- The paper introduces an entropy-regularized reinforcement learning framework that reformulates sequential trading as a relaxed control problem using randomized intensity policies.
- It derives a coupled HJB system with closed-form Gibbs policies, providing convergence guarantees and quantifiable error bounds for optimal entry/exit decisions.
- Empirical validation using pairs-trading under prospect theory reveals the framework's efficacy in approximating classical HJB solutions via model-free policy iteration.
Reinforcement Learning for Speculative Trading under Exploratory Framework: Technical Essay
The paper "Reinforcement Learning for Speculative Trading under Exploratory Framework" (2604.02035) rigorously formulates a sequential speculative trading problem—characterized by optimal entry and exit decisions—via an entropy-regularized reinforcement learning (RL) approach within continuous time. The central objective is to maximize expected utility from round-trip profit, abstract enough to encapsulate pairs-trading and single-asset speculative excursions. The core modeling contributions are:
- Reformulation of the sequential entry-exit timing as a relaxed control problem: Entry and exit times are governed by interacting Cox processes parametrized by bounded, deterministic intensity controls rather than traditional stopping times.
- Extension of the exploratory RL paradigm: The relaxation is further extended by allowing agents to randomize their intensity policies (i.e., using probability measures over intensity levels), and penalizing exploration with a Shannon entropy regularizer. This constructs a genuinely exploration-driven stopping policy, distinguishing it from prior binary or Dirac policies.
- Theoretical analysis: The authors derive and analyze the corresponding exploratory HJB system, characterize the optimal randomized policies in closed form (as Gibbs distributions), and provide non-asymptotic error bounds with convergence guarantees towards the original value function as entropy and intensity bounds are tuned.
- Computation and validation: The theoretical apparatus is applied to a pairs-trading scenario under an Ornstein-Uhlenbeck (OU) spread and prospect-theory preferences, and validated both with finite-difference HJB solvers and a model-free policy iteration algorithm using deep networks.
Relaxed and Exploratory Control Framework
The conventional optimal stopping framework is intractable in high dimensions and non-Markovian settings, primarily due to free boundary and variational inequality complications. To circumvent this, the paper replaces optimal stopping times (τ,ν) with jump times of two Cox processes (entry/exit), driven by bounded intensities (α,β)∈[0,M]2. Specifically, the state is augmented to include both the trading regime (Jt∈{0,1,2}: before entry, in position, after exit) and reference entry price, yielding Markovian process Xt=(Pt,Jt,Bt).
This relaxation guarantees:
- The process is Markovian in the extended state.
- The distinction between regimes is maintained at all times, facilitating a dynamic-programming decomposition.
- The functional correspondences between the original stopping problem and the controlled version are made precise (pathwise), with equivalence for admissible controls.
Exploration is enforced by considering randomized policies, i.e., the agent selects a probability measure πt on the intensity space rather than a deterministic value. Shannon's differential entropy is used as a regularization, weighted by a temperature parameter η. The RL objective, combining discounted reward and entropy cost, is then:
Ventη(p)=π∈A(p)supE[∫0∞e−ρt(r~tπ+ηH(πt))dt∣P0=p]
This brings the classic RL exploration-exploitation dilemma directly into the continuous-time trading context.
Analytical Characterization: HJB System and Gibbs Policies
The main analytical result is the derivation of a coupled HJB system for the value functions in the different regimes (denoted V0(p) before entry, V1(p,b) after entry), incorporating both the control and the entropy regularization terms. The HJB equation structure is:
ρV0(p)−LPV0(p)=παmax(−η∫Mπαln(Mπα)dλ+Eπ[switching reward])
(α,β)∈[0,M]20
The maximizing measure in both cases is the Gibbs distribution: (α,β)∈[0,M]21
Such structure enables closed-form computation of both the optimal density and expected intensity. When (α,β)∈[0,M]22, the distributions concentrate on extremal actions (fully greedy policy), while for (α,β)∈[0,M]23—especially at moderate values—significant exploration is enforced.
