- The paper introduces WAV, a method that decomposes world model verification into state plausibility and action reachability components.
- The methodology leverages abundant action-free data and sparse inverse dynamics, ensuring sample-efficient predictions in high-dimensional environments.
- Empirical evaluations across MiniGrid and robotic manipulation benchmarks demonstrate that WAV improves policy rewards by up to 18% over baseline methods.
Introduction
World models—action-conditioned predictors of future states—are foundational in enabling scalable policy evaluation, optimization, and planning for robotics and embodied agents. However, robust generalization outside well-characterized data regimes remains a core challenge, especially given the expense and limited coverage of action-labeled interaction data. The "World Action Verifier: Self-Improving World Models via Forward-Inverse Asymmetry" (2604.01985) introduces the World Action Verifier (WAV), an architecture and methodology to self-improve world models by leveraging two key structural asymmetries: (1) action-free data is orders of magnitude more abundant than labeled robot interactions, and (2) action-relevant features typically comprise a low-dimensional subset of the full state. WAV exploits these asymmetries through decomposition of verification into complementary state-plausibility and action-reachability factors, which are solved respectively by a subgoal generator (from broad video data) and a sparse inverse model (from labeled interaction data). This essay examines the paper's theoretical results, experimental findings, and implications for future world modeling and policy learning in robotics and beyond.
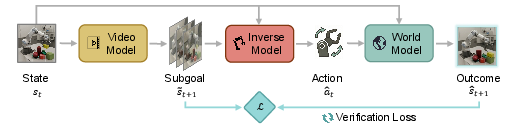
Figure 1: Overview of World Action Verifier: a self-improving cycle linking subgoal generation, sparse inverse action inference, and forward-model rollouts.
Methodology: Decomposition and Cycle Consistency
The core methodological contribution of WAV is the decomposition of action-conditioned world model verification into two tractable subproblems—state plausibility and action reachability.
State plausibility checks whether a predicted future state is feasible under environment dynamics, framed as an out-of-distribution (OOD) detection problem. By leveraging massive action-free video corpora to learn a generative subgoal proposal model, WAV anchors candidate futures on the support of visually and physically plausible transitions, enabling much broader coverage than what action-labeled interaction data can provide.
Action reachability verifies that a transition is achievable under the given action. A key insight is that, for most robotic/embodied domains, actions are reflected in a compact, agent-centric feature subspace (e.g., end-effector pose or proprioceptive signals). This supports the use of a sparse inverse dynamics model, trained to infer the action from compressed representations of state pairs. The model's sparse mask is learned and focuses adaptively on action-relevant features, promoting generalization.
The overall architecture constitutes a reverse cycle: from the current state, plausible subgoals are proposed, the inverse model infers the requisite action, and the forward model attempts to realize the transition. The discrepancy between the subgoal and the rollout provides a reliable verification signal, guiding prioritized exploration and data acquisition in under-explored regions.
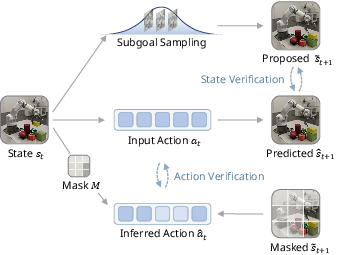
Figure 2: Schematic decomposition of verification: state plausibility (broad, action-free manifold) and action reachability (inverse dynamics in action-relevant subspace).
Theoretical Analysis: Robustness and Sample Efficiency
The manuscript analytically demonstrates why sparse inverse verification is statistically and practically easier than dense forward prediction, especially in high-dimensional stochastic environments. This is formalized with two principal results:
- Distribution Level Robustness (Compositional OOD): If action-relevant features (the sparse subset) remain in-distribution even as full-scene transitions become OOD, the sparse inverse model continues to generalize, whereas dense forward (or dense inverse) models fail. The paper makes explicit assumptions about blockwise latent structure, causal insulation, and action identifiability for rigorous guarantees.
- Sample-Efficiency Gap: Leveraging linear-Gaussian models, the expected error ratio between dense forward models and sparse inverse verifiers amplifies with (i) the dimensionality ratio between full and action-relevant state, (ii) environment stochasticity, and (iii) when labeled data is limited. The theoretical ratio aligns with empirical gaps, which become dramatic in the low-data, high-dimensional regime.
