- The paper introduces a novel framework that integrates render-based visual scoring with Direct Preference Optimization (DPO) for cinematic camera trajectory synthesis.
- It leverages a cyclic semantic similarity mechanism via a vision-language model to ensure consistent subject framing and robust composition in rendered scenes.
- Quantitative evaluations show a reduction in off-screen frames from up to 80.3% to nearly 0%, demonstrating improved visual fidelity and narrative adherence.
VERTIGO: Visual Preference Optimization for Cinematic Camera Trajectory Generation
Introduction
Cinematic camera trajectory generation is constrained by the inherent disconnect between geometric camera motion synthesis and the perceptual evaluation of shot quality. Existing generative systems can model text-conditioned distributions over camera paths but lack explicit visual feedback mechanisms necessary to enforce narrative adherence, subject framing, and compositionally robust outputs. The absence of a "director-in-the-loop" restricts current approaches to geometric plausibility, resulting in models with high trajectory fidelity but poor visual outcomes, such as off-screen characters or unstable framing.
VERTIGO introduces a framework bridging this gap by aligning camera trajectory generators with visual feedback post-training. The core methodology leverages fast graphics engine-based renders (Unity) to reify motion into visual preview sequences, which are then scored using a vision-LLM (VLM) via a novel cyclic semantic similarity mechanism. The resulting preference signals are employed for Direct Preference Optimization (DPO), yielding a generator explicitly tuned for downstream perceptual quality in both CG and generative pipelines.
Methodology
The VERTIGO pipeline operates in three stages: trajectory synthesis, render-based visual scoring, and preference-driven post-training.
Trajectory Generation and Dataset
VERTIGO formalizes camera planning as a conditional generation problem. The generator, πθ(τ∣p,c), is trained on LenScript—a procedurally constructed, Unity-based dataset with 120K trajectories comprehensively annotated along five cinematographic axes (motion, scale, direction, angle, screen property) and paired with natural language descriptions. This enables both supervised learning of motion primitives and fine-grained semantic discrimination.
Trajectories are instantiated as 3D sequences, rendered in diverse Unity scenes to create preview videos. This real-time rendering ensures that perceptual evaluation is scene-consistent and efficient.
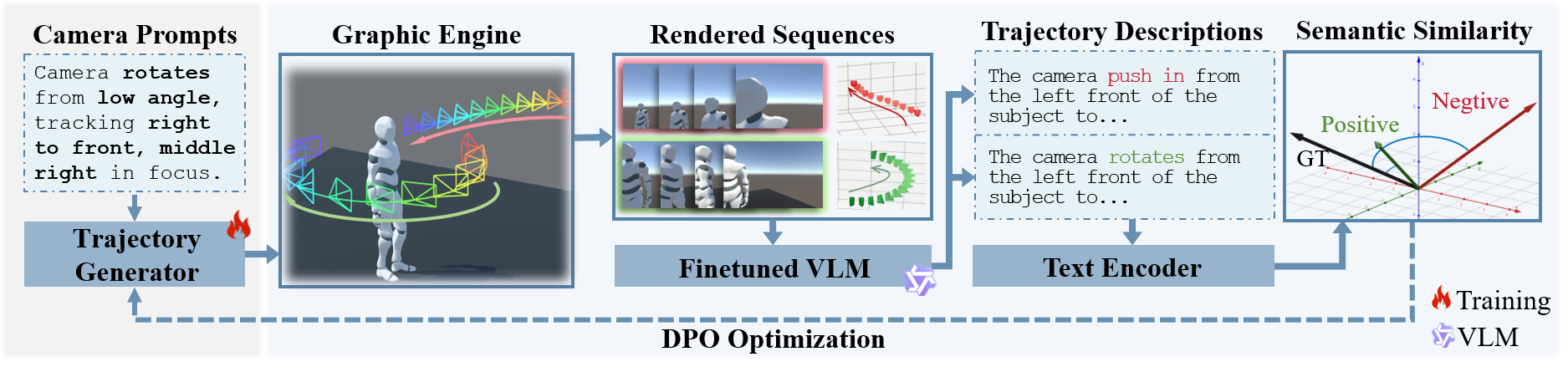
Figure 1: End-to-end VERTIGO pipeline illustrating transformation from text prompt to 3D trajectory, rendering, VLM-based semantic scoring, and DPO.
Visual Preference Scoring
Given the disconnect between geometric paths and perceptual quality, VERTIGO establishes a preference model through three VLM-based scoring strategies:
- Tag-consistency: Counts dimensional matches between targets and generated shots via VLM classification.
- Scalar Regression: Aggregates the quality signal into a single value using interpolated trajectories and RAFT-style regression.
- Cyclic Semantic Scoring: The VLM acts as an inverse cinematic reasoner, captioning the realized trajectory render. Caption and input prompt embeddings are compared for latent-space cosine similarity, providing a semantically aligned, continuous preference score.
