- The paper introduces GBQA as a benchmark that challenges LLMs to autonomously discover bugs in game environments.
- It employs a hierarchical multi-agent pipeline and dual-memory system to systematically evaluate agent performance across 30 games and 124 bugs.
- Experimental results reveal low recall rates in autonomous bug discovery compared to conventional code repair benchmarks, highlighting critical research gaps.
GBQA: A Benchmark for Evaluating Autonomous Bug Discovery in Game Environments
Overview and Motivation
This paper introduces GBQA, a Game Benchmark for Quality Assurance, which directly evaluates the capacity of LLMs to function as fully autonomous QA engineers in interactive software environments, with a focus on game development (2604.02648). While prior research has primarily targeted code generation and repair conditioned on explicit issue reports, GBQA addresses the upstream challenge of autonomous bug discovery, in which LLM agents must detect specification-violating anomalies without human-supplied bug descriptions.
GBQA targets agentic evaluation through a suite of 30 systematically constructed game environments, embedding 124 human-verified bugs across varying difficulties. The benchmark is meticulously curated and provides a quantitative evaluation protocol, emphasizing recall in bug discovery—maximizing the coverage of latent faults, which remains a critical bottleneck in fully autonomous software engineering.
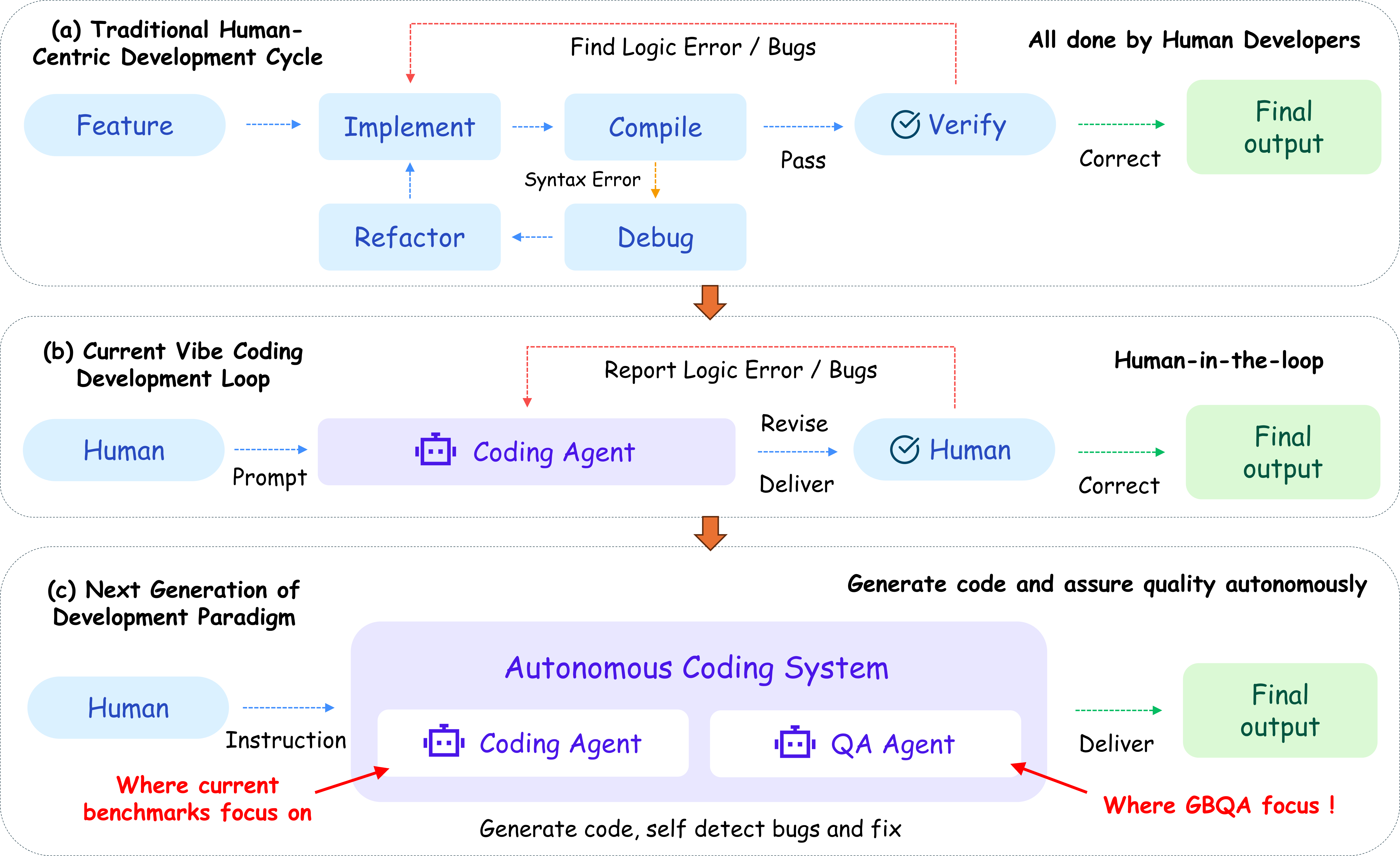
Figure 1: Evolution of the software development paradigm in the LLM era: from human-driven workflows (a), to human–LLM collaborative coding (b), to the goal of fully autonomous development, including bug detection and QA (c), which is the principal focus of GBQA.
The GBQA benchmark leverages a hierarchical multi-agent pipeline for scalable environment and bug generation. A producer agent orchestrates three expert teams (Design, Programming, Art), each managed by leaders, and operationalizes a modular, multi-workspace development process. The system iteratively escalates environment complexity, injecting diverse and challenging bugs until a minimum discovery threshold is met, ensuring non-trivial state and interaction spaces.
Each environment E is defined as a tuple comprising state space, action space, transition dynamics, and initial state. Agents interact with E through RESTful backend APIs, collecting observations, emitting actions, and generating multiple ReAct-based exploration trajectories. Bugs are divided into three categories—easy, medium, hard—using cognitive and temporal complexity criteria ranging from perceptual inconsistencies to long-horizon state tracking challenges.
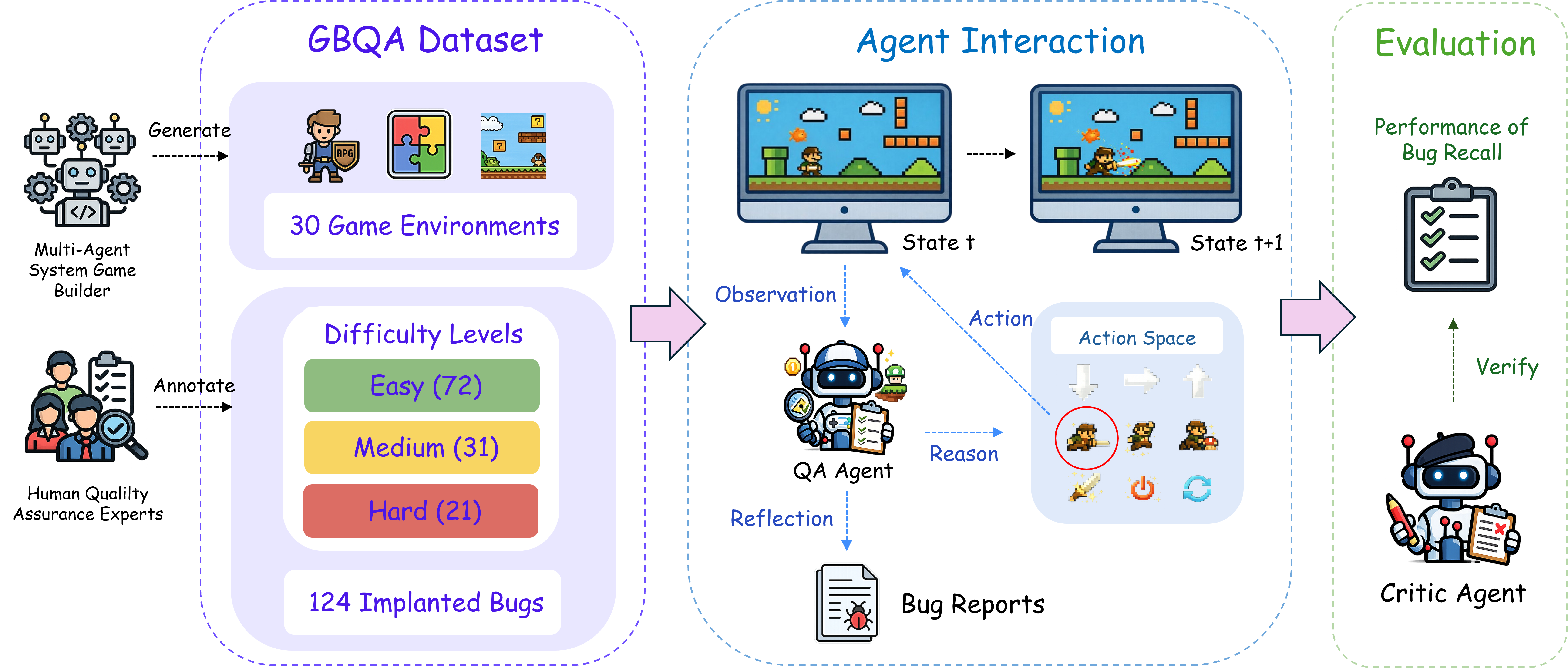
