Uncertainty-Aware Variational Reward Factorization via Probabilistic Preference Bases for LLM Personalization
Published 1 Apr 2026 in cs.CL | (2604.00997v1)
Abstract: Reward factorization personalizes LLMs by decomposing rewards into shared basis functions and user-specific weights. Yet, existing methods estimate user weights from scarce data in isolation and as deterministic points, leading to inaccurate and unreliable inference. We introduce Variational Reward Factorization (VRF), an uncertainty-aware framework that represents each user's preferences as a variational distribution in a shared preference space. VRF infers user distributions via a variational encoder, derives weights through Wasserstein distance matching with shared probabilistic bases, and downweights uncertain estimates through a variance-attenuated loss. On three benchmarks, VRF outperforms all baselines across seen and unseen users, few-shot scenarios, and varying uncertainty levels, with gains extending to downstream alignment.
The paper introduces a novel VRF framework that models user preferences as Gaussian distributions to capture uncertainty.
It employs Wasserstein matching and a variance-attenuated Bradley-Terry loss to achieve robust, scalable LLM adaptation even with sparse data.
Experimental results demonstrate superior pairwise accuracy and rapid few-shot adaptation compared to traditional reward modeling approaches.
Uncertainty-Aware Variational Reward Factorization: Probabilistic Preference Bases for LLM Personalization
Problem Formulation and Motivation
Recent LLM alignment strategies predominantly optimize for a shared, user-agnostic objective, often via reward modeling from human feedback. This paradigm is fundamentally limited in scenarios with diverse, conflicting, or sparse user preferences. Reward factorization frameworks, where scalar rewards are decomposed into shared basis functions and user-specific weights, provide a formal foundation for personalized reward modeling. However, current approaches suffer from two key pathologies: the isolated estimation of weights wu for each user and the reliance on deterministic point estimates rather than distributions, resulting in poor generalization and uncertainty quantification, particularly under data scarcity (C1) and inherent preference ambiguity (C2).
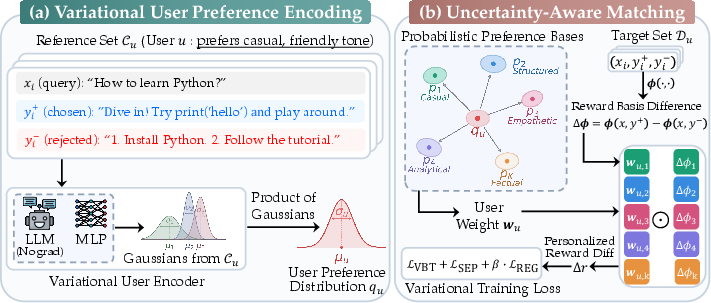
The VRF framework proposed in "Uncertainty-Aware Variational Reward Factorization via Probabilistic Preference Bases for LMM Personalization" (2604.00997) addresses these failures by embedding both users and preference bases as distributions in a learned preference latent space.
Figure 1: User preferences may be consistent or diverse; modeling this variance is critical to robust personalization.
VRF encodes each user’s preference as a Gaussian distribution qu=N(μu,diag(σu2)), computed from a small reference set of annotated preference pairs per user. Individual pairwise representations are mapped through a two-layer MLP to per-pair Gaussians, then aggregated via product-of-Gaussians (PoG) for both data-efficient and uncertainty-aware estimation. This choice ensures that more confident pairwise inferences have proportionally greater influence on the final user embedding.
Probabilistic Preference Bases and Wasserstein Matching
Shared preference bases {pk}k=1K are modeled as parametric Gaussians in the latent space. The derivation of user weights is formalized through softmax over negative squared 2-Wasserstein distances between the user embedding and each basis:
This matching incorporates both the location and uncertainty of the preference distribution, resulting in soft, uncertainty-aware assignments.
Figure 2: Schematic of VRF; both user and basis representations are variational Gaussians allowing structured uncertainty modeling and probabilistic assignment.
Variance-Attenuated Training
The loss function generalizes the Bradley-Terry formulation to the distributional setting. For a user-specific pairwise comparison, the reward difference is treated as a Gaussian whose mean and variance are derived from the probabilistic weights and basis outputs. Training leverages a variance-attenuated Bradley-Terry loss:
LVBT=−E[logσ(1+πσΔ2/8μΔ)]
where high variance (uncertain preferences) attenuates gradient signal, mitigating unreliable updates from ambiguous or scarce data.
Further, the learning objective incorporates a separation loss among bases to enforce diversity, and a KL regularization relative to a mixture-of-Gaussians prior, maintaining both expressivity and identifiability in the latent space.
Experimental Analysis
VRF is evaluated on three benchmarks: PersonalLLM (synthetic user preferences with controllable diversity), TL;DR (user-annotated text summary preferences), and PRISM (real-world dialog data with high demographic coverage). The evaluation protocol distinguishes performance on seen and unseen users with few-shot adaptation regimes.
