- The paper introduces a unified vision-language-action model that enables end-to-end UAV tracking in challenging urban environments.
- It employs a Temporal Compression Net and Dual-Branch Decoder to enhance tracking robustness and reduce inference latency.
- Evaluations on the UAV-Track benchmark demonstrate improved success rates and real-time processing critical for mission scalability.
UAV-Track VLA: Vision-Language-Action Models for Embodied Aerial Tracking
Introduction
The paper "UAV-Track VLA: Embodied Aerial Tracking via Vision-Language-Action Models" (2604.02241) introduces a novel approach for end-to-end UAV tracking in complex urban scenarios using a Vision-Language-Action (VLA) model. Unlike previous VAT and EVT frameworks, which are constrained by limited semantic understanding or platform-specific assumptions, this work addresses the integration of natural language instructions, visual perception, and continuous action generation—delivering robust tracking across a diverse set of tasks and objects. The authors also present UAV-Track, an extensive multimodal benchmark for evaluating such systems, alongside a specialized VLA architecture with improvements in temporal feature efficiency and cross-modal control alignment.
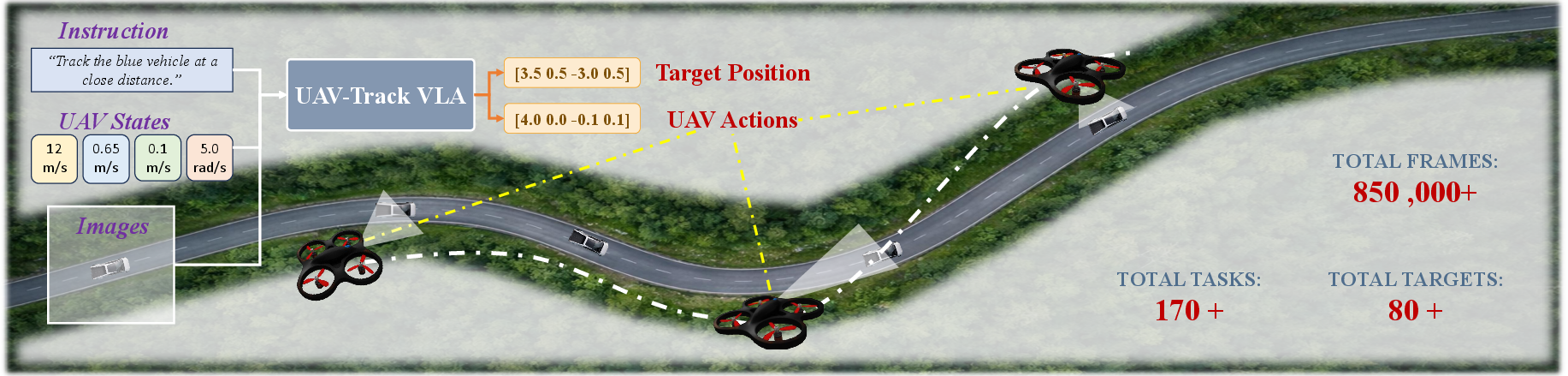
Figure 1: The UAV-Track VLA model follows human instructions to simultaneously predict the target position and continuous UAV flight actions.
Benchmark and Dataset Construction
A critical contribution is the UAV-Track benchmark, designed to facilitate research on UAVs operating under both high-level language instructions and dynamic urban conditions. The dataset encompasses 892,756 frames across 176 tasks featuring 85 diverse objects, collecting both expert and algorithmic demonstration trajectories in the CARLA simulator. The data generation pipeline relies on a hybrid of human piloting and an augmented Artificial Potential Field (APF) algorithm for coverage and robustness, with dynamic perturbations to induce off-nominal recovery strategies and reduce imitation learning covariate shift.
The benchmark captures heterogeneity along three axes:
- Environment and Target Diversity: Various urban topologies, lighting, and weather, including both pedestrian and vehicular targets.
- Kinematic Completeness: A spectrum of target dynamics (0–70 m/s), realistic UAV yaw evolution, and 4-DoF continuous motion trajectories.
- Language Instruction Variation: Hundreds of unique, grounded natural language expressions directing complex semantic flight intents.
