- The paper introduces LI-DSN, which overcomes information silos by enabling continuous cross-stream interaction using a novel Temporal-Spatial Integration Attention (TSIA) mechanism.
- It outperforms 13 state-of-the-art baselines in motor imagery, emotion recognition, and SSVEP decoding, achieving improved accuracy with fewer parameters.
- The progressive layer-wise design enhances interpretability and neurophysiological validity, paving the way for real-time, embedded BCI system deployments.
LI-DSN: A Layer-wise Interactive Dual-Stream Network for EEG Decoding
Introduction
LI-DSN introduces a progressive, layer-wise interactive dual-stream network architecture addressing the "information silo" limitation prevalent in conventional dual-stream EEG decoders. Traditional approaches, which separately process temporal and spatial features in parallel with late-stage fusion, fail to leverage the coupled spatiotemporal dependencies inherent to EEG signals. LI-DSN proposes continuous cross-stream information exchange at every layer, with a novel Temporal-Spatial Integration Attention (TSIA) mechanism enabling the explicit modeling of dynamic spatiotemporal relationships and robust feature refinement. The implications of this architecture are substantiated across diverse decoding tasks, positioning LI-DSN as an efficient and interpretable solution for real-world BCI systems.
The architecture of LI-DSN is depicted in Figure 1. The model employs parallel Temporal and Spatial Tokenizers for initial feature embedding, followed by N block-wise interactive modules. Each block stacks a Feed-Forward Network (FFN) and the TSIA unit. The interaction is explicitly asymmetric: spatial features serve as contextual priors guiding the refinement of temporal representations through multiplicative integration within TSIA. This design avoids contamination of stable spatial structures by noisy temporal fluctuations.
