- The paper introduces a dual-bottleneck model that hierarchically maps image features to human-understandable concepts for improved interpretability in classification.
- It employs label-free concept generation using GPT-4 and CLIP-based methods, achieving competitive accuracy on benchmarks like ImageNet and CIFAR-100.
- Consistency objectives, including Grad-CAM based visual alignment and tree-path KL divergence, ensure semantic coherence across abstraction levels.
Hierarchical, Interpretable, Label-Free Concept Bottleneck Model: Expert Summary
Introduction and Motivation
The "Hierarchical, Interpretable, Label-Free Concept Bottleneck Model" (HIL-CBM) (2604.02468) advances the paradigm of concept-based interpretability in deep neural networks by introducing an architecture that explicitly models hierarchies in both the concept and label spaces. Traditional Concept Bottleneck Models (CBMs) provide post-hoc or intermediate interpretability by mapping features to human-understandable concepts, using them as sufficient statistics for class predictions. However, existing CBMs are generally limited to a single level of semantic abstraction, hindering their ability to mirror hierarchical, multi-level human reasoning.
HIL-CBM addresses this limitation by enabling prediction and explanation at multiple semantic abstraction levels—without requiring annotated relational labels for concepts. This is achieved via a dual-bottleneck architecture, joint consistency objectives in both the visual and label spaces, and automated concept set construction using LLMs and CLIP-based methods. The resultant model better reflects the cognitive process by which humans first categorize entities at basic levels before refining their identification using more specific features.

Figure 1: HIL-CBM extends the CBM architecture to a hierarchy, with upper-level concepts and labels capturing general semantics and lower-level ones focusing on specificity.
Model Architecture
HIL-CBM is constructed atop a pre-trained vision encoder (e.g., ResNet, ViT-CLIP). Two projection layers—concept bottleneck layers—map image embeddings into interpretable concept spaces aligned with different abstraction levels. The upper layer focuses on general features for broad class categorization, while the lower layer captures specific features for fine-grained identification. Each layer feeds into a sparse classifier outputting predictions at its respective hierarchy level.
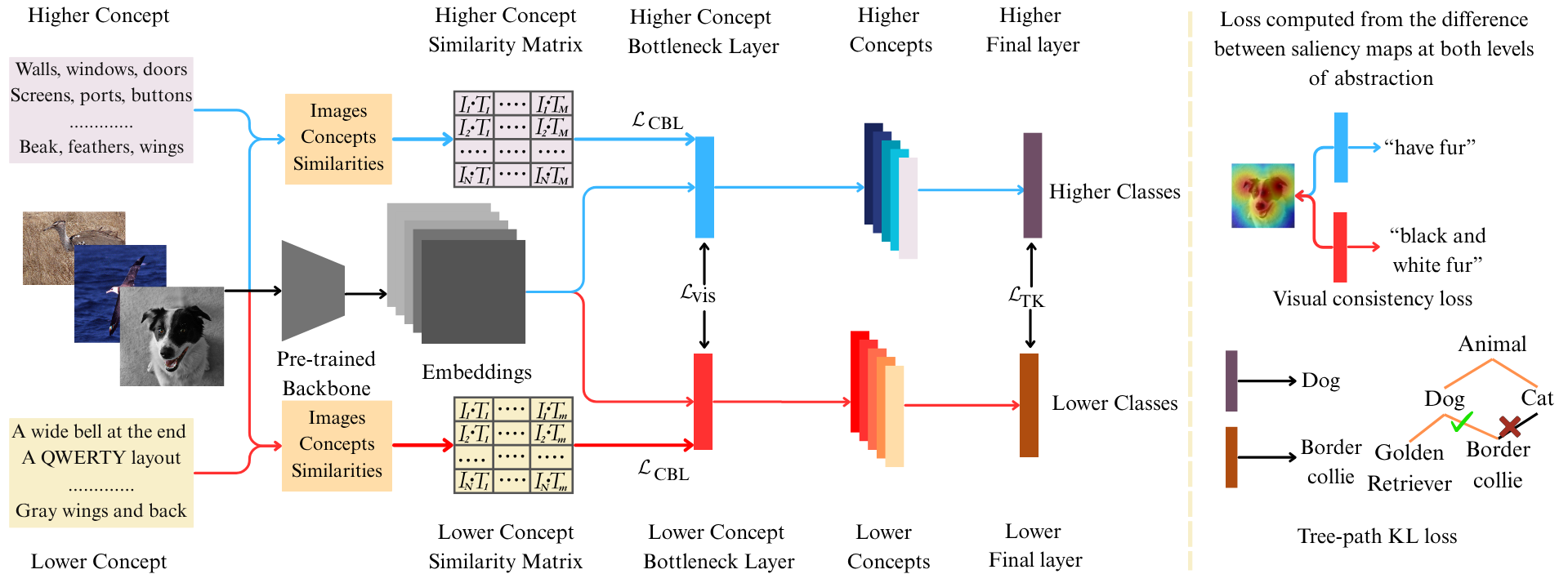
Figure 2: Overview of HIL-CBM: image encodings are projected into dual hierarchical concept spaces, each trained for interpretability and consistency, culminating in two classification heads for multi-level prediction and explanation.
