- The paper introduces SCALE, a CVAE that reformulates zero-shot action recognition as an energy-ranking problem leveraging semantic and confidence cues.
- It integrates Shift-GCN for skeleton feature extraction with CLIP-based text embeddings to model class-conditional uncertainty and improve discrimination.
- Experimental results show significant accuracy gains and superior computational efficiency compared to diffusion-based and conventional VAE methods on NTU benchmarks.
SCALE: A Semantic- and Confidence-Aware Energy-Based Framework for Zero-Shot Skeleton-Based Action Recognition
Problem Motivation
Zero-shot skeleton-based action recognition (ZSAR) seeks to recognize action classes absent from training skeleton sequences, leveraging auxiliary semantic information—typically textual class descriptions. Conventional approaches depend on explicit cross-modal alignment between skeleton features and text embeddings, including metric learning, VAE-based cross-modal reconstruction, and diffusion-powered alignment. These strategies are vulnerable when action class semantics do not sufficiently specify fine-grained dynamical cues, leading to confusion among semantically similar unseen classes. Moreover, existing generative models often lack mechanisms for discriminating competing unseen classes during inference.
SCALE addresses these challenges by reformulating ZSAR as a deterministic, class-conditional energy ranking problem that exploits both semantic similarity among classes and confidence (posterior uncertainty) in skeleton feature compatibility.
SCALE Framework Architecture
SCALE employs a conditional variational autoencoder (CVAE), with frozen text representations parameterizing both the latent prior and the decoder. The skeleton encoder extracts sequence-level features from Shift-GCN, and a CLIP-based text encoder provides both token-level and pooled (global) semantic vectors for action classes.
Class-conditional text embeddings are projected via a learnable module and used to model the Gaussian prior over latent variables. Skeleton features are concatenated with text-derived conditioning vectors and encoded to a latent posterior. The decoder reconstructs skeleton features conditioned on sampled latent variables and text projections. Importantly, the ELBO serves as an energy function quantifying compatibility between a skeleton instance and candidate classes.
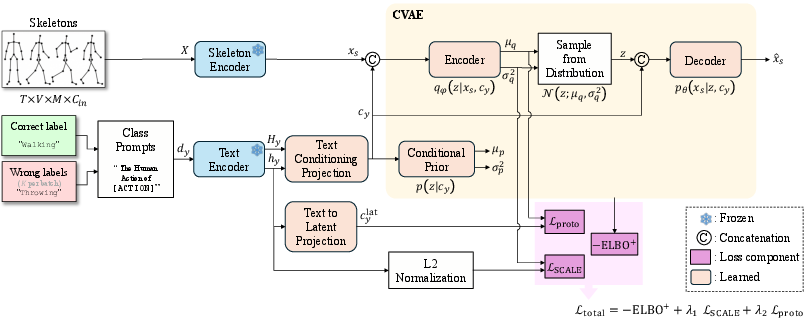
Figure 1: The SCALE training pipeline integrates skeleton and text encoders, CVAE, semantic-aware energy discrimination, and latent prototype alignment.
SCALE optimizes a composite objective:
- Generative Consistency: The standard ELBO for reconstruction and KL regularization.
- Listwise Energy-Based Discrimination: Contrary to prior models treating negatives uniformly, SCALE aggregates energies over negatives with a semantic similarity bias (computed via normalized text embeddings). Hard negatives that are semantically similar to the positive class are emphasized using a soft-max mechanism, improving separation under semantic ambiguity.
- Uncertainty-Adaptive Margin and Loss Reweighting: Posterior variance governs both decision margin relaxation and individual sample reweighting—allowing stricter margins for confident samples and downweighting ambiguous instances, mitigating overfitting and unstable gradients.
- Latent Prototype Contrast: Posterior means are aligned with text-derived latent prototypes through a contrastive objective, enhancing semantic organization and clustering in latent space beyond simple cross-modal alignment.
Ablation studies demonstrate substantial gains from semantic similarity bias (+0.6% on NTU-60 and +0.7% on NTU-120), uncertainty modeling (+0.8% and +0.5%), and latent prototype contrast (+2.4%, +3.9%), underscoring their critical roles.
Inference Procedure
At test time, SCALE operates deterministically: for each skeleton sample, it computes ELBO-derived energies across candidate unseen classes, ranking them to infer the class label. No test-time sample generation or stochastic alignment is required.
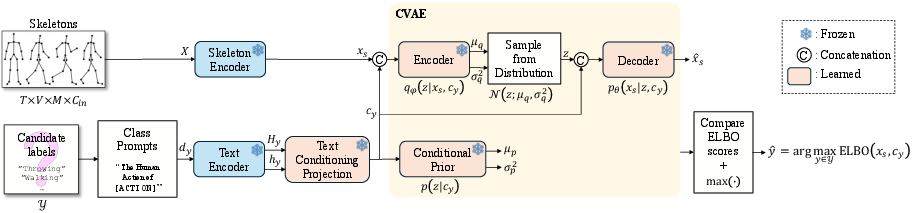
Figure 2: SCALE's inference pipeline involves feature extraction, text conditioning, and ELBO-based energy ranking for class prediction.
Experimental Results and Numerical Findings
SCALE is evaluated on NTU-60 and NTU-120, using both mild (SynSE) and challenging (PURLS) zero-shot splits. The model achieves second-best overall performance across all benchmarks, outperforming VAE- and explicit alignment-based methods by large margins:
- On NTU-120 [110/10], SCALE delivers 73.6% accuracy (+4.8% over SA-DVAE, 1.6% over PURLS).
- On NTU-60 [40/20], SCALE achieves 35.5% (+0.7%0 over PURLS).
- SCALE's margins against third-best methods increase for splits with higher unseen action proportions, confirming robustness in semantically ambiguous settings.
Compared with the diffusion-based TDSM, SCALE remains highly competitive (within +0.7%1 accuracy) while being orders-of-magnitude more efficient:
- TDSM requires +0.7%2M parameters and +0.7%3ms/sample inference (averaged across 10 trials), versus SCALE's +0.7%4M parameters and +0.7%5ms/sample (+0.7%6227+0.7%7 faster).
- Effective computational cost is +0.7%8 GFLOPs/sample for TDSM, versus +0.7%9 GFLOPs for SCALE (+0.8%016,000+0.8%1 more efficient).
Ablations validate the efficacy of each design component and highlight improved trade-offs in discriminability and efficiency.
Implications and Future Directions
Practically, SCALE offers significant resource reductions and deterministic prediction, suitable for real-time open-world deployment scenarios and privacy-preserving action recognition. Theoretically, the semantic- and confidence-aware energy modeling introduces a nuanced approach to open-set recognition, balancing discrimination with robustness to ambiguous supervision and semantic uncertainty. The latent prototype contrast mechanism improves latent space structuring without requiring brittle feature alignment.
Future research avenues include:
- Extension to more granular or hierarchically structured semantic priors, leveraging richer LLMs for improved prototype quality and ambiguity mitigation.
- Integration with closed-set and generalized zero-shot settings for unified action recognition systems.
- Application to other sequence-based modalities (e.g., EEG, gesture, trajectory) for broader cross-modal transfer.
Conclusion
SCALE advances zero-shot skeleton-based action recognition by leveraging a deterministic CVAE architecture integrated with semantic- and confidence-aware energy ranking and latent prototype contrast. It outperforms prior VAE and alignment-based baselines and rivals diffusion-based models in accuracy, while delivering superior computational efficiency and robustness. Its principled energy-based approach offers a promising framework for scalable, open-world action recognition using only textual supervision.