Empirical Evaluation: Robust Verification and Efficient Exploration
Extensive experiments validate three main research questions: (RQ1) robustness and sample-efficiency of sparse inverse verification, (RQ2) generalization beyond training support, and (RQ3/RQ4) ultimate improvement in world model and downstream policy quality.
MiniGrid Experiments
Controlled studies in MiniGrid support all theoretical predictions: as the number of objects increases, the forward model's performance degrades sharply but sparse inverse models retain accuracy; as observation noise increases, only the forward model suffers. Critically, WAV's verification scores display superior monotonic alignment with actual prediction errors, while uncertainty and learning-progress baselines produce noisy or misleading rankings.

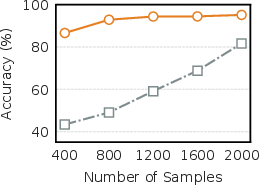
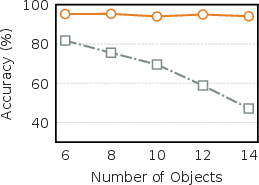
Figure 3: Verification of robustness in MiniGrid: (Left) sample efficiency; (Mid) robustness to state dimension; (Right) robustness to stochasticity.


Figure 4: World-model learning in MiniGrid: (Left) action prediction accuracy of sparse vs. dense inverse models; (Mid) Spearman/Kendall rank correlation to Oracle; (Right) comparative efficacy in data acquisition.
Qualitative analysis further reveals that random or heuristic-based exploration over-selects redundant or movement actions, while WAV targets informative, interaction-centric transitions (e.g., "Toggle", "Swap"), yielding substantial improvements in rollouts for previously undersampled action-object compositions.
Robotic Manipulation Benchmarks (RoboMimic, ManiSkill)
In diverse high-dimensional manipulation tasks, WAV consistently achieves the highest rank correlation to Oracle error, more accurate world model predictions (lower MSE at all data budgets), and amplified benefits in sparse-data regimes.
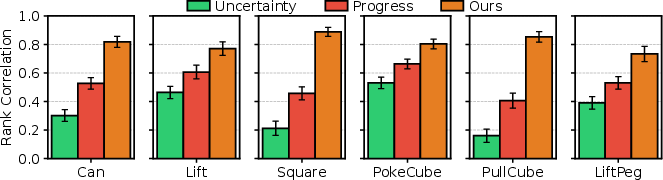
Figure 5: Correlation between WAV verification and ground-truth Oracle scores for Robomimic/ManiSkill; higher is better.
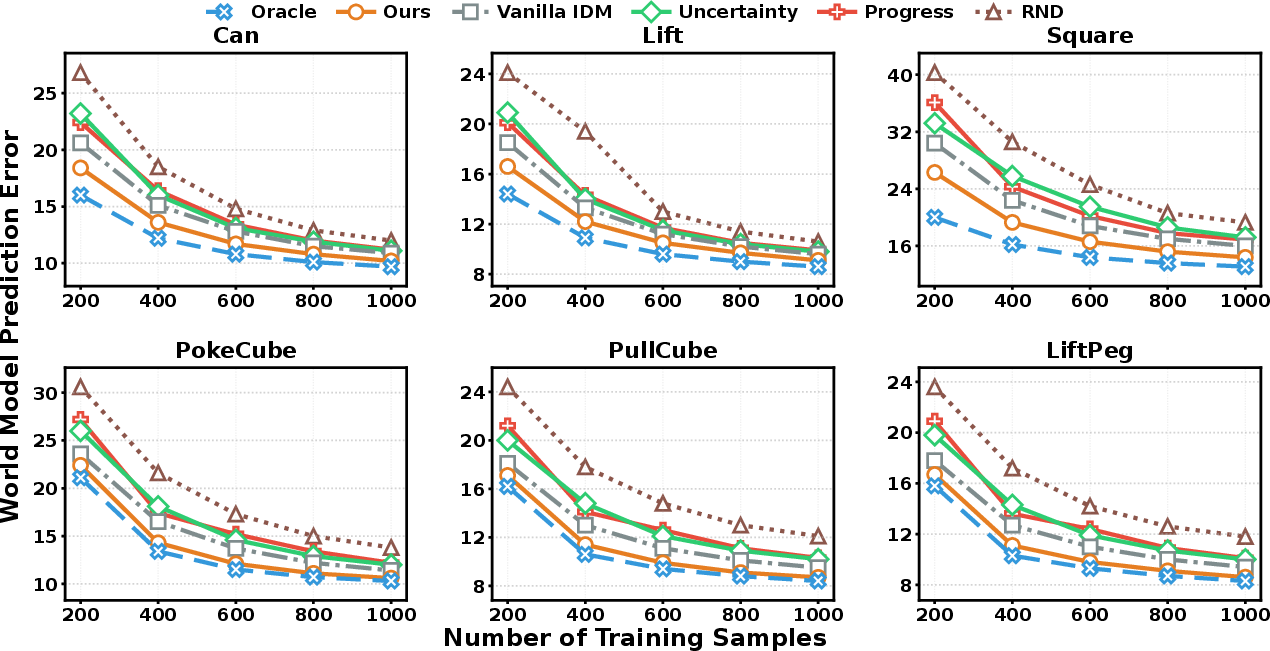
Figure 6: Observation prediction curves for RoboMimic/ManiSkill: WAV enables more accurate predictions with fewer samples than all baselines.
