- The paper introduces LinkS2Bench, a benchmark comprising over 17,900 high-quality VQA pairs from UAV video and satellite imagery to evaluate cross-view spatial intelligence.
- It reveals substantial performance gaps between state-of-the-art VLMs and human baselines, with explicit cross-view alignment challenges dominating failures.
- The study proposes the Cross-View Alignment Adapter (CVAA), which improves localization and relational tasks by leveraging contrastive learning for spatial grounding.
Comprehensive Evaluation of VLMs for UAV–Satellite Cross-View Spatial Intelligence: LinkS2Bench
Introduction
The interaction between Unmanned Aerial Vehicles (UAVs) and satellites is pivotal for large-scale real-world spatial intelligence in applications such as autonomous navigation, wide-area surveillance, and disaster response. Integrating the dynamic, high-resolution observations from UAVs with stable, global satellite imagery remains a significant challenge for Vision-LLMs (VLMs), given the extreme scale, viewpoint, and dynamic domain discrepancies involved. To date, prior benchmarks have failed to encapsulate the essential local-to-global dynamic correspondence required for robust cross-view reasoning. "Are VLMs Lost Between Sky and Space? LinkS2Bench for UAV-Satellite Dynamic Cross-View Spatial Intelligence" (2604.02020) introduces the LinkS2Bench benchmark, directly addressing this critical evaluation gap and providing infrastructure for the advancement and diagnosis of multimodal models in this domain.
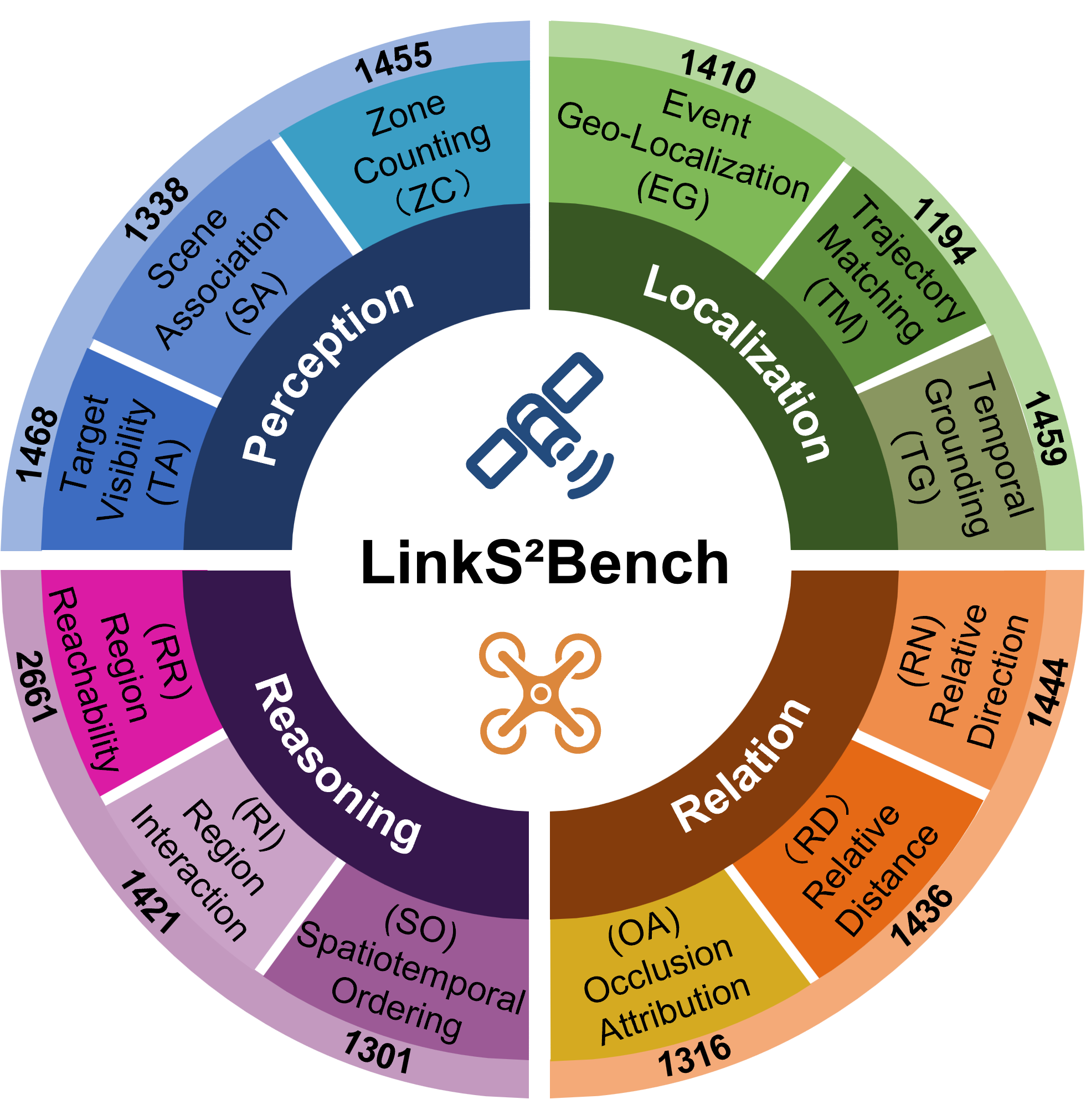
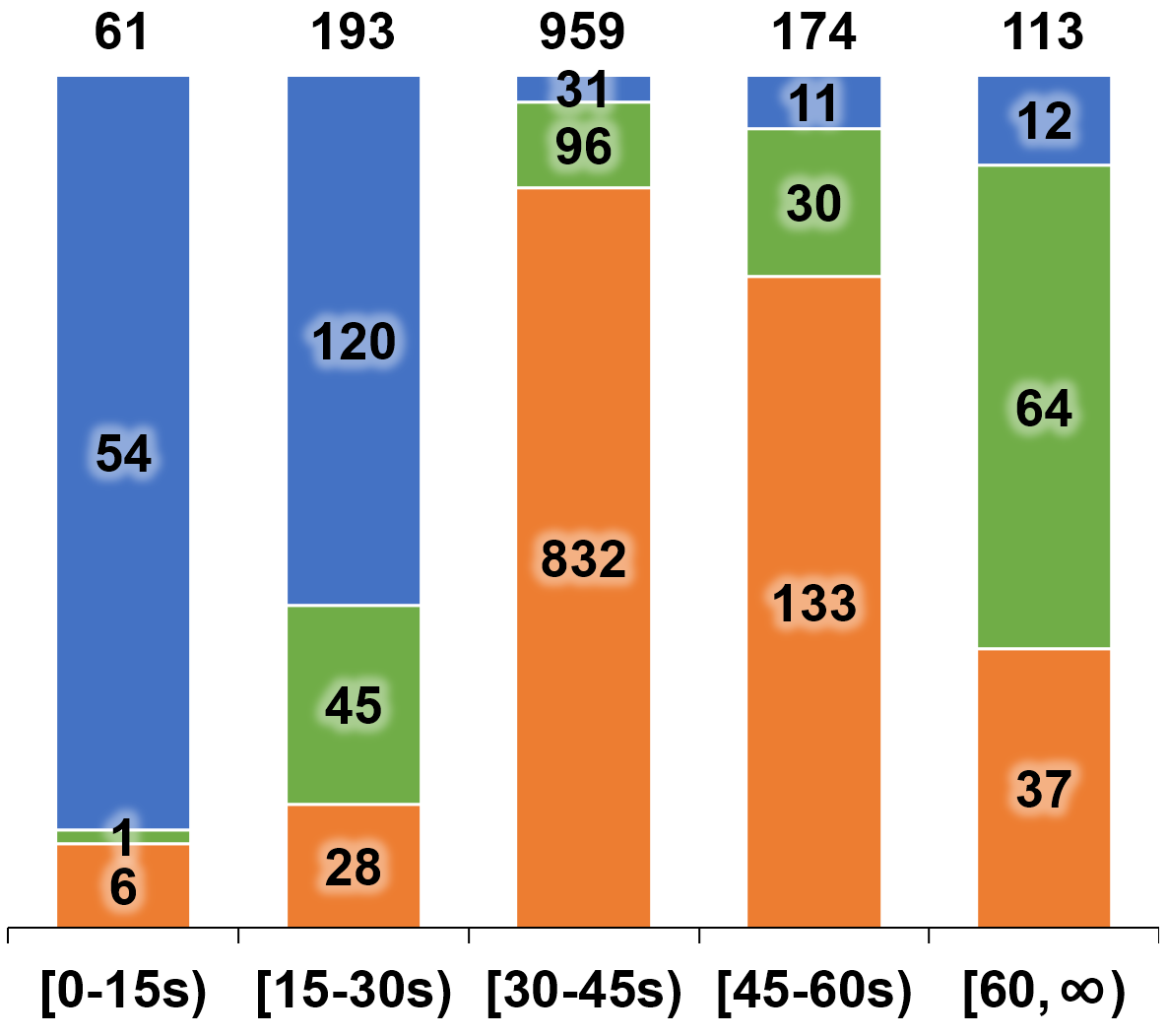
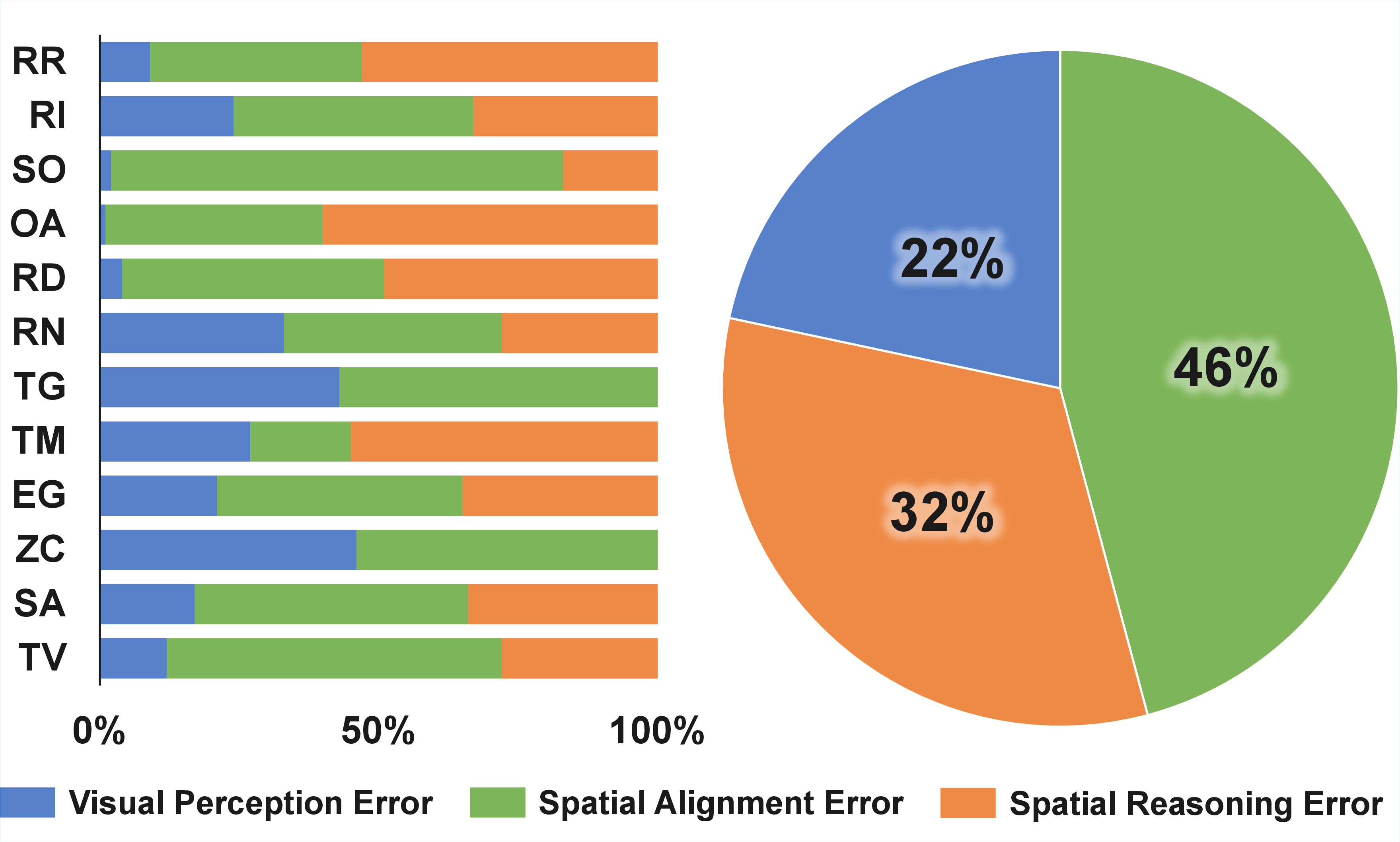
Figure 1: (a) Statistics of task distribution across four main categories. (b) Data source breakdown by video duration.
