- The paper introduces DaxFS, which achieves lock-free, multi-writer coordination using CXL’s atomic operations, eliminating centralized locks.
- It employs a novel overlay hash table and decentralized shared page cache with MH-clock to optimize metadata operations and reduce latency.
- Benchmark evaluations demonstrate that DaxFS delivers up to 6.2x faster sequential reads and superior random I/O performance over traditional filesystems.
DaxFS: A Lock-Free Shared Filesystem for CXL Disaggregated Memory
Introduction and Motivation
DaxFS addresses the coordination and efficiency problems inherent in multi-host access to byte-addressable memory over CXL (Compute Express Link) 3.0, a hardware standard enabling hardware-coherent memory sharing across hosts. Existing solutions either rely on per-host memory duplication, single-writer semantics, or introduce high-latency network protocols inconsistent with the nanosecond-scale performance that CXL unlocks. DaxFS is the first filesystem to exploit CXL’s cache-coherent atomic operations to realize lock-free, multi-writer coordination without a centralized manager.
The design targets deployment scenarios in which multi-host systems require shared POSIX semantics with performance commensurate with direct DRAM, such as sharing container root filesystems, LLM model weights, or pooling DRAM across independent nodes. It simultaneously enables GPUs on the same PCIe/CXL fabric to coordinate access to these shared memory regions, introducing a new layer of data-path acceleration for GPU-dominated, bandwidth-intensive workloads.
DaxFS Architecture
The DaxFS architecture is grounded on three principles: (1) physical memory as the definitive file storage medium, (2) elimination of intermediate copies for both reads and memory mapping, and (3) complete reliance on hardware atomics—specifically CXL-coherent cmpxchg/CAS—for cross-host coordination.
The filesystem organizes the DAX-mapped memory region into up to four sequential areas: superblock, base image, hash overlay, and shared page cache. The overlay and cache regions are optional; their composition determines operating modes spanning read-only (static), writable overlays over base images (split), and ephemeral fully in-memory (empty) configurations.
Overlay and Lock-Free Coordination
Central to cross-host communication is the CAS-based hash overlay, an open-addressing hash table in DAX memory supporting all structural file operations. File writes, metadata updates, and directory operations are performed without locks: hosts insert and update overlay entries solely using 64-bit cmpxchg, with linear probing resolving hash conflicts. Pool allocation and free-list management among variable-sized entry types (inodes, pages, dirents) are similarly fully lock-free by design.
Cooperative Page Cache with MH-Clock
The shared page cache (pcache) implements a fully decentralized cache using a Multi-Host CLOCK (MH-clock) eviction algorithm adapted for hardware-coherent atomic operations. All state transitions, including slot acquisition, refcount management, and eviction, are carried out via single cmpxchg updates, supporting safe and lock-free operation across hosts. Each host can independently scan and manage cache slot eviction according to local access patterns without global coordination.
Zero-Copy Read and GPU Integration
The read path enables direct retrieval of DRAM pointers, allowing file data to be mmap’ed directly from DAX memory across all participating hosts. For GPU integration, DaxFS leverages dma-buf to export the DAX region into GPU address space. This permits GPUs to conduct load, overlay lookups, and even coordinate cache promotion/demotion using the PCIe AtomicOp TLP protocol, supporting peer-to-peer DMA scenarios in the accelerator data path.
Evaluation
DaxFS is evaluated across performance, scalability, and correctness metrics. Numerical results establish clear advantages over both existing DAX filesystems and DRAM-resident tmpfs in various regimes.
Sequential Throughput
DaxFS matches or surpasses tmpfs throughput in most sequential workloads. It achieves 59.2 MB/s in large (16 MB) sequential reads—6.2x that of ext4-dax—while matching tmpfs on 1 MB sequential reads (100 MB/s for both), with only a minor throughput deficit compared to tmpfs on very large transfers due to per-page overlay resolution overhead, which is amortized for smaller files.
(Figure 1)
Figure 1: Sequential read throughput comparison across filesystems illustrates the relative scaling of DaxFS, tmpfs, and ext4-dax as a function of workload size.
Sequential and Random Latency
DaxFS completes a 16 MB sequential read in only 274.2 ms (6.1x faster than ext4-dax's 1660.7 ms) and achieves parity with tmpfs on small-scope (1 MB) workloads.