Most notably, downstream policy learning benefits directly: policies trained with WAV-improved world models achieve on average 18% higher reward than the strongest baseline, nearly matching the Oracle with privileged knowledge on several tasks.
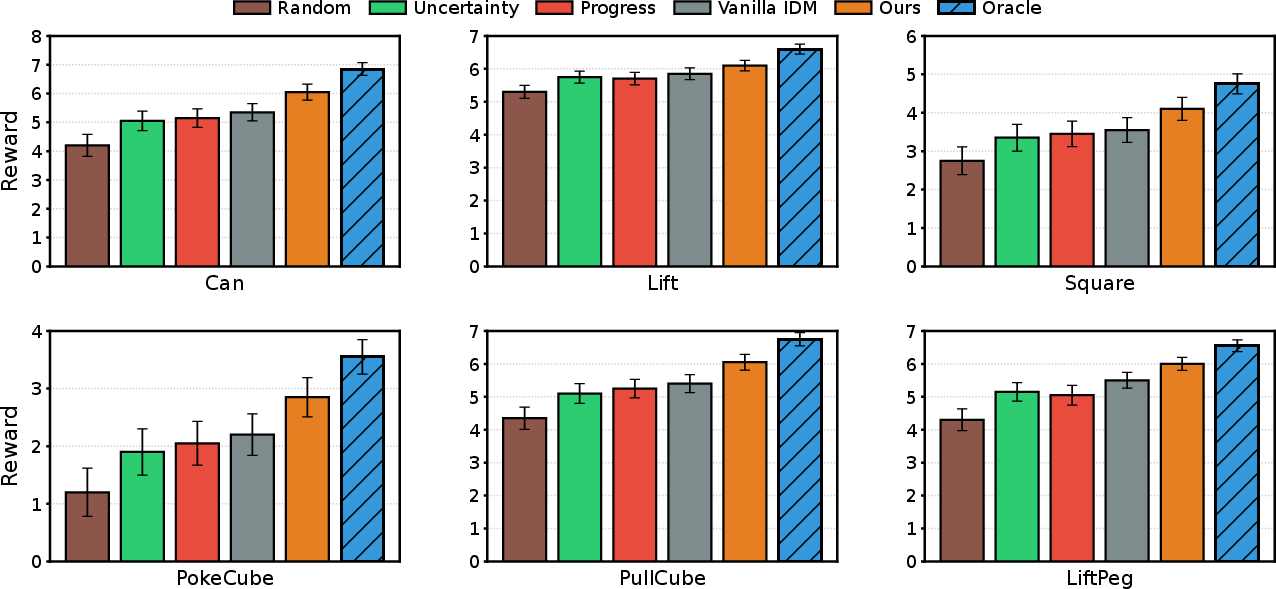
Figure 7: Downstream policy rewards: WAV-augmented models drive substantial gains over competitor methods in all tasks evaluated.
Analysis: Verification Alignment and Data Selection
Complementary analyses visualize the strong alignment between WAV's verification signal and true error (Figure 8) and show that WAV preferentially selects samples that are challenging under the current model, in contrast to baselines that often miss hard transitions or focus on easy/redundant samples.