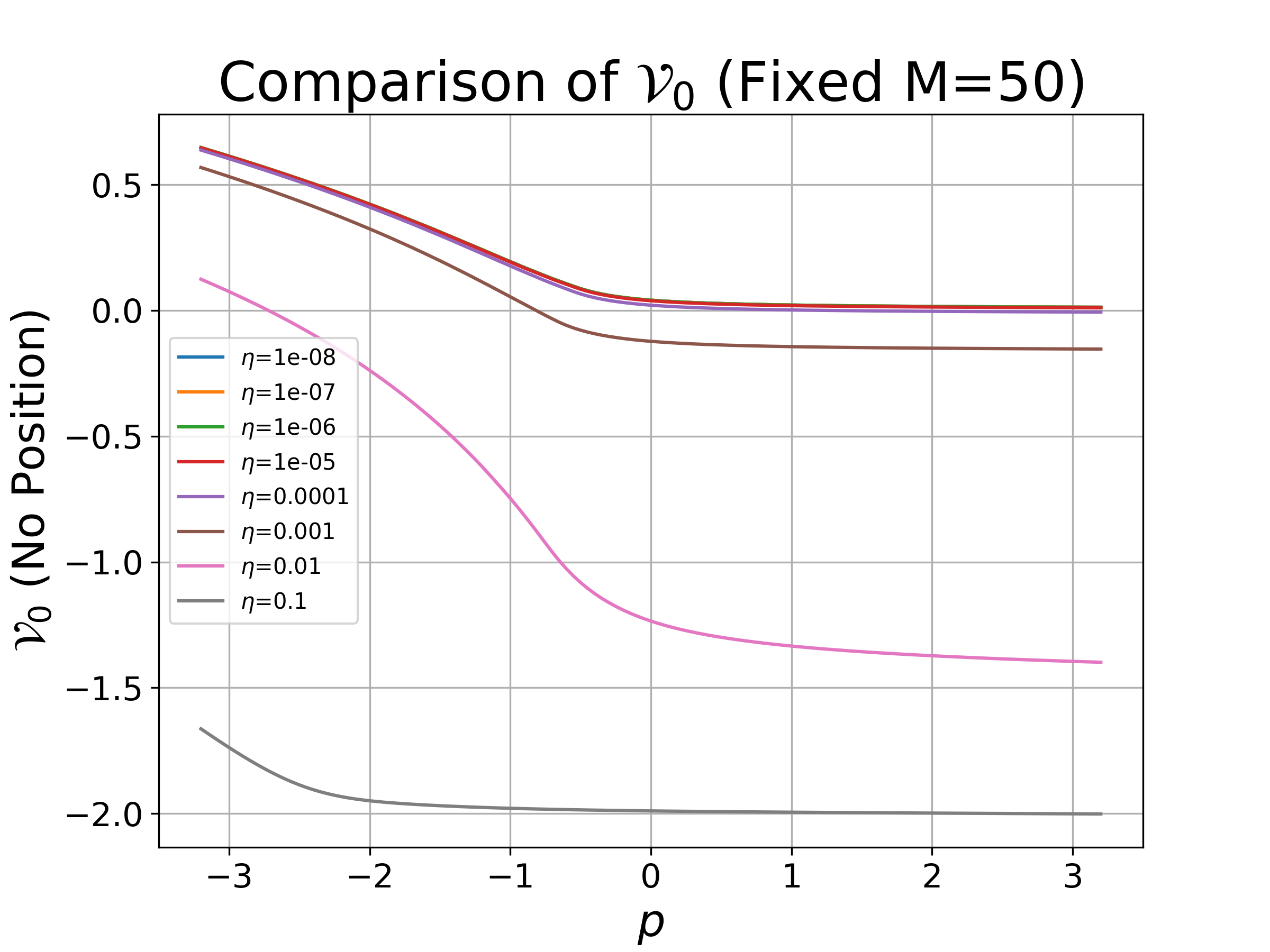
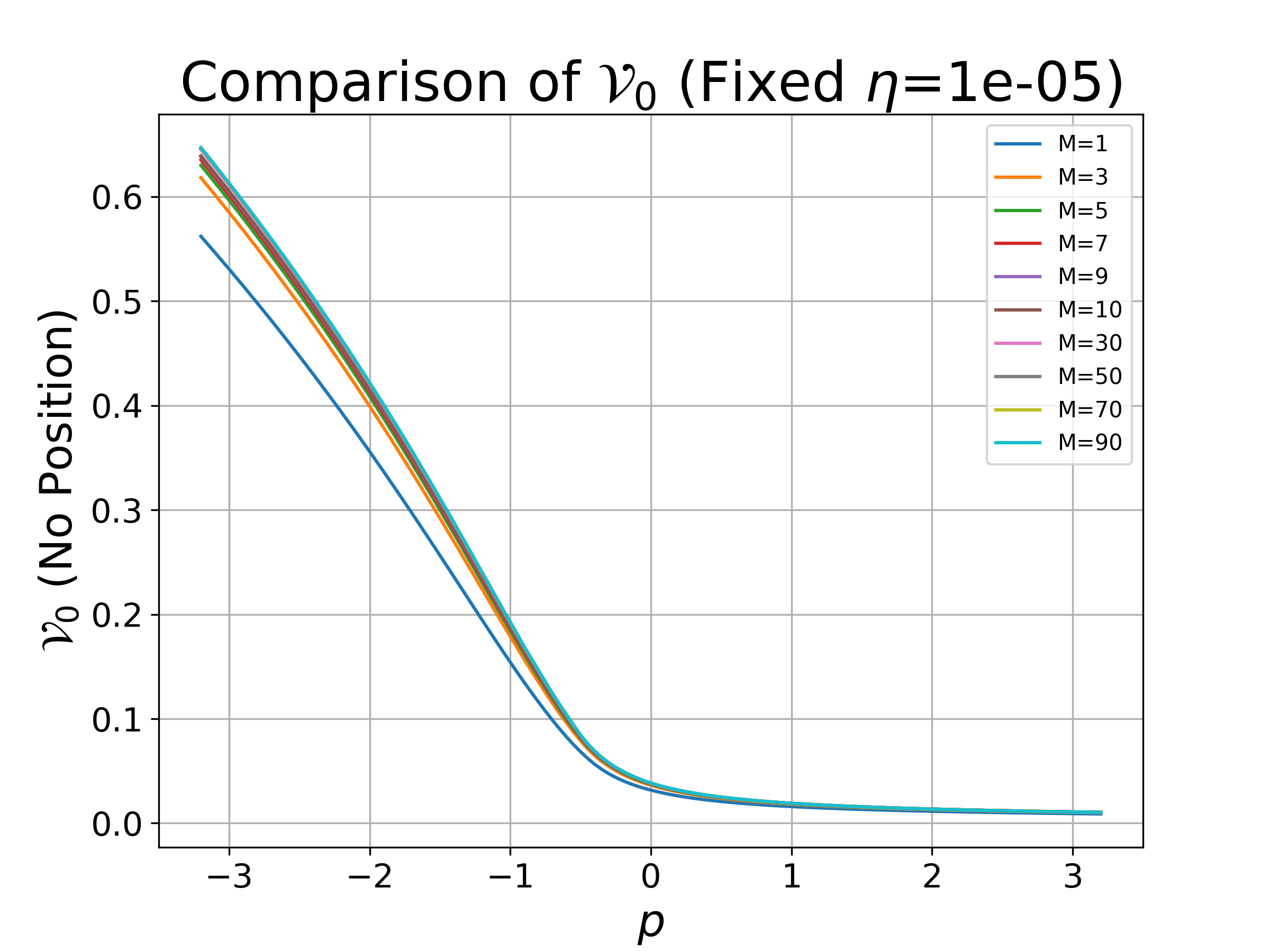
Figure 1: Value function (α,β)∈[0,M]24 as a function of signal (α,β)∈[0,M]25 for different (α,β)∈[0,M]26 settings, illustrating regularization effects.