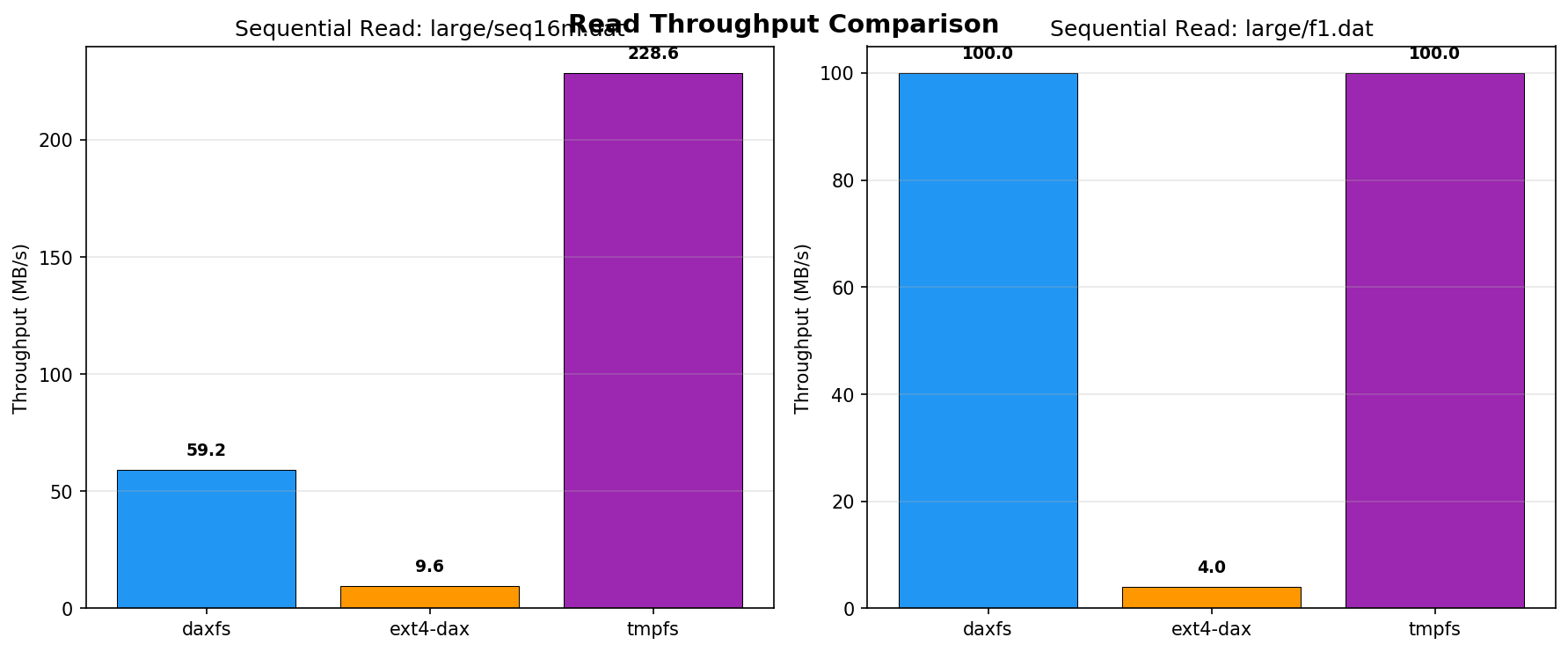
Figure 2: Sequential read latency comparison demonstrates DaxFS’s considerable improvement over ext4-dax, especially for larger transfers.
DaxFS achieves the lowest stat() operation latency (3,528 ms on 1,000 files), outperforming both tmpfs and ext4-dax, attributed to the flat overlay lookup structure. The only deficit appears in readdir, where the extra cost of walking both a base dirent array and overlay list (in the absence of per-directory indices) slightly increases latency versus its peers.