Empirically, cyclic semantic scoring demonstrates superior granularity, avoiding the mode collapse and poor discriminative capacity of the other approaches.
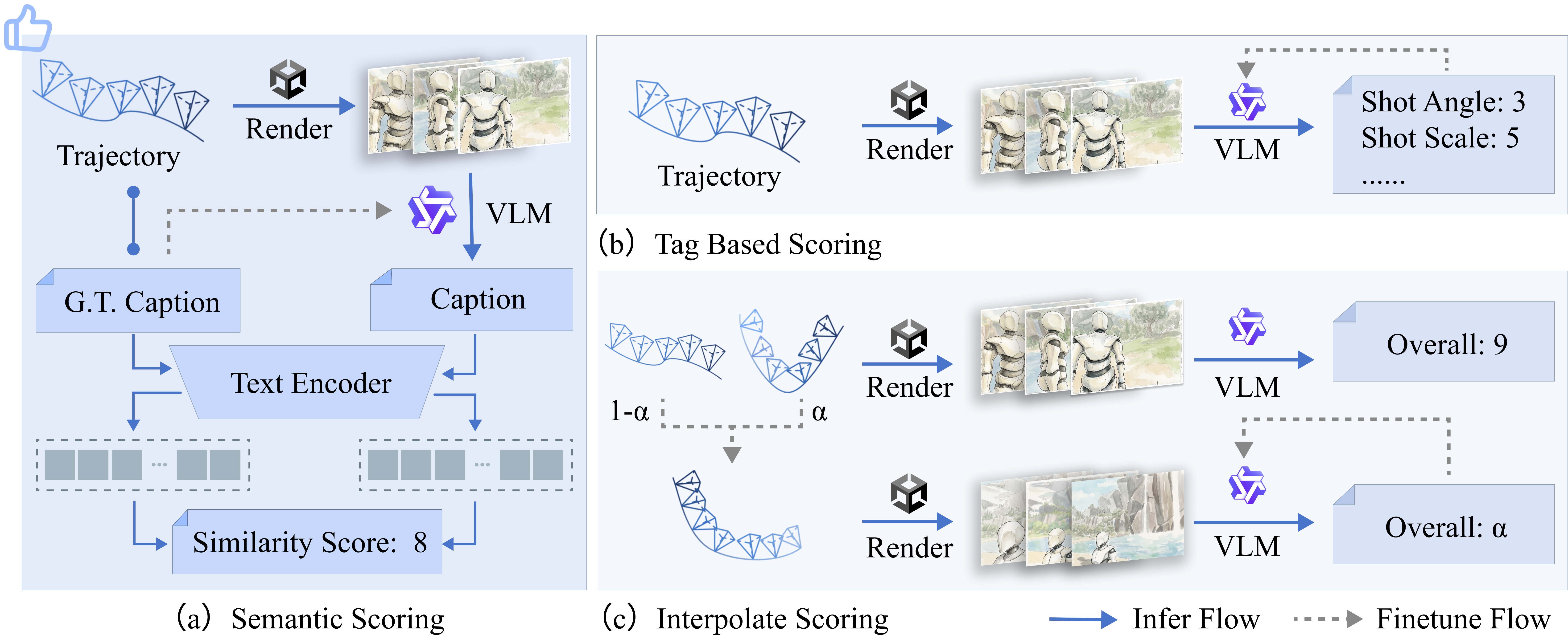
Figure 2: Comparative overview of VLM-based preference scoring mechanisms: cyclic semantic similarity, tag consistency, and direct regression.
VLMs are fine-tuned for cinematic understanding, initialized from models such as ShotBench and adapted through LoRA fine-tuning on rendered-sequence captions to mitigate domain shift effects in Unity environments.
Direct Preference Optimization
The generator receives preference pairs for DPO derived from VLM-based scoring. Unlike reward model-based RL or direct imitation, DPO directly optimizes the generator by increasing the log-odds of preferred trajectory likelihood over less-preferred ones, regularizing toward a reference policy to avoid overfitting. This process is computationally efficient due to the speed of graphics engine rendering and compact VLM scoring.
Experimental Results
Quantitative Evaluation
VERTIGO displays competitive or superior results on geometric metrics (FCD, Coverage, etc.) when compared with baselines like GenDoP, DIRECTOR, and CCD, demonstrating that perceptual optimization does not compromise structural fidelity. The most significant gains are observed in visual quality metrics, especially Missing Rate (proportion of off-screen frames), where VERTIGO reduces the rate from GenDoP’s 38.7% and DIRECTOR’s 80.3% to nearly 0%. Consistency and Aesthetic Quality on both Unity renders and downstream video generation (via Wan VACE pipelines) are substantively improved.
