- The paper reveals that AVLLMs effectively encode early audio cues but ultimately suppress them during deep cross-modal fusion, resulting in vision-dominant outputs.
- Attention knockout interventions show that removing visual bias significantly restores audio fidelity in counterfactual scenarios.
- The study uses rigorous adversarial audio-visual captioning tasks to demonstrate that latent audio understanding persists despite poor external audio outputs.
Mechanistic Interpretability of Audio-Visual LLMs: Analysis and Findings
Introduction and Motivation
Audio-Visual LLMs (AVLLMs) integrate vision and auditory modalities to extend LLM capabilities for real-world multimodal understanding, with potential applications across multimedia analysis, robotics, education, healthcare, and biodiversity monitoring. Despite architectural advancements, their internal mechanisms for audio-visual integration remain opaque, particularly regarding modality bias and reliability when handling conflicting cues. This paper provides the first mechanistic interpretability analysis of AVLLMs, dissecting modality fusion, representation evolution, and causal pathways in text generation. The fundamental concern addressed is whether AVLLMs genuinely perceive both modalities or disproportionately rely on vision—especially in scenarios where audio signals are vital yet visually absent.
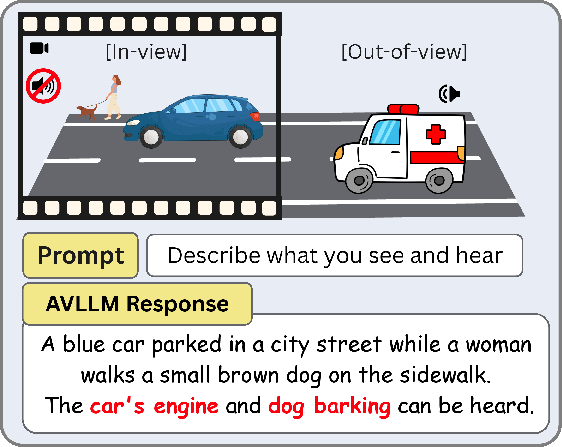
Figure 1: AVLLM hallucination example: visual cues dominate over an off-screen ambulance siren, causing the model to miss the siren and hallucinate irrelevant audio events.
Experimental Framework and Evaluation Design
To systematically probe AVLLM behavior, the study employs an audio-visual captioning task using factual (aligned) and counterfactual (conflicting) samples curated from AudioCaps, with human-annotated audio captions paired with GPT-4-generated video captions. Counterfactuals are synthesized by swapping audio tracks and minimizing semantic overlap using embedding similarity; this ensures rigorous stress-testing for modality-independent understanding.
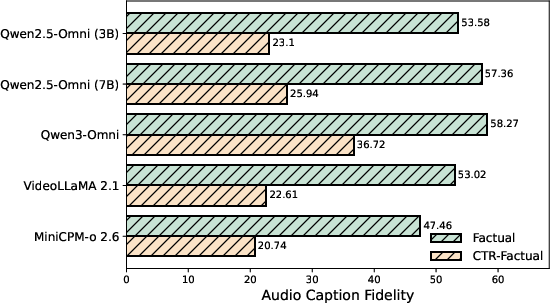
Figure 2: Quantitative degradation in audio understanding for counterfactual samples indicating severe bias under modality conflict.
Caption fidelity is evaluated using an LLM judge (Qwen3-32B) calibrated with in-context examples, measuring audio and video fidelity on a normalized scale. Spearman correlation with human scores is substantial (ρ=0.816 for audio, $0.732$ for video), validating metric reliability.

