- The paper introduces Popularity Quantile Calibration (PQC) to measure alignment by comparing users' historical and recommended popularity distributions.
- It presents SPREE, an inference-time activation steering method that personalizes recommendation outputs without retraining the model.
- Empirical results on multiple datasets show SPREE robustly improves calibration and trade-offs between popularity alignment and prediction utility.
Calibration and Steering for Personalized Popularity Alignment in Recommender Systems
Introduction
Popularity bias is a systematic artifact in contemporary recommender systems, where disproportionately frequent exposure of popular items undermines item and user diversity, exacerbating feedback loops and homogenization. This bias not only reduces visibility for niche content and underrepresented creators but also misaligns recommendations with individual user preferences for popular versus niche items. The paper "Aligning Recommendations with User Popularity Preferences" (2604.01036) performs a comprehensive measurement-theoretic analysis of popularity bias, revealing the inadequacy of prior metrics, and introduces Popularity Quantile Calibration (PQC) for precise user-recommender alignment measurement. Subsequently, the paper contributes SPREE, a lightweight, inference-time mitigation framework for transformer-based sequential recommenders, leveraging activation steering for individual user calibration.
Measurement-Theoretic Critique of Popularity Bias Metrics
Existing approaches for quantifying popularity bias utilize diverse operationalizations, including system-level global averages (e.g., ARP, ALRP), item-level exposure concentration (e.g., entropy, Gini, Herfindahl indices), and user-level history-recommendation mappings (e.g., PopLift, LogPopDiff, User Popularity Deviation (UPD)). However, these metrics entangle distinct underlying notions—such as diversity, fairness, and personalization—and often lack key validity properties. Notably, UPD, which applies Jensen-Shannon divergence on binned popularity histograms, is insensitive to the direction of bias due to the symmetry of the divergence, ignores intra-bin dispersion, and fails to capture nuanced deviations in popularity spread and variance.
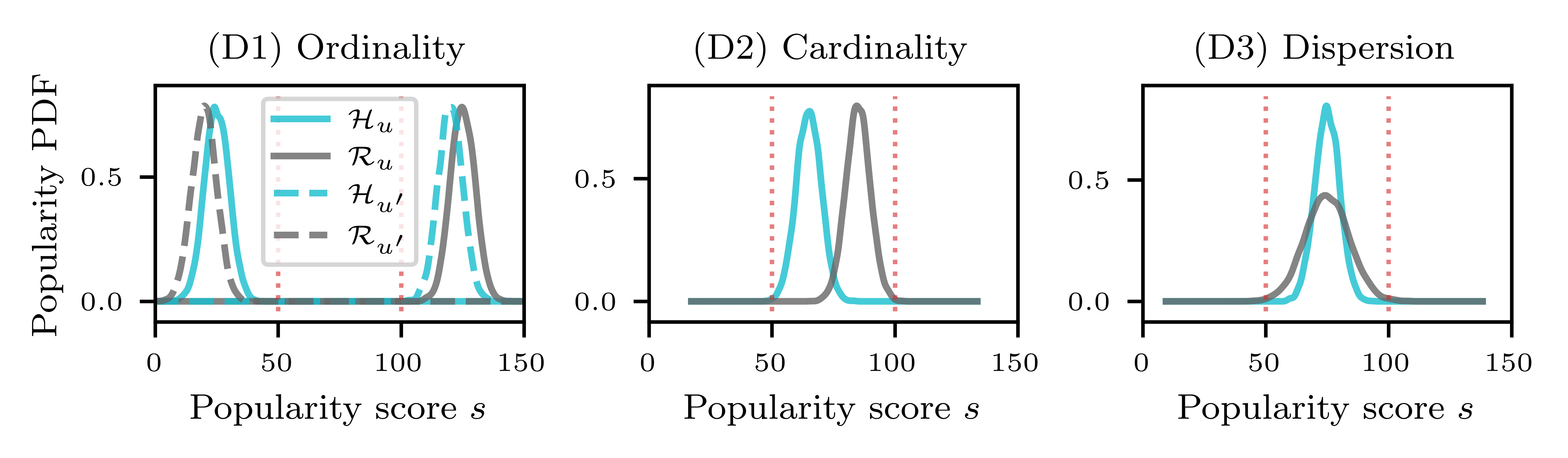
Figure 1: Symmetry and binning issues in UPD obscure true directionality and variance of popularity bias between user histories and recommendations.