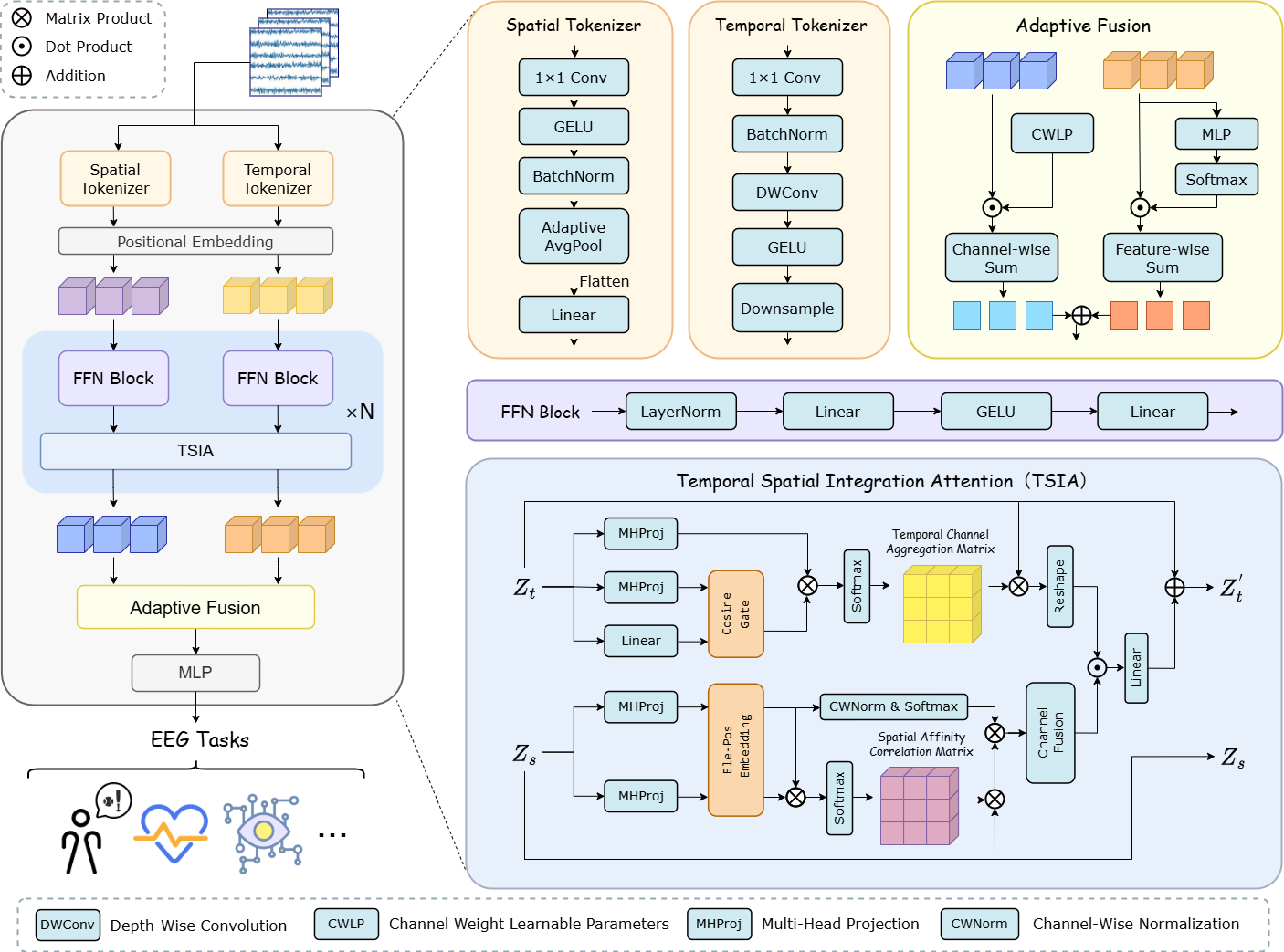
Figure 1: LI-DSN's overall architecture, featuring parallel tokenizers, N interactive dual-stream blocks (FFN + TSIA), and an adaptive fusion module producing final classification outputs.
The Adaptive Fusion head concatenates weighted spatial and attention-pooled temporal abstractions, creating a unified representation for MLP-based downstream classification across tasks such as MI, emotion, and SSVEP.
Temporal-Spatial Integration Attention (TSIA) Mechanism
LI-DSN’s primary innovation is TSIA, which operationalizes bi-domain integration via:
- Spatial Affinity Correlation Matrix (SACM): Encodes inter-electrode relationships, integrating geometric priors by augmenting channel embeddings with learnable spatial positions.
- Temporal Channel Aggregation Matrix (TCAM): Leverages a cosine-gated transformation to model oscillatory EEG phenomena and synthesize channel-temporal dependencies.
- Multiplicative Integration: Fuses the refined spatial and temporal features via elementwise multiplication, functioning as a soft gating mechanism that accentuates task-relevant patterns.
This architecture provides differentiable, progressive spatiotemporal coupling, in contrast to static, late-fusion concatenation.
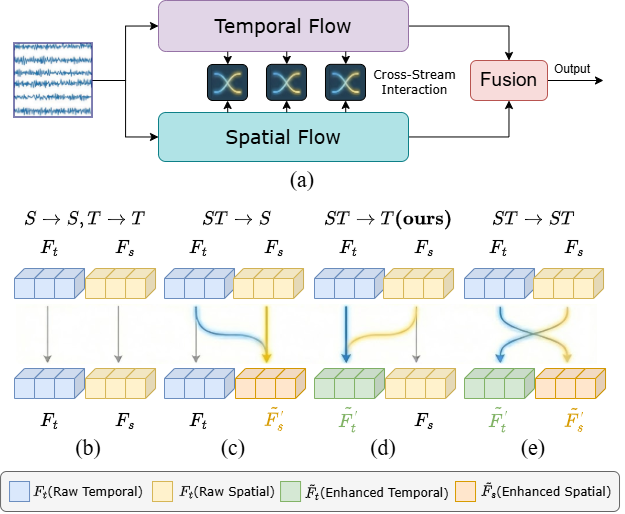
Figure 2: Exploration and alternatives of dual-stream interaction strategies for EEG analysis, motivating the asymmetric spatiotemporal-to-temporal integration chosen for LI-DSN.
