- The paper integrates advanced vision-language models with an adaptive PID-Tversky loss to address class imbalance in lumbar spinal stenosis segmentation.
- It demonstrates high diagnostic accuracy, robust segmentation (Dice > 0.95), and effective radiology report generation via an automated ARRG module.
- The approach offers explainability and highlights trade-offs between model complexity and clinical scalability for improved diagnostic support.
An Explainable Vision-LLM Framework with Adaptive PID-Tversky Loss for Lumbar Spinal Stenosis Diagnosis
Introduction
This work presents a comprehensive end-to-end framework combining advanced vision-LLMs (VLMs) with principles from control theory to optimize the diagnosis of lumbar spinal stenosis (LSS) using MRI. The key contributions are the integration of multimodal clinical and imaging information, the development of a Spatial Patch Cross-Attention mechanism for enhanced anatomical localization, a control-theoretic Adaptive PID-Tversky loss function to explicitly address severe class imbalance in segmentation, and an Automated Radiology Report Generation (ARRG) module enabling explainable AI outputs.
Methodological Advancements
The framework leverages three VLMs: BiomedCLIP, LLaVA-Med, and SmolVLM. MRI scans are preprocessed via non-local means denoising and class rebalancing through controlled augmentation. Pseudo-masks are generated via a hybrid of Otsu’s thresholding, Canny edge detection, and morphological refinements conditioned on both image content and natural language clinical reports.
Central to the architecture is the Spatial Patch Cross-Attention module, where dense ViT patch embeddings (excluding [CLS]) are fused with tokenized clinical prompts. This module uses an 8-head architecture, achieving a precise mapping of complex clinical semantics to spatially explicit imaging regions, overcoming limitations from standard global pooling approaches.