Main Results
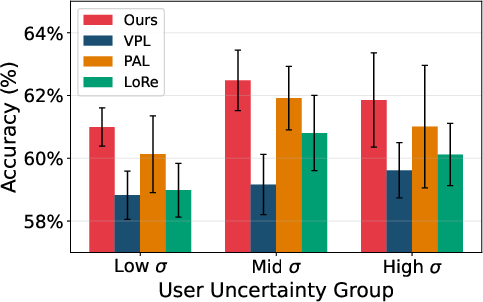
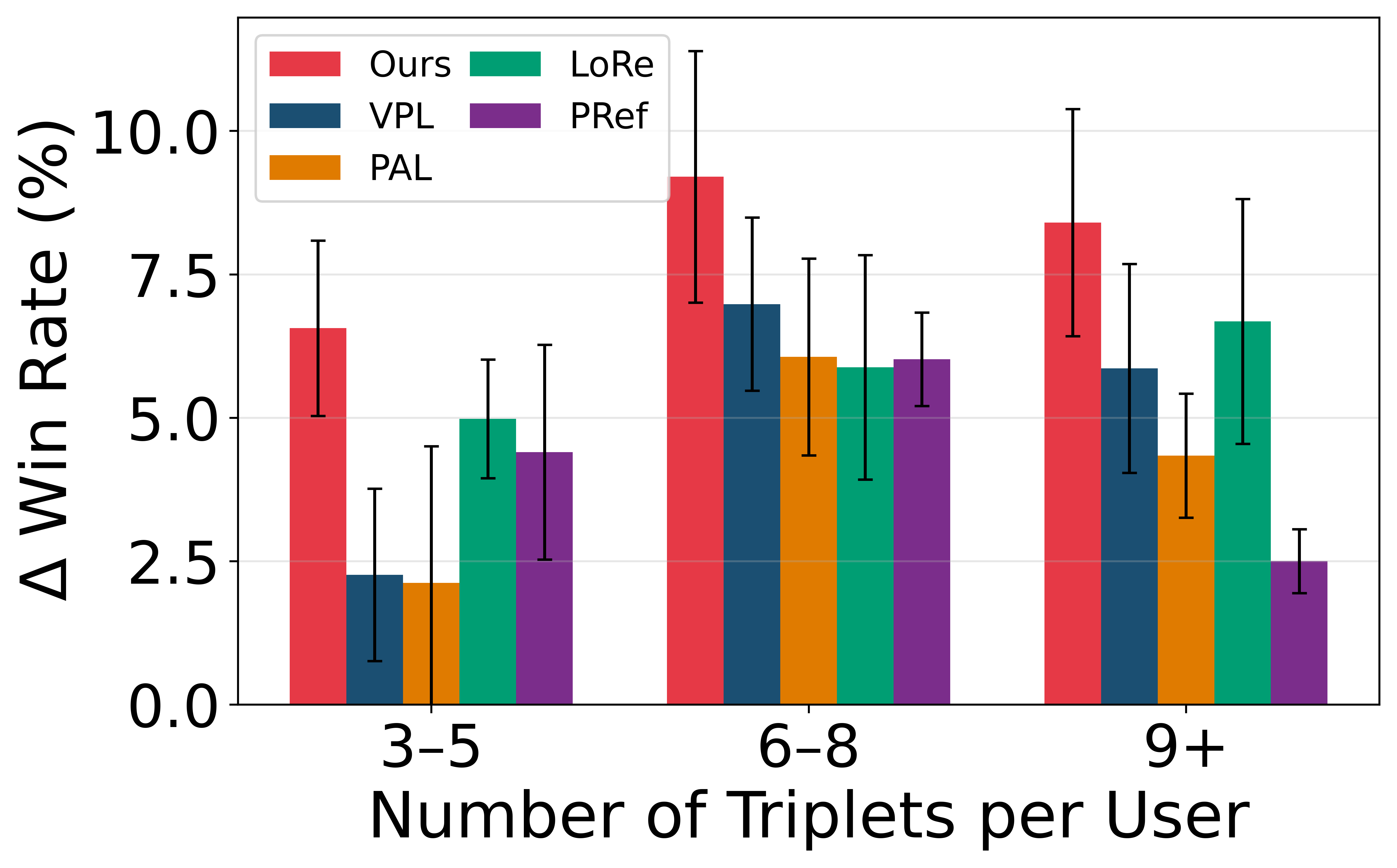
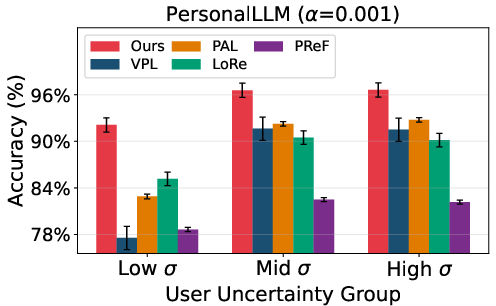
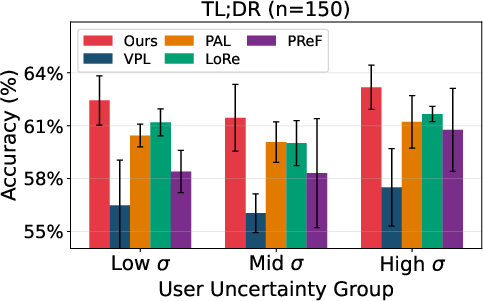
Across all datasets, VRF achieves the highest pairwise preference accuracies for both seen and unseen users, consistently outperforming both non-personalized (BT) and personalized (PAL, LoRe, PReF, VPL) baselines. Crucially, as user preference diversity or uncertainty increases, the VRF advantage amplifies, indicating scalability and robustness.
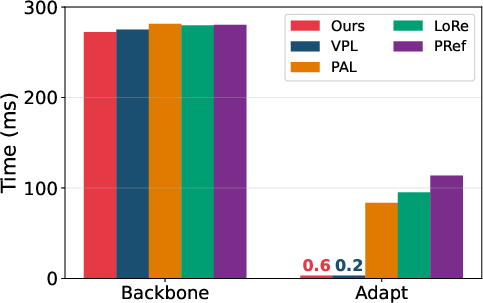
Figure 3: On PRISM, VRF maintains robust accuracy across user uncertainty bins and achieves minimal adaptation latency compared to gradient-based personalized reward methods.