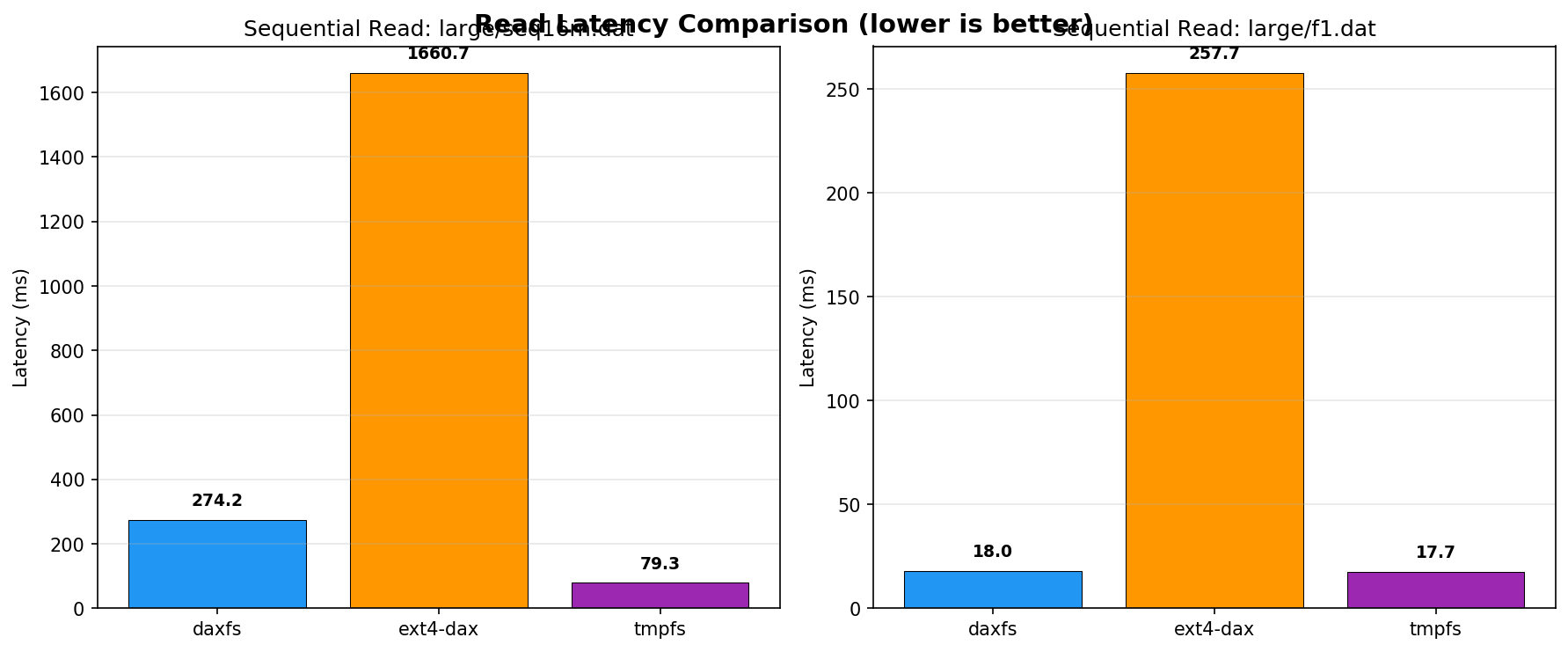
Figure 3: Metadata operation latency across stat and readdir highlights DaxFS’s metadata lookup advantage, with only readdir showing marginally higher latency.
Random I/O and Scaling
Random read throughput at 64 KB and 4 threads peaks at 1.18x that of tmpfs (15.1 GiB/s vs. 12.8 GiB/s). For random writes, the lock-free fast path provides substantial scaling: with 4 threads and 4 KB blocks, DaxFS reaches 2.68x tmpfs's throughput. All concurrent access patterns benefit from absence of page cache lock serialization.
The comprehensive benchmark normalization illustrates DaxFS’s performance envelope: it matches tmpfs at 1 MB sequential reads, leads in stat lookup, and substantially exceeds ext4-dax across all read and write I/O categories. Only on select metadata and large sequential workloads does overlay or directory scan overhead make it less competitive.
