- The paper demonstrates that Mamba-based state-space models achieve similar accuracy (~2% CER) to Transformers while significantly reducing latency.
- Efficient benchmarking on line and paragraph-level OCR reveals that SSMs scale linearly, overcoming Transformer's quadratic memory growth.
- Diverse decoding strategies (CTC, AR, NAR) and optimized tokenization highlight practical trade-offs for large-scale cultural heritage digitization.
Introduction
The paper "A Benchmark of State-Space Models vs. Transformers and BiLSTM-based Models for Historical Newspaper OCR" (2604.00725) presents a systematic comparison between State-Space Models (SSMs), particularly the Mamba architecture, and established Transformer/BiLSTM-based models for historical newspaper OCR. The motivation arises from the substantial inference and memory bottlenecks imposed by Transformer-based recognizers when scaling to long sequences typical in paragraph-level OCR tasks for heritage documents, along with the need for efficient, reproducible benchmarks supporting large-scale cultural heritage digitization.
Methods and Architectures
The study introduces the first Mamba-based OCR architecture, which combines a CNN visual encoder with a bidirectional Mamba context layer, followed by distinct decoding modules supporting CTC, autoregressive (AR), and non-autoregressive (NAR) strategies.
Figure 1: Mamba-based OCR architecture with a shared visual encoder, bidirectional Mamba context block, and three decoder instantiations: AR, NAR, and CTC.