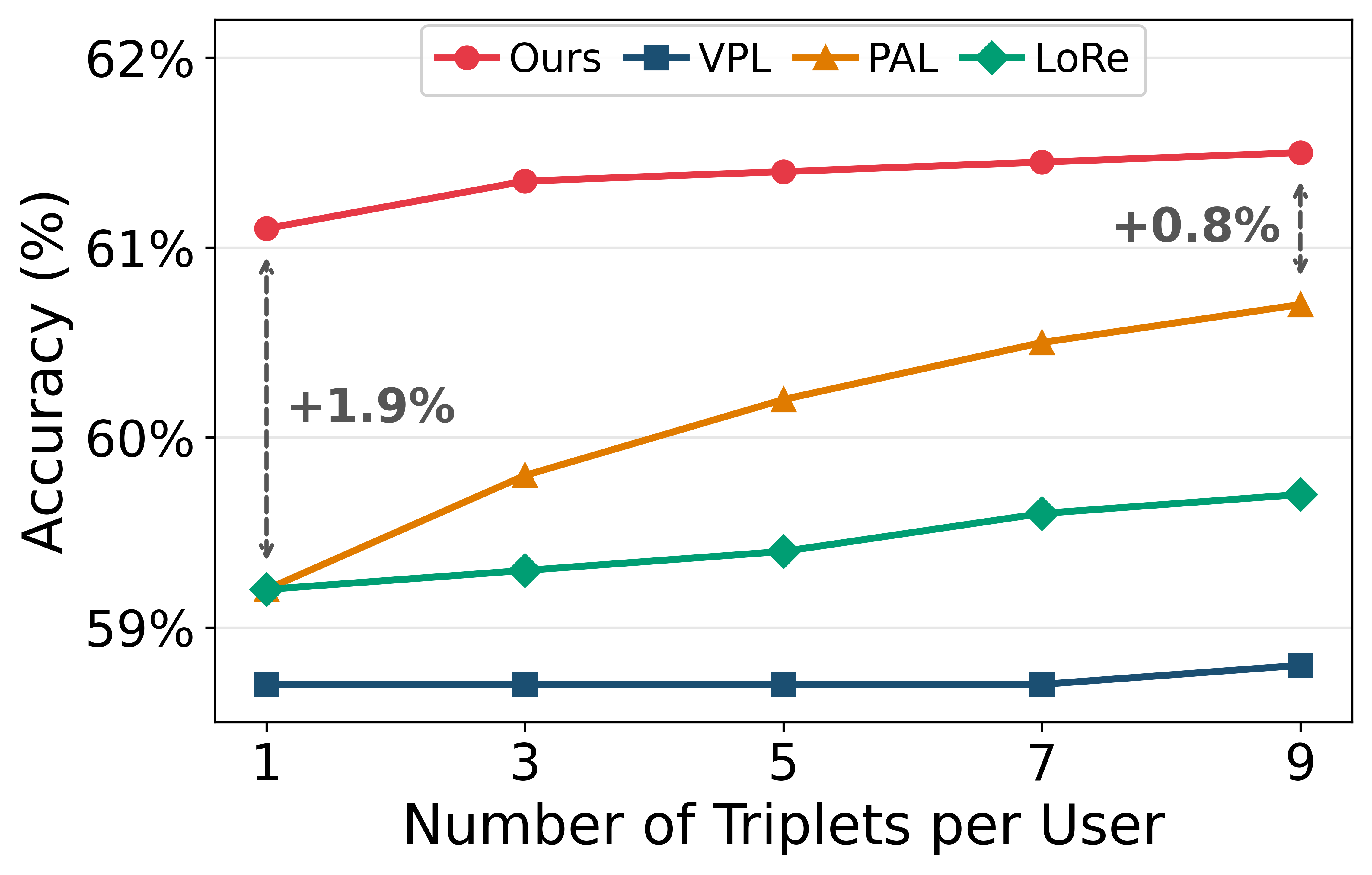
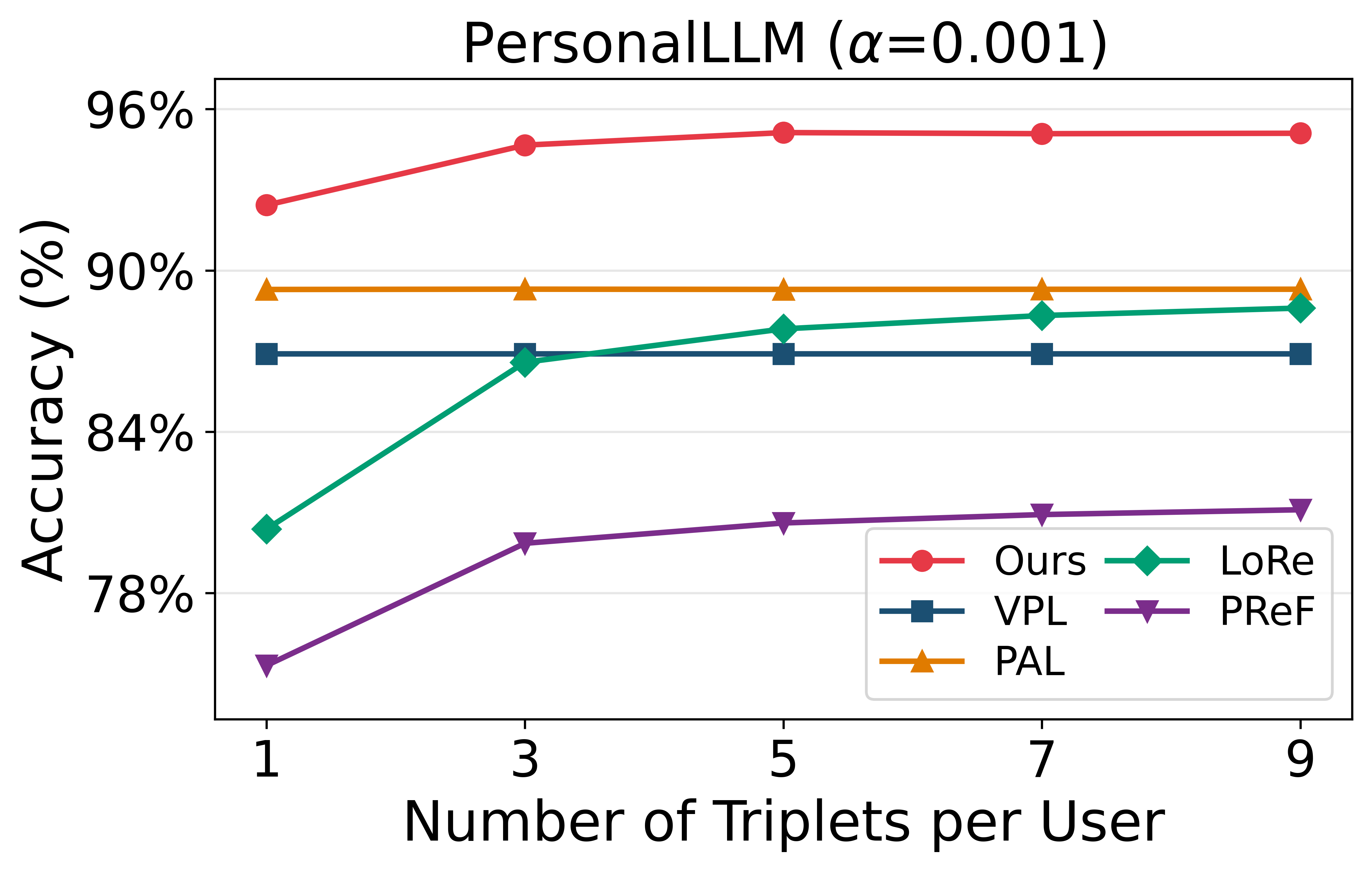
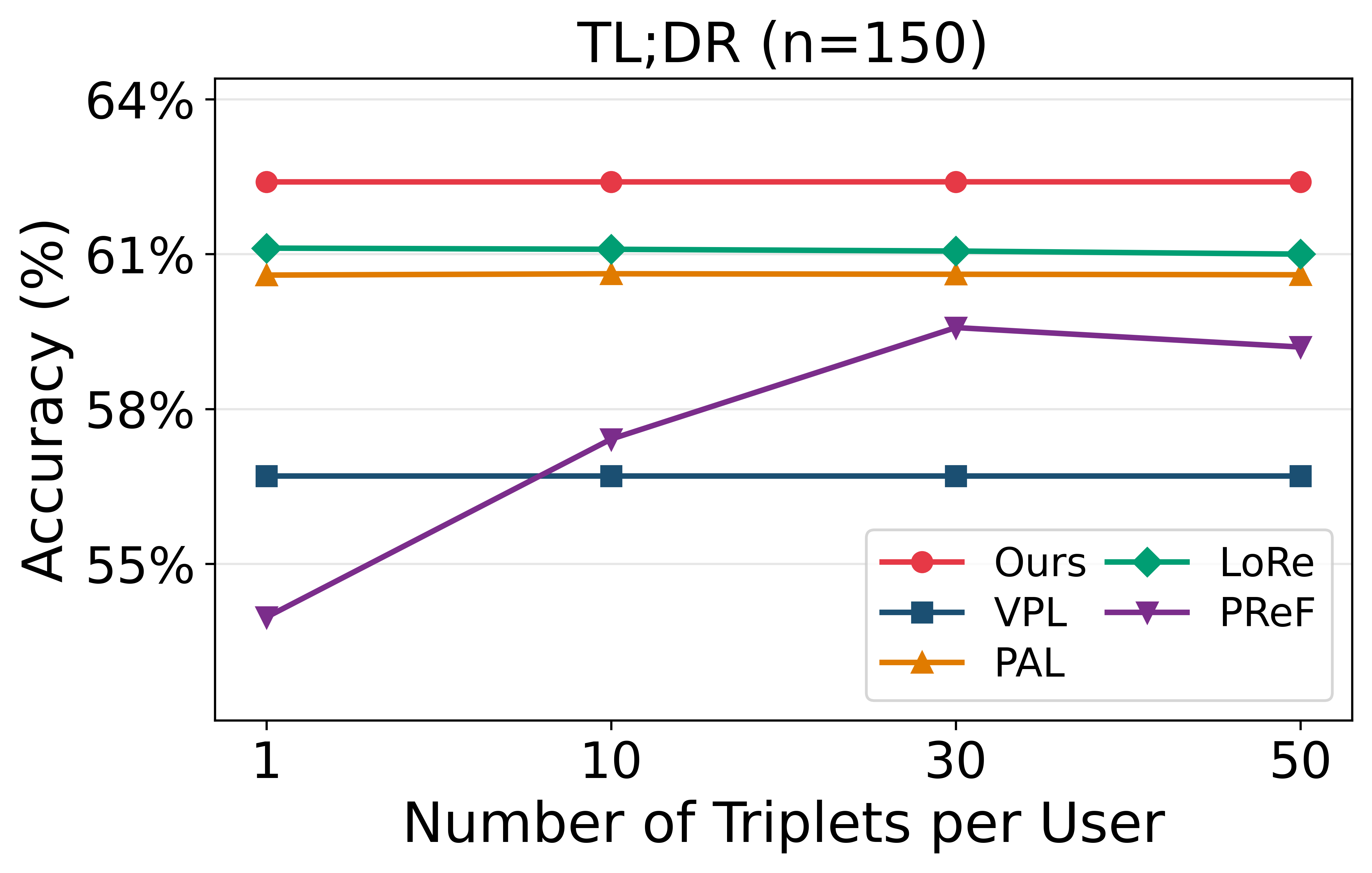
Few-Shot and Uncertainty Ablation
VRF achieves optimal adaptation accuracy with as little as a single reference triplet per user and shows minimal degradation as user uncertainty increases. The probabilistic bases enable effective generalization to users with limited or ambiguous historical data, with adaptation performed in a single forward pass.
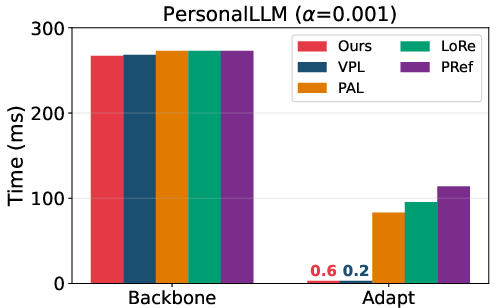
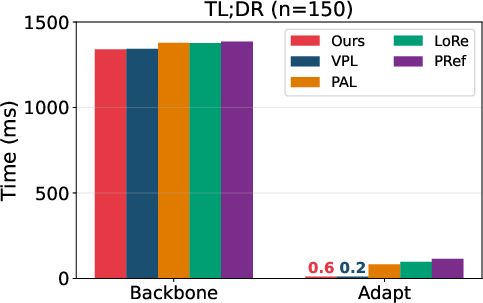
Efficiency and Scalability
