Improving Latent Generalization Using Test-time Compute
Abstract: LLMs (LMs) exhibit two distinct mechanisms for knowledge acquisition: in-weights learning (i.e., encoding information within the model weights) and in-context learning (ICL). Although these two modes offer complementary strengths, in-weights learning frequently struggles to facilitate deductive reasoning over the internalized knowledge. We characterize this limitation as a deficit in latent generalization, of which the reversal curse is one example. Conversely, in-context learning demonstrates highly robust latent generalization capabilities. To improve latent generalization from in-weights knowledge, prior approaches rely on train-time data augmentation, yet these techniques are task-specific, scale poorly, and fail to generalize to out-of-distribution knowledge. To overcome these shortcomings, this work studies how models can be taught to use test-time compute, or 'thinking', specifically to improve latent generalization. We use Reinforcement Learning (RL) from correctness feedback to train models to produce long chains-of-thought (CoTs) to improve latent generalization. Our experiments show that this thinking approach not only resolves many instances of latent generalization failures on in-distribution knowledge but also, unlike augmentation baselines, generalizes to new knowledge for which no RL was performed. Nevertheless, on pure reversal tasks, we find that thinking does not unlock direct knowledge inversion, but the generate-and-verify ability of thinking models enables them to get well above chance performance. The brittleness of factual self-verification means thinking models still remain well below the performance of in-context learning for this task. Overall, our results establish test-time thinking as a flexible and promising direction for improving the latent generalization of LMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Improving Latent Generalization Using Test-time Compute — Explained Simply
What this paper is about
This paper asks: can we teach AI LLMs to “think” more at the moment they answer a question so they use what they already know in smarter ways? The authors show that giving a model extra time and guidance to reason step by step at test time helps it connect facts it learned during training, especially for logic-like tasks. They call this improving “latent generalization.”
Key ideas and questions the paper explores
Before diving in, here are a few quick definitions:
- In-weights learning: facts the model has learned and stored in its “memory” (its parameters) during training. Think “closed-book test.”
- In-context learning (ICL): giving the model examples in the prompt so it can work from them. Think “open-book test.”
- Latent generalization: using what you know to answer questions that are logically implied but not written exactly the same way during training.
- The “reversal curse”: the model learns A → B but struggles with B → A. For example, it learns “dogs are mammals,” but fails on “mammals include dogs.”
With those in mind, the paper tackles simple questions:
- Can we train models to spend a bit more time “thinking” at test time so they use their stored knowledge better?
- Is this better than adding a lot of special training data (called “data augmentation”) to cover every case?
- Does this kind of “thinking” help on new, slightly different tasks the model wasn’t trained on?
- Does it fix the reversal curse?
How the researchers tested their ideas (in everyday terms)
The team used a three-step approach. You can think of it like training a student for a quiz:
- Teach the facts (Knowledge Acquisition)
- They fine-tuned a LLM on new, cleanly controlled facts (to avoid any data leaks from pre-training). This is like giving the student a set of study notes.
- Teach how to think through problems (Thinking Bootstrapping)
- They asked a “teacher” model to write high-quality step-by-step solutions showing the right way to think: recall the right facts, ask yourself questions, try ideas, and check them (“guess-and-check”).
- They trained the main model to imitate these good thinking steps. Analogy: a tutor shows worked examples, and the student practices explaining their thinking.
- Practice with feedback (Reinforcement Learning from correctness)
- They let the model try answering problems and rewarded it when the final answer was correct. This is like practice quizzes where correct answers earn points, nudging the model toward useful ways of thinking.
- Important: they trained on one dataset and then also tested on a different-but-related dataset to check if the model’s thinking skills generalize.
They compared this “thinking at test time” method to:
- Regular fine-tuning (just learning facts).
- Fine-tuning plus extra training data (data augmentation).
- Those same baselines with reinforcement learning but without step-by-step thinking.
- In-context learning (giving all the training facts in the prompt — the strong “open-book” baseline).
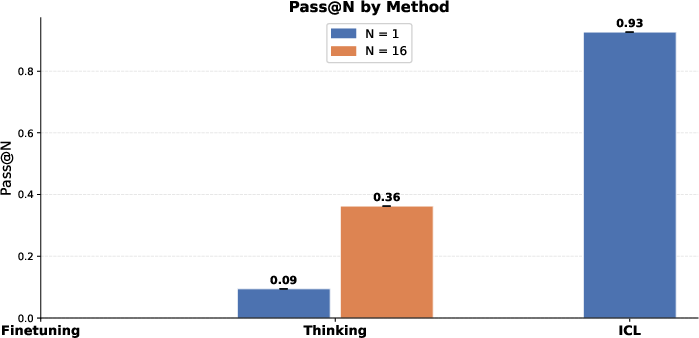
They measured performance by asking the model to list all correct answers for a query (like “which things are in this category?”) and checked precision, recall, F1, and whether it gets everything exactly right if we let it try multiple times.
What they found and why it matters
Here are the main takeaways in plain language:
- Test-time “thinking” helps the model connect facts it already knows.