All models are benchmarked under unified conditions using the BnL historical newspaper dataset, encompassing both line-level and paragraph-level granularity for two scripts (Antiqua, Fraktur) with extensive gold annotation. Transformer baselines include VAN (CTC), DAN (AR), and DANIEL (subword BPE, AR), with further comparison against off-the-shelf OCR engines (PERO-OCR, Tesseract, TrOCR, Gemini). Neural models are tested using consistent tokenization (character-level unless otherwise specified), data augmentation, and training protocols.
Experimental Evaluation
Recognition Quality: Lines and Paragraphs
Neural models fine-tuned on BnL data achieve low CER (∼2%) on line-level recognition. For Antiqua, Mamba-AR matches DAN at 1.83% CER, while VAN provides optimal practical throughput. In Fraktur, character-level models (VAN, Mamba-NAR) edge out others, with DANIEL’s CER rising substantially, indicating subword vocabulary mismatch with historical typesetting.
Inference time is a significant differentiator: AR Transformer models (DAN) exhibit elevated latency (156.5 ms/line), while Mamba-AR is 2.9× faster (53.3 ms/line) at equivalent CER. CTC-based VAN and Mamba models are dominant in throughput (6–13 ms/line, >120 img/s). Off-the-shelf TrOCR and Gemini models, even with fine-tuning, are inferior in both accuracy and efficiency relative to specialized approaches.
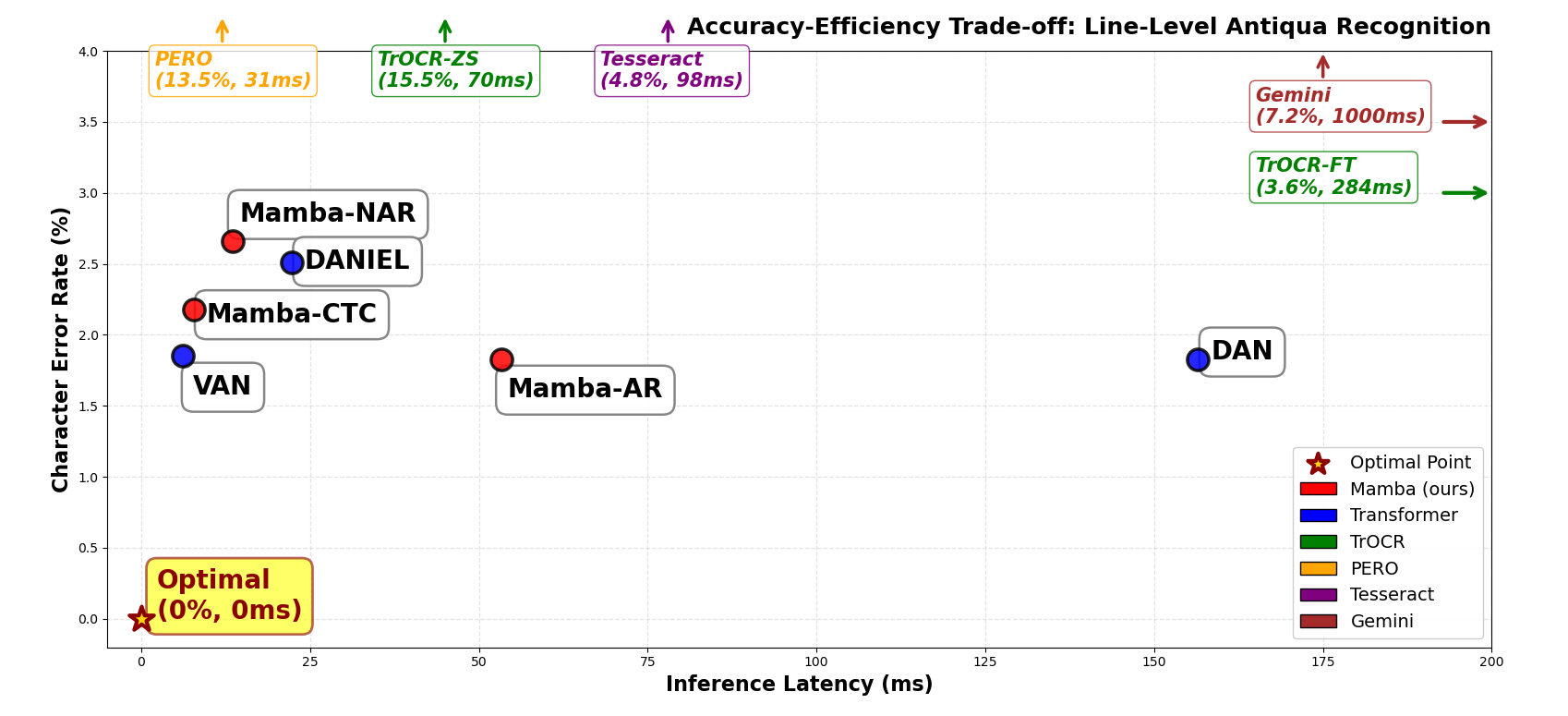
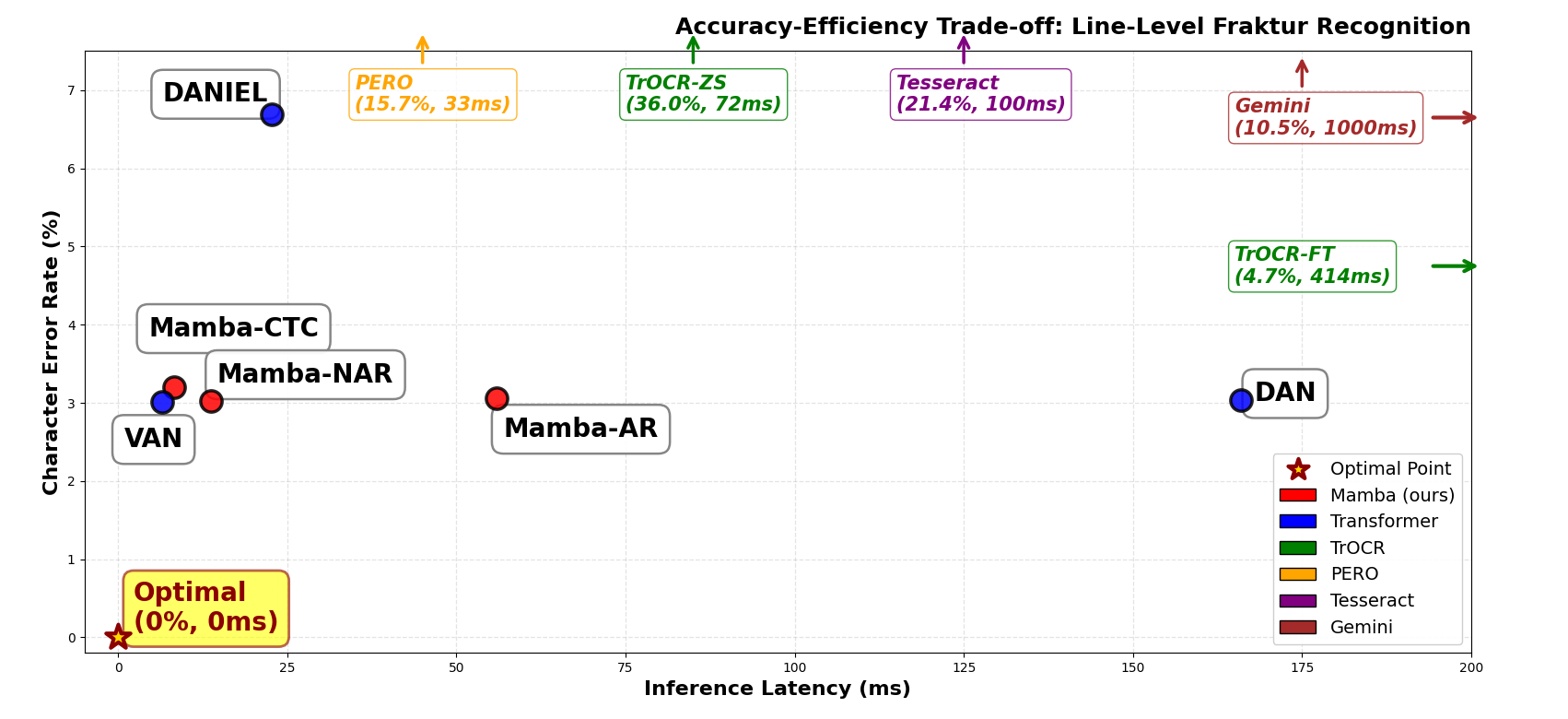
Figure 2: Accuracy-latency Pareto frontier for line-level recognition: Mamba-AR achieves DAN-level CER with 2.9× lower latency; VAN and Mamba-NAR provide the optimum speed-accuracy trade-off in Fraktur.