Error Analysis and Monotonic Convergence
A core theoretical result is the establishment of tight, quantitative error bounds between the entropy-regularized RL value and the value of the original sequential stopping problem. Specifically, for intensity cap (α,β)∈[0,M]27 and entropy parameter (α,β)∈[0,M]28, the sub-optimality gap satisfies:
(α,β)∈[0,M]29
where Jt∈{0,1,2}0 is the H\"older exponent of the utility function. This shows:
- Tuning Jt∈{0,1,2}1 and Jt∈{0,1,2}2 with Jt∈{0,1,2}3 (jointly) recovers the original non-exploratory optimal value.
- The error bound is constructive, directly guiding hyperparameter selection for computational schemes.
- The convergence is monotone (from below): the entropy-regularized value functions approximate the original value from below as exploration is gradually turned off.
Application to Pairs-Trading under Prospect Theory Preferences
To demonstrate tractability and practical significance, the authors apply their framework to a synthetic pairs-trading task. The spread process is given as an OU diffusion. The agent's utility function is S-shaped (piecewise power law with loss aversion):
Jt∈{0,1,2}4
Numerical solution of the HJB system using finite differences, along with analysis of the optimal entry/exit densities, reveals:
- As Jt∈{0,1,2}5 increases (greater capacity for exploitation), the value function improves up to saturation. As Jt∈{0,1,2}6 increases (greater exploration), the value function rises due to regularization, but becomes suboptimal if excessive.
- The optimal stopping policies' free boundaries are explicitly characterized, and align with economic intuition about risk-aversion and mean-reversion of the spread.
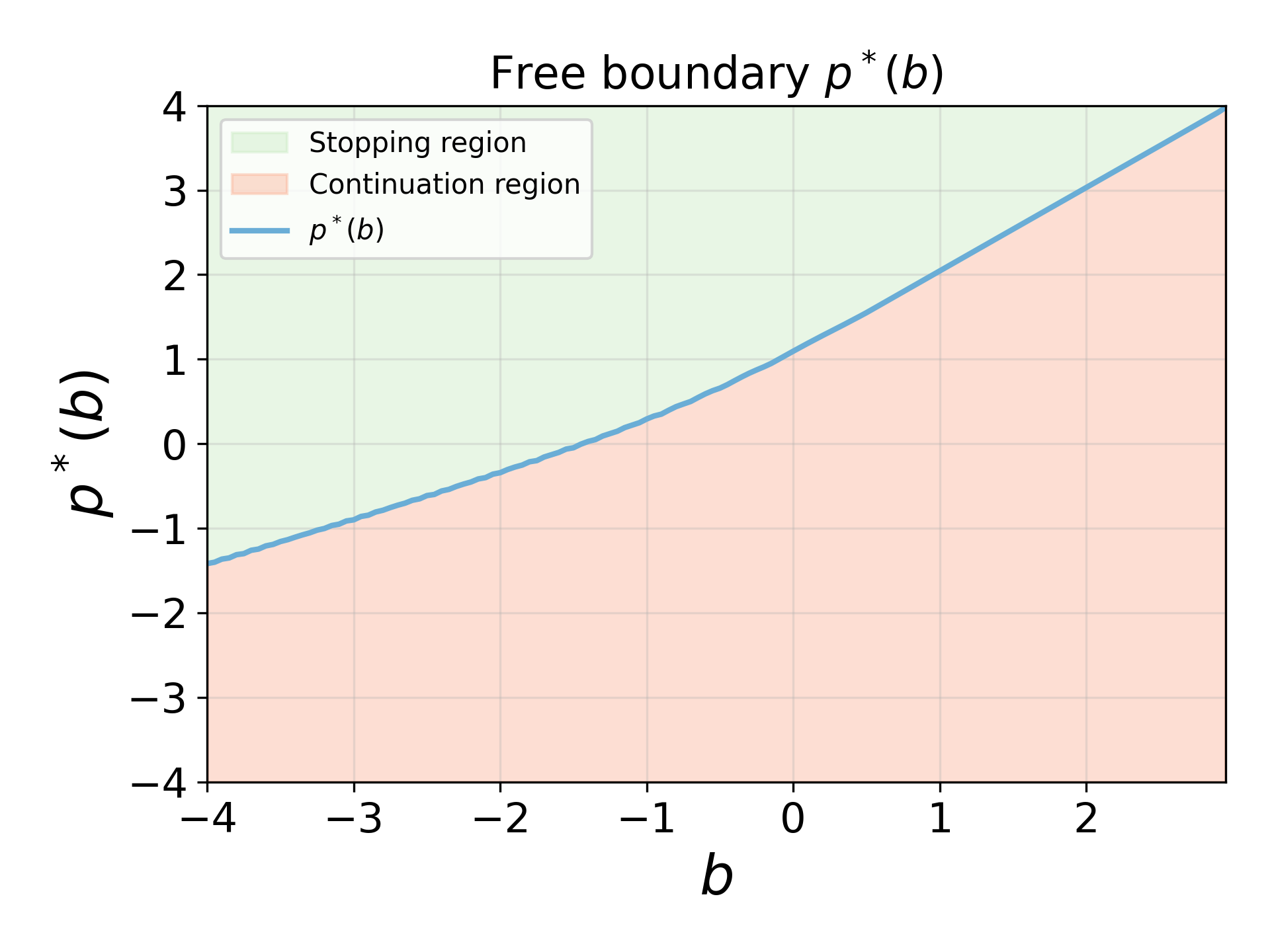
Figure 3: Free boundary Jt∈{0,1,2}7 for exit as a function of entry price Jt∈{0,1,2}8 with Jt∈{0,1,2}9, Xt=(Pt,Jt,Bt)0; higher entry increases the optimal exit threshold.
- The form of the optimal intensity density Xt=(Pt,Jt,Bt)1 changes sharply around the free boundaries, demonstrating how the agent transitions from exploration (uniform policy) to exploitation (spiked greedy policy).