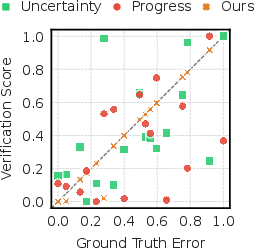
Figure 8: Scatter of WAV verification score vs ground-truth error: tight monotonic relationship for WAV; poor calibration for uncertainty/progress.
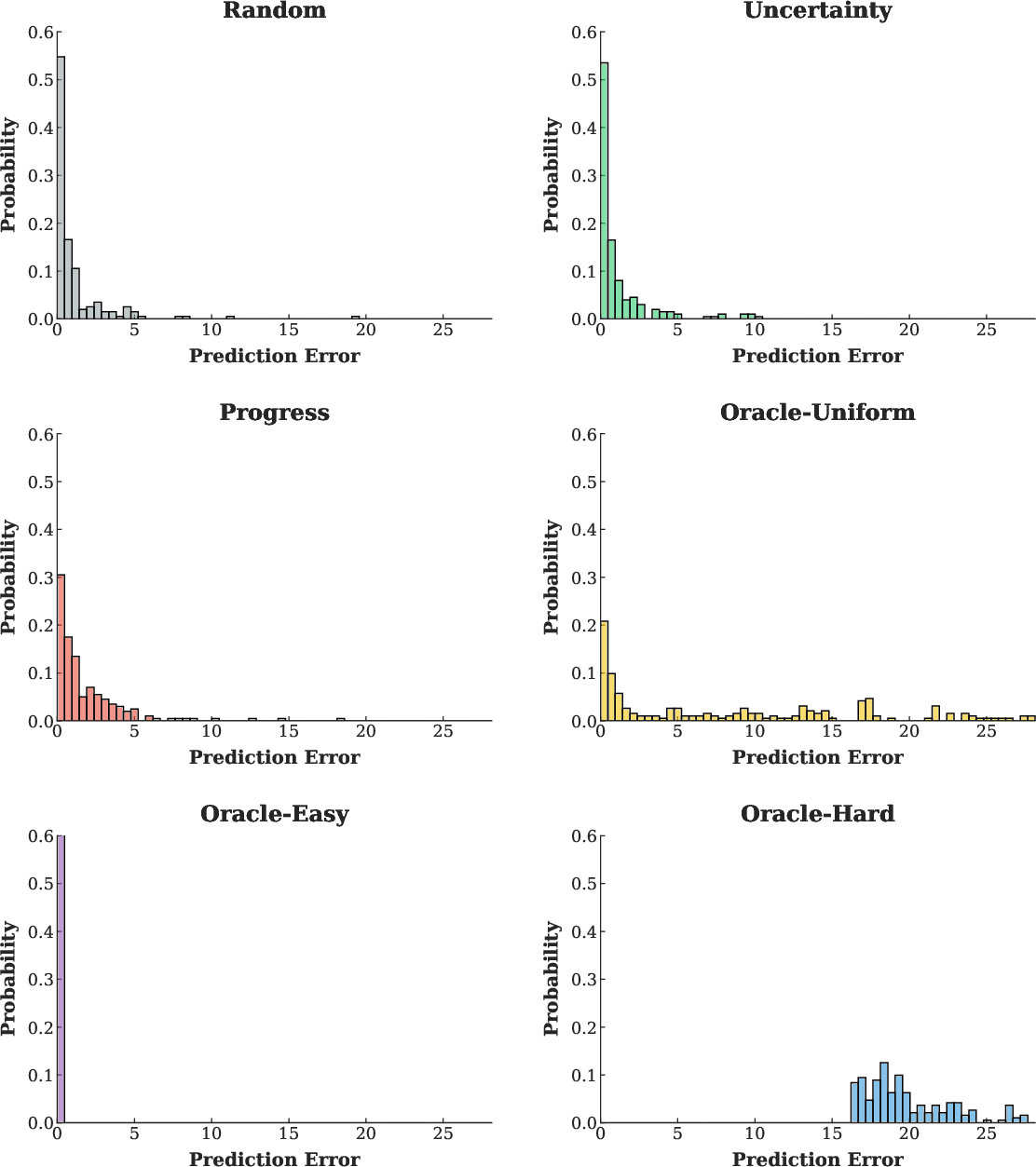
Figure 9: Distribution of world model prediction error for candidate data—WAV acquires more informative samples than other methods.