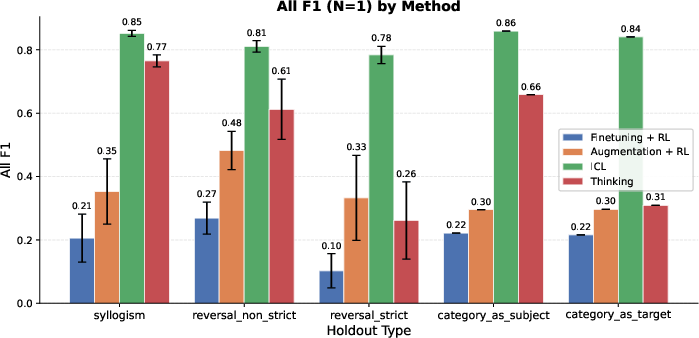
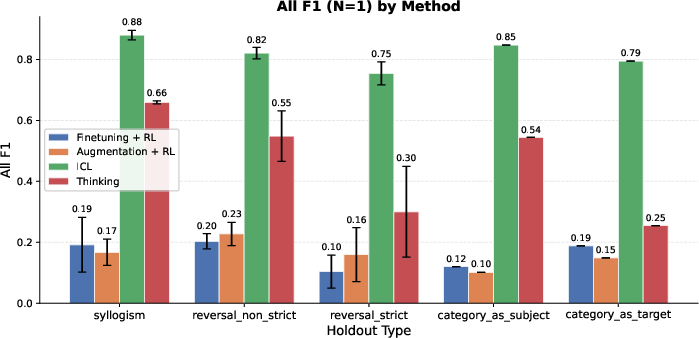
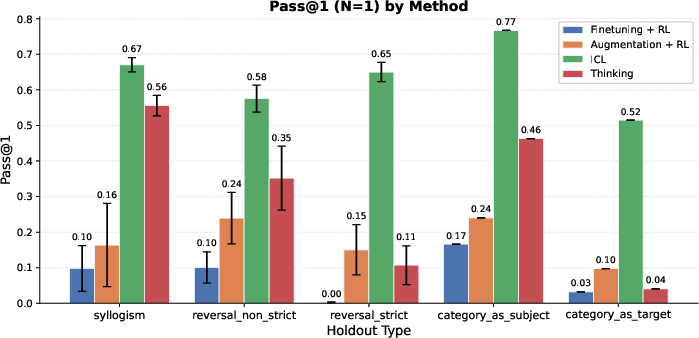
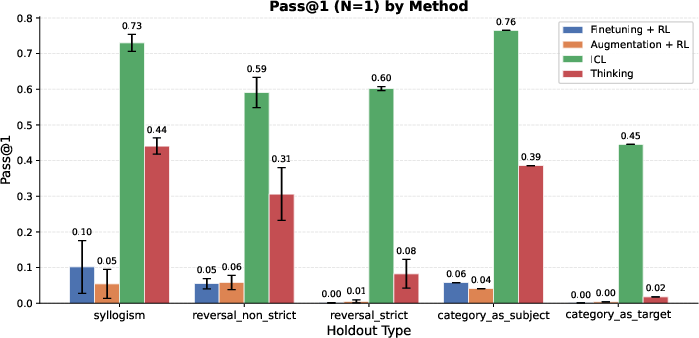
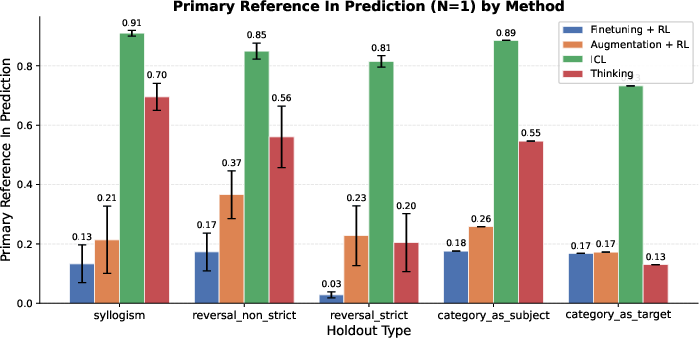
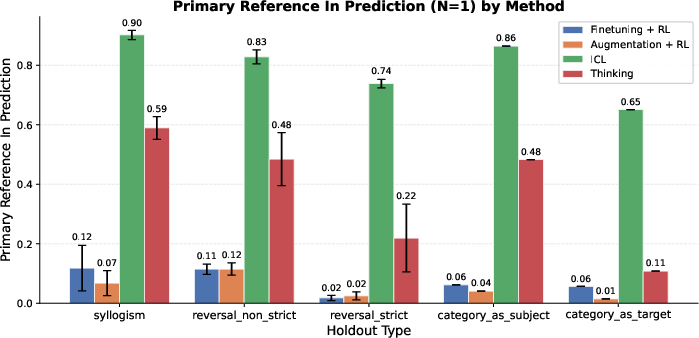
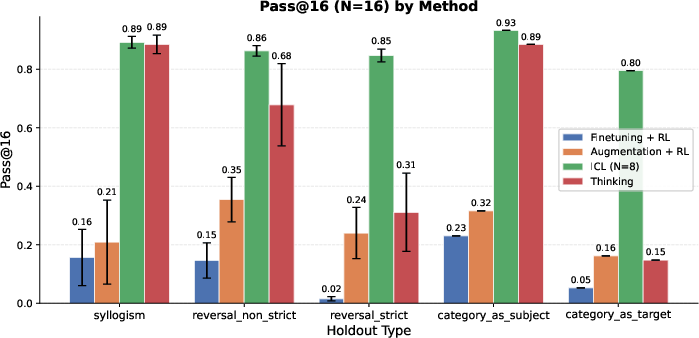
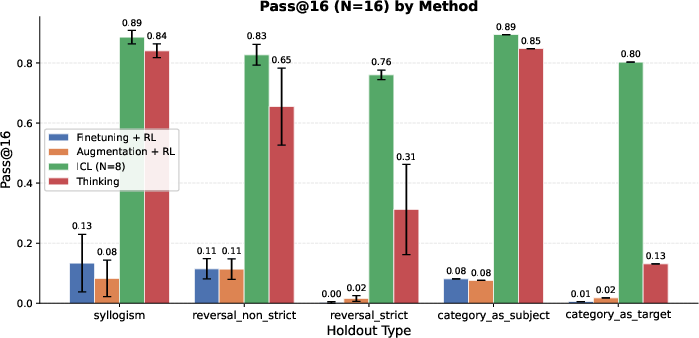
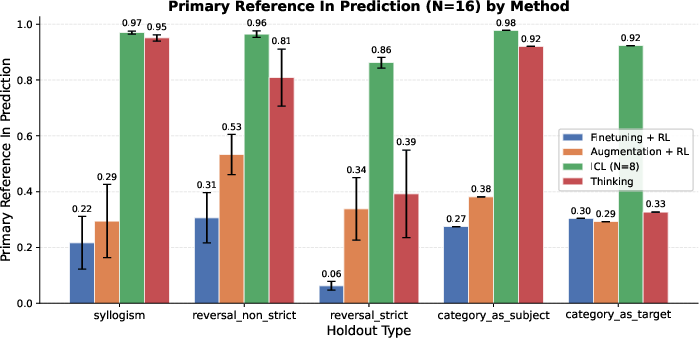
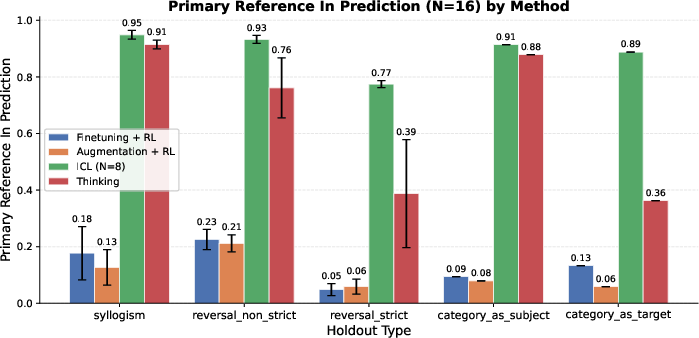
- For tasks that need combining facts (like syllogisms: “dogs are mammals” and “mammals are warm-blooded,” so “dogs are warm-blooded”), the thinking-trained models did much better than models trained with extra data alone.