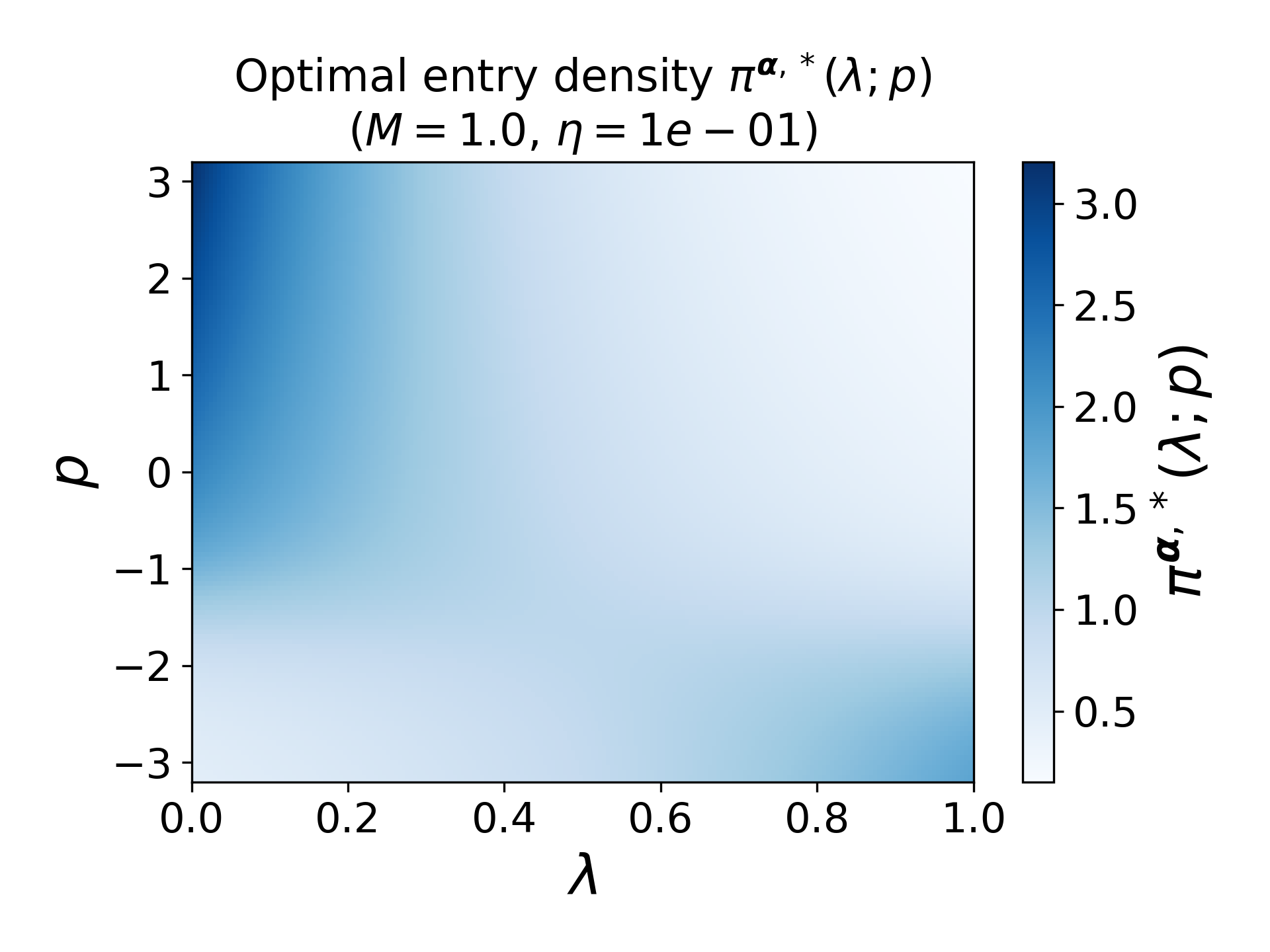
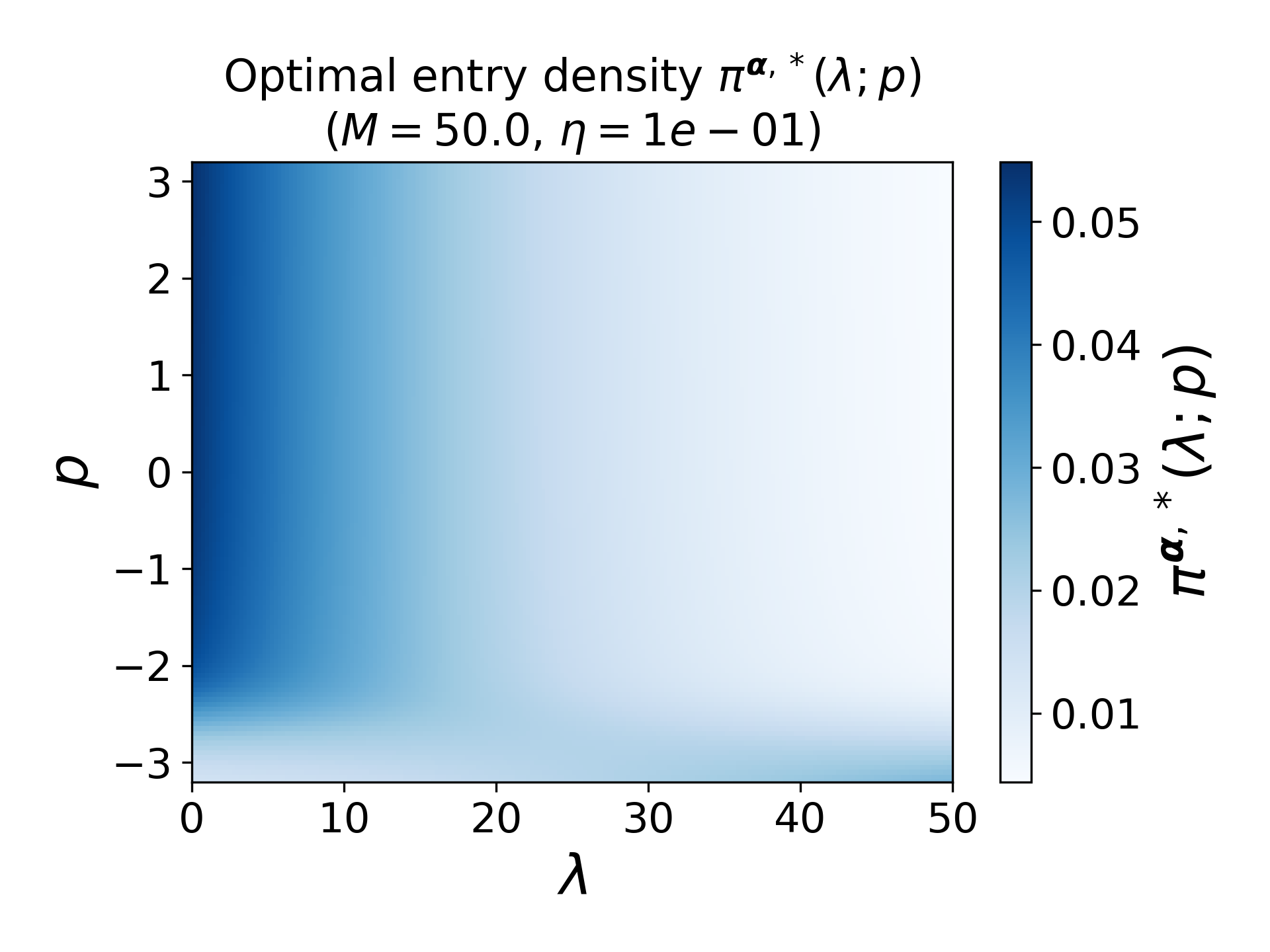
Figure 4: Entry density Xt=(Pt,Jt,Bt)2 for varying Xt=(Pt,Jt,Bt)3 when Xt=(Pt,Jt,Bt)4 is small, showcasing the concentration of action selection.
Model-Free Policy Iteration and Empirical Validation
Notably, the optimal control structure is leveraged for an offline model-free policy iteration algorithm, embedding Xt=(Pt,Jt,Bt)5 and Xt=(Pt,Jt,Bt)6 in deep neural networks and simulating exploratory trajectories based only on observed or synthetic signal paths. Empirical comparison shows the RL method's value function nearly matches the numerically solved HJB benchmark, with discrepancies only around regime boundaries due to higher functional sensitivity.
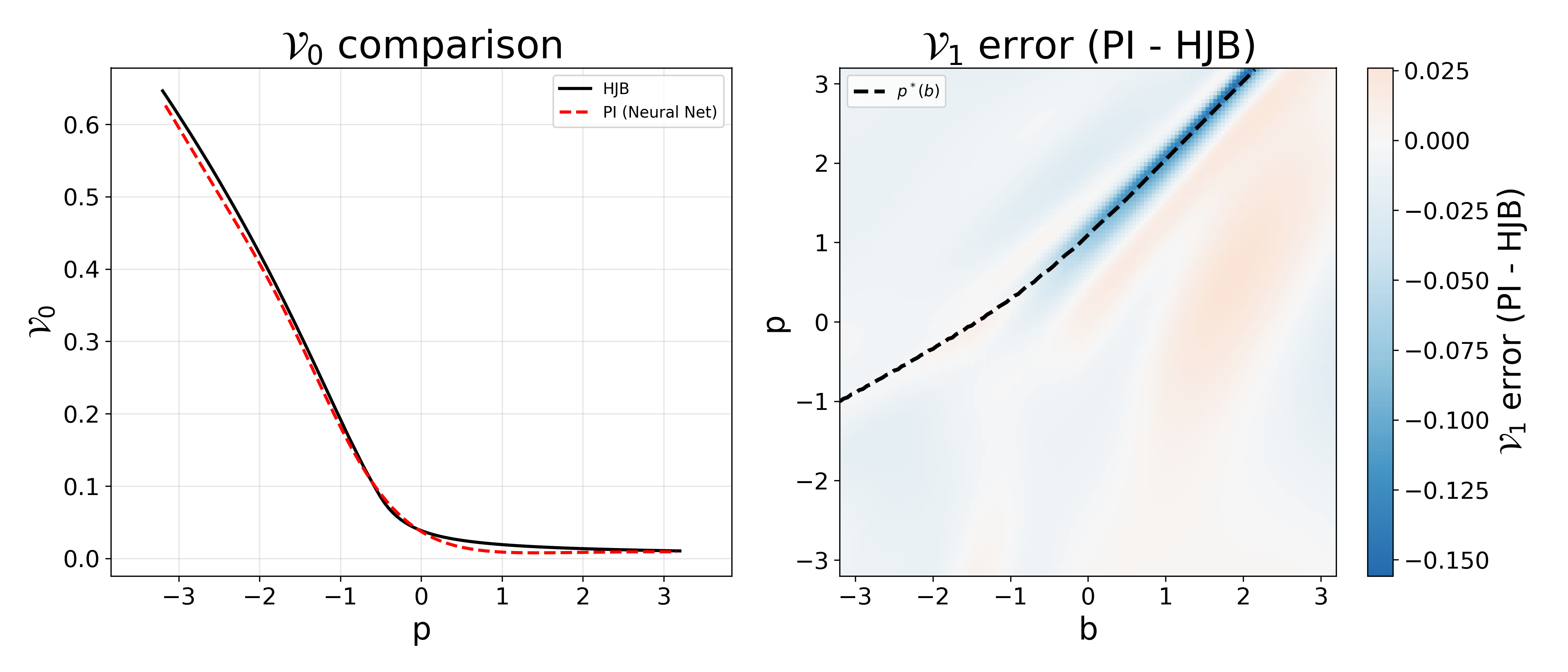
Figure 6: Comparison of Xt=(Pt,Jt,Bt)7 and Xt=(Pt,Jt,Bt)8 learned by policy iteration (neural networks) and by HJB solution (benchmark), for Xt=(Pt,Jt,Bt)9, πt0.