The Adaptive PID-Tversky loss employs a PID controller on epoch-level false positive (FP) and false negative (FN) rates to modulate Tversky alpha and beta weights, tightly focusing optimization on ambiguous boundaries particularly in minority (e.g., severe) classes, and dynamically reducing bias toward the dominant class.
The ARRG module generates structured reports directly from segmentation outputs, mapping affected area estimates to clinical severity templates and synthesizing natural language summaries via autoregressive modeling. The system thus links quantitative spatial evidence to qualitative clinical reasoning.
Experimental Results
Severity Classification
LLaVA-Med attains a diagnostic accuracy of 90.69%, macro-F1 of 0.9072, and AUCs approaching 0.993 for severe cases, outperforming SmolVLM by a statistically significant margin (p < 0.001, McNemar’s test). Both BiomedCLIP and SmolVLM perform robustly for clear-cut normal and severe classes but show reduced reliability for intermediate (B/C) grades, highlighting consistent challenges distinguishing subtle morphological variance.
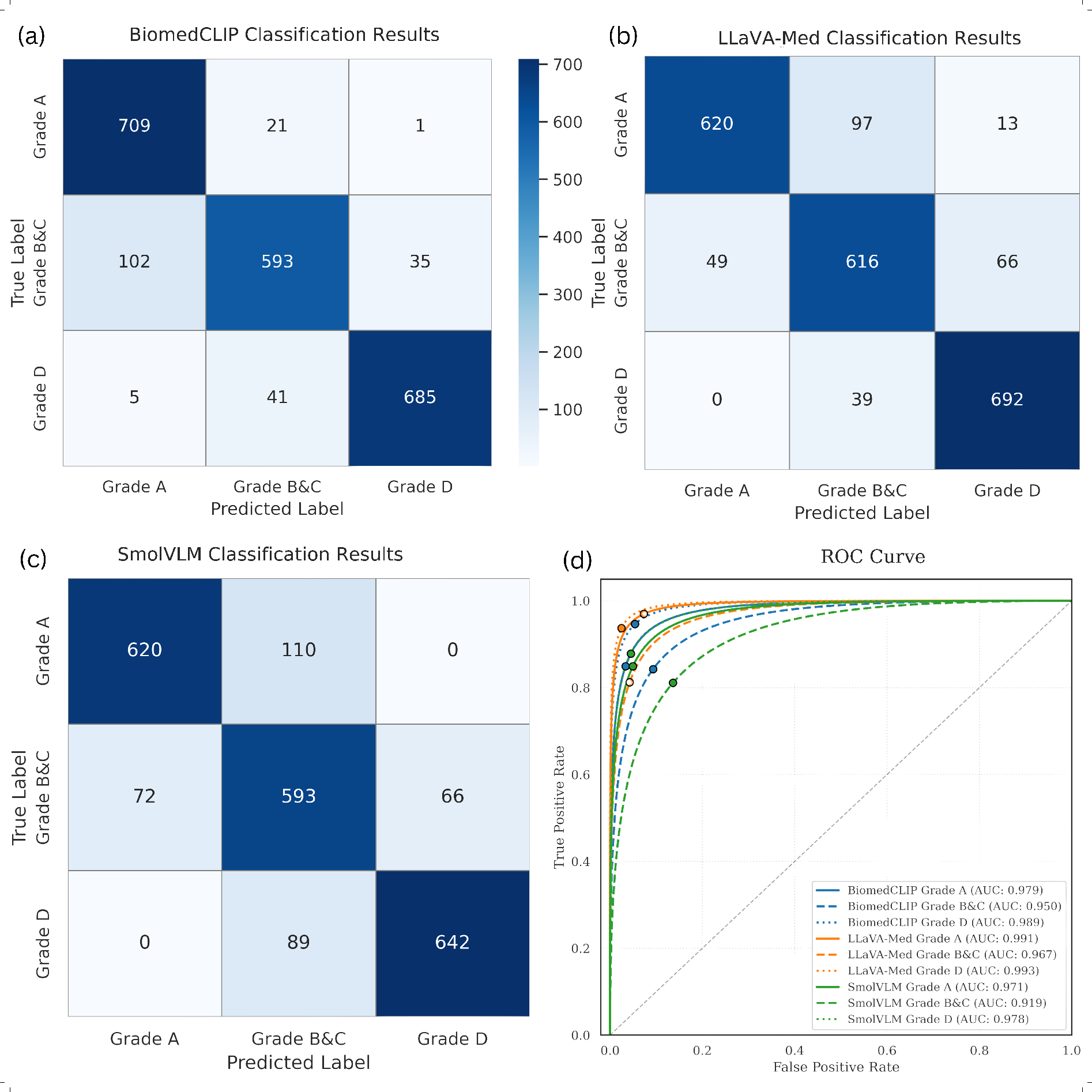
Figure 2: Classification performance and ROC analysis for BiomedCLIP, LLaVA-Med, and SmolVLM, illustrating high discrimination but cross-model variance on mild-to-moderate classes.
LLaVA-Med achieves a Dice coefficient of 0.9624 (95% CI: 0.951-0.973), with BiomedCLIP close behind (0.9512), both substantially outperforming SmolVLM (0.8603). These models demonstrate the advantage of retaining localized spatial features via patch-based cross-attention. Severe (Grade D) and normal (Grade A) presentations are identified with up to perfect recall, while performance for mild/moderate grades (Grades B/C) shows material degradation, particularly in BiomedCLIP (Dice drop of 0.0851).