- In many cases, the thinking models approached the “open-book” baseline (ICL), even though they weren’t given all facts in the prompt.
- It generalizes to new-but-similar situations.
- Models trained to think didn’t just memorize a specific dataset; they performed well on new structures the model hadn’t practiced thinking on. This shows the “thinking habit” can carry over.
- In contrast, adding lots of special training examples (data augmentation) helped mostly on the exact kinds of cases it covered and didn’t transfer well.
- Pure reversals (the “reversal curse”) are still hard.
- For strict “reverse” questions (B → A with no alternative reasoning path), thinking helped somewhat (thanks to “generate-and-verify,” a kind of guess-and-check), but not enough to beat the “open-book” ICL baseline.
- The model’s self-checking of facts can be brittle — it doesn’t always reliably verify its guesses.
- Reinforcement learning improves baselines too, but the real boost comes when it’s combined with good step-by-step reasoning.
- RL alone (without thinking steps) improved factual accuracy, but it didn’t unlock the same level of latent generalization as the thinking approach.
Why this matters:
- It shows a more flexible way to improve how models use their stored knowledge without needing to create huge, carefully engineered training sets for every new task.
- It highlights limits of today’s models: direct inversions (like strict reversals) remain tough, suggesting deeper architectural or training changes might be needed.
What this could mean for the future
- Teaching models to “think” at test time is a promising, scalable way to help them use what they already know in smarter ways, especially for multi-step logic.
- However, stubborn problems like the reversal curse suggest that just thinking more isn’t always enough. Future progress may require:
- New model designs that store and retrieve facts more flexibly.
- Different training objectives that encourage reversible or bidirectional understanding.
- Better methods for reliable self-verification.
In short: giving models time and training to think through problems helps them generalize from what they’ve learned — especially when they need to connect multiple facts — and often works better than piling on more training examples. But certain kinds of logic, like pure reversals, still need deeper solutions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper’s approach and findings.
- External validity beyond synthetic settings: Assess whether the proposed thinking+RL method improves latent generalization on real-world, open-domain knowledge tasks (e.g., Wikipedia-based multi-hop QA) under strict contamination controls.
- Model generality: Replicate on diverse base models (open-source and proprietary, different sizes and pretraining regimes) to quantify dependence on pre-existing reasoning ability and instruction tuning.
- Stronger OOD tests: Evaluate transfer to structures with different depth/branching, unseen relation types, noisy or contradictory facts, and more realistic heterogeneity—not just minor property-type changes.
- Strict reversal gap: Develop and test methods that enable true zero-hop inversions beyond generate-and-verify (e.g., explicit inversion operators, symbolic modules, search over parametric memory), and benchmark against ICL.
- Self-verification brittleness: Quantify where and why factual self-verification fails; compare one-model self-check vs. a separate verifier; measure calibration and agreement under perturbations.
- Candidate generation bottleneck: The method’s success on strict reversals hinges on proposing the correct entity; study mechanisms to ensure recall without unconditional name-output augmentation (e.g., learned candidate generation, internal retrieval).
- Compute/latency trade-offs: Provide compute-normalized comparisons (total tokens, wall-clock), optimal thought length, and pass@N vs. cost curves; evaluate against ICL’s context cost and augmentation’s train-time cost.
- RL objective design: Ablate reward shaping (final-answer vs. step-wise), variance reduction/baselines, KL penalties, and explicit penalties for unnecessary thought length; report sensitivity and stability.
- Thought behavior ablations: Isolate contributions of “focus-driven recall,” “self-probing,” and “generate-and-verify” by removing each behavior and measuring deltas on in-/out-of-distribution splits.
- Leakage auditing: Rigorously audit that thought traces do not leak held-out facts (especially on the reversal dataset where protections were not applied); implement automated leakage detectors and red-team evaluations.
- Side effects on other capabilities: Quantify impacts on instruction-following, general factuality, hallucination rate, and calibration across standard benchmarks pre/post thinking+RL training.
- Synergy with augmentation: Test augmentation+thinking+RL combinations to see if they close the strict reversal gap or further help multi-hop generalization.
- Retrieval/tool integration: Compare to and combine with retrieval-augmented generation or learned memory modules; test whether external retrieval plus thinking resolves strict reversals more reliably.
- Mechanistic understanding: Empirically probe the KV-association hypothesis for reversals via interpretability (causal tracing, attention pattern analysis) and measure how thinking changes internal activations/retrieval.