Concept Generation
Label-free concept supervision leverages GPT-4 to generate feature concepts pertinent to both basic- and subordinate-level classes, further filtered for quality and relevance. CLIP-Dissect is employed to align image- and text-based concept embeddings, leveraging cubic cosine similarity to optimize projection parameters.
Consistency Objectives
Visual Consistency Loss: To ensure that both concept bottlenecks ground their abstractions in similar spatial image regions, a gradient-based alignment is used. Specifically, Grad-CAM saliency maps generated from each concept layer are compared via an MSE loss, tightly coupling the spatial focus across the hierarchy.
Semantic Consistency Loss: To enforce taxonomic coherence in predictions, a Tree-path KL divergence loss penalizes inconsistent class assignments across the hierarchy. This ensures, for instance, that subordinate-level "Golden Retriever" predictions are always aligned with the parent class "Dog," maintaining consistency in the hierarchical output.
Sparsity: Both concept and classifier linear layers adopt elastic net regularization to incentivize sparsity, which further bolsters interpretability and prevents over-reliance on spurious features.
Empirical Evaluation
Classification Accuracy
HIL-CBM demonstrates superior or comparable accuracy to state-of-the-art CBMs on CIFAR-100, CUB-200, Places365, and ImageNet benchmarks under both sparse and dense classifier settings. Notably, these gains are present without explicit relational or region-level supervision, highlighting the efficacy of hierarchical structuring and joint optimization.
Key quantitative results:
- CIFAR-100: 69.50% (lower) / 73.55% (higher)
- ImageNet: 75.54% (lower) / 81.50% (higher)
- Marginal gains over LF-CBM and SALF-CBM under comparable sparsity.
- With ViT-based backbones, performance remains competitive with coarse-to-fine and feature-driven models.
Ablation Studies
A comprehensive set of ablations isolates the contributions of visual and semantic consistency losses:
- Both losses independently and jointly increase accuracy and hierarchical consistency.
- Grad-CAM-based MSE loss outperforms IoU-based alternatives for promoting visual alignment.
- Tree-path KL loss yields higher rates of model- and ground-truth-consistent predictions, with improvements up to 3.65% in model consistency on ImageNet.
Increasing the concept "budget" in single-level models yields only negligible accuracy improvement, indicating that hierarchy—not sheer concept count—is responsible for observed gains.
Interpretability and Explanation
Extensive qualitative and quantitative evaluation underscores HIL-CBM's interpretability advancements:
- User Studies: Human evaluators rated HIL-CBM’s explanations as systematically more understandable and accurate than those from strong single-level baselines such as LF-CBM, with mean Likert scores increasing from 2.85 to 3.39 (understandability) and from 2.84 to 3.38 (accuracy).
