- The paper introduces a community-informed rubric framework that quantifies the cultural appropriateness of AI-generated images of artifacts.
- It details a three-stage methodology — systematization, operationalization, and application — derived from social science measurement theory.
- Comparative analysis reveals significant discrepancies between community-elicited and LLM-generated rubrics, highlighting key model limitations.
Introduction
The paper "Evaluating AI-Generated Images of Cultural Artifacts with Community-Informed Rubrics" (2604.02406) addresses the challenge of evaluating the cultural appropriateness of text-to-image generative models. Existing AI evaluation frameworks primarily rely on benchmarks and automatic metrics that are often decontextualized and fail to capture the nuanced, context-specific requirements of marginalized or underrepresented communities. The authors propose a measurement framework that foregrounds community expertise, and systematically investigate how to incorporate lived experiences and community-driven values in the definition and operationalization of cultural appropriateness metrics.
Measurement Framework and Research Design
The methodological foundation builds on established social science measurement theory, notably the Adcock & Collier framework [adcock2001measurement], as adapted for AI by Wallach et al. [wallach2025position]. Measurement proceeds in three distinct stages:
- Systematization: Mapping abstract concepts (e.g., cultural appropriateness) into precise, well-specified criteria, heavily informed by domain or community expertise.
- Operationalization: Translating these criteria into measurement instruments (e.g., rubrics, checklists) amenable to human or automated annotation.
- Application: Deploying these instruments on model outputs to produce evaluative metrics.
The paper situates community engagement primarily at the systematization stage, scaffolding this participation through empirical workshops across three sociocultural domains: blind/low vision (BLV) communities in the UK, and residents of Kerala and Tamil Nadu in India. The artifacts chosen (e.g., guide cane, braille notetaker, Kasavu saree, Chundan Vallam) represent high cultural saliency and previously documented AI representational failures.

Figure 1: Scaffolding community engagement to develop community-centered measures of cultural representation, and integrating these rubrics into an LLM-as-a-judge pipeline.
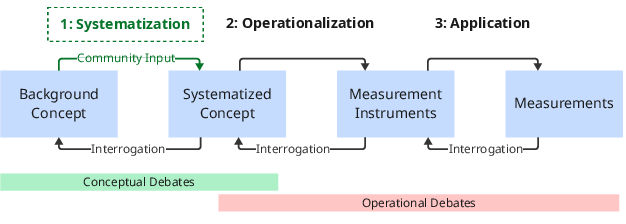
Figure 2: The measurement framework from social sciences guiding the transformation from abstract concepts to applied metrics.
Elicitation and Construction of Community Rubrics
Rubric construction advances through tightly moderated workshops. Participants are shown curated sets of real and AI-generated images, which they review for appropriateness. Facilitators extract both positive features and representational failures, prompting participants to articulate substantive visual, functional, and contextual criteria necessary for a “culturally appropriate” rendering.
Rubrics are binary in structure: an image is considered appropriate if all core criteria are met. The authors are explicit about prioritizing criteria with cross-participant consensus and excluding highly contested features to maximize practical applicability. These rubrics are contextually anchored and not assumed to transfer across settings.
Key thematic axes extracted across communities include:
- Functionality: The depicted artifact must plausibly serve its intended purpose within the target community.
- Recognizability: Distinction from visually or contextually similar—but culturally divergent—objects is essential.

Figure 3: Samples of the culturally significant artifacts used in workshops across the BLV community, Kerala, and Tamil Nadu.

Figure 4: Example rubric for the guide cane synthesized from BLV community feedback, categorizing visually salient and functional features.
In a critical empirical contribution, the authors contrast community-elicited rubrics with those produced by prompting GPT-4o for evaluation criteria. LLM-generated rubrics are prone to both factual inaccuracies (e.g., requiring displays on a braille notetaker) and omissions of critical, culturally defining features (e.g., the black circular membrane on a Mridangam drum).

