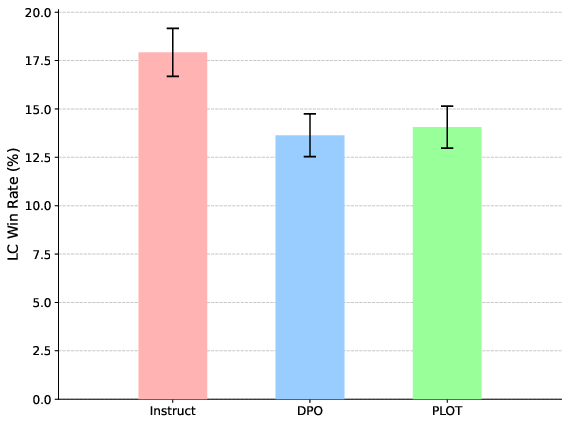
- The paper proposes an OT-based loss that globally aligns token distributions with human preferences via semantic embeddings.
- It demonstrates significant reductions in attack success rates and improvements in benchmarks for human values and logical problem solving.
- The method integrates seamlessly with various fine-tuning strategies, preserving general model capabilities while enhancing robustness.
PLOT: Enhancing Fine-Tuning-Based Preference Learning via Optimal Transport
Existing preference alignment strategies for LLMs, including RLHF paradigms and direct fine-tuning-based methods (SFT, DPO, PRO, AOT), are constrained by high computational demands, local rather than global optimization at the token level, hyperparameter sensitivity, and insufficient modeling of semantic dependencies. Many approaches apply divergence measures (e.g., KL, JS) or token-level losses without considering global semantic structure and, critically, do not offer a principled framework for aligning the entire output distribution with human-preferred behaviors. As a result, aligned models often remain vulnerable to adversarial and jailbreak attacks and can exhibit suboptimal robustness and generalization under preference constraints.
The paper proposes Preference Learning via Optimal Transport (PLOT), which reframes preference learning as a structured distributional alignment problem. By leveraging Optimal Transport (OT), PLOT computes the minimal transportation cost—incorporating semantic token embeddings—between the model output distribution and the human preference distribution. This enables fine-tuning objectives that penalize distributional misalignment in a way that is holistically informed, theoretically principled, and operationally robust.
Method: Optimal Transport-Based Preference Alignment
Central to PLOT is the integration of a semantic-aware OT-based loss LPLOT into any standard fine-tuning objective:
L=Lvanilla+αLPLOT
where α regulates the strength of the global alignment penalty.
Token-level preference distributions are constructed using positive/negative preference datasets. The preference distribution Pt is computed as:
Qdiff=∑Q+Q+−∑Q−Q−
where Q+ and Q− are frequency-based token distributions from preferred and rejected output pairs, followed by a normalization and a non-negative transformation.
To encode semantic relationships, PLOT computes a cost matrix C based on l-norms (typically Euclidean, l=2) of the token embeddings:
L=Lvanilla+αLPLOT0
allowing transportation cost to reflect semantic similarity in embedding space, unlike default position-agnostic or 0-1 cost matrices. The overall OT problem is then evaluated, and, for computational tractability, reduced to the one-dimensional Wasserstein-1 distance (Earth Mover's Distance) between cumulative distributions projected via embeddings.
The final L=Lvanilla+αLPLOT1 term penalizes the aggregated semantic transport cost between the current model output distribution and the preference-aligned target. This global, embedding-aware distributional loss is universally composable with existing preference learning frameworks.
Empirical Evaluation
Datasets and Baselines
Experiments target two principal preference axes: (1) Human Values (Harmlessness, Helpfulness, Humanity), and (2) Logic {content} Problem Solving (Mathematics, Reasoning, Coding, STEM), with standard datasets (e.g., HH-RLHF, MT-Bench, GSM8K, MATH) and advanced adversarial evaluation protocols (e.g., HarmBench, multiple red teaming attack methods such as Zero-Shot, PEZ, GBDA, UAT, SFS, GCG).
Baselines include SFT, DPO, PRO, and AOT, with PLOT integrated as a plug-and-play loss term.