Inference-time user adaptation in VRF is approximately three orders of magnitude faster than gradient-based methods for unseen users (e.g., PAL, LoRe, PReF), supporting practical deployment at scale.
Figure 4: VRF’s adaptation time per user is negligible compared to alternatives, supporting massive personalization.
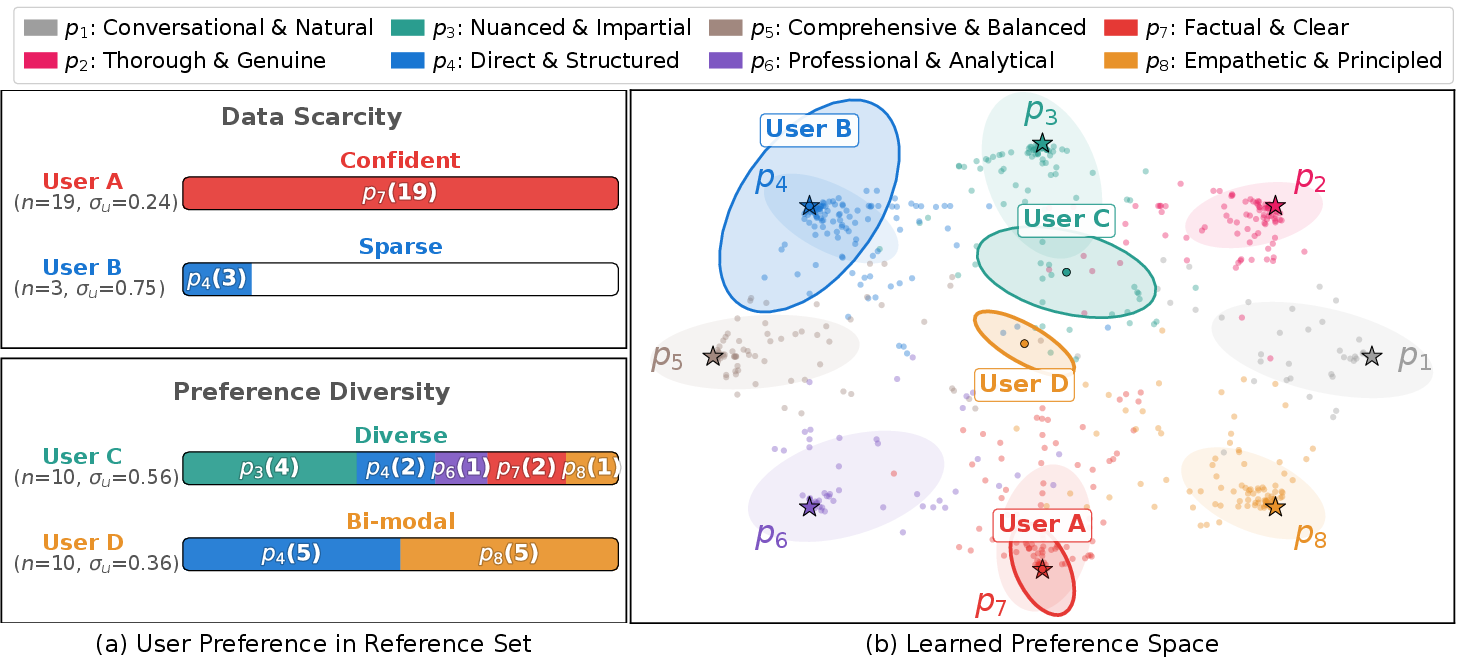
Preference Space Visualization and Case Studies
Visualization of learned preference space confirms that VRF captures both the mode (preference directionality) and dispersion (confidence/uncertainty) of user interests. Users with scarce data or internally diverse signals manifest as wider Gaussian covariances, while concentrated, well-observed users are tightly clustered near specific preference bases.