On paragraph-level OCR (1–10 lines, ≤1000 characters), Mamba-AR yields 6.07% CER versus DAN’s 5.24%, but with a 2.05× speedup (195.6 ms/image vs 401.2 ms/image). VAN offers compelling production throughput (17.2 ms/image, 58.1 img/s) at 6.42% CER. DANIEL is more efficient than DAN by virtue of BPE, but is vulnerable to CER degradation on non-Latin scripts.
Computational Efficiency and Memory Scaling
Empirical measurements confirm theoretical asymptotics: Mamba-based models’ inference memory scales linearly with input length (O(n)), while Transformer's self-attention incurs quadratic growth (O(n2)). At 1000-character sequences, Mamba-AR’s memory footprint increases by 1.26×, as compared to DAN’s 2.30×, enabling larger batch sizes and more efficient deployment for high-throughput digitization tasks.
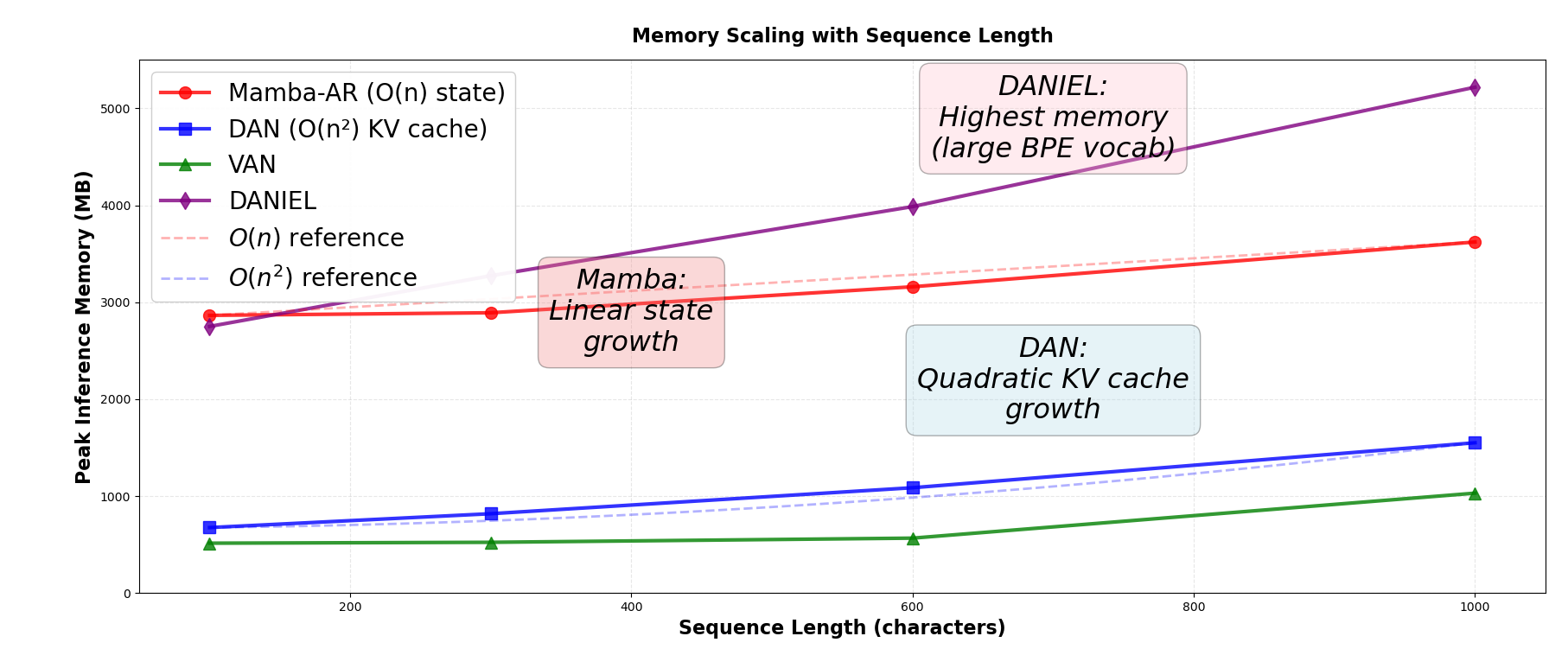
Figure 3: Peak inference memory as a function of sequence length: Mamba-AR’s memory increases linearly (O(n)), compared to DAN’s quadratic scaling (O(n2)).
Decoding Paradigm Insights
Across CTC, AR, and NAR decoders, accuracy differences diminish for long sequences when constrained to the character-level vocabulary. The separation between CTC speed/simplicity and AR contextual modeling—central in modern OCR—becomes less impactful given that all considered neural models achieve ∼2% CER; thus, throughput and resource efficiency become the principal axes for practical adoption.
Theoretical and Practical Implications