Figure 2: GBQA dataset and evaluation loop, with a multi-agent system generating 30 games and 124 annotated bugs. During evaluation, an LLM-based QA agent autonomously interacts, submits bug reports, and a critic agent quantitatively matches to ground-truth.
Baseline Agents: ReAct and Memory Architectures
A baseline QA agent is provided, formalizing the agentic bug discovery loop. Unlike task-completion or repair agents, this model deploys intertwined ReAct-style planning and acting interleaved with explicit reflection on expectation violation at every step. Critically, upon anomaly suspicion, the agent invokes a local verification phase, seeking reports that are robust to false positives and reproducible.
To address context constraints in long-horizon interactive testing, a dual-level hierarchical memory system is introduced: an in-session short-term memory supporting summarization of recent trajectories, and a cross-session memory serving experience abstraction across playthroughs. This enables systematic rather than stochastic exploration, informative verification, and sustained reasoning about stateful, temporally delayed inconsistencies.
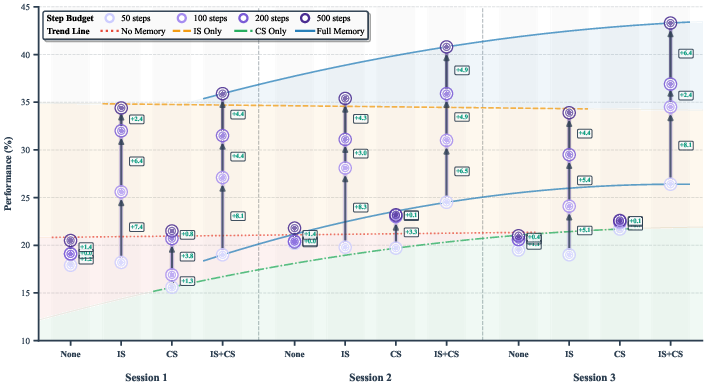
Figure 3: Ablation study of the memory module, demonstrating that the combination of in-session and cross-session memory avoids redundant exploration and supports superior long-horizon discovery—each session cluster shows step budget gains with increasing memory sophistication.