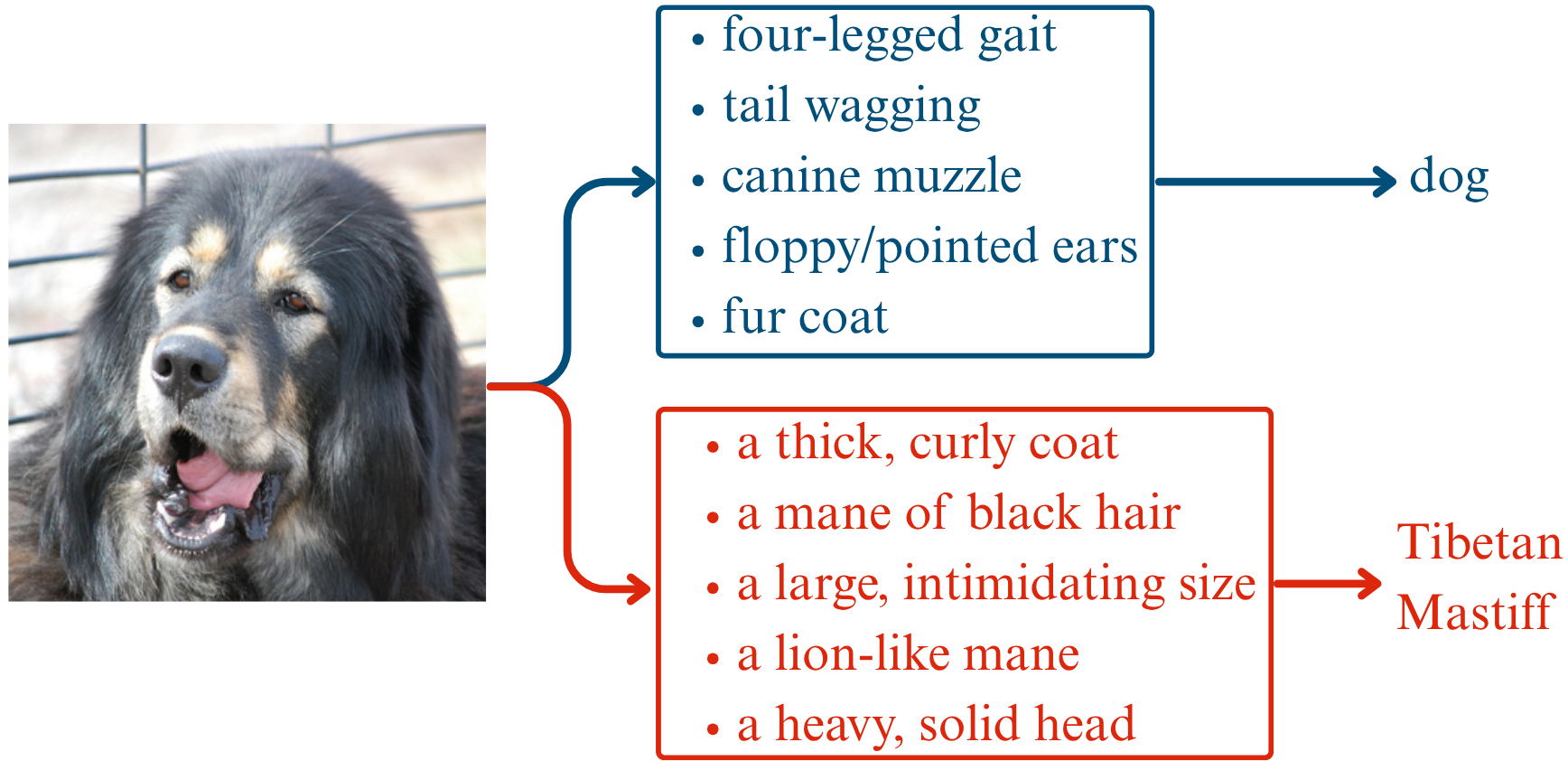
Figure 3: Example of hierarchical multi-level prediction and explanation from HIL-CBM, with concept-based rationales presented at each abstraction level to map model reasoning from general to specific.
- Hierarchical Debugging: The explicit separation of abstraction levels facilitates targeted model intervention. By editing concept-class weightings within each classifier head, domain experts can modify or correct predictions at the appropriate semantic granularity.
- Counterfactual Analysis: The dual-level prediction enables structured counterfactual queries within superclasses (e.g., "What if this dog had different fur color?"), a feature of fundamental importance for trustworthy AI.