Figure 5: Case studies show VRF’s learned user distributions span a structured preference latent space with interpretable basis semantics and uncertainty quantification.
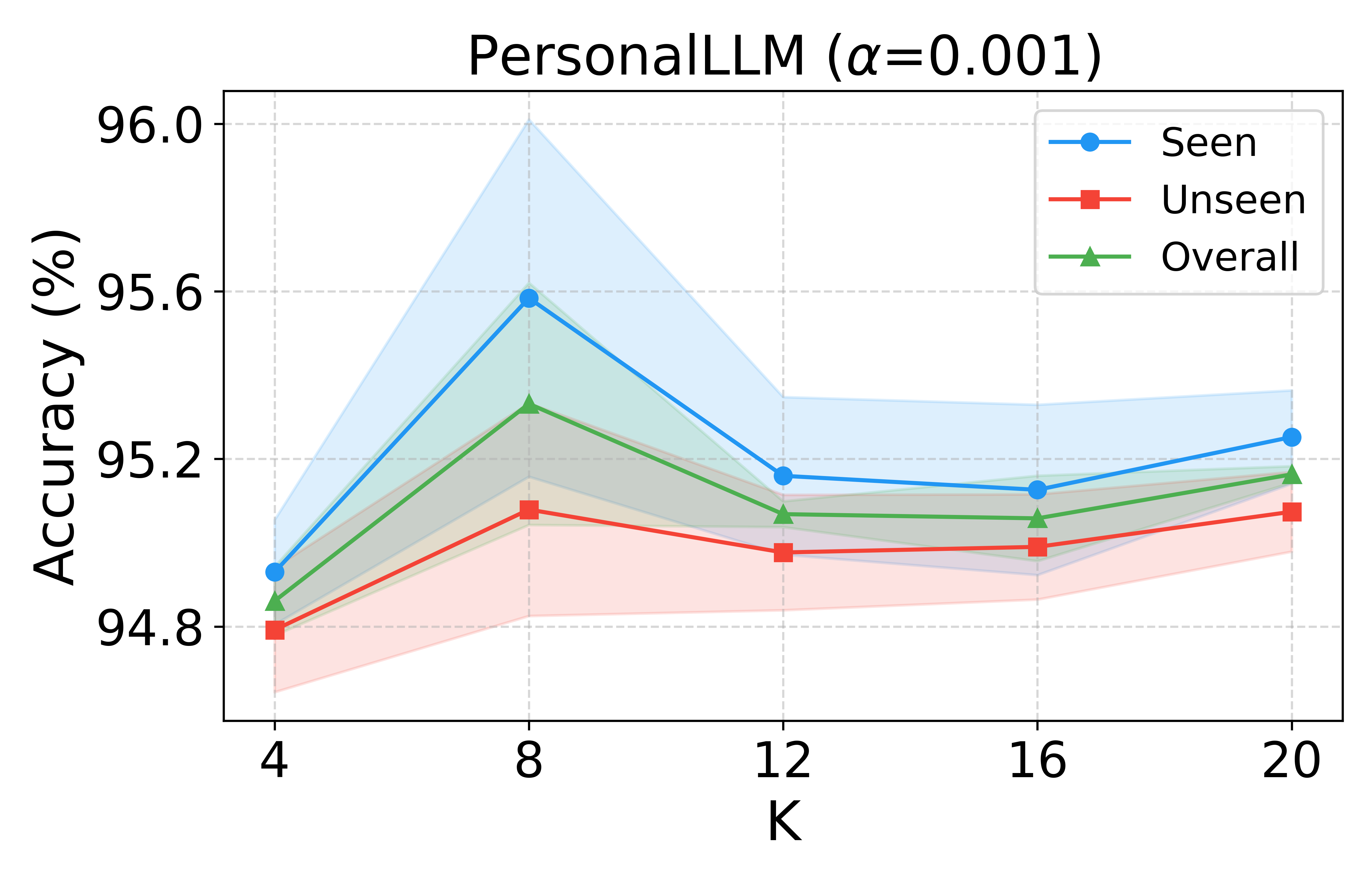
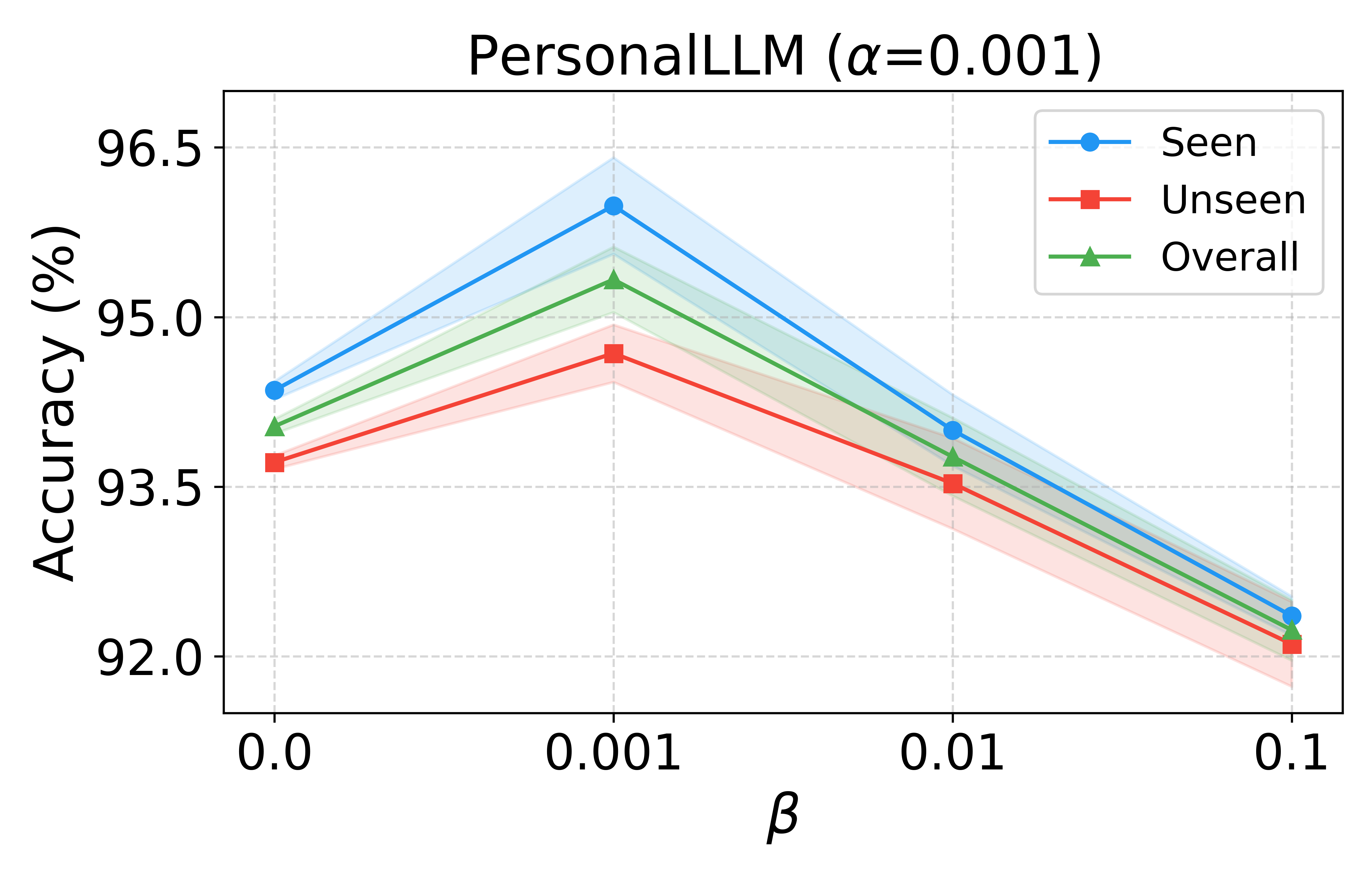
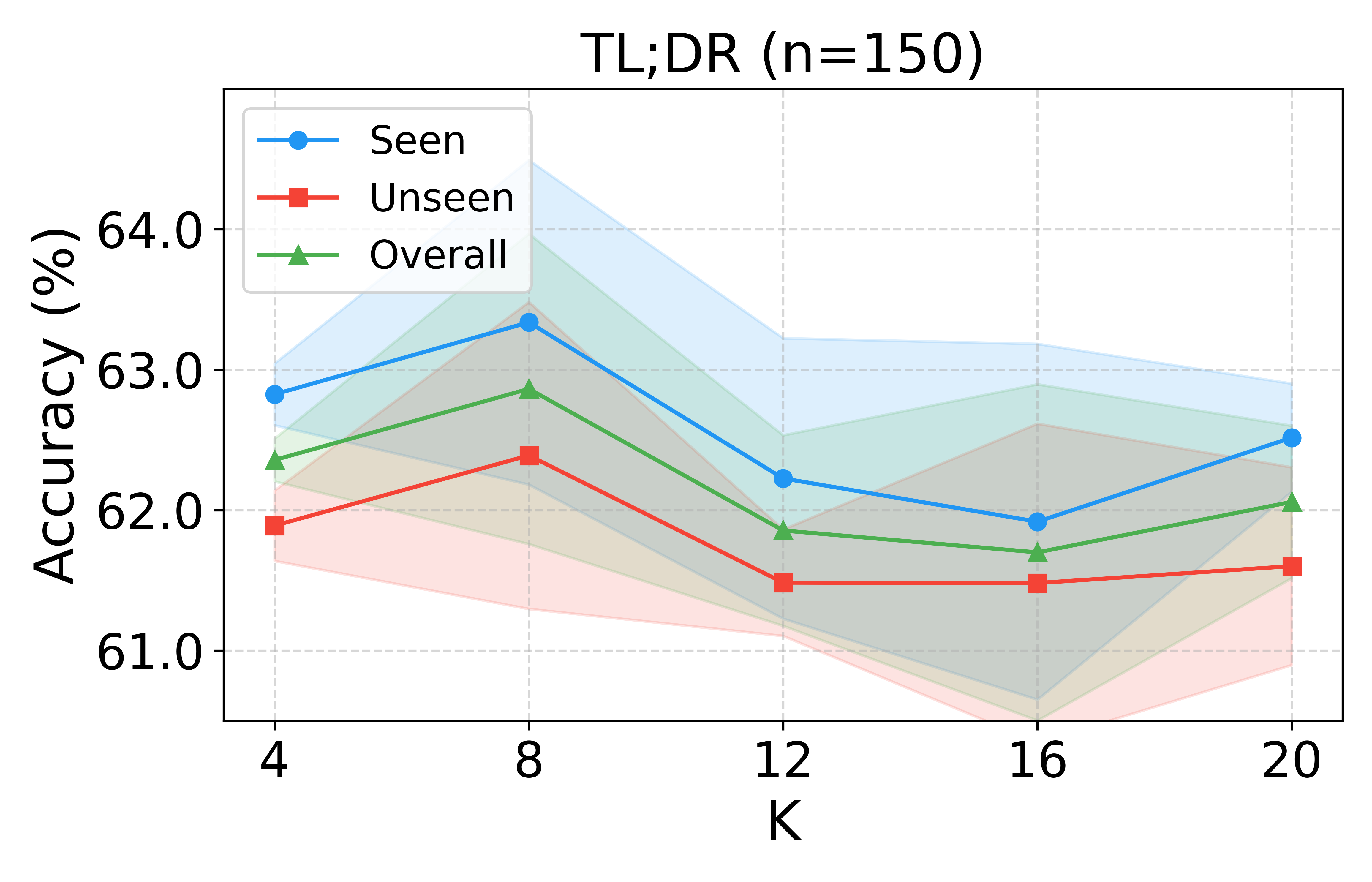
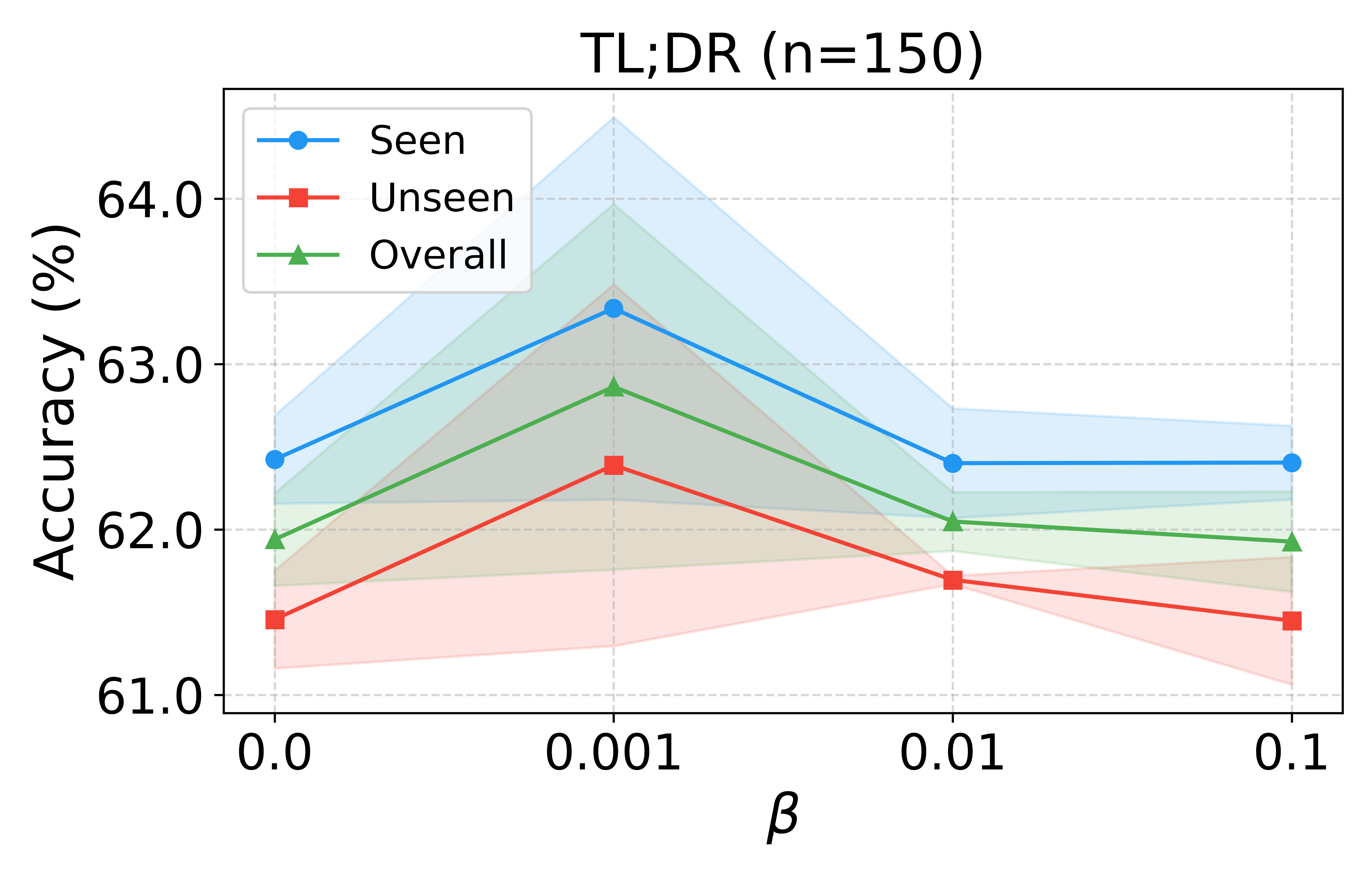
Hyperparameter and Ablation Analysis
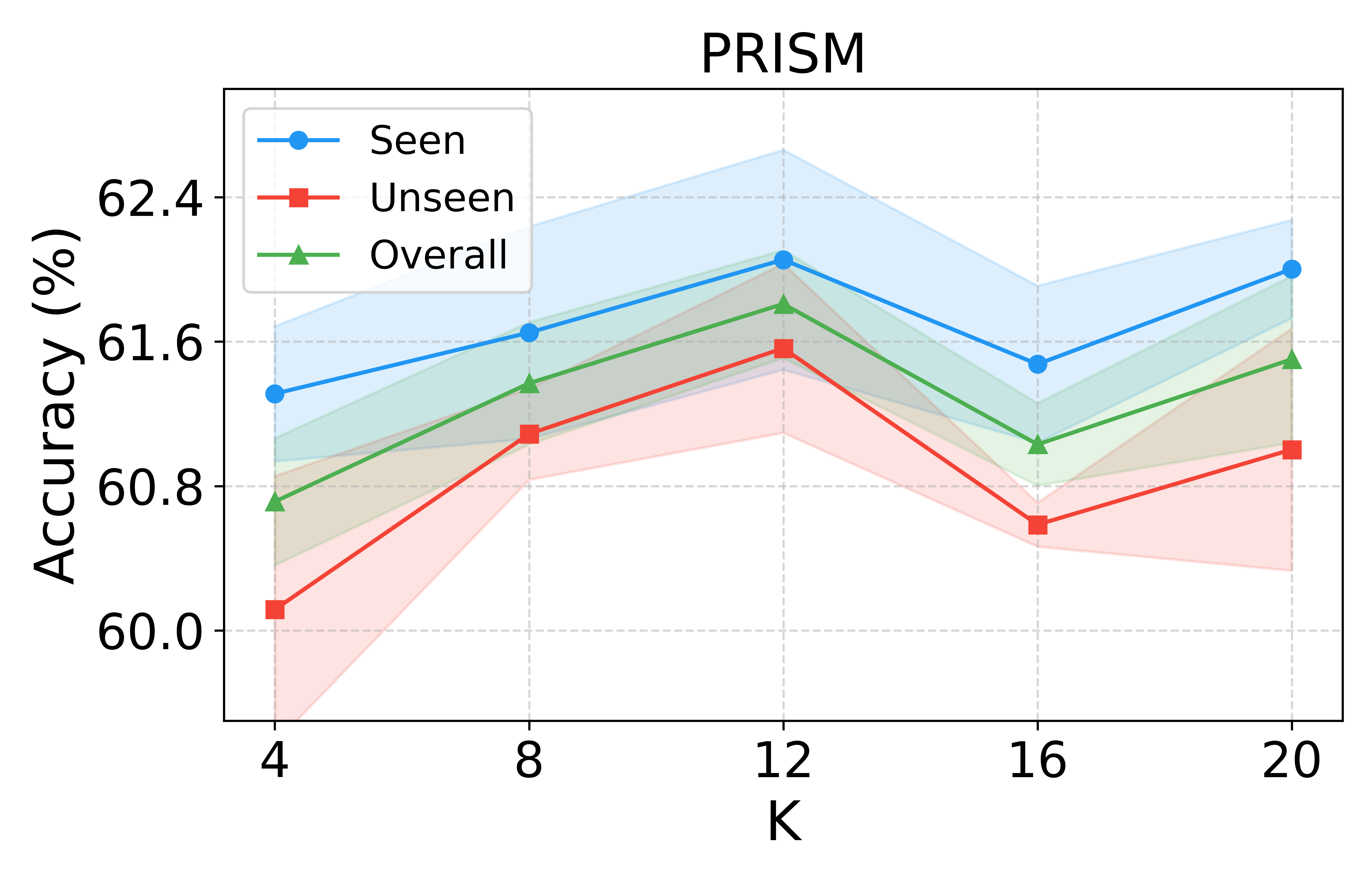
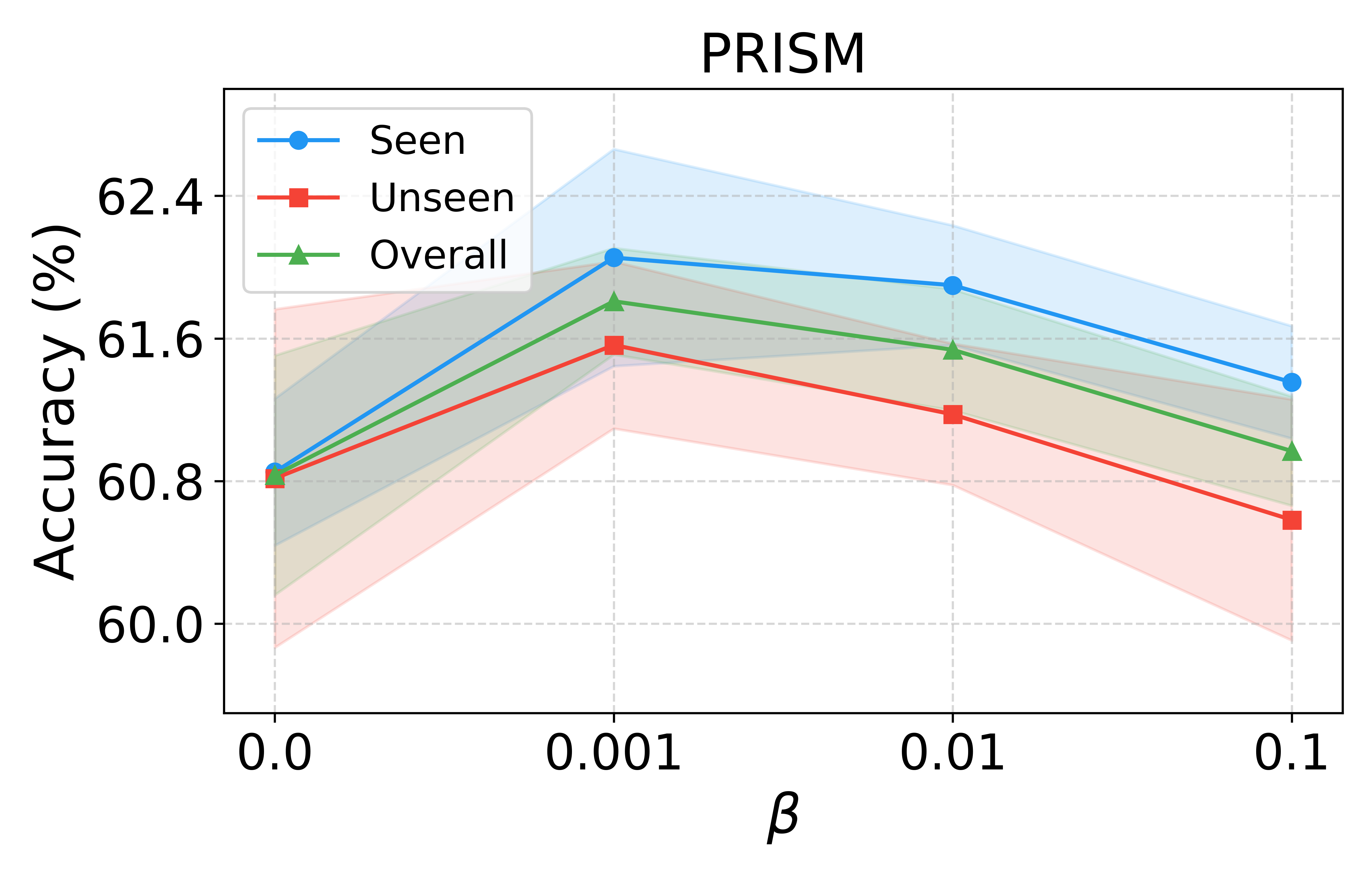
Performance saturates for modest numbers of bases (K∈[8,12]), and regularization via KL to a mixture prior is essential for generalization. Ablations