Experimental Results and Analysis
Empirical evaluations are conducted over a representative suite of contemporary LLMs—Claude-4.6-Opus(-Thinking), GPT-5.2, Gemini-3.1-Pro, DeepSeek-R1, Qwen3(-Coder-Next)—with testing under player-only and QA-informed regimes, across four step budgets (T=50,100,200,500). Their recall on GBQA is substantially lower than on recent code repair leaderboards (e.g., SWE-bench Verified), with the best result—Claude-4.6-Opus-Thinking—detecting only 48.39% of annotated defects at a 500-step budget.
Key findings include:
- Bug discovery remains unsolved: Even with comprehensive source access and extended exploration, all agents fail to detect over half of present bugs under realistic constraints, highlighting the intrinsic complexity and limitation of autonomous bug discovery as compared to guided code repair.
- Scaling law for reasoning: Incremental improvements are observed with both model scaling and more sophisticated inference-time capabilities ("thinking" variants), but increased weights alone trail behind deliberative reasoning enhancements.
- Significant difficulty gap: Easy bugs—those evident from direct observation—are largely exhausted within a few hundred steps, while hard bugs, which depend on aggregating long-term interaction context, essentially require orders of magnitude more exploration and remain mostly unsolved.
- QA mode advantage: Providing game specifications and code consistently boosts recall, but the effect is bounded by reasoning deficits, particularly around persistent state, planning, and systematic hypothesis testing.
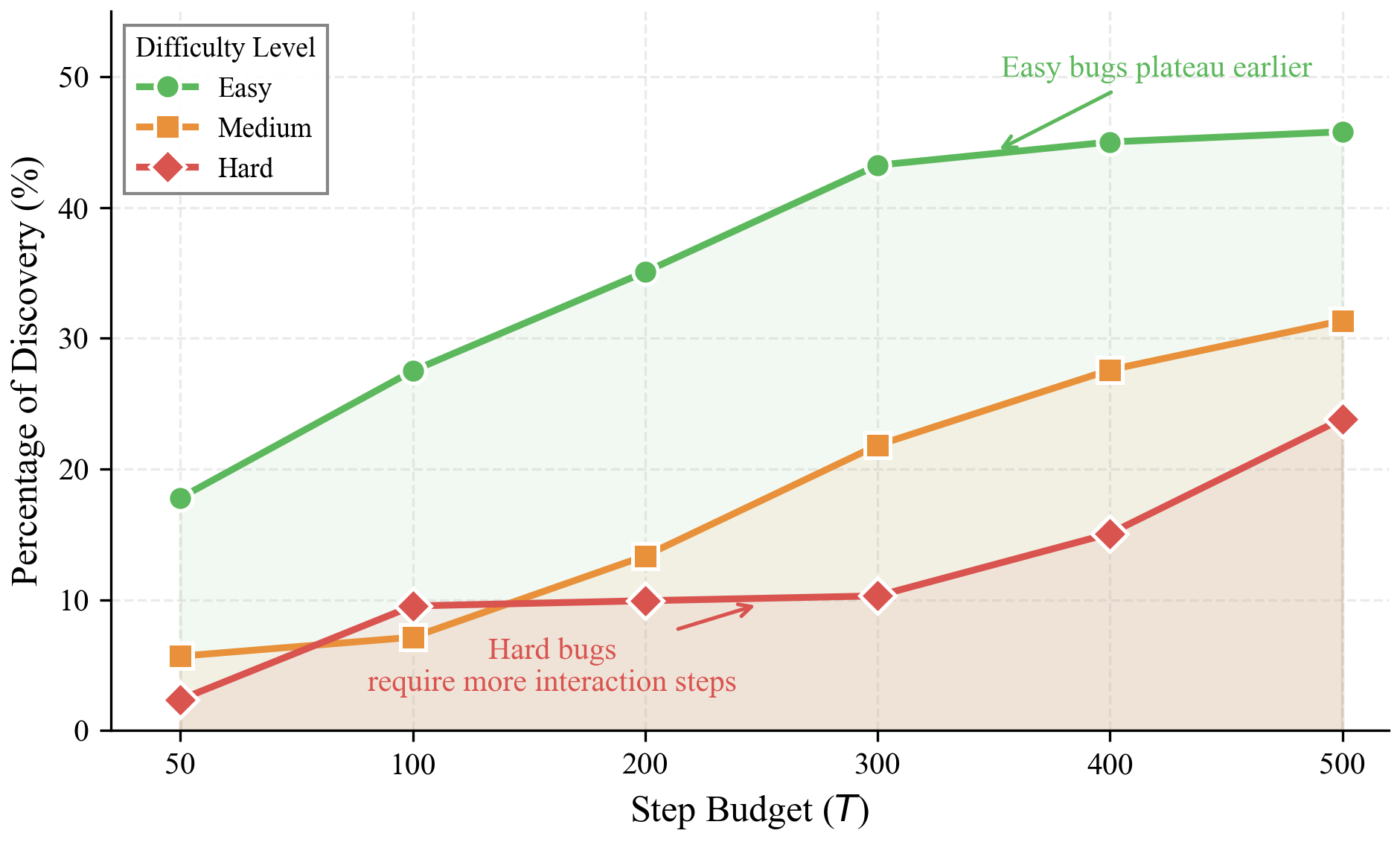
Figure 4: Percentage of bug discovery by difficulty level and step count, showing plateauing for easy bugs and an unsaturated, near-linear regime for hard bugs, affirming the heightened long-horizon challenge.
Comparison with Conventional Code Benchmarks