Experimental Validation
A comprehensive evaluation protocol covers three paradigm classes: motor imagery (MI), emotion recognition, and steady-state visually evoked potentials (SSVEP), across 8 open-source datasets. LI-DSN outperforms 13 SOTA baselines, including both compact CNNs (e.g., EEGNet, FBCNet) and recent multi-branch/transformer-based architectures (e.g., DBConformer, MSVTNet).
Motor Imagery Classification
On MI datasets (BNCI2014001/2/4, Zhou2016), LI-DSN achieves mean accuracy gains of 1–4% over the next best competitor in CO, CV, and LOSO regimes. Notably, in low-density channel conditions (BNCI2014004), LI-DSN maintains strong performance, demonstrating robustness under information-constrained input.
Emotion Recognition
On both SEED and the large-scale FACED dataset, LI-DSN secures top/second-best scores for ACC and F1. The explicit disentanglement and progressive integration of temporal and spatial evidence confer notable advantages for handling high inter-subject variability in affective decoding.
SSVEP Decoding
On Nakanishi2015 and Kalunga2016, LI-DSN yields new SOTA results, outperforming specialized spectral models and demonstrating general applicability to oscillatory evoked potentials decoding.
Computational Efficiency
LI-DSN achieves SOTA accuracy with fewer than 130K parameters and 6.1M FLOPs, surpassing deep hybrid models and making it viable for low-latency edge deployment.
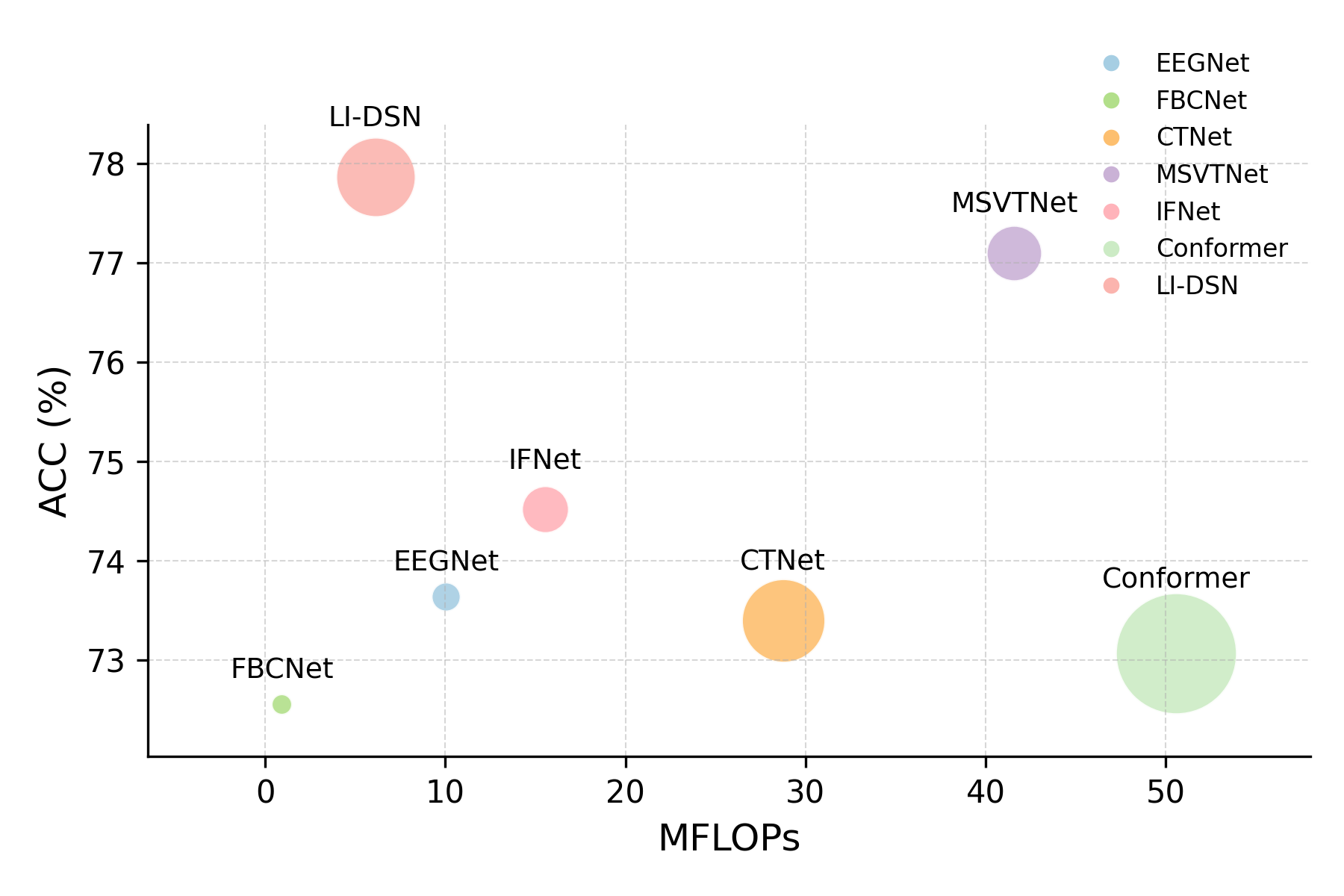
Figure 3: Comparative analysis of accuracy, parameter count, and computational cost (MFLOPs) on BNCI2014001, illustrating LI-DSN's optimal balance.
Ablations and Design Analysis