A validity-oriented desiderata analysis highlights that prior metrics oftentimes fail essential properties such as ordinality (direction), cardinality (magnitude), dispersion (spread), scale-invariance, and robustness to outliers. This motivates a conceptual shift toward a calibration-oriented framework that directly encodes distributional alignment.
The paper formalizes user popularity preference as the empirical distribution p(s∣u) derived from historical interactions, contrasted with the model-induced recommendation popularity distribution q(s∣u). Rather than reduce these distributions to summary statistics, Popularity Quantile Calibration evaluates the quantile functions and cumulative distribution function (CDF) alignments. For a set of quantiles τj, each user’s popularity calibration curve is constructed by measuring the fraction of the user history below the model’s τj-th popularity quantile. Deviation from the identity line quantifies miscalibration.
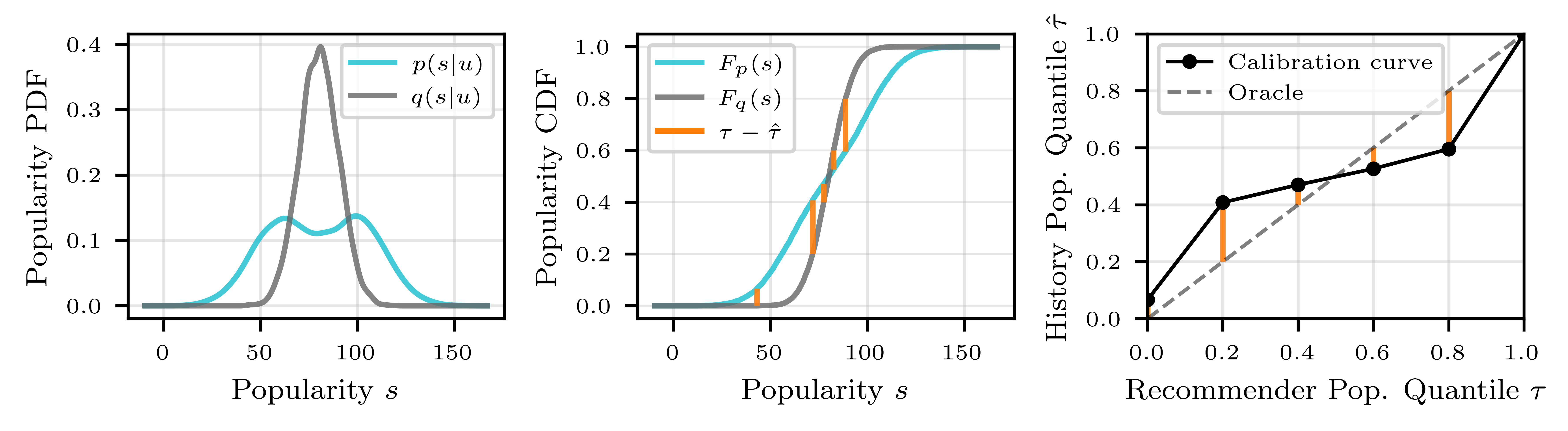
Figure 2: PQC captures user-recommender miscalibration by comparing empirical CDFs across popularity quantiles and constructing calibration error curves.
Popularity Calibration Error (PCE), defined as the mean squared deviation over quantile levels, provides a scalar, robust, scale-invariant measure of popularity alignment. Critically, PQC and PCE satisfy all validity desiderata except global ordinality (for PCE), and can be used for both diagnostic visualization and model selection.
SPREE: Inference-Time Activation Steering for Alignment
SPREE (Steering PopulaRity toward human prEferEnces) is an inference-time mitigation framework designed for transformer-based sequential recommenders. Building on evidence that popularity is linearly encoded in the transformer’s activation space (as revealed by high linear probe accuracy; see Figure 3), SPREE constructs a ‘popularity steering vector’ by contrasting mean activations from artificial user sequences representing the heads (most popular) and the long tail (least popular) of the popularity spectrum.