Frontier LLMs now routinely exceed 70–80% on code repair datasets such as SWE-bench Verified; however, their recall on GBQA is routinely less than half of that. This supports the paper’s claim that "bug discovery presents a fundamentally harder problem than issue-driven repair," as it involves unscripted state exploration, implicit anomaly recognition, and real-time hypothesis refinement rather than localization and patching of a known defect.
Benchmark Reliability and Evaluation Protocol
GBQA’s annotation and evaluation pipeline is robustly validated: inter-annotator agreement achieves Krippendorff's α=0.901, and the automated critic agent’s decisions exhibit high Pearson correlation with human raters (e.g., GPT-5.2 ρ=0.903, p≪0.0001), ensuring consistent and reliable assessment of discovered bugs.
Case Study: Autonomous Closed-Loop Development
A closed-loop case study demonstrates the feasibility of integrating GBQA’s discovery agent with a code repair agent (Claude Code), iteratively achieving 100% discovery and fix rates across three sessions on a representative environment. This highlights the viability of fully autonomous agentic development cycles, albeit contingent on more robust upstream discovery.
Implications and Future Directions
The introduction of GBQA exposes key research gaps in autonomous system-level QA. Practically, it provides a rigorous environment for experimentation on agentic strategies for systematic exploration, expectation inference, and specification-based anomaly detection. Theoretically, it sets an agenda for the development of memory-augmented agents, efficient credit assignment across interactions, and RL approaches attuned to QA task structure.
Looking forward, scaling GBQA beyond games to encompass broader, multimodal real-world applications, and augmenting LLMs with specialized QA RL or structured hypothesis-testing priors are clear next steps. The observed performance ceilings suggest that meaningful advances will require not just larger LLMs, but also new agentic architectures and training regimes specifically targeting open-ended bug discovery and long-horizon inference.