Layer-wise ablations unequivocally demonstrate the necessity of progressive interaction, positional/geometric embeddings, and the cosine-gated modeling of temporal dependencies. Removing TSIA, positional cues, or adaptive fusion yields substantial accuracy drops (e.g., up to 5% in MI tasks). Asymmetric integration (spatiotemporal-to-temporal flow) significantly outperforms bi-directional and reverse paradigms.
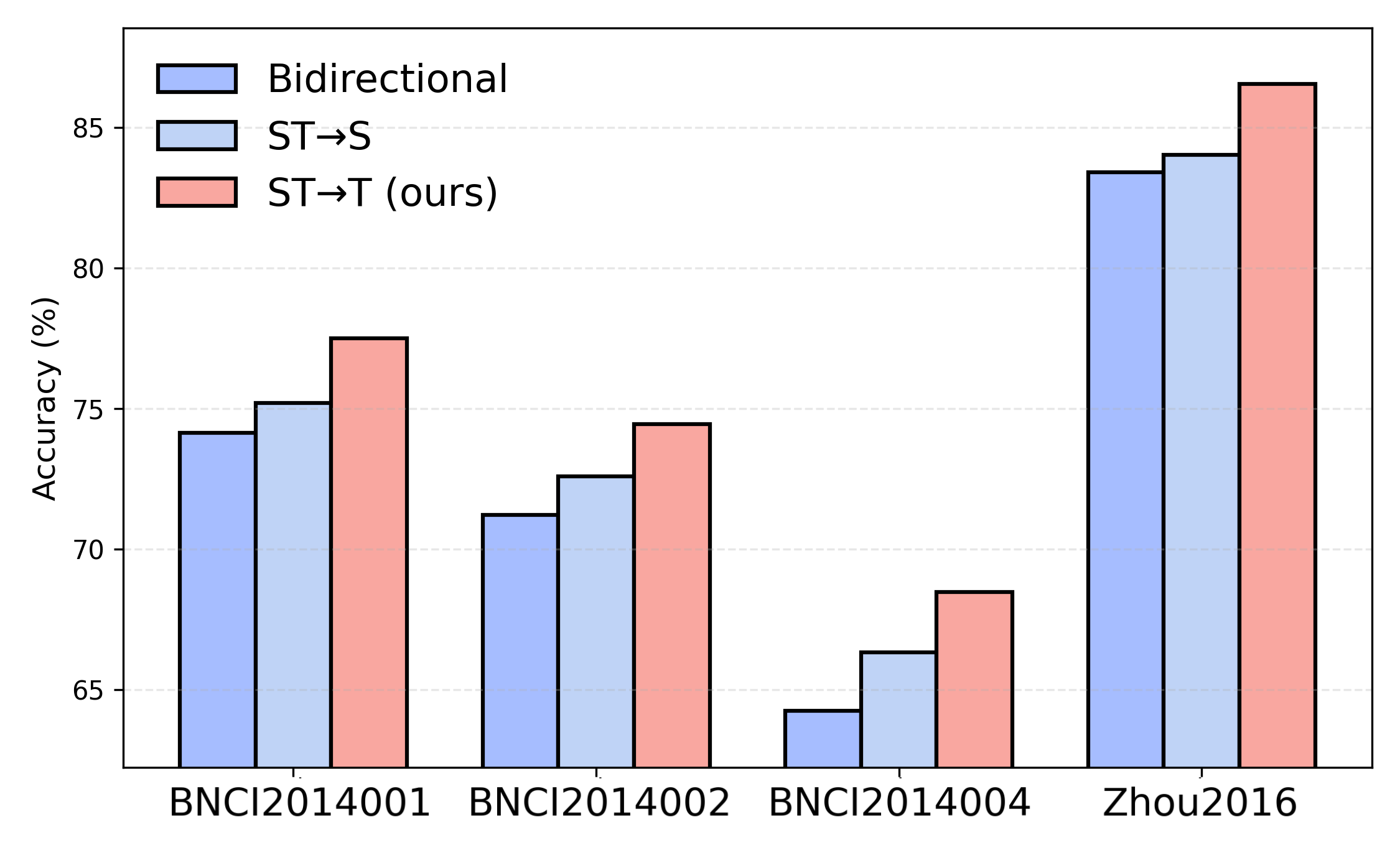
Figure 4: Comparative results of integration strategies under the LOSO protocol reveal the superiority of the asymmetric ST→T fusion adopted by LI-DSN.
Hyperparameter sweeps indicate that both under- and over-parameterization (in block depth or embedding width) produces deleterious effects, underscoring the importance of architectural balance.
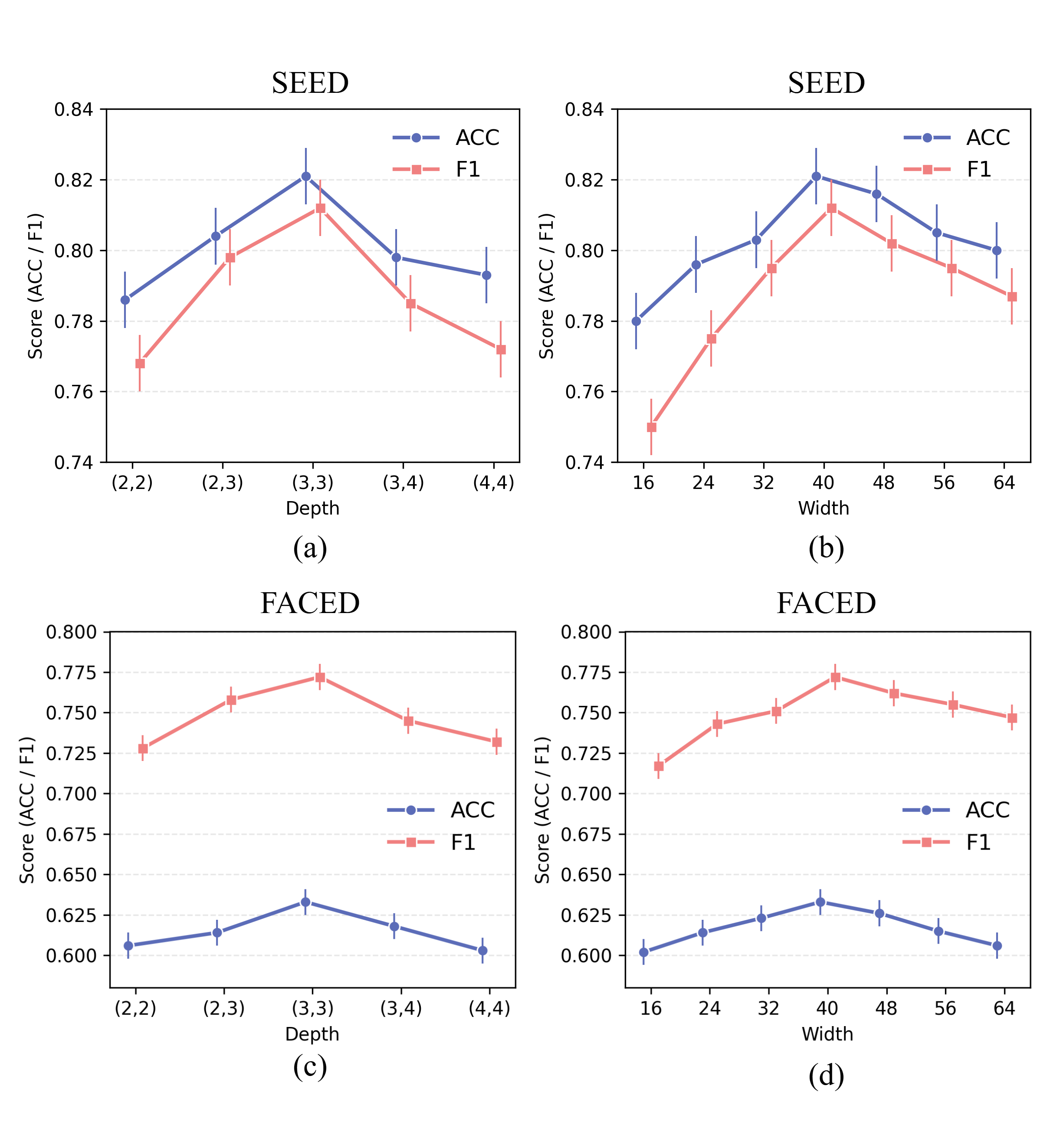
Figure 5: The effect of architectural hyperparameters (block depth and feature embedding width) on model performance, with the optimum at (3,3) blocks and embedding width of 40.