Figure 5: Systematic differences between community-elicited and LLM-generated rubrics, highlighting corrections, clarifications, and missing culturally-salient details.
(Figures 7–12)
Figures 7–12: Annotated LLM-generated rubrics for each artifact, with explicit call-outs of inaccurate, underspecified, or omitted criteria relative to community-produced standards.
This shows that automated rubric generation is variably effective: it is more aligned for well-documented or globally recognized artifacts, but diverges sharply for culturally nuanced, marginalized, or underrepresented domains.
Operationalization: Automation with Multimodal LLM-as-a-Judge
The authors transfer community rubrics into an LLM-as-a-judge setting, specifically using GPT-4o as the evaluation model. An experimental data set of 50 images per artifact from five SOTA image generation models (DALL·E 3, GPT Image-1, Flux.1 DEV, Stable Diffusion 3/3.5) is scored by both community rubric designers and the LLM judge.
Inter-rater alignment is strong in aggregate (78–88% agreement depending on artifact), but highly heterogeneous at the criterion level: criteria involving visually salient, surface-level features (e.g., “Is the cane white?”) are judged with high accuracy, whereas those demanding fine-grained spatial, material, or contextual reasoning (e.g., arrangement of braille cells) suffer poor LLM agreement.
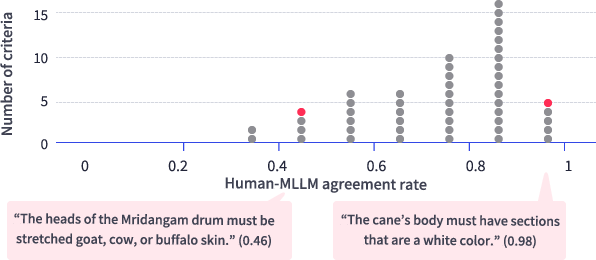
Figure 6: Distribution of human–MLLM agreement scores at the individual rubric criterion level, illustrating high variance contingent on the nature of the visible feature.
Diagnostics: Model Failure Modes and Interpretability
By scoring images across models and artifacts, the rubric framework reveals interpretable, model-specific failure profiles. For example, some models systematically omit key features such as the Mridangam’s black membrane or generate inappropriate embellishments. The class imbalance—few or no “culturally appropriate” images for several artifacts—quantifies current model limitations with marginalized or culturally-embedded artifacts.
(Figures 13–16)
Figure 7: Fine-grained diagnostic breakdown of criterion violations in AI depictions of the braille notetaker.
Figure 8–16: Comparative criterion-level error profiles by model for braille notetaker, Mridangam, and Kasavu saree, respectively.
Challenges with Cross-Lingual and Underrepresented Prompts
Experiments with transcribed artifact names and simple prompts for certain Indian artifacts yielded highly irrelevant outputs from Stable Diffusion, demonstrating generative models’ incapacity to handle transliterated, culturally local queries without auxiliary descriptive information.

Figure 9: Stable Diffusion 3 outputs for transliterated prompts versus enriched, DALL·E-style descriptive prompts, demonstrating significant improvement only with detailed guidance.
Limitations and Methodological Considerations
The efficacy of rubric automation is tempered by the inherent ambiguity and contestation in cultural representation—participant agreement bottoms out at 67% for some artifacts even during in-community annotation, highlighting the impossibility of universal formalization. The authors also note the labor-intensive demands on participants, the non-portability of rubrics across cultural settings, and the limitations of one-off workshop engagements for capturing the full diversity of community experience.
Implications and Future Directions
- Practical: Community-centered rubric design produces more valid, culturally-aligned metrics for AI representation in low-data or marginalized domains, surfacing model-specific limitations that industrial benchmarks miss. However, the automation pipeline (MLLM-as-a-judge) requires substantial iteration and prompt engineering; criteria reliant on complex or ambiguous visual relationships remain a bottleneck.
- Theoretical: The separation of systematization from operationalization allows for a division of labor between community epistemic authority and technical implementation, aligning with recent calls for participatory AI and social science–informed evaluation [adelazuarda2024towards, rahman2025just, wallach2025position].
- Future AI Development: The framework provides a foundation for scalable, context-sensitive evaluation pipelines, with important lessons for interventions ranging from rubric bootstrapping via LLMs to hybrid, iterative human-in-the-loop designs [pan2024human, gabreegziabher2024metricmate]. However, true pluralism and participatory measurement may require fundamentally new approaches to accommodate contested or non-binary notions of representation [sorensen2024roadmap, hall2025human].
Conclusion
This paper offers a rigorous, empirically grounded methodology for integrating community expertise into quantitative AI evaluation by systematizing cultural appropriateness through context-driven rubrics. The approach exposes the limitations of automated criteria generation and reveals both the promise and bottlenecks in automating community-defined evaluation through MLLMs. These results are critical for practitioners committed to responsible, inclusive AI evaluation—especially for domains, communities, and artifacts that elude standard benchmarks—by foregrounding validity, transparency, and stakeholder alignment in AI measurement processes.