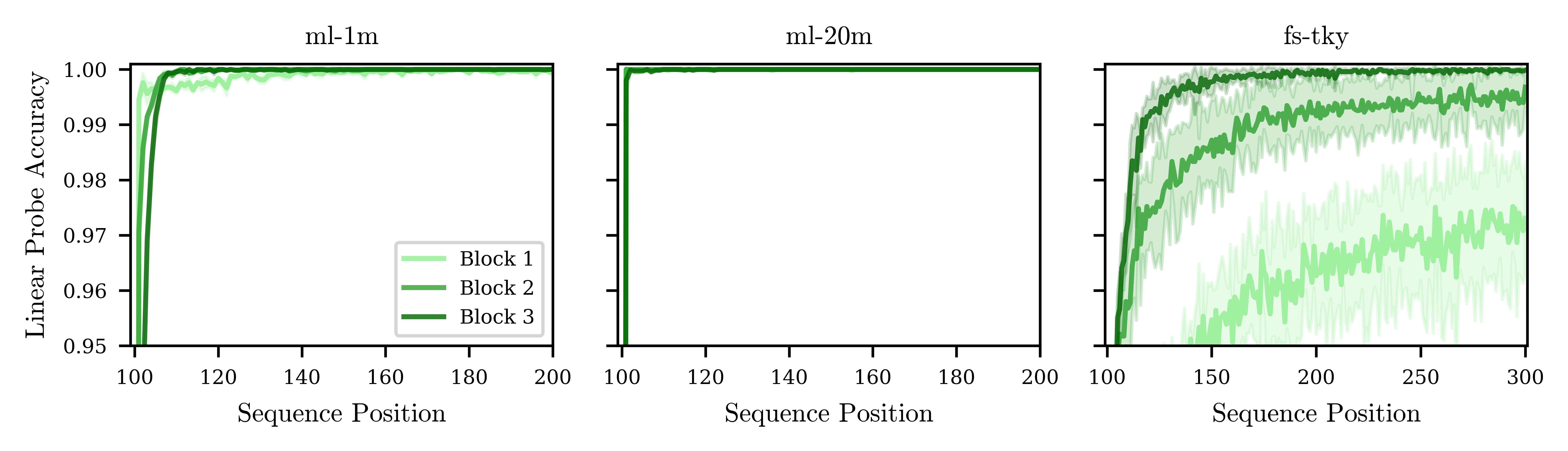
Figure 3: Linear probes confirm that popularity is linearly separable in the activation space at the final transformer layer and sequence position.
The key advancement of SPREE is its adaptive, user-specific steering magnitude. Instead of applying a global shift, SPREE predicts a personalized bias estimator f^ (trained via Lasso regression on validation activations) that determines per-user steering strength and direction. At inference, the steering vector is added to the activations at the transformer block and position with maximal popularity encoding, directly manipulating model behavior without retraining.
Empirical Evaluation and Results
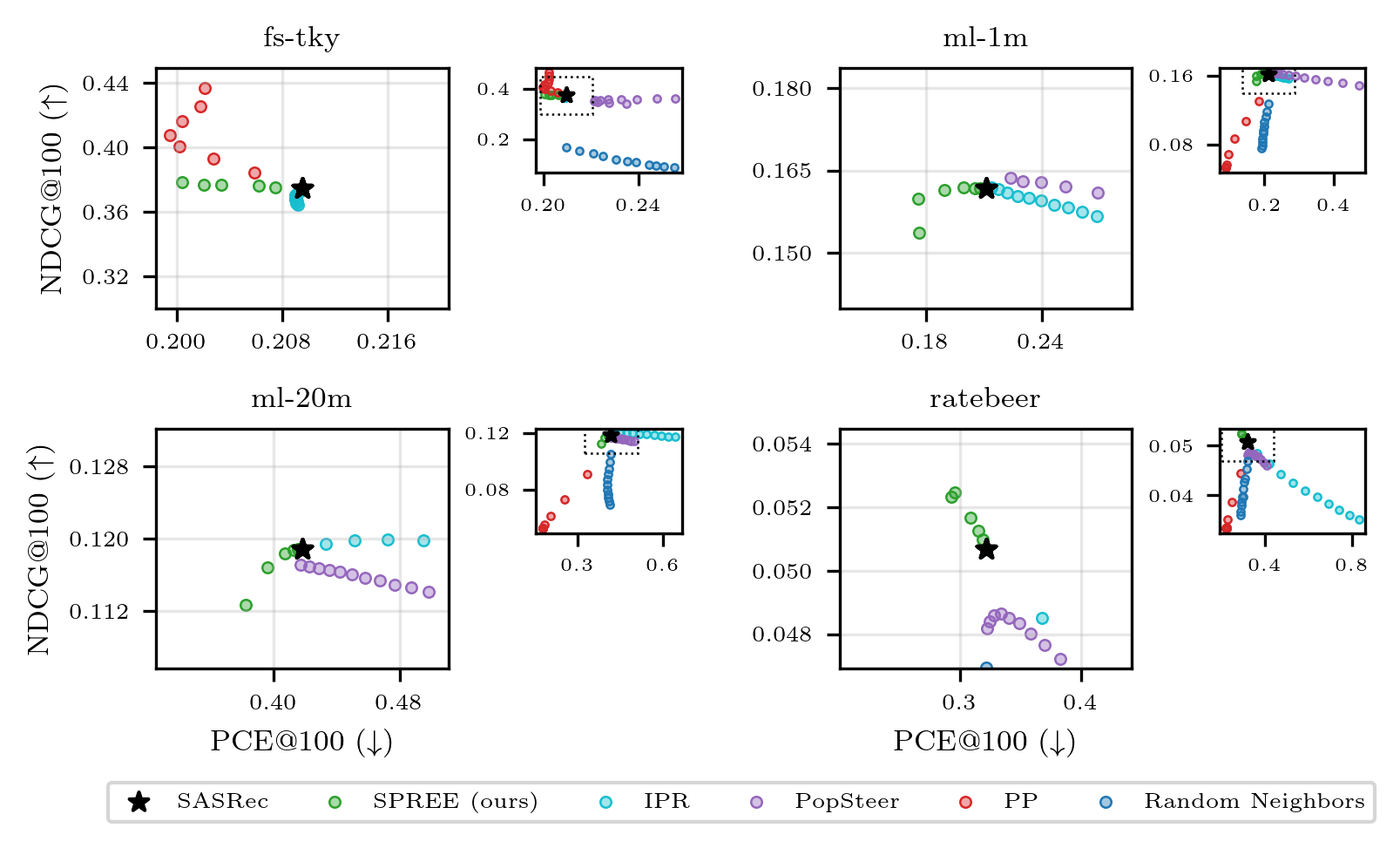
SPREE is evaluated on four benchmark datasets (Foursquare Tokyo, MovieLens-1M/20M, RateBeer) with comparison to a range of inference-time baselines: Inverse Popularity Ranking (IPR), Personalized Popularity (PP), PopSteer (steering via autoencoder neuron interventions), and random neighbors.
The alignment-performance Pareto analysis (Figure 4) demonstrates that:
Detailed analysis of average calibration curves (Figure 5) confirms that SPREE uniquely centers recommendations at the ideal calibration diagonal, systematically reducing both under- and over-recommendation of popular items per user, while other methods shift the distribution uniformly and exacerbate either over- or under-popularity.
Figure 5: Average calibration curves illustrate that SPREE (green) brings model-user popularity alignment close to parity, unlike other baselines.
Implications and Future Directions