Qualitative open-loop rollouts and comparative predictions underline the practical utility of improved data selection: interaction-induced state changes (especially for rare actions) are better modeled by WAV-enabled architectures, translating to both quantitative and task-relevant gains.
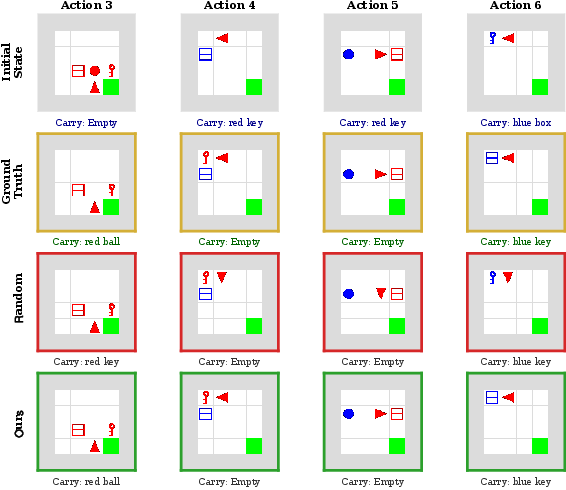
Figure 10: Qualitative world-model rollouts in MiniGrid for diverse actions—WAV-trained models capture complex transitions robustly.
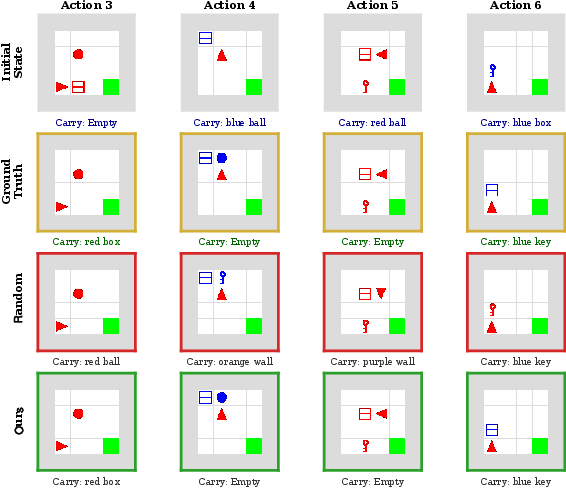
Figure 11: Extended qualitative rollouts—WAV outperforms random selection, especially on rare/intermediate interaction sequences.

Figure 12: World model predictions for Robomimic Lift—WAV preserves fine-grained, action-driven state correlations.

Figure 13: World model predictions for Robomimic Square—WAV maintains coherence over longer horizons than baselines.
Implications and Future Directions
This work demonstrates that, under broad and practically justified conditions, self-improving cycles that decompose verification into sparse inverse and generative components enable more robust, sample-efficient, and ultimately performant world models and downstream policies. The approach fundamentally exploits structural properties of embodied domains—namely, the decoupling between high-dimensional scene observations and low-dimensional action imprints—yielding a clear separation of statistical difficulty not addressed by prior work that relies primarily on uncertainty estimation or curiosity-based heuristics.
The implication for large-scale (possibly internet-pretrained) world modeling is clear: advances in verification, particularly those exploiting forward–inverse asymmetries, may be as impactful as scaling world models themselves (2604.01985, Kwok et al., 12 Feb 2026). Further developments could integrate richer generative subgoal priors and more expressive inverse dynamics models, scale to longer-horizon tasks, or merge verification cycles into more computationally efficient architectures via joint parameterization or adaptive computation.
The framework is also highly relevant to emerging lines on world-model-based policy alignment, offline data curation, and test-time scaling—areas where robust, reliable error estimates are critical in open-world settings.
Conclusion
The World Action Verifier introduces a concrete, theoretically sound, and empirically validated mechanism for self-improving world models by exploiting the forward–inverse asymmetry present in action-conditioned prediction. By integrating cycle consistency over subgoal generation, action inference, and forward rollout in an exploration-guided loop, WAV establishes a new state-of-the-art in sample-efficient world modeling, robust generalization, and downstream policy optimization. The validation across synthetic and realistic manipulation benchmarks confirms both the feasibility and impact of decomposed verification for embodied intelligence, pointing to new research at the interplay of generative modeling, verification, and autonomous self-improvement.