LinkS2Bench comprises over 17,900 high-quality VQA pairs constructed from 1,500 UAV video clips (over 1,022 minutes), aligned with 43,273 satellite images covering a global area above 200 km². Data is collected from 16 cities using diverse sources, curated via a semi-automated pipeline involving VLMs and extensive manual annotation, resulting in robust, high-fidelity QA instances.
Task design is a cornerstone of LinkS2Bench—it encompasses 12 fine-grained tasks, grouped under four critical capability dimensions:
- Perception: Cross-view correspondence (target visibility, scene association, zone counting).
- Localization: Dynamic spatiotemporal anchoring (temporal grounding, event geo-localization, trajectory matching).
- Relation: Multi-entity and region relation modeling (relative distance, relative direction, occlusion attribution).
- Reasoning: Higher-level sequential and interaction-based reasoning (region reachability, spatiotemporal ordering, region interaction).
These tasks require explicit alignment between local UAV video perspective and the global satellite map, pushing VLMs to operate in a regime unaddressed by prior benchmarks.
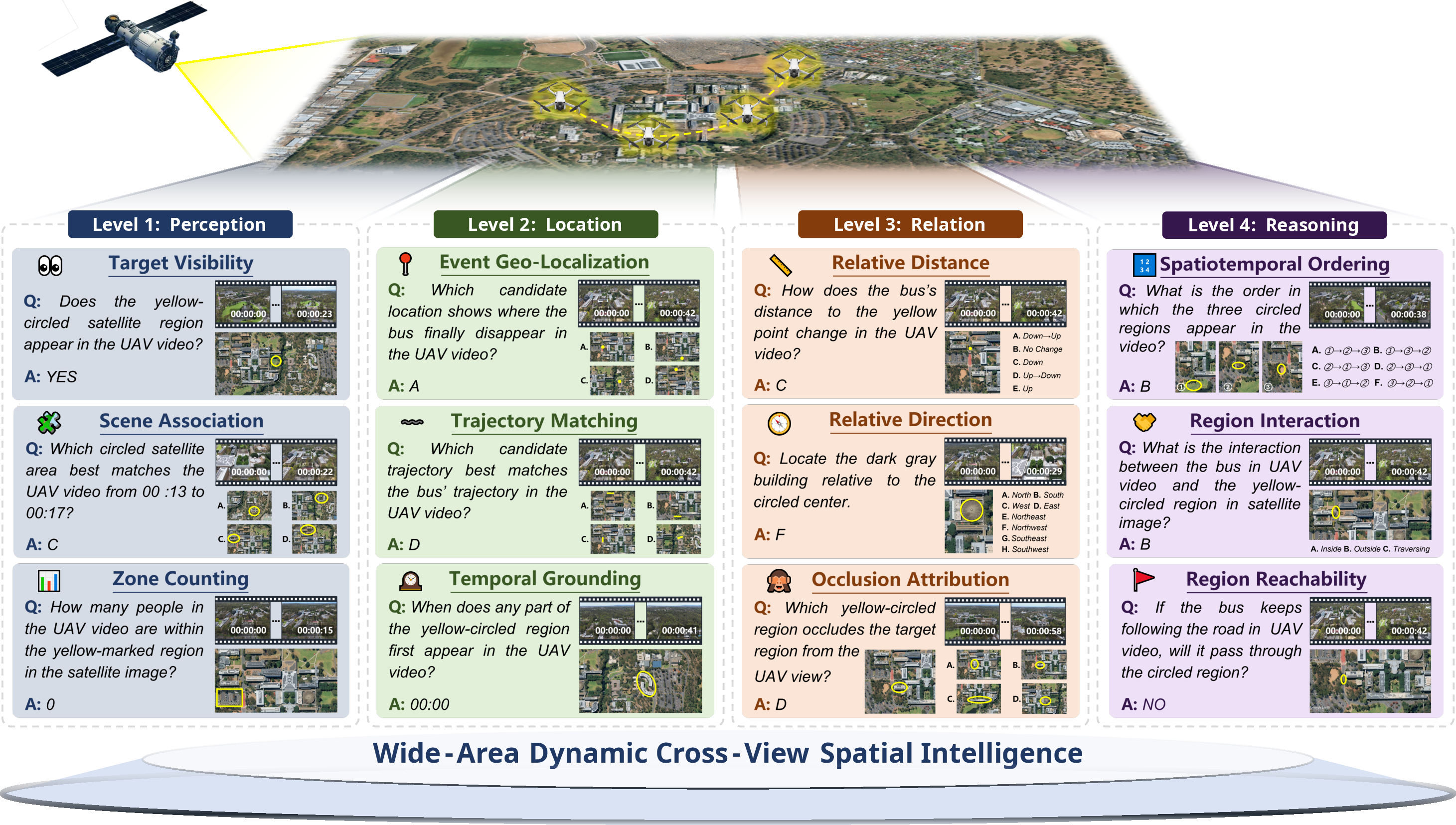
Figure 2: LinkS2Bench tasks span Perception, Location, Relation, and Reasoning, with satellite crops shown only for visualization; benchmark samples maintain full spatial context.