- Prompt and decoding robustness: Evaluate sensitivity to prompt style, distractors, adversarial phrasing, temperature, and decoding strategies; establish robust defaults.
- Cross-task transfer: Train thinking on one latent structure (e.g., syllogisms) and test transfer to qualitatively different latent tasks (temporal, causal, spatial, relational algebra).
- Data efficiency: Provide learning curves for bootstrapping and RL (number of prompts vs. gains), minimal data needed to achieve OOD improvements, and diminishing returns analyses.
- Teacher dependence: Test different teacher qualities and sizes, or self-generated STaR without a teacher; quantify how teacher correctness and style affect downstream latent generalization.
- Reproducibility details: Release full RL configs (advantages, KL, reward shaping), sampling policies, thought-length limits, seeds, and code to enable replication and fair comparison.
- Baseline parity: Include baselines that allow CoT during RL without specialized bootstrapping, and augmentation baselines that also use CoT, to disentangle the effect of thought vs. data exposure.
- Evaluation breadth: Complement exact match/F1 with calibrated confidence, partial-credit measures for set predictions, and normalization/aliasing rules for string matching; report variance across seeds.
- Scaling laws: Characterize how gains scale with model size, thought-token budget, and RL data; identify thresholds where thinking ceases to help or leads to diminishing returns.
- Memory interference: Measure whether SFT of new knowledge or thinking+RL induces catastrophic forgetting or alters latent generalization on prior knowledge.
- Adversarial training: Explore hard-negative and counterfactual training to strengthen self-verification and reduce susceptibility to spurious matches during generate-and-verify.
- Privacy and safety: Assess whether thought traces expose sensitive or proprietary training facts and evaluate mitigation strategies (e.g., redactible thoughts, verifier-only reasoning).
- Modality and domain extension: Test applicability to code reasoning, scientific facts, and multimodal settings where latent relationships are cross-modal (e.g., image-category hierarchies).
Practical Applications
Overview
Based on the paper’s findings, below are concrete, real-world applications that leverage “test-time thinking” (long chain-of-thought with generate-and-verify) trained via RL from correctness to improve latent generalization (deductive use of in-weights knowledge). Each item lists likely sectors, candidate tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be deployed with current LLMs and engineering practices, acknowledging the paper’s caveats (notably, strict reversals remain brittle).
- Enterprise knowledge ingestion with thinking-enhanced fine-tuning
- Sectors: software, enterprise IT, knowledge management
- What: Replace large-scale data augmentation with a fine-tuning pipeline that adds “thinking” (focus-driven recall, self-probing, generate-and-verify) to improve multi-hop latent generalization over internal docs and taxonomies.
- Tools/Workflows: SFT of base model on internal documents; thinking bootstrapping using a teacher LLM to produce golden traces; RL from correctness; inference-time “reasoning mode” with pass@k; leakage-safe CoT prompts.
- Assumptions/Dependencies: Access to a capable teacher model; correctness signals for RL rewards; additional inference-time compute budget; careful prevention of CoT leakage; base model already supports reasoning traces.
- Compliance and policy Q&A over in-weights rules (multi-hop deduction)
- Sectors: finance, healthcare, legal, public sector
- What: Answer policy/compliance questions that require combining multiple trained rules (e.g., deducing obligations from layered regulations) without enumerating all implications during training.
- Tools/Workflows: Generate-and-verify CoT; pass@N sampling for high-stakes answers; correctness-oriented RL on representative QA; audit of “held-out recall.”
- Assumptions/Dependencies: Access to authoritative verifiers/SME review; latency budget; strict reversals (e.g., mapping reverse relations) remain unreliable and need fallback (ICL/RAG/human-in-the-loop).
- Customer-support policy assistants that infer implied actions
- Sectors: customer support, SaaS, telecom
- What: Given product and support policies learned during fine-tuning, deduce implied eligibility, escalation paths, and exception rules without explicitly training on every scenario.
- Tools/Workflows: Thinking templates emphasizing focus-driven recall; pass@k aggregation; confidence-based routing to human agents when uncertainty is high.
- Assumptions/Dependencies: Representative policy corpora; QA data for reward shaping; monitoring for hallucinations; compute cost controls.
- Engineering documentation copilots for multi-hop knowledge
- Sectors: software engineering, DevOps, platform teams
- What: Infer compatibility constraints, deprecations, and transitive dependencies from internal docs (e.g., API X implies using auth flow Y, which requires permission Z).
- Tools/Workflows: Thinking-enabled inference mode for design/code reviews; generate-and-verify to reduce hallucinations; “latent generalization tests” as CI checks.
- Assumptions/Dependencies: High-quality internal doc curation; reward signals for correctness; latency tolerance during reviews.
- Education and training tutors that infer implied concepts
- Sectors: education, corporate L&D
- What: Provide explanations that chain together multiple learned facts (syllogisms, non-strict reversals), enabling concept transfer across lessons or modules.
- Tools/Workflows: Thinking traces designed for concept composition; pass@k for diversified explanations; feedback-driven RL on correctness/rubrics.
- Assumptions/Dependencies: Curated curricula with testable answers; vigilance against strict reversal tasks that remain brittle.
- Retrieval-optional multi-hop answering over parametric knowledge
- Sectors: knowledge assistants across domains
- What: When retrieval is unavailable or noisy, use thinking to combine stored facts for multi-hop answers (e.g., category/property inheritance).
- Tools/Workflows: Dynamic inference controller that escalates to thinking mode for queries flagged as latent-generalization-heavy.
- Assumptions/Dependencies: Base model must have already internalized relevant facts; cost/latency budgets; fallback to ICL/RAG for strict reversals.
- Reduced need for task-specific data augmentation
- Sectors: ML platform/ops
- What: Lower reliance on handcrafted augmentation for new knowledge structures by teaching models to reason at test time, improving OOD latent generalization relative to augmentation baselines.