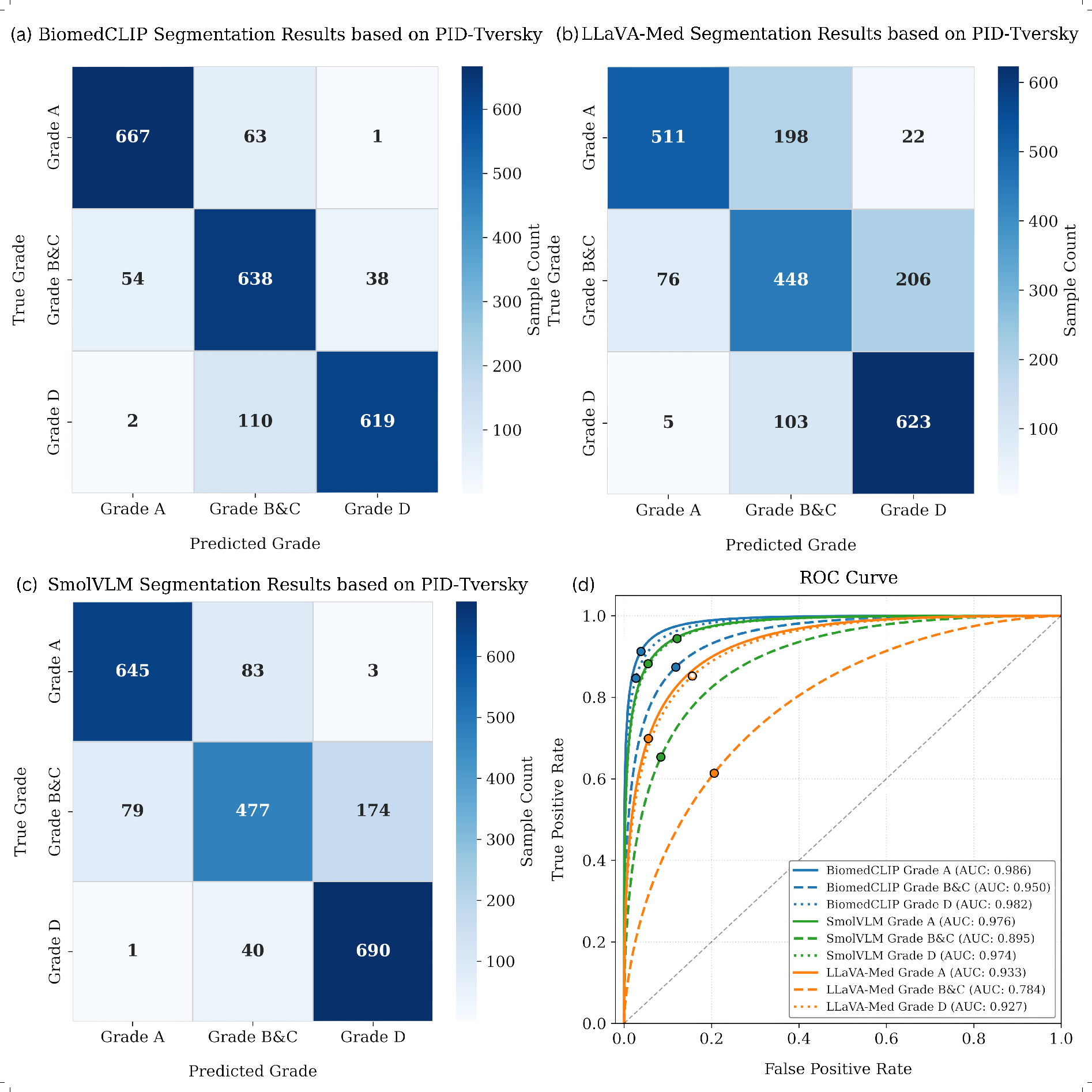
Figure 1: Segmentation-derived confusion matrices and ROC curves display model sensitivity to subtle grade transitions, with LLaVA-Med and BiomedCLIP demonstrating strong spatial discrimination.
