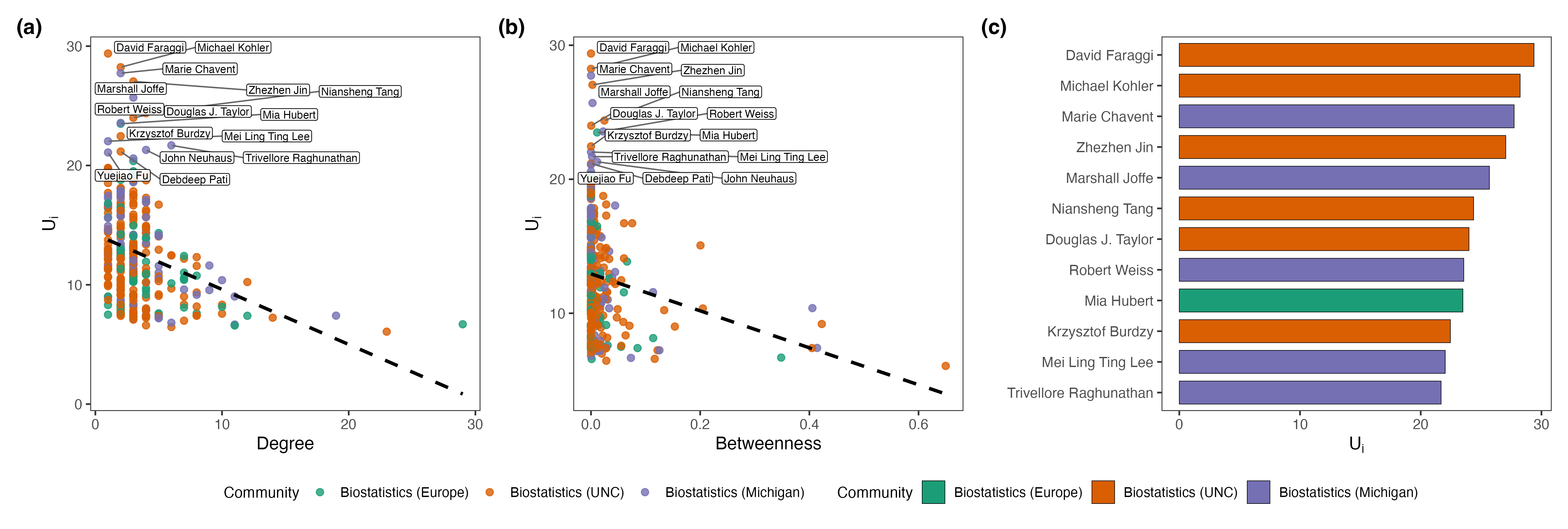
Figure 6: Node-level uncertainty versus degree and betweenness, and most ambiguous nodes.
Dyad-level inference showed within-community and between-community uncertainty intervals were highly overlapping, indicating porous and ambiguous boundaries between declared communities.
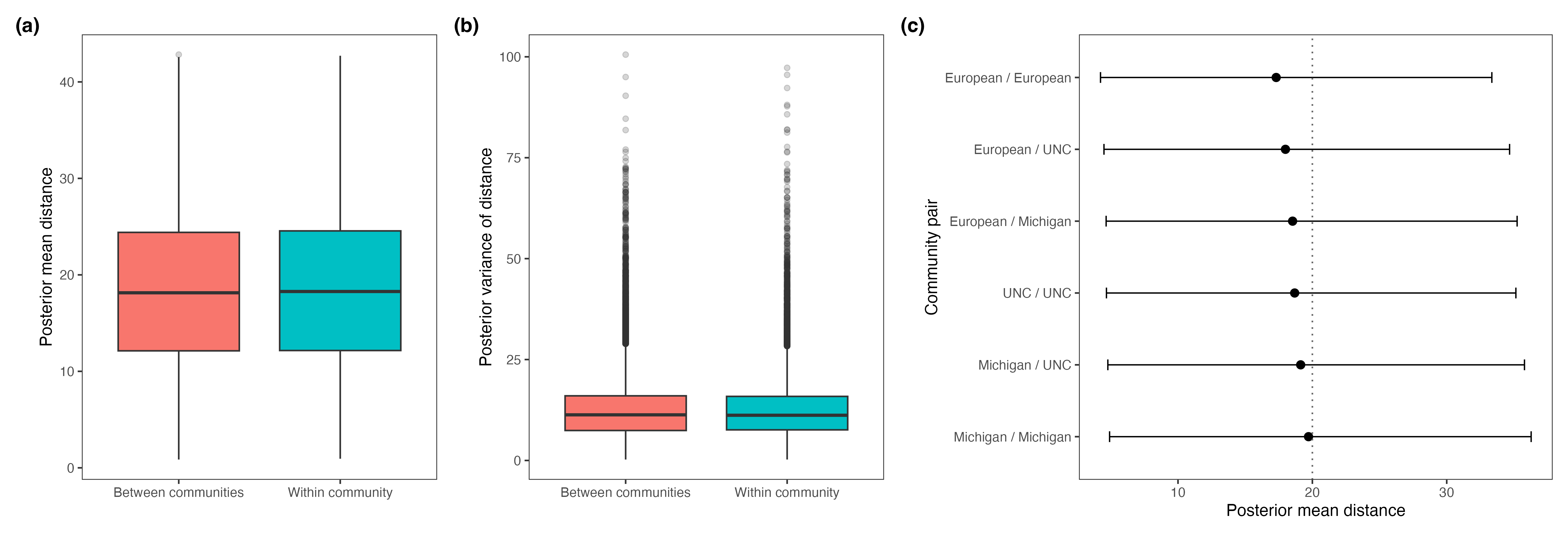
Figure 7: Dyad-level summaries comparing within- and between-community latent distances and uncertainties.
Practical and Theoretical Implications
This work decisively delineates the divide between mere visualization (alignment-based) and principled Bayesian inference in latent space models. The quotient approach eliminates the arbitrariness of reference-based summaries, producing interpretable, stable, and theoretically justified uncertainty quantification — especially critical in weakly identified regimes, large networks, or multi-modal posteriors. This results in enhanced diagnostics for both relational patterns and uncertainty, facilitating more robust scientific interpretation of network latent structure.
The quotient representation's generality paves the way for extension to more complex latent geometries (e.g., hyperbolic, spherical), dynamic and weighted graphs, and large-scale, streaming, or federated inference settings. Moreover, its connection to geometric statistics and manifold-valued inference indicates tight integration with emerging non-Euclidean statistical theory (2604.02739).
Conclusion
Quotient-based posterior analysis constitutes a mathematically principled, computationally feasible, and highly informative approach to inference in latent space models. By separating inferential content from nonidentifiable coordinate choices, it yields canonical posterior summaries, transparent uncertainty measures, and robust diagnostics across a wide range of network scenarios. This framework sets a new standard for uncertainty quantification and interpretability in network latent space analysis, calling for quotient-based analysis as standard practice in structural network inference.

