- The paper introduces RebusBench, a dataset of 1,164 human-authored rebus puzzles to evaluate LVLMs’ abstract and neurosymbolic reasoning beyond literal mapping.
- It demonstrates that even state-of-the-art LVLMs achieve less than 10% Exact Match, highlighting a significant gap in abstract visual–linguistic fusion.
- The study advocates for new architectures incorporating symbolic manipulation and cognitive control to overcome current LVLM limitations.
Evaluating Abstract Visual Reasoning with RebusBench
Introduction
Recent progress in Large Vision–LLMs (LVLMs) has established a new paradigm at the intersection of visual recognition and natural language understanding. However, existing benchmarks predominantly assess tasks that align with referential, literal mapping—evaluating "System 1" capabilities that do not require deeper, multi-modal entanglement or symbolic recombination. "Hidden Meanings in Plain Sight: RebusBench for Evaluating Cognitive Visual Reasoning" (2604.01764) introduces RebusBench, a challenge dataset crafted to rigorously probe the abstract, neurosymbolic reasoning capabilities of LVLMs. Drawing from the tradition of rebus puzzles, the core task necessitates synthesizing visual cues and linguistic priors—requiring fusion, suppression of literal response tendencies, and robust cognitive control.
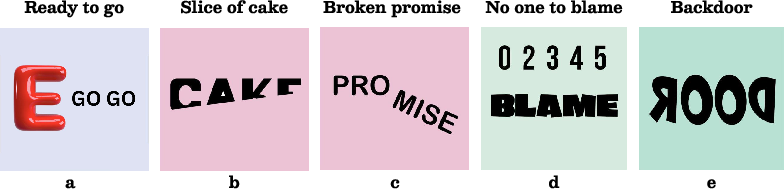
Figure 1: Exemplars from RebusBench demand surpassing literal perception and compel "System 2" reasoning for reconstructing the intended idiomatic expression via entwined visual and linguistic inferences.
Most LVLM benchmarks, including MS COCO, VQA v2, GQA, and CLEVR, are tightly aligned with literal scene description or referential grounding. While datasets such as OK-VQA introduce the need for retrieval of external knowledge, they maintain a parallelism between visual and textual streams that does not require entangled symbolic reasoning. Compositional, spatial, and counting tasks in datasets like SpatialVLM, HowManyQA, and CAPTURe test relationships and enumeration but rarely demand multi-step, suppressive reasoning typical of neurosymbolic cognition.
Advanced, discipline-spanning benchmarks (e.g., MMMU, SEED-Bench, MathVista, ScienceQA) shift toward expert knowledge integration, but lateral, "out-of-the-box" synthesis—central to creative human intelligence—remains virtually untested. RebusBench targets precisely this lacuna: it is designed to partition and measure the gap between current LVLM capabilities and the type of cross-modal, symbolic abstraction observed in human cognitive workflows.
The RebusBench Dataset
RebusBench consists of 1,164 human-authored rebus puzzles curated for diversity and quality. These samples avoid procedural or synthetic patterns, presenting instead idiomatic or colloquial expressions encoded in visual form. The spectrum in RebusBench is continuous, ranging from visually driven manipulation (where the structure, deformation, or placement of text itself is the clue) to symbolically driven puzzles requiring the identification of absences or meta-linguistic relations.
Crucially, the benchmark's formulation renders recognition and recall strategies insufficient. Each puzzle must elicit from the model a suppression of literal descriptive output in favor of a mapped, abstract idiom—a hallmark of "System 2" cognitive operation. This structure is key both for probing genuine cross-modal reasoning and for resisting shortcut solutions.
Experimental Methodology
Experiments spanned a comprehensive suite of contemporary open-weight LVLMs: LLaVA-1.5 7B, InternVL 3.5 (4B/8B/30B), Qwen 2.5 (3B/7B/32B), and Qwen 3 (4B/8B). Models were assessed under one-shot and three-shot prompting to test In-Context Learning (ICL), with carefully constructed examples preceding the query to prime for non-literal, analogical chain reasoning.
Evaluation employed two metrics: Exact Match (EM) for strict correctness, and a semantic similarity score using GPT-4o as a judge to reward partial or synonymous matches. Notably, answer normalization suppressed surface form discrepancies, focusing evaluation on core abstract understanding.
Results and Analysis
Across all architectures and prompting strategies, results manifest a severe performance ceiling:
- Exact Match performance for all models saturates below 10%, with the state-of-the-art Qwen 2.5 32B reaching 7.39% in one-shot and only 8.08% in three-shot configuration.
- GPT-4o semantic scores never exceed 0.1704, indicating even generous assessment fails to find substantive semantic alignment with ground truth idioms.
- Increasing model size yields, at best, marginal improvements (e.g., InternVL 3.5 4B to 30B rises only 0.42% EM), with no architecture demonstrating qualitatively different reasoning capabilities.
- Few-shot prompting via ICL shows negligible or even negative effect, and does not facilitate significant abstraction.
These data decisively indicate that current LVLM architectures are not merely under-trained or poorly fine-tuned, but fundamentally lack the class of entangled, suppressive, multi-modal reasoning necessary for abstract idiomatic reconstruction. Model scaling does not bridge this neurosymbolic gap, and naïve strategic prompting is ineffective. This underscores a sharp limitation: modern LVLMs are unable to spontaneously discover or leverage abstract, visual–linguistic coupling via current alignment protocols or expanded parameterization.
Practical and Theoretical Implications
The demonstrated failure of leading LVLMs on RebusBench implies several theoretical and practical deficits:
- State-of-the-art LVLMs specialize in literal and referential grounding, lacking mechanisms for true symbolic fusion or creative, "lateral" inference.
- Existing training corpora and architectures do not induce suppressive "System 2" control, causing models to default to high-probability, surface-level responses even when strongly discouraged in-task.
- Contemporary benchmarks do not measure the neurosymbolic bottleneck, resulting in overly optimistic estimation of LVLM general intelligence.
- These findings motivate new research into cognitive architectures, explicit neurosymbolic fusion networks, and training regimes which interleave multi-modal control and creativity.
For model deployment, the limits evidenced on RebusBench suggest that LVLMs should be deployed with caution in use cases requiring abstract mapping from visual layout to meaning, creative visual reasoning, or idiomatic interpretation—tasks central to human–AI co-creative workflows, robust assistants, and real-world, visually grounded dialogue.
Speculation on Future Directions
Future work, as outlined by the authors, includes expansion of the dataset to diagnose and quantify modality biases, enrichment with metadata along the visual–textual abstraction spectrum, and standardized evaluation suites. Incorporation of closed weight, proprietary architectures (e.g., GPT-5.2, Gemini 3) will complete a field-wide baseline and highlight architectural bottlenecks.
More fundamentally, the results strongly indicate the need for new modeling paradigms—perhaps blending explicit symbolic manipulation modules, external memory, or cognitive control layers—rather than continued scaling of monolithic, end-to-end architectures. The future of neurosymbolic AI may thus depend on principled algorithmic advances rather than parametric growth.
Conclusion
RebusBench sets a new standard for evaluating true abstract visual–linguistic reasoning in LVLMs (2604.01764). The near-uniform, low performance across current architectures exposes a fundamental gap between human-like cognitive reasoning and the pattern recognition capabilities of today's models. These findings provide clear direction for the next phase of LVLM research—driving developments in model architecture, training data, and evaluation methodology towards truly intelligent, cross-modal abstraction and reasoning.

