- The paper introduces a robust indoor human perception dataset addressing the limitations of existing outdoor benchmarks.
- It employs a semi-automated annotation pipeline leveraging foundation models to generate high-quality instance segmentation and tracking data.
- Benchmarking reveals trade-offs between speed, accuracy, and performance across dense, occlusion-prone indoor scenarios.
IndoorCrowd: A Multi-Scene Dataset for Robust Indoor Human Perception
Introduction and Motivation
The "IndoorCrowd" dataset addresses critical gaps in human detection, instance segmentation, and multi-object tracking (MOT) for indoor environments, which are underrepresented in existing benchmarks that are primarily oriented toward outdoor urban contexts. The paper systematically characterizes densely crowded indoor spaces and associated occlusion regimes, encountering challenges such as low-scale instances, complex architectural occlusions, and sharp intra-scene density fluctuations (Figure 1).

Figure 1: Representative frames from the four dataset scenes, capturing a wide spectrum of spatial complexity, scale variance, and occlusion regimes.
The authors motivate the need for this benchmark by referencing the limited diversity of annotation types (e.g., per-instance mask, tracking IDs) and environmental characteristics in previous works, citing alternatives such as CrowdHuman, WiderPerson, and MOTChallenge—all of which fall short on indoor-specific challenges. The IndoorCrowd dataset, in contrast, captures real-world indoor complexity at scale and introduces a semi-automatic annotation pipeline