Qualitative Evaluation
VERTIGO robustly adheres to spatial composition prompts, while GenDoP and DIRECTOR frequently yield mislocalized or missing subjects. The model maintains subject retention and composition through diverse cinematic scenarios.

Figure 3: Qualitative comparison showing VERTIGO’s superior adherence to prompt-based spatial composition and framing against baselines.
In video-to-video transfer settings, VERTIGO’s trajectories consistently deliver robust target framing, unaffected by subject animation. Both static and animated character renderings preserve composition across pipeline steps, evidencing the generalization capacity of render-in-the-loop post-training.

Figure 4: VACE-based video-to-video transfer comparisons demonstrating VERTIGO's robust subject framing and invariance to subject animation.
Ablations and User Study
Comprehensive ablation validates the superiority of cyclic semantic scoring, with significant reduction in off-screen rates and improved VBench metrics compared to tag and regression-based strategies. The temperature parameter β and support for animated characters are also examined, with β=0.1 yielding optimal trade-offs.
Human evaluation (34 participants: 11 experts, 23 general) confirms the quantitative results. VERTIGO is preferred across all best-of-4 evaluation points and achieves the highest aggregate scores for both Unity renders and video generation.
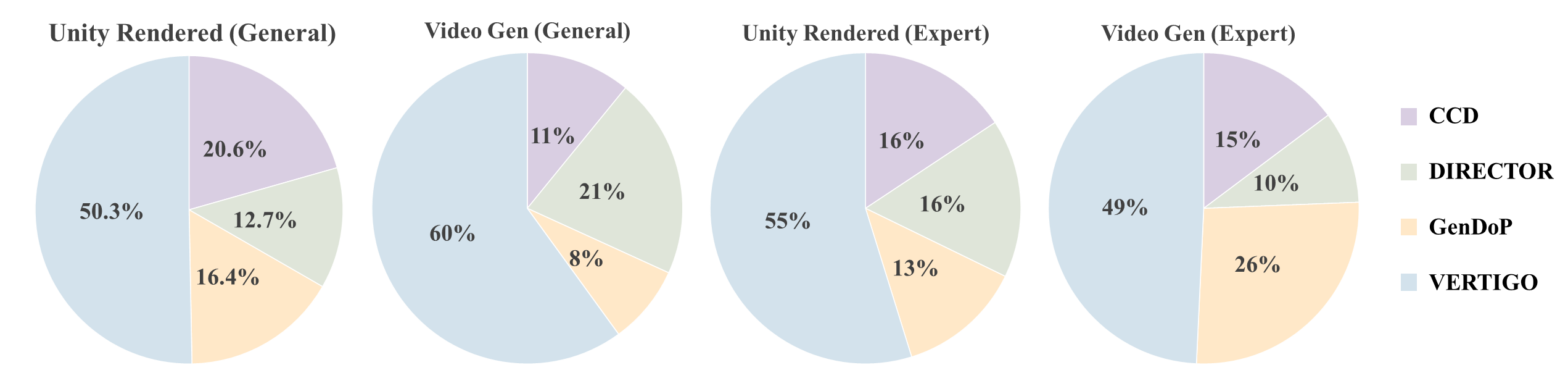
Figure 5: User study preference rates demonstrating VERTIGO's leading perceptual quality across rendering and generation tasks.
Application and System Integration
The system is designed natively in Unity, integrating script parsing, node-based shot planning, timeline editing, and batch exporting for efficient artist-in-the-loop workflows.