This work robustly demonstrates that SSMs (specifically Mamba) can supplant Transformers for historical OCR without compromising accuracy, while considerably improving efficiency for long-context recognition. This holds both at the line-level and for paragraph-level inputs where Transformer key/value cache growth thwarts batch inference.
The findings advise that for paragraph-scale heritage OCR with tight resource constraints:
- CTC models (VAN, Mamba-CTC) maximize throughput with negligible penalty in CER.
- Mamba-AR delivers strong accuracy/speed trade-off suitable when AR modeling is vital.
- Subword tokenization (DANIEL) is detrimental for historically variable scripts due to vocabulary/orthography mismatch.
- Off-the-shelf VLMs (TrOCR, Gemini) cannot substitute domain-tuned systems for complex/degraded documents.
SSMs’ computational scaling opens directions for full-page or multi-column OCR, bridging document understanding and information extraction for billion-scale digitization projects. Potential exists to jointly optimize layout analysis and sequence modeling using SSMs, and for transfer learning extensions akin to LLMs in NLP.
Conclusion
The first comprehensive benchmark of SSMs vs Transformers/BiLSTMs for historical OCR confirms that Mamba-based models are viable, efficient alternatives for paragraph-level and long-sequence recognition. When accuracy among neural paradigms saturates, computational scaling and inference speed dictate architectural selection. This benchmark framework, codebase, and high-quality gold datasets constitute a reproducible foundation for OCR research and large-scale cultural heritage processing (2604.00725).

