- The paper introduces a training-free framework that leverages parallel denoising chains with randomized reveal orders to detect hallucinations using cross-chain entropy.
- It presents a three-stage process: diversified decoding, uncertainty localization, and targeted remasking correction for factual improvements.
- Empirical results show OSCAR improves QA F1 scores and reduces hallucinated spans, outperforming both traditional and trained detection methods.
Orchestrated Self-Verification and Cross-Path Refinement in Diffusion LLMs: The OSCAR Framework
Introduction
Diffusion LLMs (DLMs) employ iterative, parallel denoising instead of the strictly sequential, unidirectional generation in autoregressive (AR) LLMs. This architectural distinction exposes the full generation trajectory, revealing a tractable model-native uncertainty signal that is inaccessible to AR models. "OSCAR: Orchestrated Self-verification and Cross-path Refinement" (2604.01624) addresses hallucination detection and mitigation in DLMs via inference-time mechanisms leveraging the model's own denoising dynamics, bypassing the need for external, trained hallucination detectors or classifiers.
This essay provides a comprehensive analysis of the OSCAR framework, focusing on its formalization of commitment uncertainty localization, the introduction of cross-chain entropy as an unsupervised uncertainty signal, the integration of targeted correction via remasking, and a quantitative and mechanistic evaluation demonstrating superiority over both output-based and trained trajectory-based alternatives.
Model-Native Commitment Uncertainty Signal
DLMs decode text by iteratively revealing tokens, each according to an explicit reveal order. Importantly, this order alters which tokens are "committed" first, subsequently conditioning all generative dynamics. As a result, early incorrect commitments (premature crystallization) can propagate and become attractors via bidirectional attention, yielding self-consistent but factually erroneous outputs—a failure mode distinct from AR decoding.
OSCAR operationalizes the following principle: parallel denoising chains using different randomized reveal orders will diverge on token positions precisely where the model's knowledge is insufficiently constrained by context. This divergence is quantified using cross-chain Shannon entropy over the final token predictions at each position:
H×,i=−v∈V∑p^i(v)logp^i(v)
where p^i(v) is the empirical frequency of token v at position i across parallel chains. High cross-chain entropy at a position i directly indicates commitment uncertainty specific to that model instance—not captured by output perplexity, latent probes, or resampling-based self-consistency in AR models. This signal is structurally inherent to parallel denoising and unobservable in AR architectures unless artificially induced with re-sampling.
The OSCAR Inference-Time Pipeline
The OSCAR framework consists of three key inference-time stages that together constitute a training-free method for accurate hallucination detection and targeted correction.
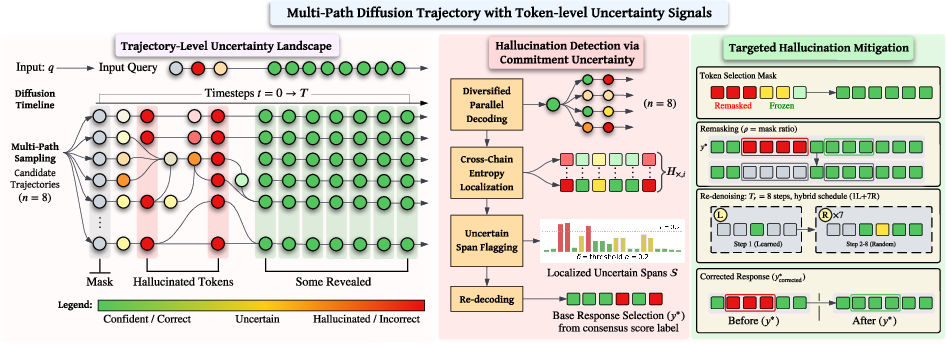
Figure 1: Oscar pipeline: N parallel denoising chains with randomized reveal orders generate diverse trajectories. Cross-chain entropy H× identifies high-uncertainty positions, and targeted remasking corrects these spans via retrieved evidence.
Stage 1: Parallel Diversified Decoding
OSCAR initiates N parallel denoising trajectories, each instantiated with a different randomly sampled reveal order. This diversity exposes model epistemic uncertainty arising from non-deterministic token commitments, in contrast to standard confidence-based decoding (favoring high-probability tokens). The chains are batched for efficiency, incurring only a modest inference overhead.
Stage 2: Commitment Uncertainty Localization
For each token position, cross-chain entropy is computed. Token positions with entropy in the top k% (default k=20%) are aggregated into contiguous spans, identifying those positions as unreliable due to factual or contextual uncertainty. This localization relies on data-driven, unsupervised thresholding without access to ground-truth labels or domain adaptation.