leveraging foundation models—focusing both on the efficiency/quality trade-off and reproducibility of the annotation process.
Dataset Design
The dataset comprises 31 surveillance-style videos (9,913 frames, 5 fps), acquired at four functionally distinct indoor public spaces within a university campus: ACS-EC (multi-level dense atrium), ACS-EG (linear corridor), IE-Central (entrance hall), and R-Central (column-interrupted central atrium). Scene selection ensures orthogonal variation in camera viewpoint, crowd density, spatial occlusion, and occupant mobility.
The annotation protocol is methodologically robust, involving:
- Human-verified per-instance segmentation masks and bounding boxes.
- A control subset (620 frames) for evaluating foundation model annotators and benchmarking their agreement with manual ground truth using Cohen's κ, AP, precision-recall, and mask IoU.
- A MOT subset (2,552 frames) with continuously-assigned identity tracks in MOTChallenge format, enabling rigorous tracking baselines and error analyses.
Notably, crowd density regimes, scale and aspect-ratio statistics, and occlusion rates are comprehensively analyzed. The ACS-EC atrium exhibits extreme density variance, with 79.3% of frames in the “dense” regime and mean person counts exceeding 12 per frame (Figure 2).
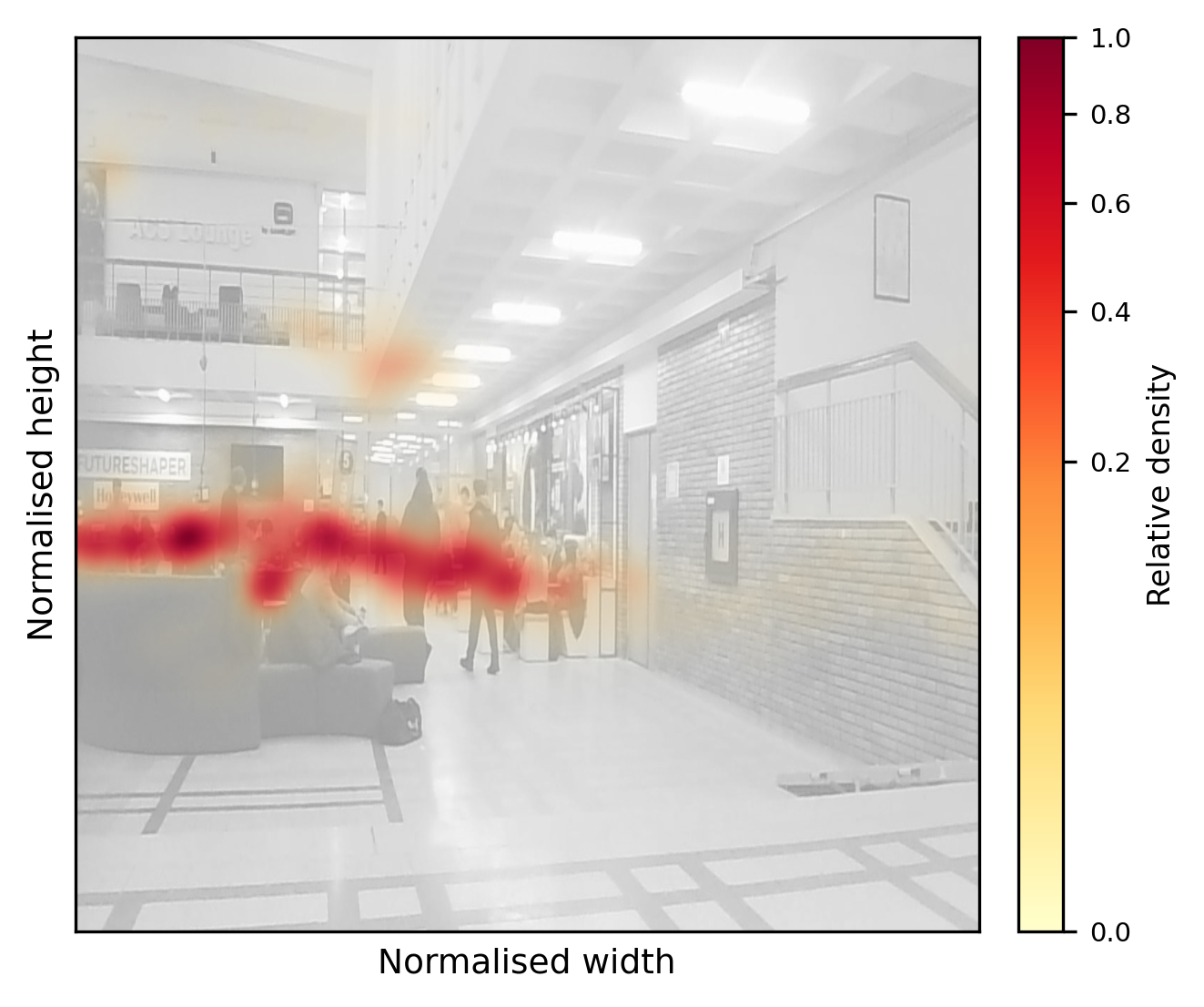
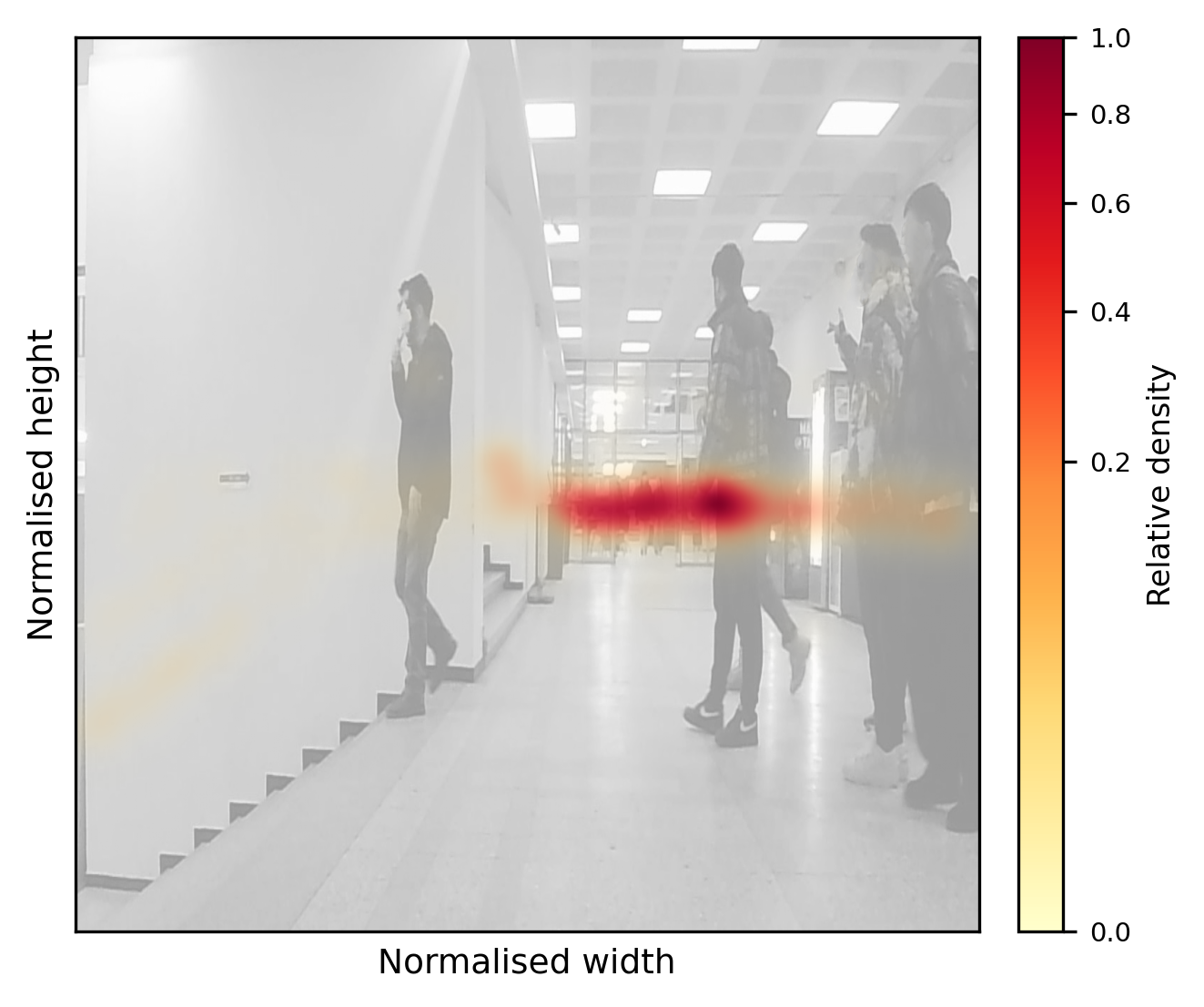
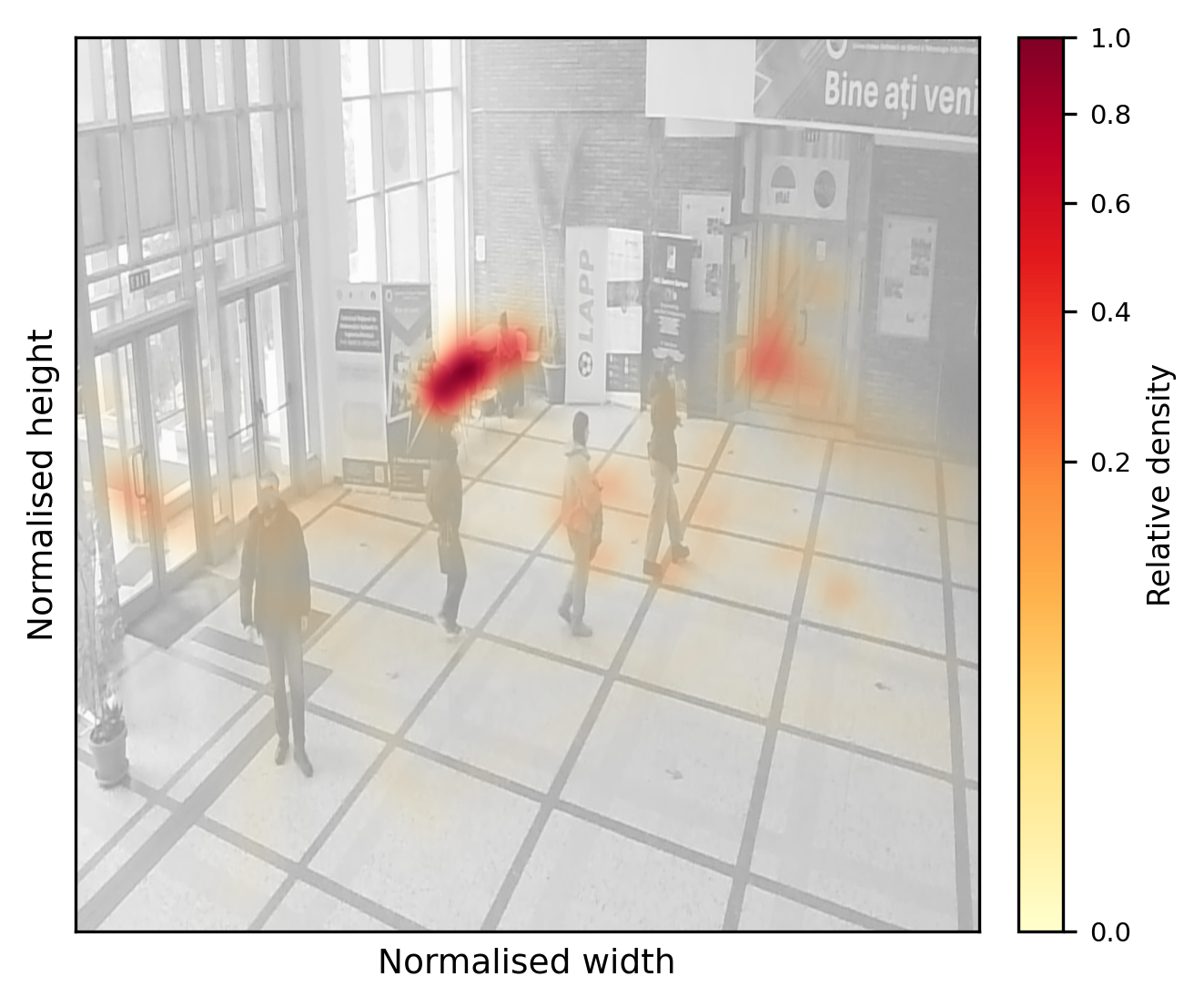
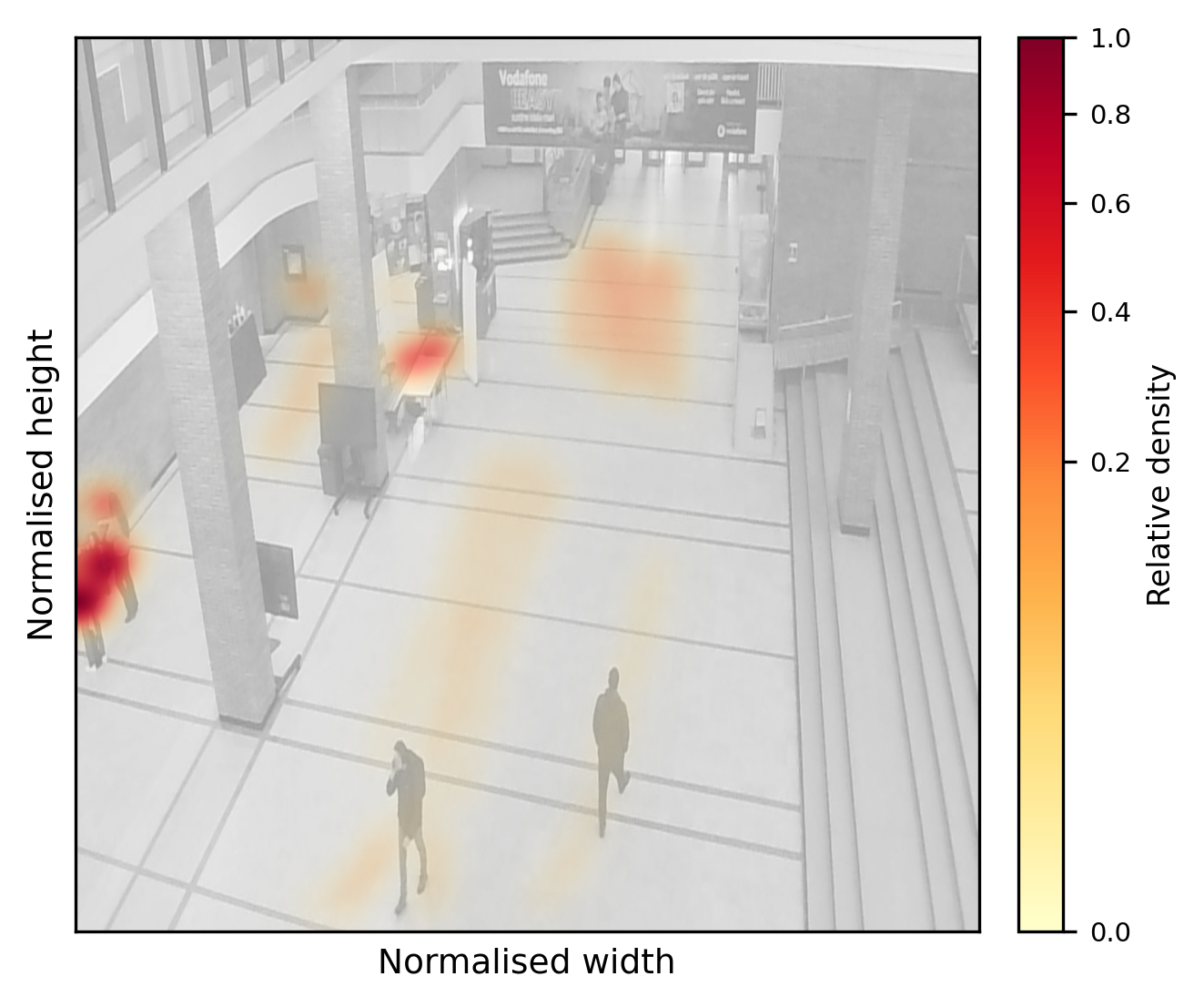
Figure 2: High-density ACS-EC scene visualizing mixed stationary and mobile person clusters, which drive detection and tracking complexity.