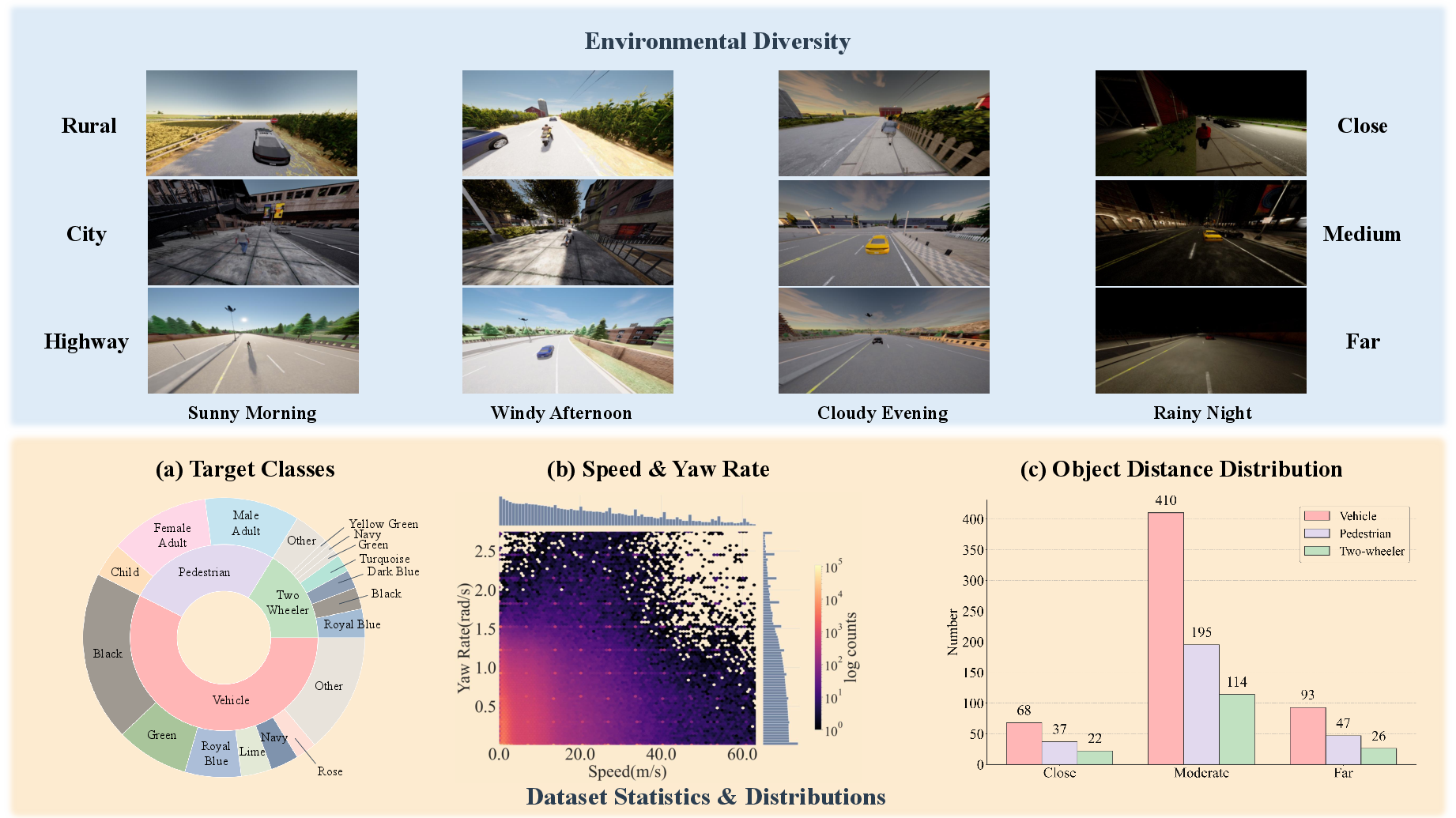
Figure 2: Overview of the multidimensional diversity of the UAV-Track benchmark: environment variety, task paradigms, and distribution over target categories, kinematic states, and tracking ranges.
The dataset is designed to enable the evaluation of robust, multimodal UAV policy learning in challenging, realistic settings.
Model Architecture
The UAV-Track VLA model is built upon the π0.5 VLA foundation and introduces two significant architectural improvements:
- Temporal Compression Net: Pre-processing of historical visual frames through aggressive token compression, drastically reducing temporal redundancy while preserving essential inter-frame dynamics for robust tracking. This enables efficient ingestion of multiple frames without overwhelming the encoder with redundant tokens.
- Dual-Branch Decoder: The decoupling of spatial grounding from action generation via parallel modules:
- A spatial-aware auxiliary grounding head predicts the relative pose (3D position and yaw) of the tracked object with respect to the UAV. This branch operates only under auxiliary supervision during training, imposing geometric priors on the shared latent space.
- A flow matching action expert outputs a 25-step sequence of low-level UAV displacement commands, leveraging enriched cross-modal features to optimize for continuous high-frequency control.
Cross-modal representation learning is orchestrated with a mixed loss (weighted sum of position and flow matching objectives), yielding temporal coherence, geometric consistency, and low-latency inference.
