- The paper presents a novel prompt-driven framework for privacy-driven unlearning that categorizes unlearning scenarios and shapes agent behavior.
- It delineates state, trajectory, and environment unlearning to effectively erase sensitive information while preserving overall performance.
- Empirical evaluations across diverse tasks confirm that NL-based unlearning outperforms baselines, offering strong theoretical guarantees and practical robustness.
Secure Forgetting: A Framework for Privacy-Driven Unlearning in LLM-Based Agents
Overview and Motivation
LLM-based agents are increasingly utilized in settings requiring complex reasoning, adaptive decision-making, and interaction with dynamic environments. Such agents accumulate knowledge over time, raising significant privacy and security concerns, particularly when sensitive or outdated information needs to be selectively forgotten. Unlike traditional machine unlearning—where model weights are altered—LLM-based agent unlearning necessitates behavioral change without direct access to LLM parameters, as the agent’s policy is shaped via prompt engineering and memory manipulation. The paper "Secure Forgetting: A Framework for Privacy-Driven Unlearning in LLM-Based Agents" (2604.00430) establishes a rigorous theoretical and practical framework for this emerging challenge, systematically categorizing unlearning targets and proposing a prompt-driven paradigm for agent forgetting.
Taxonomy of Unlearning Scenarios
Three distinct unlearning contexts are formalized:
- State unlearning: Forgetting specific states or items within a trajectory. This is vital, for example, in navigation agents that must erase knowledge about sensitive locations (e.g., private residences).
- Trajectory unlearning: Disassociating sequences of actions, such as routines that encode personal habits or routines.
- Environment unlearning: Eliminating all knowledge derived from specific environments or broad categories of tasks, mitigating risks of environmental intelligence leakage.
Each scenario differs in operational constraints and the degree of behavioral modification required. State unlearning enforces strict avoidance, trajectory unlearning disables sequence reconstruction but allows state visitation, and environment unlearning targets performance degradation to baseline levels as if the agent has never encountered the environment.
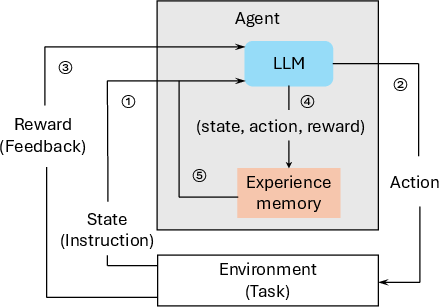
Figure 1: Overview of an LLM-based agent integrating environmental observations and memory to govern action selection.
Methodology: Prompt-Based Unlearning via Conversion Model
The framework employs a natural language-based conversion model (C) to translate high-level unlearning requests into actionable prompts compatible with underlying LLMs. The process consists of:
- Request acquisition: Crafting an unlearning query reflecting the privacy-driven objective.
- Prompt generation: Conversion model C outputs multiple candidate prompts, evaluated for efficacy via behavioral testing.
- Preference learning: A dataset of preferred and dispreferred prompts is assembled for fine-tuning C, optimizing a loss function that aligns agent responses with desired forgetting.
- Feedback iteration: Behavioral feedback from the LLM-driven agent is used to refine conversion model output.
Behavioral forgetting is achieved by manipulating the agent’s memory and guiding the LLM’s policy through precise prompt engineering, effectively shaping the action distribution without altering internal model parameters. Theoretical guarantees underpin the approach, establishing convergence and bounding the KL divergence between the unlearned agent’s distribution and a reference agent unexposed to the forgotten content.
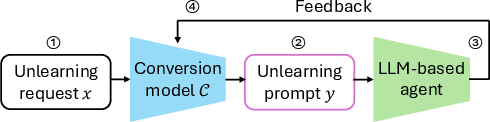
Figure 2: The unlearning approach comprises four phases, from request crafting to behavioral feedback-driven prompt generation.
Theoretical Foundations
Utility analysis demonstrates the alignment of log-odds assigned by C with true latent preferences, while convergence proofs guarantee linear approach toward the optimum under mild smoothness and convexity assumptions. Robustness analysis provides an upper bound on KL divergence between behavioral distributions, ensuring practical indistinguishability between unlearned agents and reference agents, thus mitigating information leakage under adversarial inference.
Empirical Evaluation: Unlearning Efficacy and Robustness
Experiments span GridWorld (navigation), AlfWorld (household tasks), HotPotQA (QA), and HumanEval (code generation). Three methods are benchmarked: NL-based (natural language prompting), Code-based (translation to executable code), and Example-based (in-context demonstrations).
- NL-based outperforms baselines: Across state, trajectory, and environment unlearning, NL-based achieves near-perfect unlearning efficacy and preserves untargeted task performance, outperforming Code-based and Example-based approaches.