Annotation Pipeline and Foundation Model Evaluation
IndoorCrowd's annotation pipeline systematically integrates state-of-the-art foundation models (SAM3, GroundingSAM, EfficientGroundingSAM) as auto-labelers for instance-level mask proposal. The control subset facilitates per-scene benchmarking with respect to human ground truth. Key findings include:
- SAM3 achieves the highest recall (0.88–0.98 across scenes) but low precision in the densest scene (0.52 for ACS-EC), yielding high-recall/low-precision masks optimal for downstream human correction.
- GroundingSAM and EfficientGroundingSAM offer higher precision (0.83–0.93) but lower recall, and the efficient variant maintains comparable quality at reduced inference cost.
- Across scenes, ACS-EC—a dense and cluttered atrium—provokes the greatest drop in all auto-annotation metrics, confirming it as the most challenging scenario.
In qualitative assessments (Figure 3), SAM3 introduces substantial false positives in the densest scenes, while GroundingSAM systematically misses highly occluded individuals, aligning with the numerical benchmarking.

Figure 3: Comparison of auto-labelling (SAM3, GroundingSAM) against human ground truth; SAM3 yields false positives in high-density contexts, GroundingSAM underdetects occluded individuals.
Object Detection and Instance Segmentation
Models ranging from lightweight YOLO variants (YOLOv8n, YOLOv26n) to high-capacity RT-DETR-L are evaluated. Results show:
- RT-DETR-L establishes the overall upper bound in both box [email protected] (0.911) and mask mAP, but with significantly higher computational requirements.
- YOLOv8n-seg achieves the highest accuracy–latency trade-off, delivering competitive detection and segmentation at 1.89 ms/frame, making it ideal for resource-constrained environments.
- Classical detection models saturate in medium-density scenes but degrade sharply on ACS-EC due to small instance size and extreme congestion.
Multi-Object Tracking
Combinations of detection and tracking algorithms (ByteTrack, BoT-SORT, OC-SORT) are benchmarked using MOTA, IDF1, MT/ML rates, identity switch counts, and runtime. Principal results:
- RT-DETR-L paired with OC-SORT attains maximal MOTA (56.2), with BoT-SORT yielding the lowest identity switches and highest IDF1 (71.8).
- YOLOv8n+ByteTrack achieves real-time rates (>100 FPS) but at reduced accuracy; thus, there is a clear trade-off between efficiency and performance dictated by scene density and occlusion complexity.
- Scene complexity ranking is unambiguous: ACS-EC and R-Central exhibit maximal tracking difficulty owing to density, occlusion, and overhead viewpoints, while ACS-EG and IE-Central are more tractable.
Annotation Corrections and Tracking Curation
Analysis of automatic tracklet generation and human corrections reveals distinct failure modes: BoT-SORT associations yield longer, more coherent tracks but require extensive ghost track removal and merging; SAM3-native proposals are shorter and noisier, demanding intensive interpolation. Human review is indispensable for identity assignment stability in complex indoor flows.
Implications and Future Directions
The IndoorCrowd dataset has multiple practical and theoretical implications:
- It provides a new, reproducible benchmark for model selection and architecture robustness analysis in indoor human perception tasks.
- The open, systematic annotation procedure employing foundation models will inform future dataset collection protocols, reducing annotation costs while preserving high agreement with human ground truth.
- Results underline the limitations of currently prevailing architectures in high-density, occlusion-dominated indoor regimes and provide quantifiable baselines for future progress.
- Potential developments include extending to night/low-light regimes, broadening architectural diversity, and annotating for person re-identification and behavior understanding.
Conclusion
"IndoorCrowd: A Multi-Scene Dataset for Human Detection, Segmentation, and Tracking with an Automated Annotation Pipeline" (2604.02032) establishes a comprehensive, methodologically robust foundation for advancing indoor human perception. The dataset’s design, annotation pipeline, and thorough quality analysis together create a new standard for reproducibility and realism in benchmarks targeting crowded, complex indoor environments. The empirical findings quantify the limits of current foundation models and detection/tracking pipelines, especially in dense and highly occluded settings. The dataset and associated baselines are expected to be influential references for future research in surveillance, smart buildings, and robust crowd analytics.