Model families evaluated include Llama3.2-3B, Llama3.1-8B, and Qwen2.5-7B.
Main Quantitative Results
PLOT produces highly consistent, statistically robust improvements over strong baselines on multiple axes:
Robustness and Hyperparameter Sensitivity
- Red teaming defense stability: As the number of red teaming cases or update steps increases, PLOT’s ASR gains remain robust and stable.
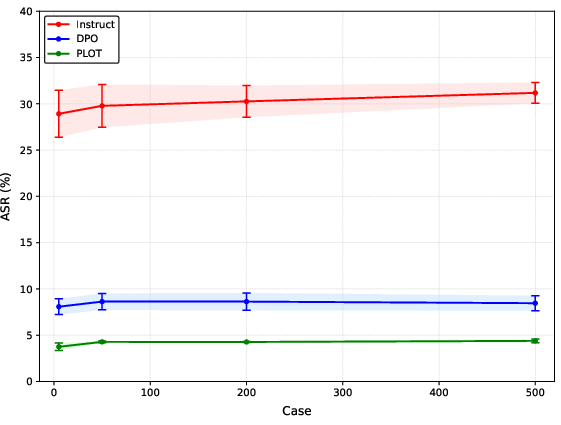
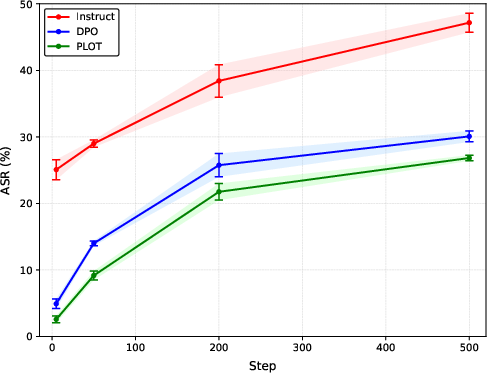
Figure 2: The ASR curves of three models under different case counts for the Zero-Shot method (Left) and varying update steps of GCG (Right). PLOT consistently demonstrates superior defense capabilities and stability compared to DPO.
- Hyperparameter stability: Error/ASR metrics with PLOT remain essentially constant across a wide range of scaling factors for L=Lvanilla+αLPLOT3; in contrast, DEFT and related methods show strong sensitivity.
- Semantic embedding utility: Ablation studies show removing semantic embedding information from L=Lvanilla+αLPLOT4 yields substantial ASR degradation, validating the importance of semantic transport for robust defense.
- Divergence alternatives: Attempts to replace OT with KL/JS divergences in the distributional loss lead to infinite losses or instability due to vocabulary sparsity. OT yields both numerical and empirical stability.
Theoretical and Practical Implications
PLOT defines a theoretically motivated, domain-agnostic framework for preference alignment that, by design, optimizes the global token distribution with explicit semantics rather than locally per-token. This not only advances practical robustness under adversarial attacks but generalizes to preference categories beyond “harmlessness” (e.g., logical reasoning or problem-solving).
The method is practically efficient (∼2.7% increase in training time over DPO), generalizes across architectures, and is immediately integrable into existing fine-tuning paradigms. The OT-based construction is particularly compelling for LLMs since it avoids known limitations of KL/JS divergence in high-dimensional sparse vocabularies and enables task-adaptive semantic transport via embedding-informed cost matrices.
Future Directions
Advancing PLOT along several dimensions could yield further gains:
- Scaling to larger LLMs with more granular vocabulary and embeddings;
- Exploring richer or architecture-specific embedding spaces for transport cost construction;
- Extending the framework to multi-turn conversational or multimodal preference alignment;
- Applying OT-based preference fine-tuning in highly data-limited or non-standard alignment domains.
Conclusion
PLOT presents a theoretically sound, universally applicable approach to preference alignment in LLMs by leveraging Optimal Transport with semantic embedding-informed loss. Empirical findings validate substantial improvements in robustness and preference alignment as well as preservation of general language capabilities, outperforming state-of-the-art DPO- and SFT-based methods with minimal computational overhead. The framework directly addresses critical limitations in existing sequence- and token-level losses, advancing both the methodological and empirical status quo in human-aligned LLM optimization.