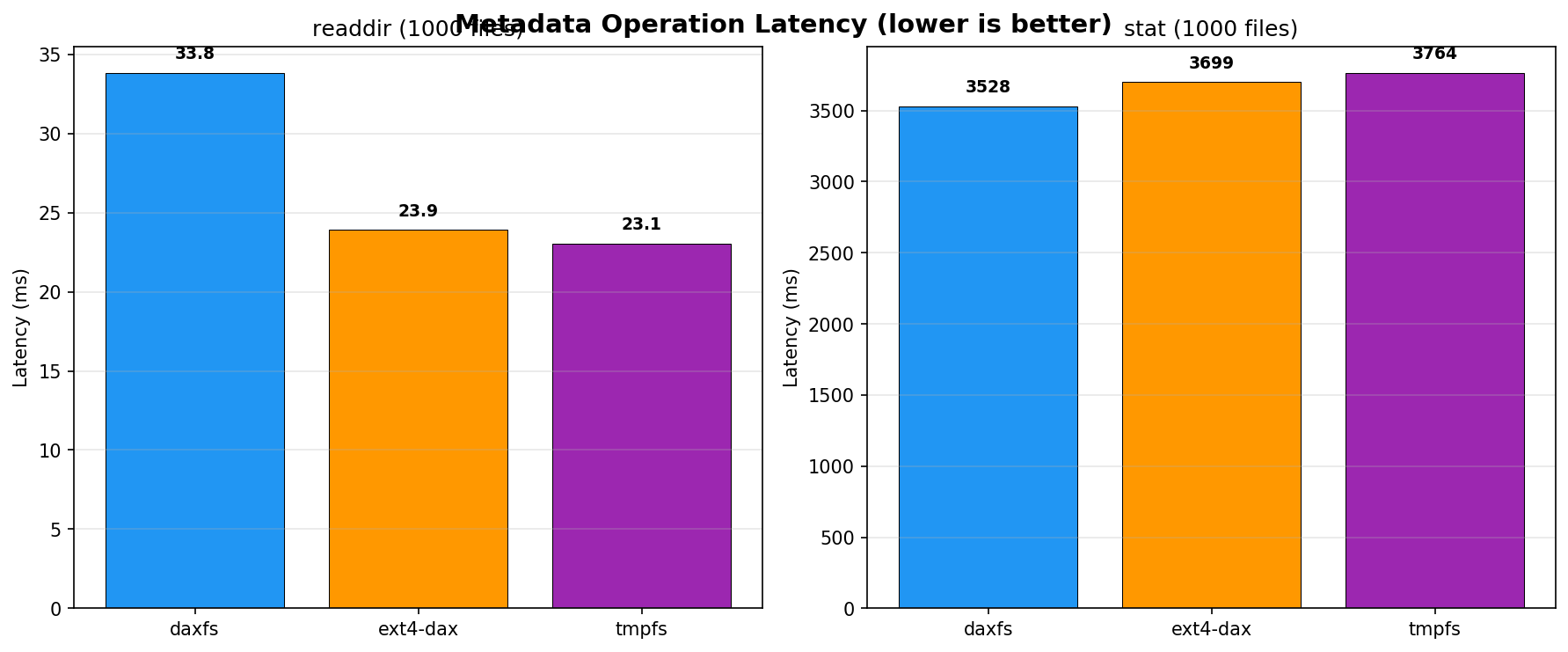
Figure 4: Normalized performance summary across all benchmarks shows DaxFS’s dominance in both data and metadata microbenchmarks.
GPU PCIe AtomicOps and Multi-Host Emulation
DaxFS’s GPU-access coordination is evaluated at PCIe 5.0 bandwidth by exporting the DAX region via dma-buf and invoking atomic operations from CUDA threads. Fast cache hit paths achieve 500+ Mops/s at high concurrency; atomic operations saturate PCIe bandwidth, confirming negligible software inefficiency. The slow path (cold cache claim) is intentionally serialized but rare in practice.
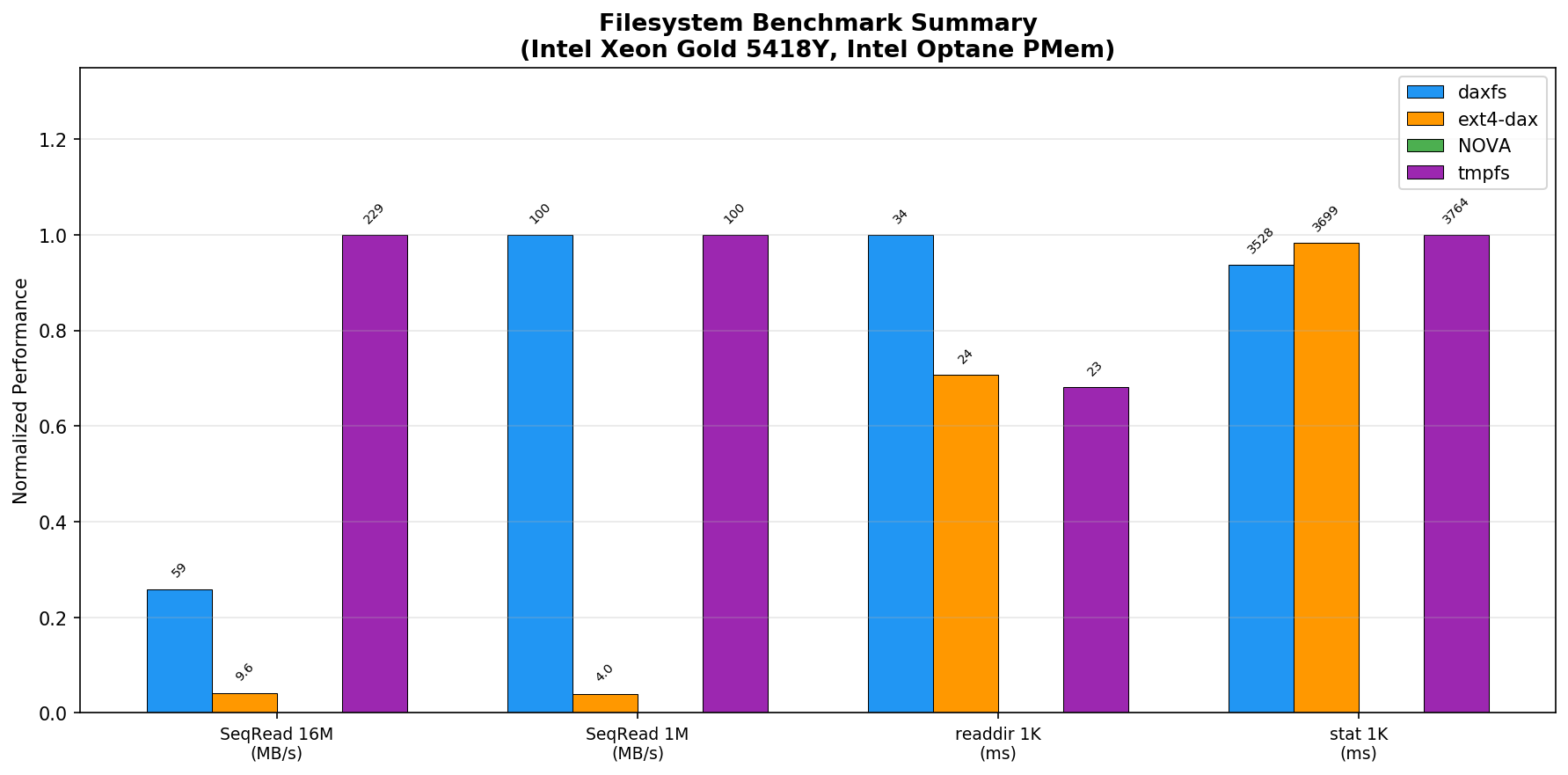
Figure 5: GPU PCIe AtomicOp coordination benchmarks show achievable lookup, slot CAS, and lock contention rates up to hardware bandwidth limits.
Multi-host correctness is validated with QEMU-based emulation of CXL 3.0 multi-host sharing. Even under high contention, DaxFS maintains >99% CAS success rates, with no lost updates on overlay or cache slots, and inserts scale linearly between hosts. Overhead in emulation is entirely attributable to TCP transport, not the filesystem’s protocols.
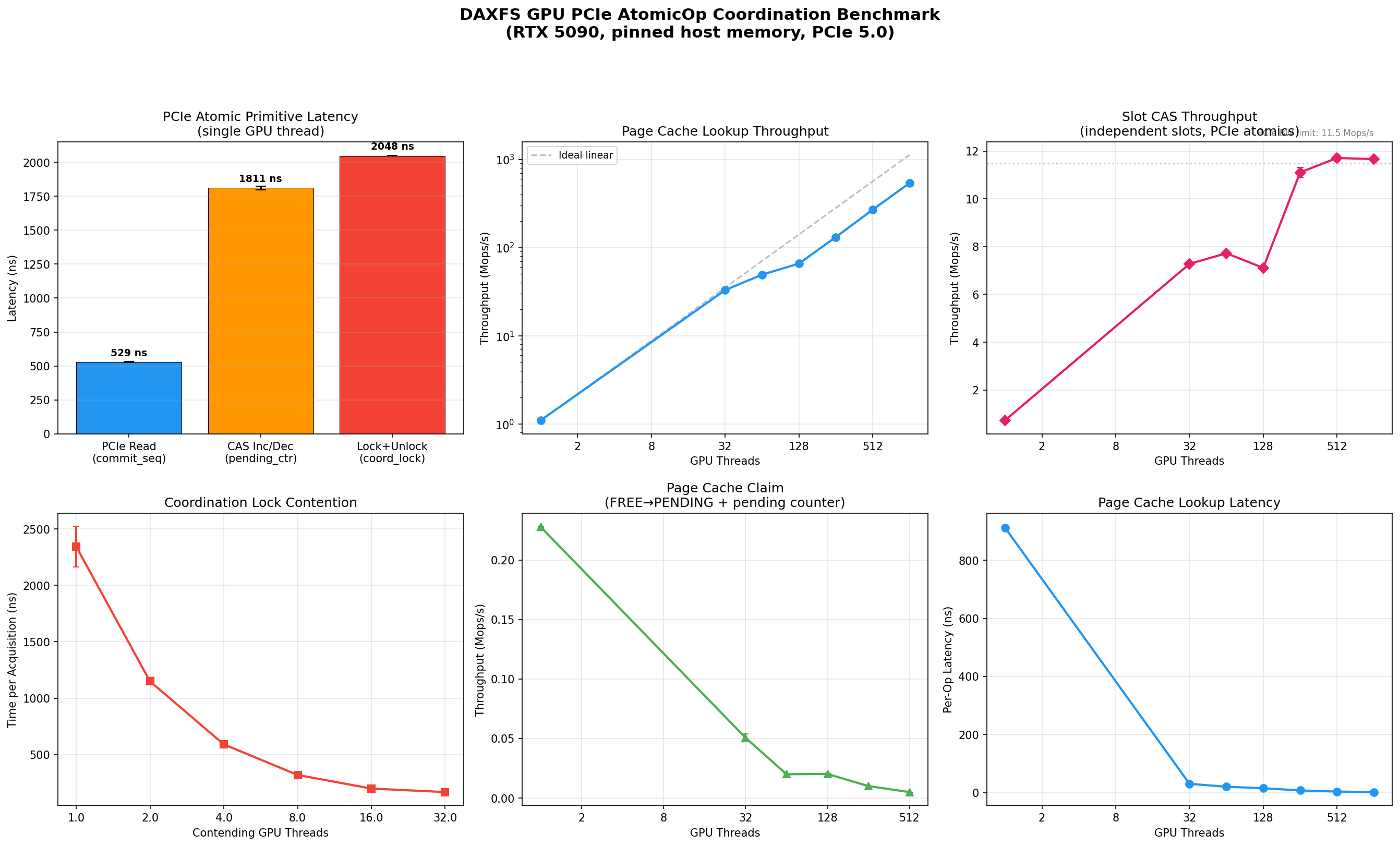