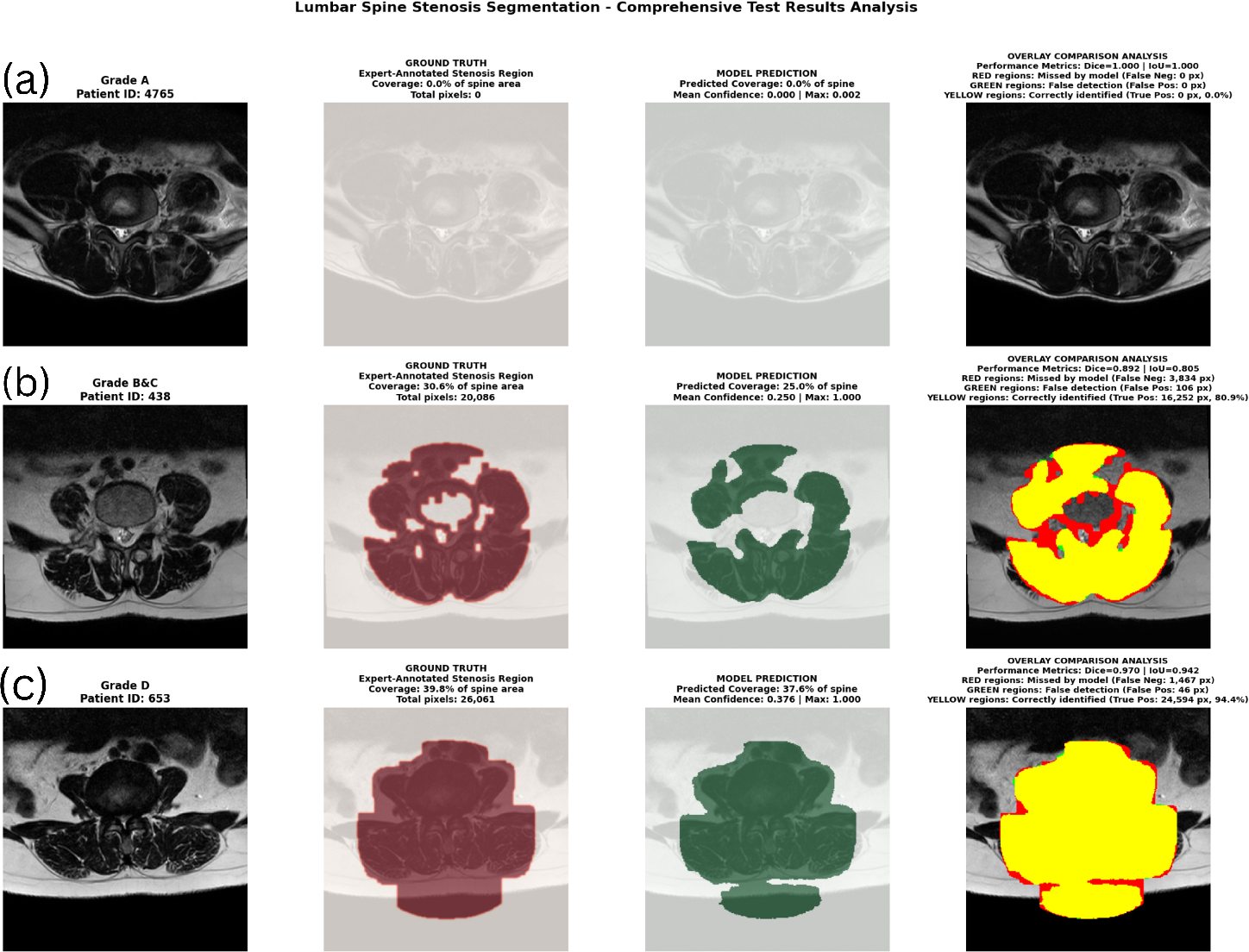
Figure 3: Detailed pixel-level overlays for BiomedCLIP show near-perfect matching in normal and severe cases, with major errors localized to ambiguous anatomical boundaries in intermediate grades.
Radiology Report Generation
The ARRG module—benchmarked across BLEU, METEOR, ROUGE, CIDEr, and Jaccard scores—demonstrates that LLaVA-Med leads in report fluency and semantic alignment (CIDEr 92.8%), closely trailed by SmolVLM (90.94%). BiomedCLIP lags linguistically but excels in report-grounded severity classification (AUC Grade A: 0.984). Notably, SmolVLM achieves the highest Dice (0.984) for implicit segmentation when generating reports for Grade D, highlighting its capacity in spatial grounding.