- Tools/Workflows: Thinking bootstrapping dataset generator; RL trainer with correctness rewards; dashboards that track “held-out recall” vs. “train recall.”
- Assumptions/Dependencies: Teacher LLM; correctness metrics; controls to prevent trace leakage; compute budget during RL and inference.
- Inference-time compute budgeting for latent-generalization queries
- Sectors: AI platform, cost optimization
- What: Predict which queries need extra “thinking” and allocate CoT tokens accordingly to improve F1/Pass@N while controlling spend.
- Tools/Workflows: Classifier to route queries to thinking vs. direct answer; pass@k strategy with early stopping upon verification.
- Assumptions/Dependencies: Reliable signals for routing; monitoring to avoid runaway token use; product SLAs.
- Evaluation harnesses for latent generalization
- Sectors: industry and academia (ML eval)
- What: Adopt the paper’s metrics (Overall/Train/Held-out Recall, F1, Pass@N, primary-reference inclusion) to audit fine-tunes for generalization vs. memorization.
- Tools/Workflows: Synthetic “semantic structure” style tests per domain; CI gate that requires minimal “held-out recall” before deployment.
- Assumptions/Dependencies: Domain-specific ground-truth generation; engineering for leakage-safe traces.
- Partial support for reverse-lookup tasks via generate-and-verify
- Sectors: daily life assistants, CRM, research tools
- What: Suggest a name/ID from a description by proposing candidates and self-verifying against stored facts (above-chance performance).
- Tools/Workflows: Multi-attempt candidate generation; self-verification within CoT; user-in-the-loop confirmation.
- Assumptions/Dependencies: Brittle self-verification; strict reversal remains weaker than ICL/RAG—must include fallbacks and disclaimers.
Long-Term Applications
These require further research, scaling, or architectural advances (e.g., overcoming strict-reversal limitations, improving self-verification reliability).
- Robust inversion of parametric knowledge (beyond reversal curse)
- Sectors: healthcare, finance, legal, scientific curation, CRM
- What: Dependably map descriptions-to-entities or invert relations from in-weights memory without ICL/RAG dependence.
- Tools/Workflows: New architectural inductive biases or loss functions; stronger self-verification; improved generate-and-verify strategies.
- Assumptions/Dependencies: Advances in model architecture/objectives; better verifiers; systematic evaluations across strict-reversal benchmarks.
- High-assurance reasoning in regulated settings
- Sectors: healthcare (clinical decision support), finance (risk/compliance), public sector (regulatory interpretation)
- What: Thinking-enabled systems with guarantees (e.g., structured proofs, auditor-friendly traces, robust self-verification) for high-stakes decisions.
- Tools/Workflows: Coupling reasoning with symbolic/KB checks; formal verification pipelines; audit logging and redaction.
- Assumptions/Dependencies: Mature verification toolchains; standardized governance for chain-of-thought; acceptance by regulators.
- Auto-bootstrapped teacher–student reasoning frameworks
- Sectors: ML infrastructure, enterprise AI
- What: Reduce reliance on external teacher LLMs by self-generating and self-critiquing reasoning traces that target latent generalization behaviors.
- Tools/Workflows: Self-generated golden traces; consistency and correctness filtering; curriculum shaping for reasoning skills.
- Assumptions/Dependencies: Reliable automated verifiers; guardrails against self-reinforcing errors; compute resources.
- Privacy-preserving chain-of-thought and leakage controls
- Sectors: enterprise, healthcare, government
- What: Methods to redact/summarize thought traces while retaining benefits, with governance that prevents training/test leakage and sensitive data exposure.
- Tools/Workflows: CoT redaction policies; structured thought schemas; leakage detection and monitors.
- Assumptions/Dependencies: Agreed standards for safe CoT; alignment between privacy and auditability.
- Hybrid RAG + thinking controllers for latent generalization
- Sectors: legal, research, enterprise knowledge search
- What: Controllers that decide when to (1) retrieve, (2) rely on parametric thinking, or (3) combine both, optimizing for correctness, cost, and latency.
- Tools/Workflows: Decision policies trained with RL; uncertainty-aware routing; post-hoc verification against sources.
- Assumptions/Dependencies: High-quality retrieval; calibrated uncertainty; well-defined cost–quality tradeoffs.
- Scalable correctness reward modeling and RL for factual reasoning
- Sectors: ML platforms, foundation model providers
- What: General-purpose reward models/critics to score multi-answer correctness (sets) and support long CoT training at scale.
- Tools/Workflows: Reward-model training data pipelines; batched REINFORCE/advantage estimators; variance reduction and stability techniques.
- Assumptions/Dependencies: Labeling/weak supervision for correctness; compute budgets; stability in long-horizon token credit assignment.
- Domain-adaptive latent generalization benchmarks and policy standards
- Sectors: academia, standards bodies, public policy
- What: Benchmarks and procurement standards that require reporting held-out recall, Pass@N, and OOD latent generalization for fine-tuned systems.
- Tools/Workflows: Open datasets mirroring “semantic structure” tasks in key domains; certification checklists for thinking systems.
- Assumptions/Dependencies: Community consensus on metrics; public/private collaboration; incentives for compliance.
- Multi-agent generate-and-verify ensembles
- Sectors: scientific discovery, enterprise analytics, safety-critical ops
- What: Ensembles of specialized agents (retriever, reasoner, verifier) collaboratively compose and check parametric knowledge for complex queries.
- Tools/Workflows: Orchestration frameworks; debate/consensus protocols; diversity-aware sampling to boost Pass@N.
- Assumptions/Dependencies: Coordination costs; robust verifiers; governance for agent-generated CoT.
Cross-cutting assumptions and constraints
- Compute and latency: Thinking increases token usage and latency; production systems need routing and budgets.
- Base-model quality: Benefits assume a model capable of generating and using chain-of-thought.
- Correctness signals: RL from correctness needs ground-truth or reliable verifiers; domain coverage matters.