Figure 3: Illustration of LLM-based caption evaluation: explicit reasoning and interpreter scores for each modality.
Layerwise Attention Dynamics and Modality Integration
Attention analysis is conducted across transformer layers, quantifying generated token attention allocation to audio, vision, and query text tokens. Early layers (0–5) show substantial audio attention (40–50%), which collapses in deeper layers (<5%), while video token attention rises monotonically in middle and deep layers (up to 40%). Query tokens dominate attention globally, regardless of modality.
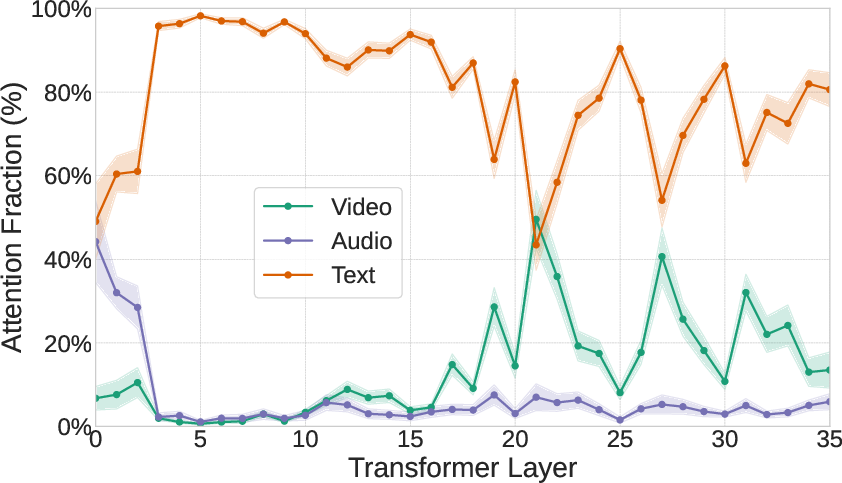
Figure 4: Mean attention allocation: audio attended early, vision intensifies in deep layers; query tokens always dominate.
This reveals an asymmetric integration: AVLLMs encode and process audio cues in preliminary layers but progressively suppress them during cross-modal fusion, privileging vision by default in later stages. This deeply impacts generated text, especially for audio-relevant prompts, where vision-driven hallucination or omission becomes prominent.
Internal Audio Representation and Latent Semantic Recall
Logit lens probing decodes audio token hidden states using the unembedding matrix at each layer, revealing that intermediate audio representations manifest meaningful concepts (sound sources, events, attributes) in multiple languages. Notably, this semantic encoding emerges in later layers, highlighting that audio semantics persist internally even when absent from the output text.
Figure 5: Decoded audio representations: internal tokens represent true audio events and sources in multiple languages, despite poor output fidelity.
Empirical findings show a large gap: whereas generated audio caption fidelity for counterfactuals is only 23%, latent recall from intermediate representations reaches 61.4%. Thus, AVLLMs retain rich audio information but fail to harness it in final text generations due to cross-modal suppression downstream.
Attention knockout interventions were performed by zeroing cross-modal attention weights from generated tokens to audio or vision at specified layers. Results are evaluated separately for factual and counterfactual samples, and with modality-specific prompts (“describe what you see” vs. “describe what you hear”).
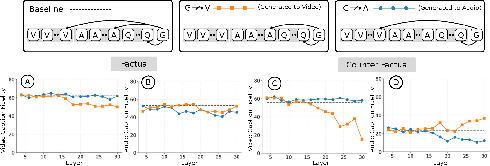
Figure 6: Ablation of attention pathways reveals visual dominance and suppression of audio integration; visual knockout recovers latent audio understanding.
In factual settings, blocking audio yields negligible loss in video understanding, while blocking vision or audio in audio-specific tasks only slightly degrades performance, evidencing strong cross-modal compensatory mechanisms. In counterfactuals, blocking vision in deep layers dramatically restores audio fidelity (up to 50% recovery), directly demonstrating that visual features actively hinder audio processing during deep fusion.
Token Distribution Analysis and Origins of Modality Bias
Token distribution comparison between AVLLMs (Qwen2.5Omni) and vision-language base models (Qwen2.5VL) using KL divergence and rank metrics shows striking similarity: KL divergence is only 0.4, with 66% of audio-related tokens generated by AVLLMs being top predictions from LVLMs. This confirms that AVLLM outputs are largely vision-predicted even when audio input is present. Authentic audio-grounded tokens, when generated, deviate from LVLM distributions, but such deviances are rare—visual cues overwhelmingly drive predictions.

Figure 7: Distribution comparison: AVLLM token choices almost always match vision-only LVLMs; genuine audio integration is rare and reflected only in shifted tokens.
Qualitative analysis shows that AVLLMs hallucinate audio events based on visible objects, and even explicit audio prompts result in visual descriptions unless visual pathways are blocked.
Dataset Construction and Benchmark Analysis
To ensure adversarial rigor, counterfactual samples were curated algorithmically with embedding-based caption similarity thresholds; the methodology ensures maximally dissimilar audio-visual combinations for robust evaluation. Existing benchmarks (World Sense, AVHBench) fail to induce sufficient cross-modal conflict, often conflating reasoning and perception or lacking adversarial mismatches that would expose modality bias.


Figure 8: Example factual sample: strong audio-visual correlation allows inference from vision.

Figure 9: World Sense tasks: perception and reasoning conflate, masking modality-specific failures.

Figure 10: AVHBench tasks: insufficient modality mismatch fails to induce perceptual bias.
Generalizability Across AVLLM Architectures
The mechanistic patterns identified here (early audio encoding, deep visual dominance, latent audio recall, attention knockout restoration, token distribution bias) persist across representative AVLLMs, including MiniCPM-o2.6 and VideoLLaMA 2.1. Minor architectural differences, such as multilingual capacities, alter fine-grained latent representations but not the overarching bias phenomenon. In all cases, attention knockout restores audio fidelity for counterfactuals, confirming robustness and generality of findings.
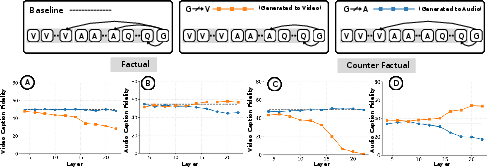
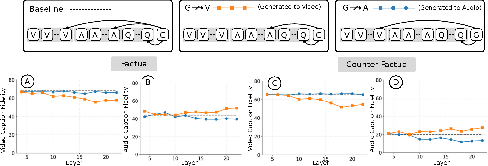
Figure 11: Visual pathway knockout in VideoLLaMA restores audio fidelity for counterfactual samples.
Qualitative Examples and Interpretability
Additional qualitative outputs (VideoLLaMA, MiniCPM) under factual/counterfactual and knockout conditions showcase persistent visual bias and the efficacy of attention knockout in restoring correct audio understanding.

Figure 12: VideoLLaMA outputs: deep layers induce visual bias, knockout restores audio reasoning.

Figure 13: MiniCPM outputs: similar visual dominance and restoration via attention manipulation.
Conclusion
This paper provides an in-depth mechanistic interpretability analysis of AVLLMs, revealing that although latent audio understanding is well-encoded at intermediate stages, models fail to manifest this knowledge in final outputs due to deep visual dominance and suppression. The bias originates primarily from LVLM initialization and vision-heavy instruction tuning, not architectural constraints. Attention knockout and counterfactual evaluation methodologies expose and potentially mitigate these modality imbalances.
Implications include the need for:
- Modality-balanced training and counterfactual data to reduce visual priors.
- Mechanistic interpretability interventions for auditing and debiasing AVLLMs in critical applications.
- Future research into regularization strategies at the transformer level and scalable counterfactual dataset curation for robust multimodal evaluation.
The findings highlight theoretical limitations in current AVLLM designs and training regimes, while proposing actionable directions for improving multimodal reasoning reliability and transparency in advanced AI systems.