Figure 6: Multi-host CXL 3.0 benchmark dashboard; CAS accuracy, throughput, and latency are plotted for dual-host TCP-emulated atomic operations.
Limitations and Future Directions
The design of DaxFS assumes fixed-size overlays, with dynamic resizing requiring stop-the-world migration. The linear scan requirements of flat directories may hamper performance for exceedingly large directories (>10k entries). There are no provisions for explicit persistence (clwb) in the absence of hardware ADR, and POSIX semantics are constrained (e.g., lack of xattr, special file types). GPU write-through is architecturally possible but not yet implemented.
Advancements in CXL hardware (especially with hardware-accelerated atomic bandwidth and lower inter-host latencies) will mitigate emulation overheads. Future directions involve overlay resizing, more scalable directory indexing, transparent persistence, and full GPU-initiated data path write support.
Theoretical and Practical Implications
DaxFS demonstrates that when atomic operations are sufficiently performant and hardware-coherent at the memory controller, lock-free concurrency control for file I/O primitives across hosts becomes viable at DRAM-scale latency. This invalidates traditional scalability constraints in shared filesystems, eliminates the necessity for distributed lock managers, and enables a fully decentralized shared page cache. For GPU-centric workloads, DaxFS enables direct accelerator participation in filesystem protocols, foreshadowing OS designs in which storage and memory hierarchies become fluid, compute-fabric cooperative resources.
Conclusion
DaxFS establishes a new design paradigm for shared filesystems on CXL-based disaggregated memory. By grounding all cross-host coordination in cmpxchg and implementing decentralized, lock-free protocols for overlays and caching, DaxFS achieves high concurrency, cross-host cache sharing, and zero-copy access with performance on par with or above DRAM-resident filesystems in most workloads. These properties render it well-suited for the forthcoming era of CXL composable memory, where the filesystem layer must become transparent, scalable, and suitable for direct accelerator access.
Reference: "DAXFS: A Lock-Free Shared Filesystem for CXL Disaggregated Memory" (2604.01620)