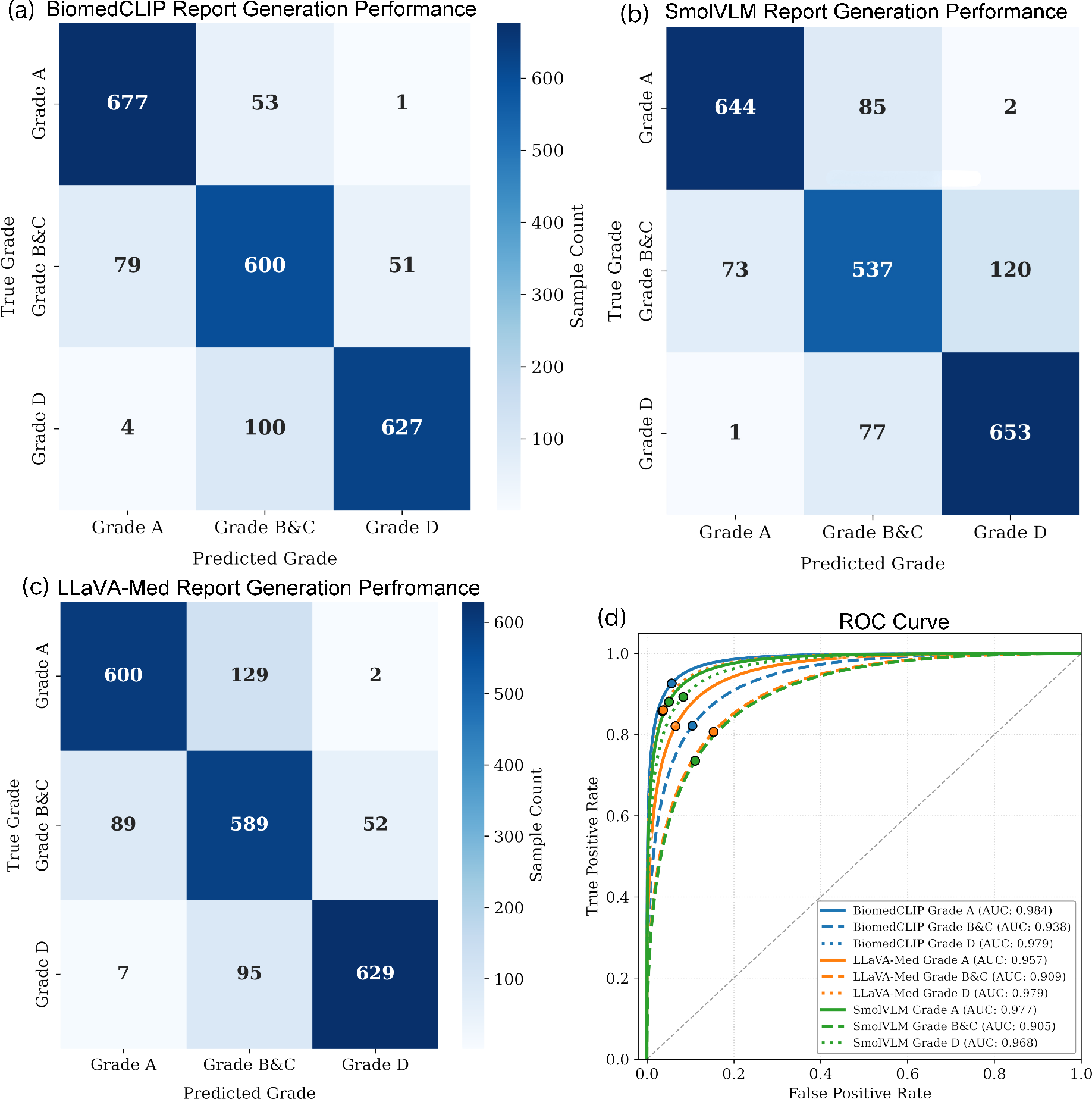
Figure 4: Confusion matrices and ROC curves for automated reports show high model consistency for severe/normal diagnoses; discrepancies emerge in linguistically and anatomically ambiguous cases.