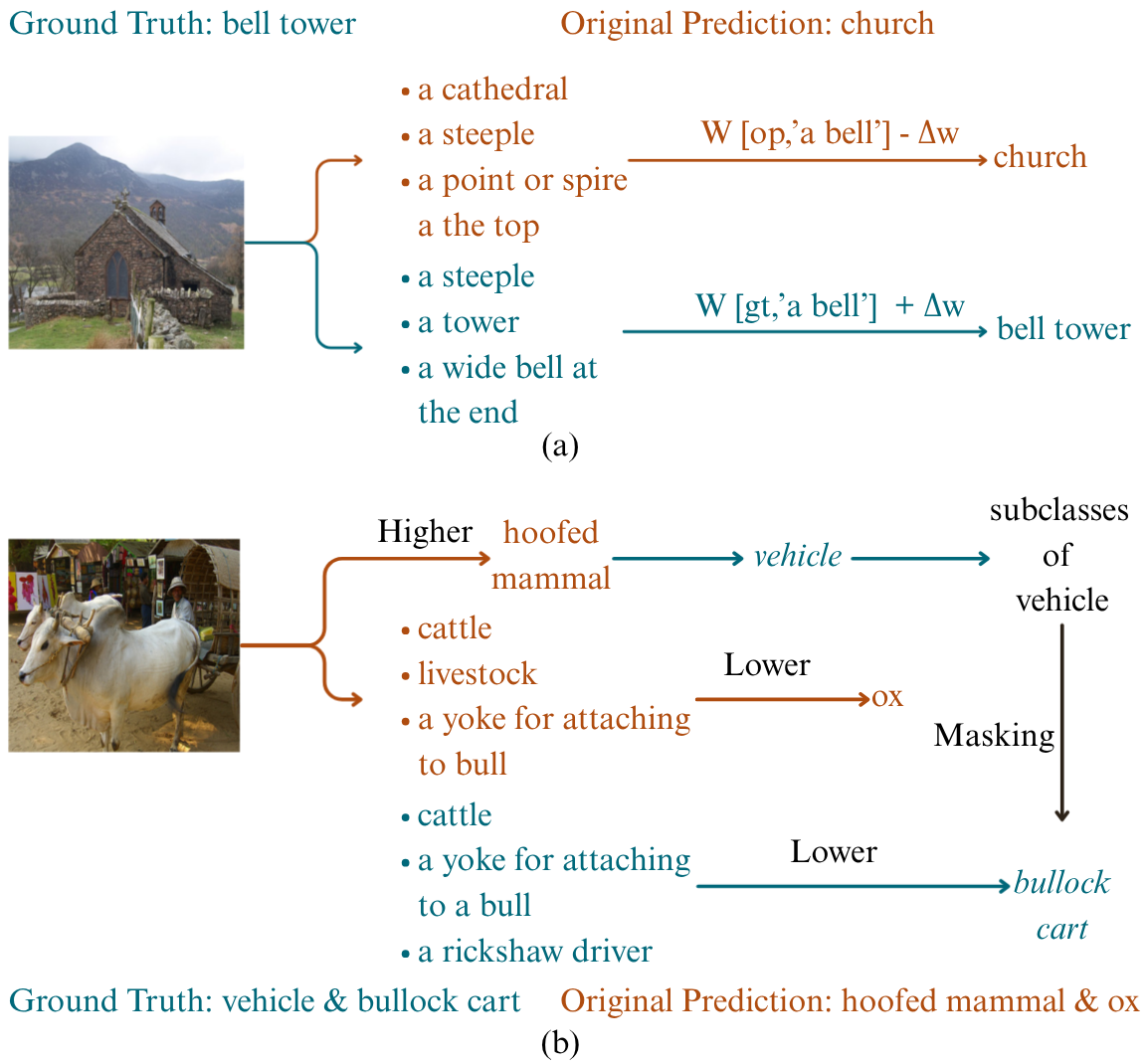
Figure 4: Visualized hierarchical error diagnosis and debugging workflows enabled by HIL-CBM; experts can intervene at coarse or fine levels to guide the network toward semantically consistent corrections.
Implications and Future Directions
Practically, HIL-CBM demonstrates that interpretable AI systems need not compromise performance for transparency. Its label-free, multi-layer concept bottlenecks provide a scalable template for constructing explainable models for large-scale, taxonomically structured datasets, especially where feature or relational supervision is infeasible.
Theoretically, the model bridges gaps between hierarchical image classification and concept-based interpretability. Its hierarchical bottlenecking opens avenues for the integration of further abstraction levels, seamless model debugging, and more sophisticated counterfactual and monotonicity constraints.
Potential developments include:
- Extension to deeper taxonomic hierarchies and more complex label structures
- Adaptation to multimodal or non-visual domains (e.g., medical diagnostics, science)
- Automated concept set expansion and clustering guided by active human feedback
Conclusion
HIL-CBM operationalizes a hierarchical, interpretable framework for deep image recognition, integrating concept bottleneck methodology with explicit hierarchical modeling and consistency constraints. Empirical validation confirms that the model secures enhanced fidelity, semantic consistency, and explanation quality while remaining annotation efficient and amenable to expert intervention. Future work could further generalize these findings to advance the integration of interpretable reasoning into large-scale, real-world AI systems.