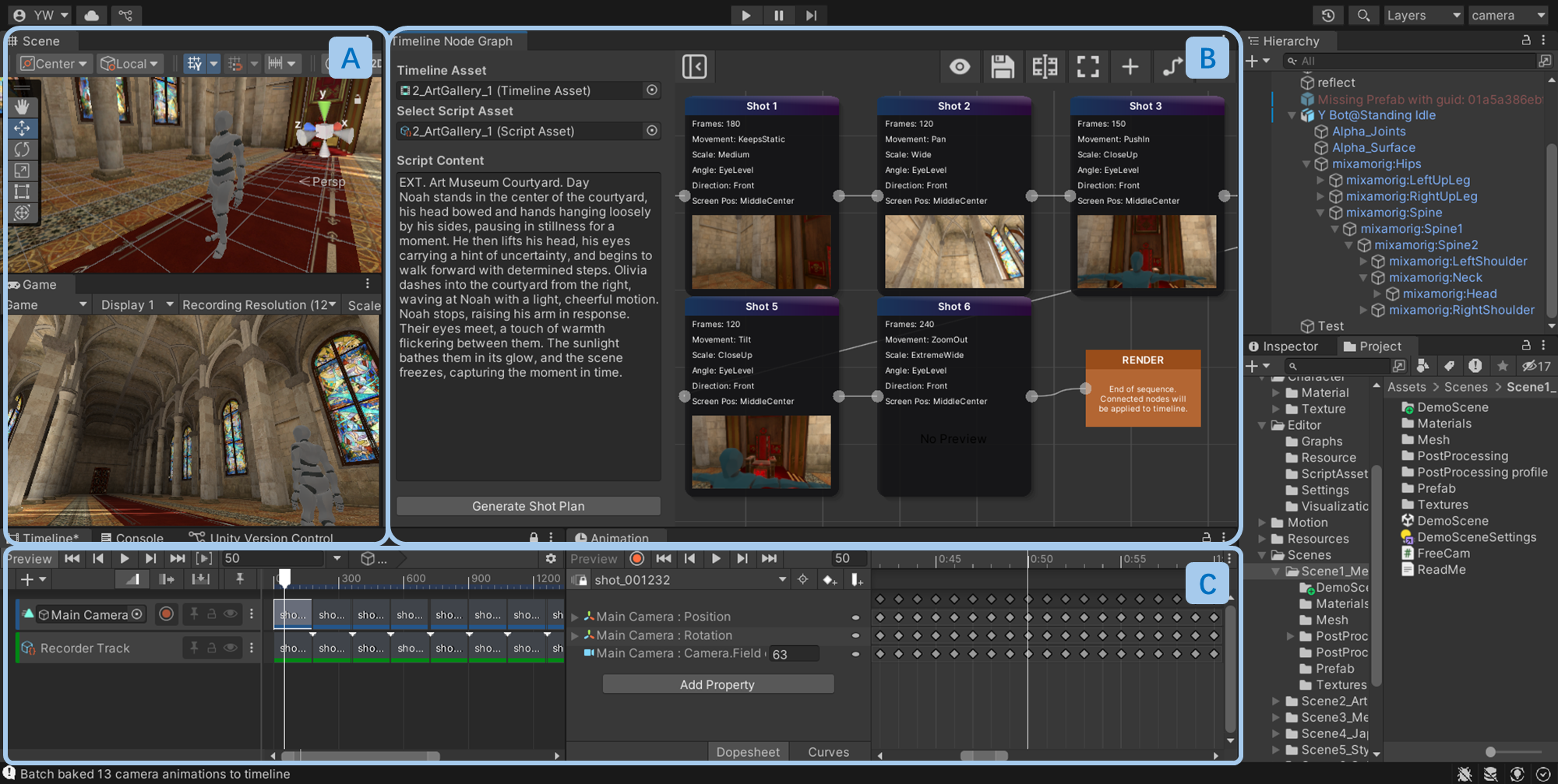
Figure 6: Unity-based authoring interface for script-to-shot pipeline planning, trajectory preview, and post-training data collection.
Questionnaire and interface design further support rigorous human evaluation of cinematic output.
Figure 7: User study interface enabling controlled comparative evaluation across multiple shot quality dimensions.
Additional and Downstream Qualitative Results
Further qualitative comparisons across diverse scenes and prompts reinforce that VERTIGO provides stable framing and target retention. Improvements in rendered previews transfer directly to downstream video outputs, confirming the value of visual preference optimization beyond simulation.

Figure 8: Extended trajectory-level comparisons emphasizing composition stability across scenes and prompts.

Figure 9: Visual output comparison in both Unity and video generation; VERTIGO maintains reliable subject framing and composition relative to all baselines.
Implications and Future Directions
VERTIGO establishes a scalable paradigm for aligning generative camera systems with shot-level perceptual feedback, enabling practical integration of director-in-the-loop supervision in virtual cinematography and film production. By explicitly optimizing for visual preference, the approach closes the loop between semantic intent and realized framing/composition. This framework is compatible with both pipeline-based previsualization and downstream generative video models, facilitating real-time, iterative creative workflows.
Theoretically, cyclic semantic scoring may be extended to other generation tasks where behavior is not directly encoded in observable outputs, representing a general strategy for bridging structural and perceptual model alignment.
Future research directions include:
- Extension to more complex narrative structures and multi-shot coherence,
- Tight coupling with multi-agent collaborative frameworks for script-driven virtual production,
- Adapting scoring mechanisms to broader video generation and animation tasks,
- Exploring transfer to other domains involving spatial planning and visual preference modeling.
Conclusion
VERTIGO represents a systematic framework for closing the gap between geometric camera motion generation and perceptually validated cinematic outcomes. By integrating real-time rendering, VLM-based cyclic semantic preference scoring, and DPO-driven policy optimization, it achieves markedly improved visual quality, stable framing, and consistent prompt adherence, as confirmed by both quantitative and human studies. The methodology offers a practical pathway toward director-in-the-loop computational cinematography, setting the stage for further advances in visually aligned trajectory generation and aesthetic-aware generative AI for film and animation production (2604.02467).