Stage 3: Targeted Remasking and Correction
Identified high-uncertainty spans are selectively remasked in the consensus chain. The model then performs additional denoising steps, optionally augmented by targeted retrieval (e.g., with Contriever over Wikipedia) using the uncertain span as the retrieval query. Correction is thus tightly focused on model-identified unreliable content rather than holistic or uniform post-generation rewrites. The first refinement step leverages a learned reveal order, anchoring confident predictions before reverting to further randomized steps to encourage correction diversity and avoid replicating errors.
This orchestration is fully training-free and exploits existing DLM competencies, including bidirectional infilling and contextual conditioning. Correction is performed only on approximately 19% of tokens per sample, minimizing computational overhead and risk of degrading previously reliable content.
Evaluation: Hallucination Detection and Correction
OSCAR is evaluated against strong baselines across LLaDA-8B and Dream-7B DLMs on TriviaQA, HotpotQA, CommonsenseQA, and RAGTruth (span-level annotations).
Key empirical findings include:
- On LLaDA-8B, OSCAR achieves 86.5% AUROC using LLM-as-judge (semantic equivalence via GPT-4o), outperforming state-of-the-art trained trajectory-based detectors (DynHD) by +2.3 AUROC points, and output- or latent-based unsupervised methods by larger margins.
- OSCAR's localization via cross-chain entropy identifies 67.3% of hallucinated positions in the top 20% most uncertain positions—over 3× better than random and significantly exceeding TraceDet and DynHD.
- Correction yields substantive QA F1 improvements: +6.1 points macro-averaged for LLaDA-8B, +8.3 on Dream-7B, and up to +10.7 on TriviaQA.
- On RAGTruth, hallucinated spans are reduced by 41.1% (macro), and FactScore is consistently increased, covering both extractive and complex summarization tasks.
- In cases such as CommonsenseQA, OSCAR does not intervene (chains agree, p^i(v)0), demonstrating high selectivity and indicating the method does not incur unnecessary corrections.
The synergy between localization and targeted correction produces effect sizes unobtainable by either stage in isolation, as verified by ablation studies.
Mechanistic and Theoretical Insights
A significant contribution of OSCAR is characterizing hallucination crystallization dynamics. The entropy gap p^i(v)1 between hallucinated and grounded tokens evolves distinctly across tasks:
- In factual QA, high uncertainty arises early in decoding and persists, implicating premature commitments.
- In summarization, the gap grows mid-denoising, reflecting compositional and cross-span errors.
This allows for speculation on early-exit strategies—intervening or terminating further remasking once sufficient uncertainty has been identified and corrected, directly impacting deployment efficiency in production contexts.
Moreover, the methodology reveals a structural asymmetry between DLMs and AR models: the former maintains uncertainty distributions over all positions throughout denoising. AR models collapse uncertainty at each step, requiring independent resampling of full outputs to estimate factual risk, conflating sampling variability with epistemic uncertainty.
Prior diffusion-based hallucination detectors—TraceDet, DynHD, EigenScore—either require supervised classifier training or remain passive observers of the denoising trace. OSCAR is distinguished by:
- Requiring no hallucination annotations, classifier training, or fine-tuning.
- Intervening at the point of factual uncertainty, not merely reporting error-prone content.
- Leveraging the order-dependence of token commitments as the actual source of model epistemic error, a property unique to DLMs.
Output-based, latent-based, or resampling measures (SelfCheckGPT) are structurally weaker, either due to reliance on surface token perplexity, task-specific latent projections, or inability to isolate commitment-order effects.
Implications and Future Research Directions
The OSCAR framework substantiates several key theoretical and practical implications:
- DLMs' native denoising trajectories can support robust, training-free error localization and correction at inference—enabling unsupervised uncertainty estimation and mitigation in open-domain generation tasks.
- This affordance, unavailable in AR models, could facilitate more general inference-time control primitives, including reliability enhancement, provenance attribution, and possibly fine-grained content editing without retraining.
- Extension to continuous or hybrid-mask DLMs, adaptive correction/retrieval schedules, and personalized uncertainty thresholds are natural continuations. The connection between uncertainty crystallization and efficient inference invites further investigation into low-latency, resource-aware DLM deployment.
- Integrating OSCAR-style localization with preference optimization and dynamic retrieval mechanisms may provide a broader framework for uncertainty-aware and retrieval-augmented controllable generation.
Conclusion
OSCAR formalizes and capitalizes on commitment uncertainty localization in DLMs through cross-chain trajectory entropy, establishing an inference-time protocol for both hallucination detection and correction. Empirical evidence demonstrates OSCAR's superiority over both unsupervised and trained supervised alternatives, with meaningful reductions in hallucinated content and enhancement in factual metrics, all within manageable resource constraints. OSCAR's paradigm foregrounds the structural potential of DLMs for robust, real-time output verification and adaptive correction—laying foundational groundwork for uncertainty-aware language generation.