- Strict reversals: Still challenging; expect to rely on ICL/RAG or user confirmation in the near term.
- Leakage and safety: CoT may leak held-out or sensitive information; adopt leakage prevention and redaction.
- OOD robustness: The method improves OOD latent generalization relative to augmentation, but coverage of new domains still depends on what was internalized during fine-tuning.
Glossary
- Autoregressive next-token prediction objective: The training objective of predicting the next token in a sequence, which can shape how transformers store and retrieve associations. "We hypothesize this limitation stems from the rigid key-value associative memory structures that models acquire as a consequence of the transformer architecture and the autoregressive next-token prediction objective."
- Bootstrapped estimator: A resampling-based method to reduce variance and estimate statistics by repeatedly sampling with replacement. "and use a bootstrapped estimator over all completions to reduce variance."
- Catastrophic forgetting: The tendency of a model to lose previously learned capabilities when fine-tuned on new data. "not confounded by the catastrophic forgetting of pre-existing instruction-following and reasoning capabilities."
- Chain-of-Thought (CoT): Explicit intermediate reasoning steps generated by a model to solve a problem, often improving reasoning performance. "We use Reinforcement Learning (RL) from correctness feedback to train models to produce long chains-of-thought (CoTs) to improve latent generalization."
- Closed-book Question Answering (QA): Answering questions without access to external documents or the training set at inference time. "For evaluation, we employ a closed-book Question Answering (QA) framework,"
- Correctness feedback: A signal indicating whether a model’s output is correct, used to guide reinforcement learning. "We use Reinforcement Learning (RL) from correctness feedback to train models to produce long chains-of-thought (CoTs) to improve latent generalization."
- Data contamination: Unintended overlap between training and evaluation data that can inflate performance estimates. "strict exclusion from the model's pre-training corpus to prevent data contamination"
- Disjoint dataset: A dataset that shares no overlapping examples with another set, used to test out-of-distribution generalization. "we keep a disjoint dataset that is strictly excluded from both the bootstrapping and RL training mixtures,"
- Generate-and-verify: A reasoning strategy where candidates are proposed and then checked against known facts. "the generate-and-verify ability of thinking models enables them to get well above chance performance."