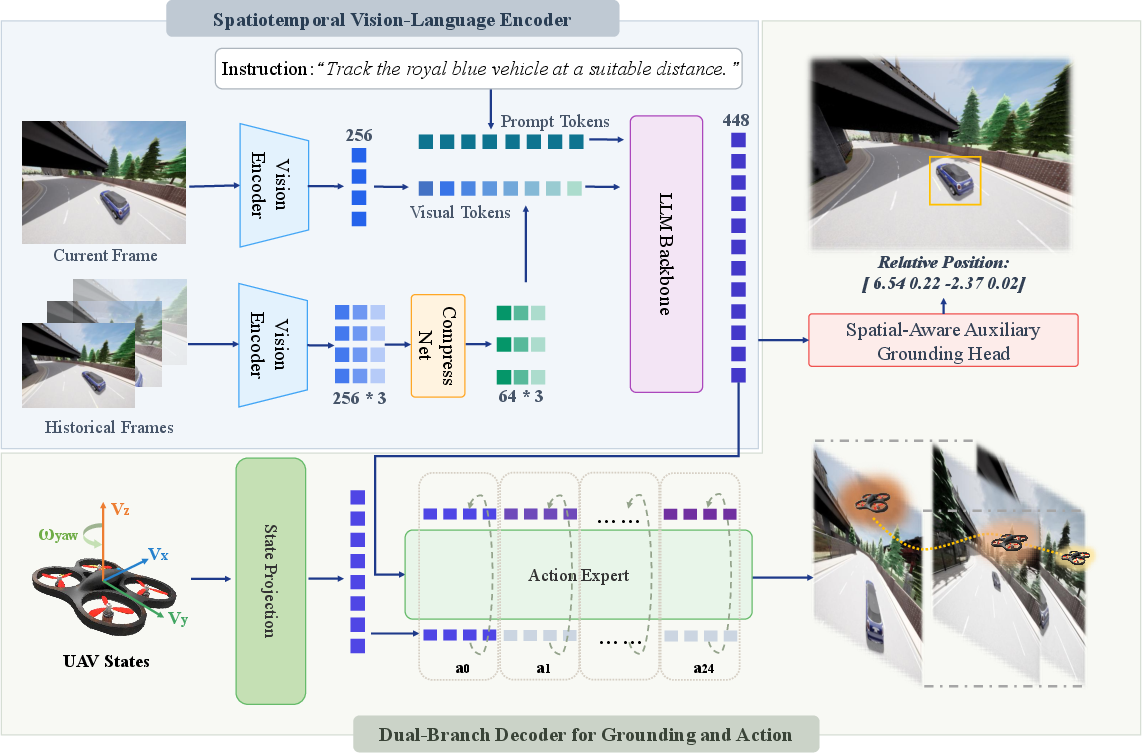
Figure 3: Overall architecture of UAV-Track VLA: a spatiotemporal encoder compresses visual history, fuses with language and proprioceptive input via an LLM, and dispatches features to parallel spatial grounding and flow-matching action decoders.
Experimental Results
The model is systematically evaluated in CARLA across both seen and unseen urban environments, benchmarked against ACT, WALL-OSS, π0, and π0.5. Two principal metrics are utilized: Success Rate (SR)—strictly defined by sustained tracking—and Average Tracked Frames (ATF), capturing stability before failure.
Key empirical findings:
- Tracking Robustness: UAV-Track VLA consistently achieves strong performance on long-horizon tracking, especially for pedestrian targets. For example, in "Far" pedestrian scenarios, the model yields 269.65 mean steps with 61.76% SR in seen maps, and 226.90 steps with 55.00% SR in unseen maps, exceeding π0.5 by substantial margins.
- Generalization: The model demonstrates strong zero-shot adaptability, retaining high ATF and SR for novel environments and instructions without overfitting.
- Ablation of Auxiliary Head: Removal of the spatial-aware auxiliary grounding head severely degrades pedestrian tracking performance, demonstrating the necessity of explicit geometric priors for fine-grained target following.
- Inference Efficiency: Average inference latency per frame is reduced to 0.0571s, a 33.4% improvement over π0.5, confirming computational feasibility for real-time deployment.
Discussion and Implications
This work offers significant advances both practically and theoretically for embodied aerial intelligence:
- Unified Cross-Modal Policy: The combination of language, vision, and proprioceptive observation in an end-to-end fashion removes the traditional bottleneck of modular planning plus perception, thus enabling instruction-driven, closed-loop control over high-dimensional state and action spaces.
- Scalability and Real-Time Feasibility: The architectural changes demonstrate that judicious spatial and temporal abstraction does not require trading off controllability or low-latency action execution.
- Benchmark Establishment: UAV-Track fills an important gap for evaluating embodied VLA models in UAV domains, with coverage across diverse environments, object categories, and instruction sets.
Potential future research directions include transferring these methods to real-world aerial platforms (addressing sim-to-real challenges), integrating with more sophisticated LLMs for compositional reasoning, expanding the range of actionable instructions, and exploring robust policy adaptation for dynamic mission objectives and adversarial environments.
Conclusion
The paper delivers a comprehensive evaluation and extension of VLA models for embodied UAV tracking, substantiating the value of cross-modal temporal compression and geometric supervision for robust, instruction-driven aerial control. UAV-Track VLA not only improves continuous tracking robustness—particularly in complex pedestrian scenarios—but also enables real-time operation through architectural optimization. The release of the UAV-Track benchmark is poised to standardize progress in the field. These contributions set a solid foundation for future research on instruction-conditioned, close-the-loop UAV autonomy in unstructured and dynamic environments.