demonstrate that removing the variance-attenuated loss, basis separation, or the MoG prior yield statistically significant accuracy degradation, empirically validating each architectural ingredient.
Figure 6: Sensitivity to number of bases (K) and regularization strength (β) confirms VRF’s robustness and stability.
Implications and Future Outlook
The VRF framework integrates structured uncertainty into the reward factorization paradigm, mitigating core deficiencies of deterministic user modeling. By leveraging shared preference bases and uncertainty-aware distributional representations, VRF enables scalable, data-efficient, and robust LLM personalization. This design supports efficient few-shot and amortized adaptation, aligning with practical system-level constraints for interactive user-facing LLMs.
Potential directions include the expansion to non-i.i.d. adaptation (e.g., temporally evolving preferences), contextually adaptive basis sets for multi-domain personalization, and deeper integration with policy learning loops (RLHF and beyond). Moreover, the probabilistic construction suggests natural extensions for meta-learning and active learning regimes targeting optimal information acquisition for user modeling.
Conclusion
VRF provides a principled, uncertainty-aware solution for personalized reward modeling in LLMs. By representing both users and preference bases as distributions and employing Wasserstein-based matching and variance-attenuated training, VRF demonstrates superior empirical performance, sample efficiency, and scalability compared to contemporary reward factorization baselines. Its formal handling of uncertainty sets a standard for further theoretical and practical advances in LLM personalization (2604.00997).
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.