The benchmark curation pipeline encompasses data collection, QA generation leveraging LMMs, meticulous human annotation, and layered manual quality control for annotation integrity.
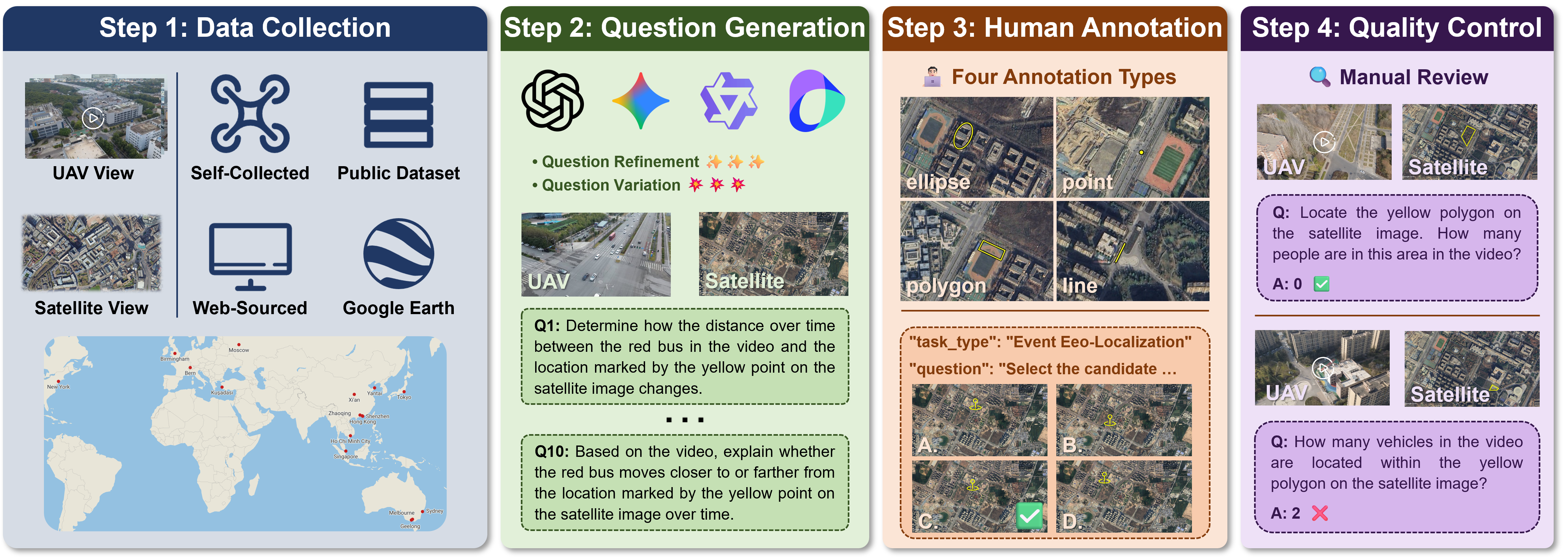
Figure 3: Pipeline for data collection, question formulation via LMMs, precise human annotation, and quality assurance.
Model Evaluation and Error Analysis
Evaluations are conducted across 18 representative VLMs, both proprietary (Gemini-3.1, GPT-5.4, Claude-Sonnet, Doubao-seed) and open-source (Qwen3.5, GLM-4.6V-Flash, LLaVA-OneVision, etc.), alongside extensive human baselines. Models are uniformly evaluated with task-appropriate metrics: accuracy (ACC), mean relative accuracy (MRA) for numerics, or ACC@1s for timestamp questions.