Implications and Theoretical Significance
This framework makes several assertive, technically impactful contributions:
- It validates entropy-regularized, continuous-time RL for non-trivial sequential entry/exit tasks—beyond the canonical one-off optimal stopping or simple LQ contexts.
- The adoption of randomized intensity policies and the use of entropy regularization aligns the RL agent with probabilistic exploration akin to what is imposed in modern on-policy RL in discrete settings, but in the context of stochastic timing.
- The constructive error bounds, based on explicit parameters, allow direct control of exploration-exploitation balance, and facilitate stable, monotone training routines.
On the theoretical front, the use of Shannon entropy relative to the uniform (Lebesgue) measure ensures regularization is non-positive, guaranteeing convergence from below and monotonic improvement as the exploration parameter is relaxed. The pathwise construction (shared Poisson/Brownian randomness for all policies) ensures rigorous comparison and error analysis.
Conclusion
This work establishes a rigorous and flexible method to deploy reinforcement learning for sequential trading decisions via exploratory randomized control of stopping intensities, supported by comprehensive error bounds and convergence analysis. Both theoretical development and computational schemes are validated on prospect-theory pairs-trading, where the approach achieves near-optimal performance as measured against classical HJB solutions.
This framework can be generalized to other optimal switching and impulse control tasks, and provides a foundation for scalable model-free RL in high-dimensional, path-dependent financial decision-making problems. Further analysis may include path-dependent functionals, transaction cost structures, and extension to multi-agent or mean-field trading environments, as well as integration with modern RL architectures for online data-driven trading.

