- The paper introduces a decoupled two-stage framework leveraging synthetic optical flow for fine-grained motion control in video synthesis.
- It demonstrates superior performance over existing models in dynamic object and camera-controlled scenarios using both synthetic and real motion data.
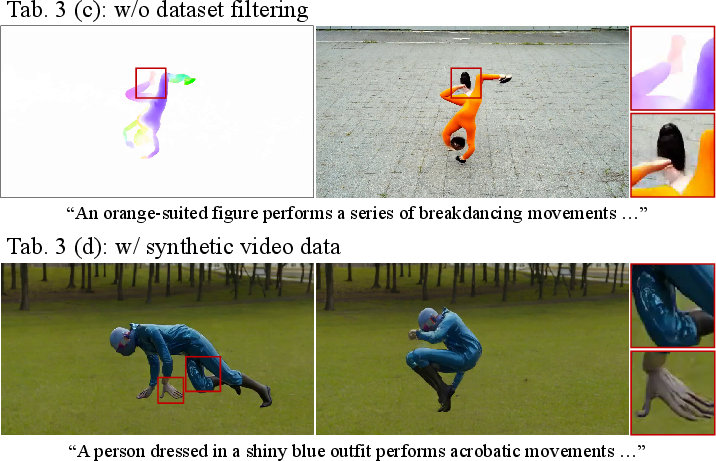
- Ablation studies highlight the critical role of synthetic data, batch mixing, and cycle consistency filtering in maintaining realistic motion fidelity.
DynaVid: Learning to Generate Highly Dynamic Videos using Synthetic Motion Data
Introduction
The synthesis of realistic videos featuring highly dynamic object and camera motions remains a significant challenge for state-of-the-art video diffusion models. The key obstacles are a scarcity of training data adequately representing such motions and the difficulty of precise motion control in generation, particularly for scenarios like rapid breakdancing, aggressive camera maneuvers, or abrupt viewpoint switches. DynaVid addresses these challenges through a decoupled two-stage pipeline, leveraging computer graphics-rendered synthetic motion data—specifically, optically computed flow maps—to inject high-fidelity motion dynamics while mitigating unwanted synthetic appearance artifacts. This strategy facilitates fine-grained motion control and visual realism jointly, serving demanding applications such as advanced video content creation, movie post-production, and AI-driven animation.
Dataset Generation Pipeline
The foundation of DynaVid’s capabilities is a modular pipeline that utilizes the Cycles renderer in Blender to construct diverse, high-velocity synthetic motion datasets. Two benchmark datasets are proposed:
- DynaVid-Human: Scenes with rigged human avatars performing vigorous motion sequences (sourced from Mixamo motion data) with stationary cameras.
- DynaVid-Camera: Urban and natural scenes (assembled from BlendSwap assets) featuring complex, rapidly varying camera trajectories produced via NURBS curve interpolation.
For both datasets, the pipeline produces paired RGB frames and dense ground-truth optical flow, where the latter is directly computed from 3D primitive displacements and projected into the image plane. The resulting pipeline enables generation of motion types that are severely underrepresented in real video datasets.
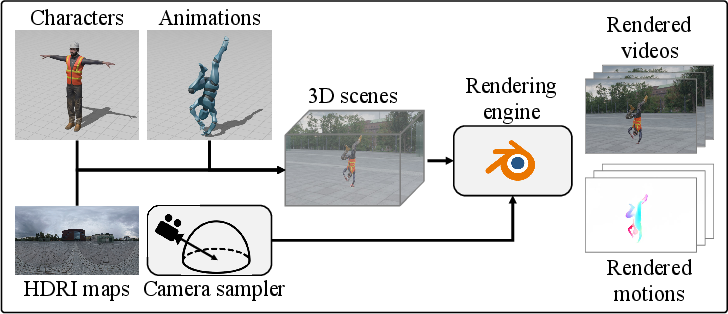
Figure 1: Overview of the synthetic dataset generation pipeline, encompassing scene construction, trajectory design, and rendering of paired optical flow data.
Framework Architecture
DynaVid employs a decoupled dual-stage latent diffusion architecture:
- Motion Generator: This model synthesizes plausible motion cues—represented as normalized optical flow sequences—in the latent space of a pretrained VAE (extended to handle HSV-mapped flow tensors). Conditioning is provided via text and, for camera trajectory control, explicit Plücker-embedded camera parameters.
- Motion-Guided Video Generator: Using as input both text and optical flow (generated or from real data), this conditional UNet-based diffusion model produces the output RGB video frames, with the flow acting as the explicit motion prior.
Crucially, by segregating motion from visual synthesis, DynaVid avoids the appearance domain gap that otherwise plagues directly rendered synthetic video training, while supporting fine-grained control via explicit motion and camera trajectory signals.
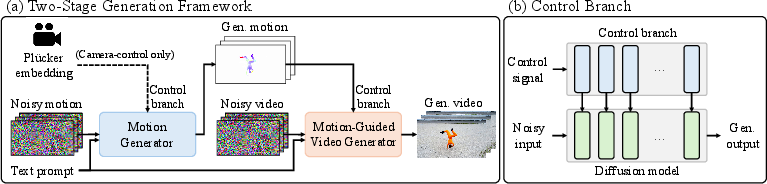
Figure 2: Overview of DynaVid: (a) Motion generator synthesizes motion followed by appearance generation; (b) Conditional architecture supporting Plücker embeddings for camera control.
Training Scheme and Data Utilization
Training proceeds in two principal stages:
- Motion Generator Pretraining: General motion priors are acquired from optical flow estimated from real videos (internal datasets and RealEstate10K/RE10K).
- Motion Generator Fine-Tuning: Capability to synthesize highly dynamic motions is established by fine-tuning with a mixture of synthetic and real motion data, ensuring both dynamic motion expressiveness and retention of natural motion priors.
The motion-guided video generator is always trained on real-world video/flow pairs with rigorous dataset filtering based on cycle consistency to counteract flow estimation errors, discarding outlier pairs likely to introduce misalignment artifacts.
Results and Evaluation
Dynamic Object Motion Generation
Compared with recent open and large-scale text-to-video models (CogVideoX, Wan2.2-5B, HyperMotion), DynaVid delivers superior realism and motion fidelity for dynamic scenarios. CogVideoX and Wan2.2-5B suffer from unrealistic or static motion artifacts due to the absence of diverse dynamic motion data in their training sets, while HyperMotion's reliance on the first input frame results in unnatural appearance and suboptimal generalization to unconstrained dynamic action.