Key results:
Correlation analysis of inter-task performance further reveals that localization-related skills are foundational, with strong mutual correlations among tasks requiring explicit mapping from local video to global map coordinates, while other tasks exhibit more specialized and less overlapping challenges.
The Cross-View Alignment Adapter (CVAA)
Addressing the bottleneck of dynamic cross-view alignment, the paper introduces the Cross-View Alignment Adapter (CVAA), an explicit feature alignment module optimized via contrastive learning. CVAA learns direct correspondences between UAV and satellite modalities and, during inference, functions as a retriever to provide accurate spatial grounding cues as priors to the downstream VLM.
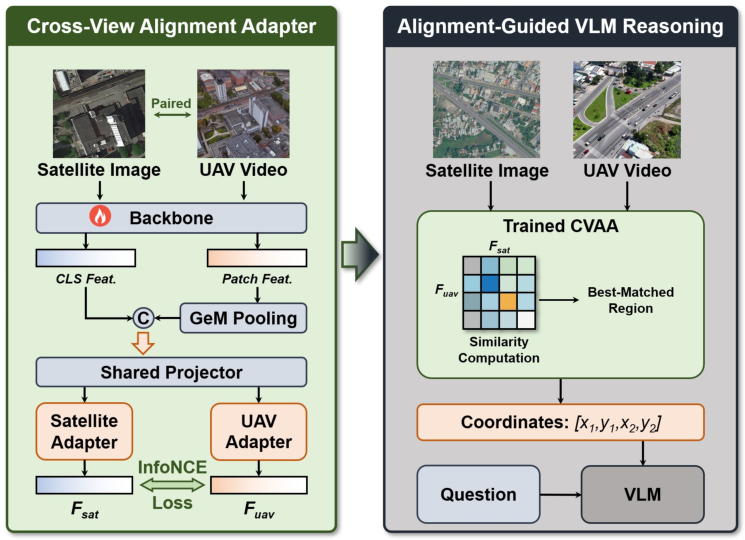
Figure 5: The CVAA leverages a dual-branch architecture for explicit cross-view feature alignment, enhancing VLM grounding and reasoning performance.
Incorporation of CVAA yields consistent improvements: Gemini-3.1-Pro increases from 51.1% to 55.4% (overall), while GPT-5.4 improves by 4.4 points. Gains are concentrated in localization and certain relational tasks, empirically validating the importance of explicit cross-view priors for spatial grounding.
Model Adaptation and Benchmark Utility
Supervised fine-tuning on LinkS2Bench provides further evidence of its value beyond evaluation. Fine-tuned Qwen3.5 models demonstrate absolute average gains of up to 24.4 percentage points. Combination with CVAA is synergistic, showing additional increases, even post-adaptation. This demonstrates that explicit cross-view spatial knowledge and priors are not fully captured through end-to-end adaptation and require dedicated architectural solutions.
Implications and Future Directions
The introduction of LinkS2Bench delivers several theoretical and practical signals:
- Benchmarking: Existing VLMs are not inherently equipped for dynamic local–global cross-view spatial intelligence; task design and evaluation must consider these explicit alignment challenges.
- Architectural advances: Architectural priors such as CVAA—and, more generally, explicit feature alignment modules—are essential for next-generation multimodal foundation models tackling large-scale real-world spatial reasoning tasks.
- Supervision and adaptation: Rich, well-constructed cross-view datasets substantially facilitate VLM transfer and adaptation. However, further architectural research is necessary for compositional generalization in extreme spatial settings.
- Application domains: Direct implications for UAV–satellite collaborative intelligence, critical infrastructure monitoring, search-and-rescue, and any application demanding seamless fusion of dynamic and static spatial inputs.
Conclusion
LinkS2Bench establishes a challenging, high-fidelity testbed for UAV–satellite cross-view spatial intelligence, exposing critical limitations and capability gaps in state-of-the-art VLMs. This work demonstrates that explicit cross-view alignment is a necessary architectural prior, and that benchmarks like LinkS2Bench are imperative both for diagnosis and for driving supervised adaptation. This resource will likely underpin future research in multimodal local–global reasoning, providing the requisite foundation for robust, real-world spatial intelligence models.
Reference: "Are VLMs Lost Between Sky and Space? LinkS20Bench for UAV-Satellite Dynamic Cross-View Spatial Intelligence" (2604.02020).