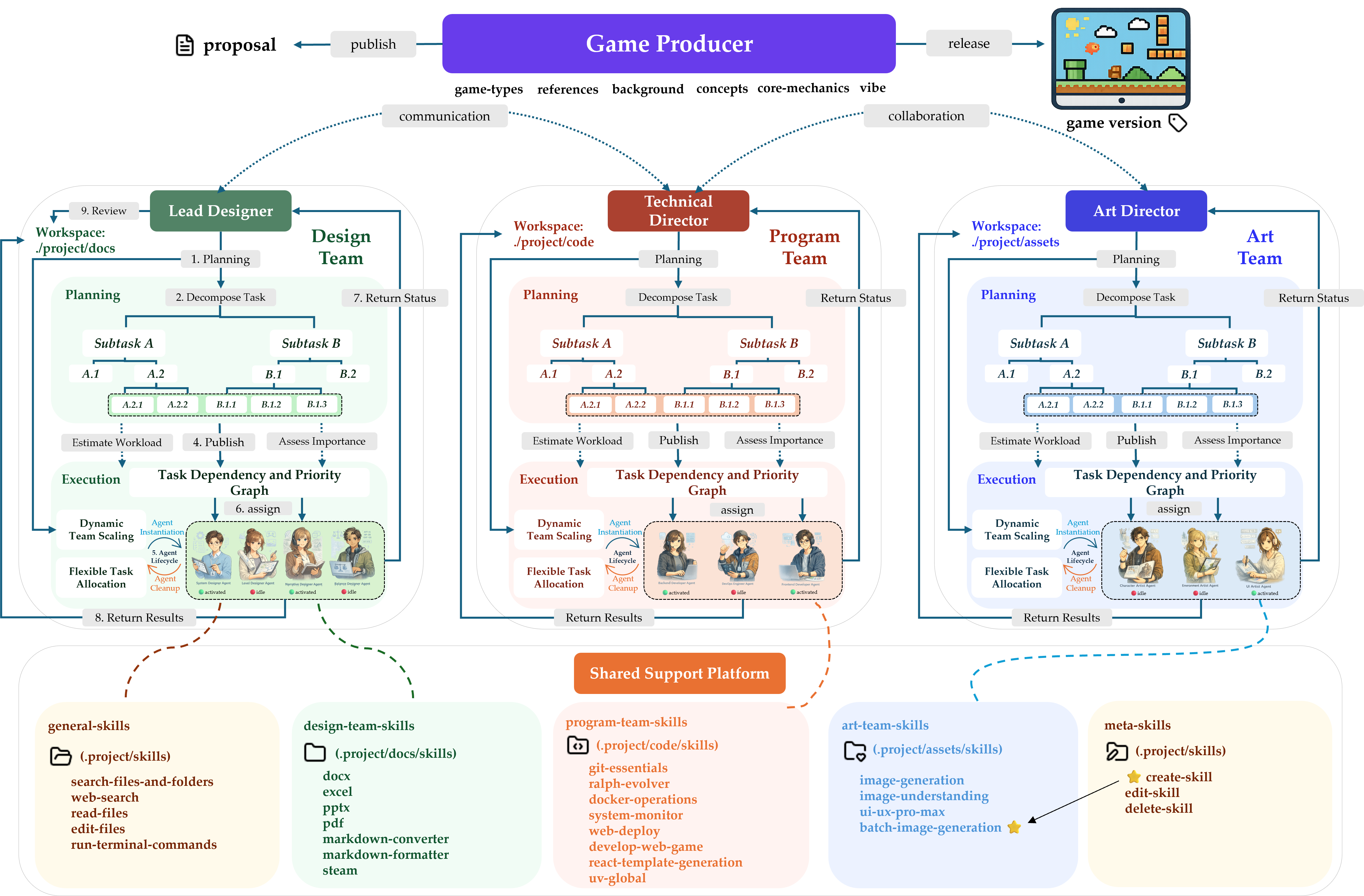
Figure 5: The Game Environment Builder’s architecture, showing the Producer Agent orchestrating modular, multi-agent development, enabling rapid, scalable benchmark generation with controllable bug complexity.
Conclusion
GBQA advances the evaluation of LLMs from guided code synthesis and repair toward genuinely autonomous software quality assurance. Substantial performance gaps with repair tasks underscore the open challenges in agentic bug discovery, particularly for dynamic, state-rich, and temporally entangled errors typical of complex software systems. The benchmark’s design, results, and accompanying analysis provide a principled foundation for the next generation of QA-centric reasoning agents and their integration into autonomous development pipelines.