Interpretation and Neurophysiological Validity
Attention matrices and saliency visualizations provide interpretability:
- SACM and TCAM reveal structured, non-uniform attention foci, indicating successful modeling of functional channel dependencies and discriminative temporal segments.
- Feature evolution maps show transition from unstructured, variance-dominated activations to stable, task-locked patterns post-interaction.
- Saliency maps localize MI to sensorimotor cortex, SSVEP to posterior occipital, and emotion to prefrontal and temporal regions—consistent with known neurophysiological correlates.
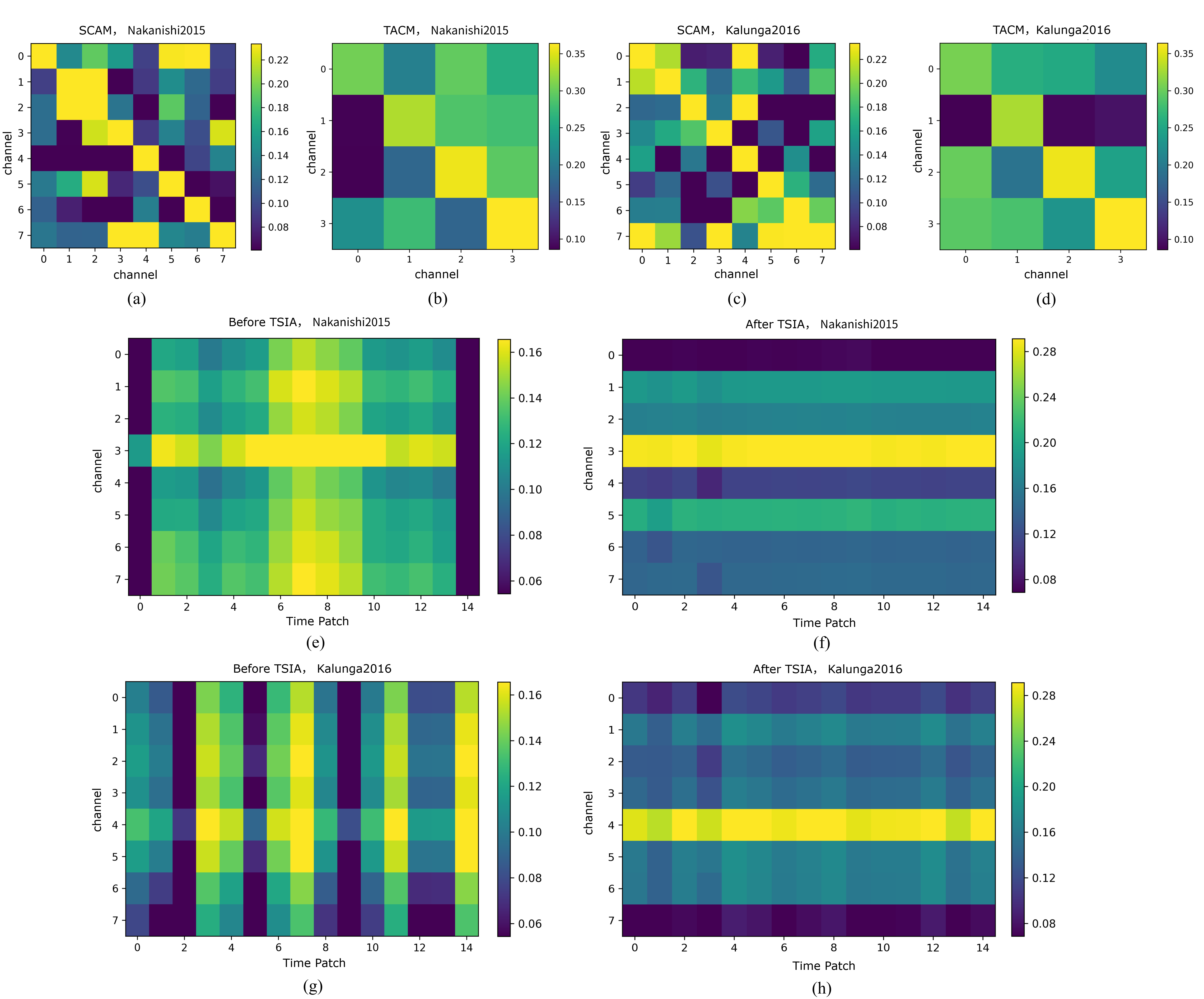
Figure 6: Visualization of TSIA-derived attention matrices and channel-temporal activations, illustrating effective suppression of irrelevant background and enhancement of task-relevant features.