- Golden reasoning traces: High-quality, teacher-curated reasoning examples used to train or bootstrap a model’s thinking process. "to curate a dataset with golden reasoning traces on a small subset of examples"
- Hallucinations: Model-generated content that is plausible-sounding but ungrounded or incorrect. "To reduce hallucinations in these reasoning traces, we condition the teacher LLM on the ground-truth answer"
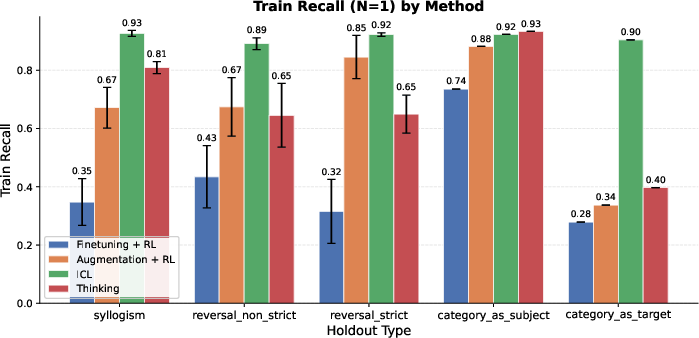
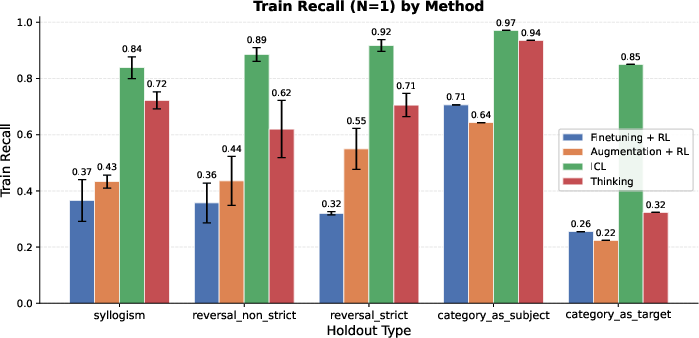
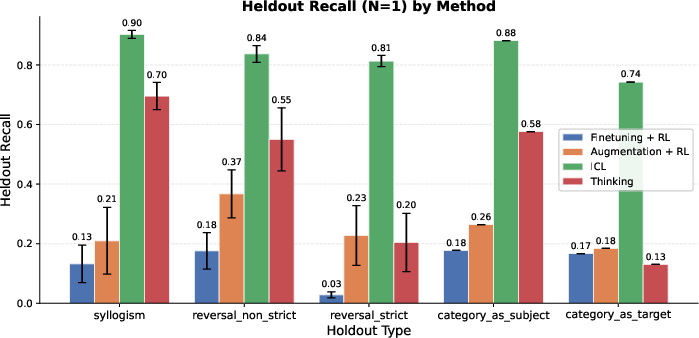
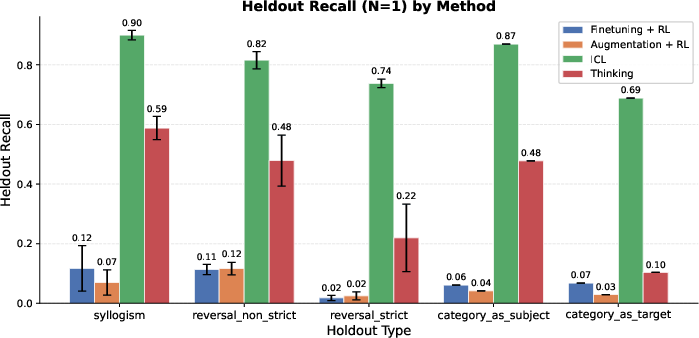
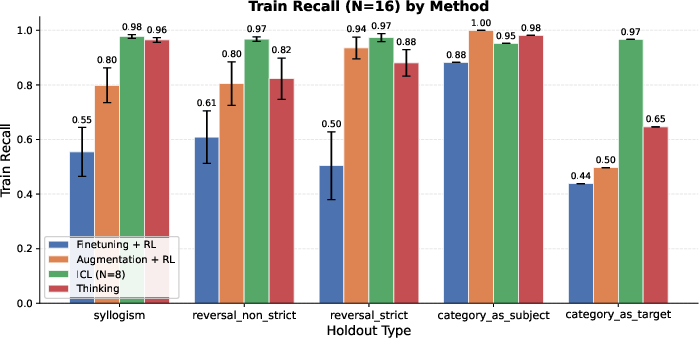
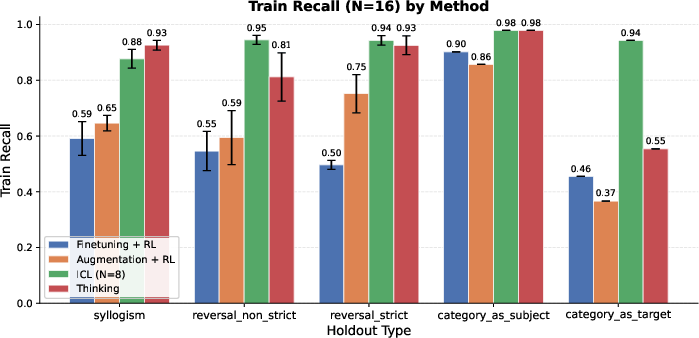
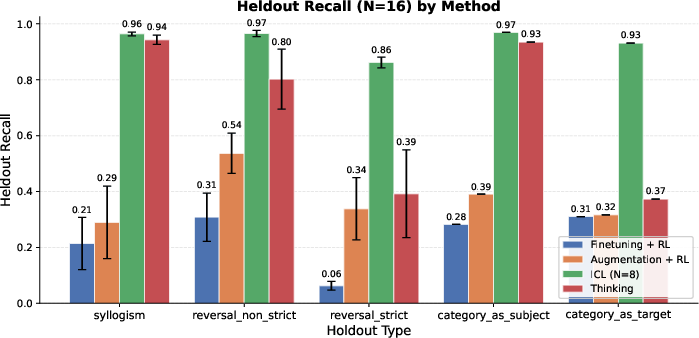
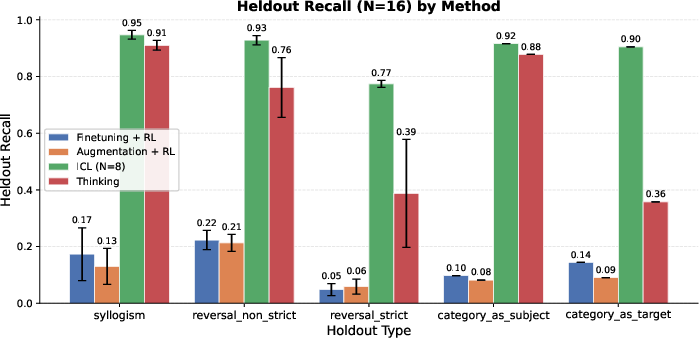
- Held-out Recall: The recall computed only on answers intentionally excluded from training, measuring true latent generalization. "Held-out Recall: The recall evaluated exclusively on the held-out subset , serving as a direct measure of latent generalization."
- In-Context Learning (ICL): Learning demonstrated by conditioning on examples provided in the prompt at test time, without weight updates. "LLMs typically exhibit strong latent generalization under this ICL paradigm."
- In-context generalization: A model’s ability to generalize using information supplied in the current context window. "The in-context generalization of LLMs is remarkably consistent even when they are queried for knowledge that is logically implied but not directly stated in the information present in the context."
- In-weights learning: Knowledge embedded directly in the model parameters through training or fine-tuning, not through context. "LLMs (LMs) exhibit two distinct mechanisms for knowledge acquisition: in-weights learning (i.e., encoding information within the model weights) and in-context learning (ICL)."
- Key-value associative memory structures: Internal representational patterns in transformers that link keys to values, shaping retrieval behavior. "We hypothesize this limitation stems from the rigid key-value associative memory structures that models acquire as a consequence of the transformer architecture and the autoregressive next-token prediction objective."
- Knowledge acquisition: The phase where new facts are incorporated into a model’s parameters, often via fine-tuning. "During the knowledge acquisition phase, we introduce a data augmentation step requiring the model to unconditionally output a randomly sampled name from the dataset."