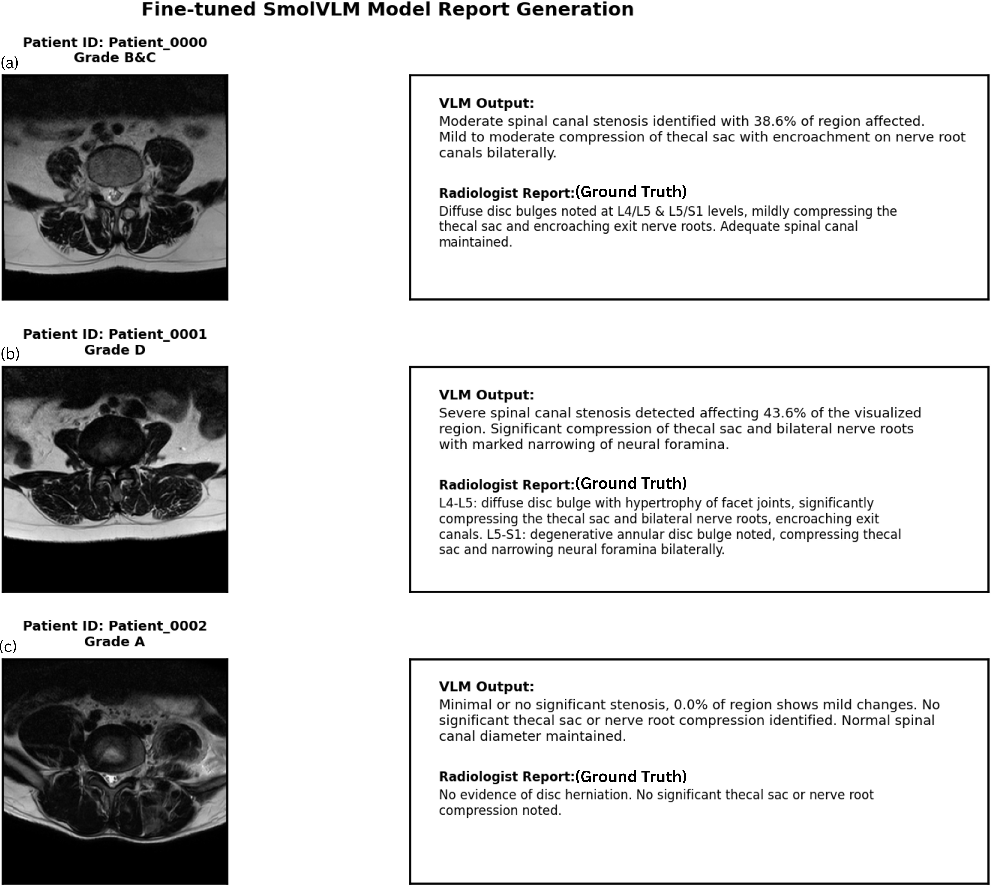
Figure 5: Qualitative side-by-side comparisons indicate high correspondence of SmolVLM-generated reports with radiologist ground truth across all severity grades.
Adaptive Loss Function Efficacy
Ablation studies confirm the PID-Tversky loss’s effectiveness, yielding improvements up to +0.21 Dice and +0.20 IoU for BiomedCLIP over cross-entropy baselines. These gains are directly attributed to the dynamic mitigation of class imbalance and improved attention to challenging (minority) clinical categories.
Discussion
The integration of VLMs with adaptive loss paradigms achieves both high quantitative accuracy and model output interpretability—critical for deployment in clinical decision support. Large-scale models like LLaVA-Med reach peak pixel-level performance but at increased computational cost, impacting clinical scalability. In contrast, SmolVLM offers computationally efficient inference with lower—but consistent—segmentation reliability. Across all models, discrimination between extremes (normal vs. severe) is robust, but intermediate verdicts remain challenging, aligning with the fundamental morphological ambiguity inherent in early-stage LSS.
The ARRG’s capacity for nuanced language generation is directly coupled to spatial segmentation performance, with model linguistic expressivity mapping onto visual evidence. Human-in-the-loop oversight remains essential to address factual errors and maintain clinical safety, underscoring that explainability in AI augments, rather than replaces, expert analysis.
Future directions include expansion to multi-modal and multi-sequence MRI, external validation, and domain adaptation—each essential for the translational impact of framework deployment. Attention remains on rigorous regulatory compliance and maximizing the synergy between automated models and radiologist input, especially in ambiguous diagnostic contexts.
Conclusion
This study establishes a new technical paradigm for the automated, interpretable diagnosis of lumbar spinal stenosis. By synergizing multimodal vision-language learning, spatially resolved cross-attention, and dynamically controlled segmentation loss, the framework achieves high diagnostic performance (Dice 95.12%), robust linguistic reportability, and explainable linkage between quantitative and qualitative clinical data. Deployment of such architectures will drive advances across medical imaging, raising both the standard of diagnostic accuracy and clinical interpretability while ensuring human expertise remains central to decision-making.
(2604.02502)