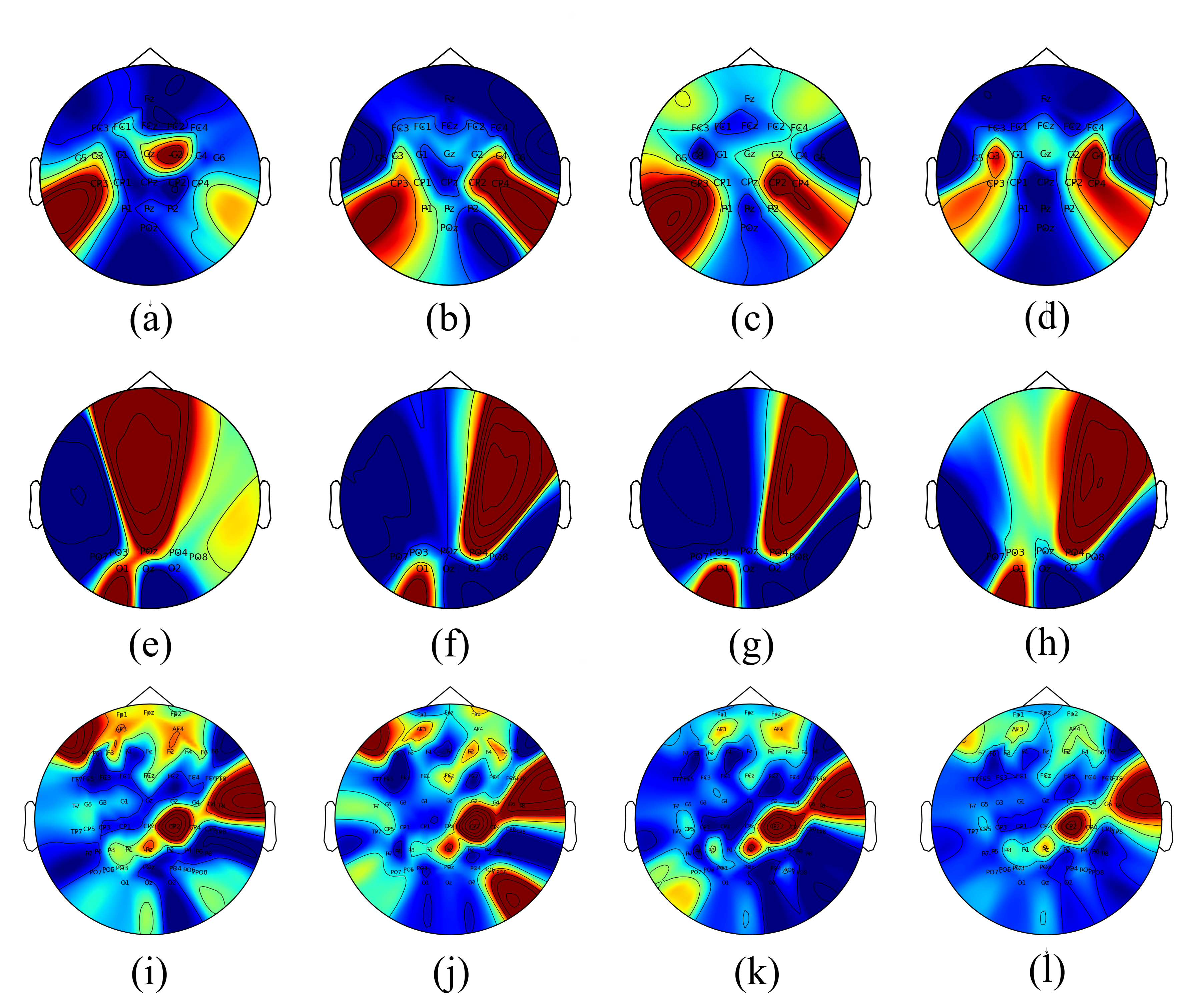
Figure 7: Saliency map visualizations confirm that LI-DSN identifies biologically meaningful, task-specific activation patterns at both the subject and population level.
Theoretical and Practical Implications
LI-DSN's architecture demonstrates that continuous, fine-grained interaction between spatial and temporal feature spaces is essential to unlocking EEG decoding accuracy and robustness. This finding challenges prevailing late-fusion dogma in BCI neural network design. The proposed TSIA unit suggests novel directions for integrating geometric and oscillatory priors in deep neural architectures across other biosignal tasks. Practical deployment is facilitated by the model's favorable computational profile, enabling real-time, interpretable BCI systems deployable on embedded hardware.
Limitations and Prospective Directions
Open challenges include enhancing adaptability to paradigms beyond MI, emotion, SSVEP, and addressing extreme inter-subject and intra-task variability with even more dynamic fusion or transfer learning. Further, the fixed asymmetric update rule could be generalized via learnable routing or attention-based cross-modal controllers. Extensive clinical trials will be required to confirm translational value in patient-facing BCI therapeutics.
Conclusion
LI-DSN realizes a new paradigm in EEG neural decoding with its layer-wise progressive interactive dual-stream network, unified via the TSIA mechanism and adaptive fusion. Its superior empirical performance, architectural interpretability, and formal efficiency establish it as a strong candidate for future BCI systems and foundational research in neural spatiotemporal modeling.
(2604.01889)