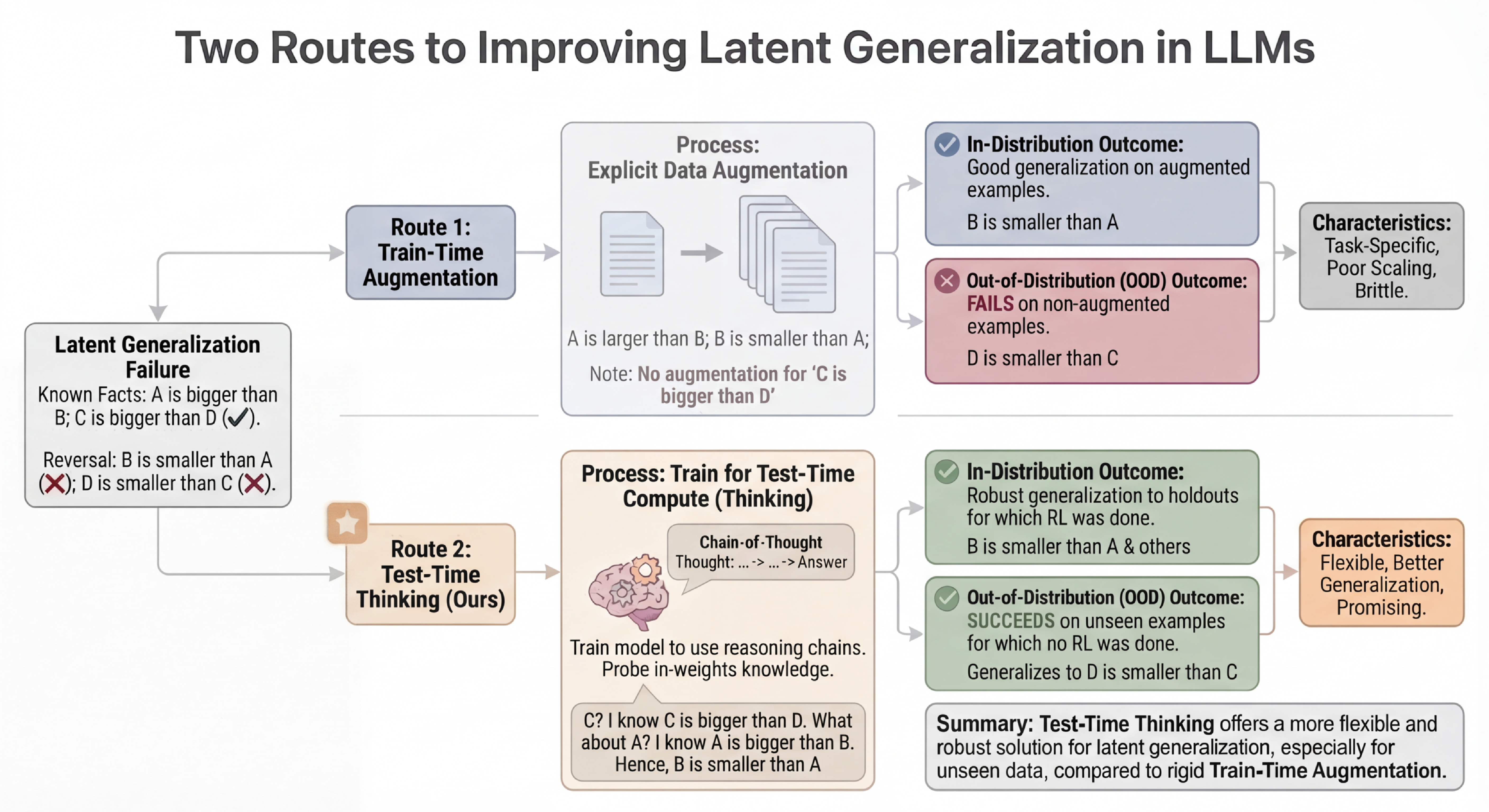
- Latent generalization: Generalization to facts implied by training data but not explicitly stated or seen during training. "We characterize this limitation as a deficit in latent generalization, of which the reversal curse is one example."
- Leakage prevention: Methods to ensure that held-out information does not appear in training signals or thought traces. "Leakage prevention in thinking models"
- Out-of-distribution (OOD) latent generalization: Generalization to new structures or domains not represented during augmentation or RL phases. "We now evaluate out-of-distribution (OOD) latent generalization."
- Parametric knowledge: Information stored within a model’s parameters rather than provided in the prompt at inference time. "when generating responses exclusively from parametric knowledge."
- Pass@N: The probability that at least one of N independent generations exactly matches the correct answer or set. "Pass@N: The rate at which the model's predicted set exactly matches within independent attempts."
- Primary Reference Inclusion: A binary metric indicating whether the specific held-out target (e.g., a reversal or syllogism) appears in the output. "Primary Reference Inclusion: A binary indicator of whether the specific completion targeting the held-out condition (e.g., a specific reversal or syllogism) is present in the model's output."
- REINFORCE algorithm: A policy gradient method for reinforcement learning that updates parameters based on sampled rewards. "The policy is updated using a variant of the REINFORCE algorithm"
- Reasoning bootstrapping: Initial training to induce desired reasoning behaviors using curated traces before RL. "Reasoning (Ours): Initial SFT during the knowledge acquisition phase, followed by reasoning bootstrapping and RL,"
- Reversal Curse: The phenomenon where models fail to invert known associations (e.g., from description-to-name) learned in the forward direction. "We now present the results on the Reversal Curse dataset \citep{berglund2024reversal}."
- Self-probing: A deliberate reasoning behavior where the model queries its own internal knowledge to surface relevant facts. "focus-driven recall, self-probing, generate-and-verify etc."
- Self-verification: The model’s process of checking candidate answers against its internal knowledge for consistency with the prompt. "the brittleness of factual self-verification means thinking models still remain well below the performance of in-context learning for this task."
- Semantic Structure Benchmark: A controlled dataset of categories and relations designed to test reversals, syllogisms, and other latent generalizations. "This dataset is analogous to the strict reversal condition in the Semantic Structure Benchmark:"
- Strict reversals: Reversal cases with no alternative multi-hop path; the model must directly invert a learned association. "On strict reversals, the performance of thinking, although better than augmentation, significantly trails ICL."
- Supervised fine-tuning (SFT): Updating model weights with labeled examples using supervised learning objectives. "Standard supervised fine-tuning (SFT) conducted exclusively during the knowledge acquisition phase."
- Syllogisms: Logical inferences that compose two premises to deduce a conclusion (e.g., A→B and B→C implies A→C). "On some of these holdouts, such as syllogisms, thinking achieves performance comparable to the ICL baseline,"
- Test-time compute: Additional computation during inference (e.g., longer reasoning traces) used to improve performance. "this work studies how models can be taught to use test-time compute, or 'thinking', specifically to improve latent generalization."
- Train-time data augmentation: Expanding or transforming training data to cover more cases and improve generalization before inference. "To improve latent generalization from in-weights knowledge, prior approaches rely on train-time data augmentation,"
- Zero-hop reversals: Reversal queries that cannot use multi-hop reasoning and require direct inversion of a fact. "Pure (0-hop) reversals of knowledge remain difficult even for thinking models,"
Collections
Sign up for free to add this paper to one or more collections.