Figure 3: Qualitative comparison on dynamic object motion: only DynaVid synthesizes plausible, artifact-free dynamic scenes.
Quantitatively, on the DynaVid-Human test set (high velocity) DynaVid achieves noticeable gains in FVD, aesthetic quality (A-Qual), and imaging quality (I-Qual), matching or surpassing HyperMotion especially in scenarios with significant motion controllability requirements.
Camera-Controlled Synthesis
For camera-controllable generation, DynaVid was benchmarked against AC3D and GEN3C. While existing models showed moderate camera accuracy in low-dynamic benchmarks (RE10K), only DynaVid robustly tracks complex, rapid viewpoint transitions and maintains appearance consistency, avoiding the geometric hallucinations or frozen artifact regions common in prior methods.

Figure 4: Camera-controlled synthesis: only DynaVid successfully follows extreme camera trajectory changes with robust temporal and spatial appearance.
Across metrics including mean rotation error (mRotErr) and FVD, DynaVid establishes clear advantages, particularly in synthetic benchmarks characterized by large, rapid viewpoint sweeps.
Ablations and Analytical Insights
Ablation studies confirm:
Replacing the optical flow training modality with direct rendered video compounds the well-known problem: the model produces visually artificial scenes (domain gap overfitting), as detailed in the literature.
Robustness and Generalization
DynaVid’s motion-guided video generator demonstrates robust error tolerance: even as input flow quality degrades (down to 20dB SNR), aesthetic quality and motion fidelity decline gracefully. The generator can extrapolate beyond its motion domain, synthesizing plausible, dynamically consistent non-human locomotion, despite training solely on single-human scenes.

Figure 6: DynaVid successfully generalizes to non-human, highly dynamic motion, outside original training distribution.
Nevertheless, a salient limitation persists: model performance in scenes with multiple interacting agents or multi-object dynamic composition is weak, reflecting dataset construction biases.

Figure 7: Limitation—DynaVid struggles with multi-human dynamic compositions due to data scarcity.
Implications and Future Directions
DynaVid's explicit decoupling of motion and appearance paves the way for controllable, high-dynamic video synthesis, tackling challenges posed by training data sparsity and domain gap in advanced video generation. The results indicate both practical relevance in high-impact generative media and theoretical advances in domain adaption and multi-modal training architectures.
Key future directions include scaling synthetic motion to multi-agent and multi-body scenes, integrating physically plausible dynamic constraints, and incorporating additional control modalities (e.g., physical parameters, complex trajectories) for granular scene-level directability.
Conclusion
DynaVid introduces a dual-stage motion-conditional video generation framework that, through the novel use of synthetic optical flow, overcomes data and controllability bottlenecks in highly dynamic video synthesis. Systematic evaluation establishes its superiority over prevailing architectures on both object and camera motion benchmarks, with strong robustness and generalization capacity. The framework and synthetic assets lay a foundation for future research in controllable dynamic video generation and its downstream applications.