The results have both practical and theoretical implications. In operational settings, PQC and SPREE enable platforms to expose and remediate individually misaligned recommendations, promoting longitudinal user engagement, reputation, and regulatory compliance. Activation steering, as instantiated in SPREE, establishes a template for addressing other dimensions of alignment (e.g., genre diversity, minority exposure, fairness) and can be further tailored to control parts of the popularity distribution beyond central tendency (e.g., specific quantile targeting).
Theoretically, the findings suggest that high-level behavioral properties—such as user-specific popularity bias—are not only measurable with rigor, but also mechanistically encoded in deep model representations in line with the linear representation hypothesis. Advances in interpretability and mechanistic probing will likely expand the repertoire of steerable concepts. Limitations remain in the granularity obtainable due to embedding space structure and retrieval via nearest neighbors, highlighting avenues for research in structured and disentangled representations.
Conclusion
"Aligning Recommendations with User Popularity Preferences" provides a rigorous measurement-theoretic formalism for popularity bias in recommenders through PQC and demonstrates, via SPREE, that activation steering can align sequential recommenders’ outputs to user-specific preferences at inference time, outperforming both global and history-based baselines. These contributions lay a foundation for precise, flexible post-hoc alignment interventions in large-scale, real-world systems and motivate further adaptation to additional fairness and alignment axes in machine learning.