- Fine-tuning of conversion model is critical: Ablations reveal sharp declines in unlearning effectiveness when the conversion model is removed or unfined-tuned.
- Base model selection: Larger representational capacity in base models (e.g., GPT-Neo-2.7B, Pythia-2.8B) correlates with higher unlearning efficacy.
- Prompt diversity trade-off: Generating three candidate prompts (m=3) achieves balance—more brings redundancy, fewer limits behavioral coverage.
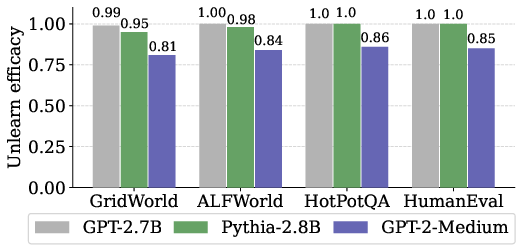
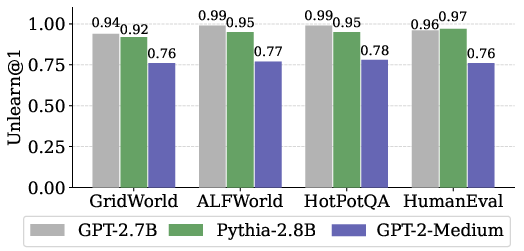
Figure 3: Unlearning performance of the proposed method across varying base models.
Simulation studies on Gazebo validate real-world applicability, confirming that privacy-driven unlearning remains robust under environmental complexity and agent deployment.


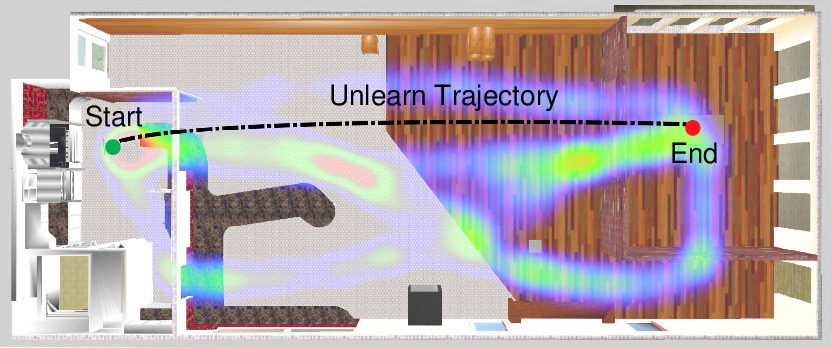

Figure 4: Unlearning in the Gazebo platform demonstrating avoidance and behavioral reshaping across unlearning scenarios.
Privacy Threats and Adversarial Robustness
An adversary conducting behavioral inference via query construction and trajectory analysis fails to distinguish between unlearned agents and reference agents when NL-based unlearning is employed. State and trajectory traversal frequencies post-unlearning converge to those of agents with no prior exposure. Environment reconstruction attacks are effectively mitigated, as evidenced by low structural similarity post-unlearning.
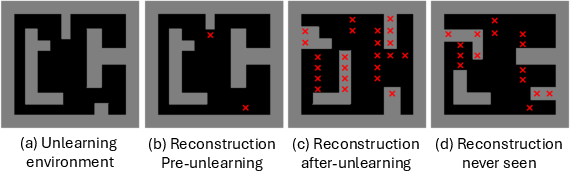
Figure 5: Environment reconstruction results affirm the framework’s robustness against adversarial inference.
Practical and Theoretical Implications
The framework introduces significant advances for privacy-preserving agent architectures:
- Parameter-free unlearning: Enables forgetting without LLM access—increasing practicality in cloud-deployed agents or proprietary LLM integrations.
- Modular behavioral control: Supports granular forgetting aligned with regulatory requirements (e.g., GDPR, CCPA) without catastrophic forgetting.
- Foundation for regulatory compliance: Establishes a concrete methodology for implementing “right to be forgotten” in agentic AI, with direct implications for autonomous vehicles, service robotics, personal assistants, and multi-agent systems.
Theoretically, prompt-driven policy shaping offers a tractable mechanism for constrained behavioral adjustment, delivering tight analytical guarantees and opening avenues for safe agent design.
Future Directions
Extension to multi-agent systems, integration with federated architectures, and investigation of continual unlearning dynamics are promising. Further exploration into adaptive adversarial robustness and formal privacy guarantees for prompt-based unlearning will sharpen theoretical underpinnings and fortify agent systems against evolving privacy threats.
Conclusion
The paper provides the first unified framework for privacy-driven unlearning in LLM-based agents, combining rigorous problem taxonomy, prompt-engineering strategies, conversion model optimization, and robust empirical validation. It establishes both theoretical and practical foundations for controlled forgetting in agentic systems, with immediate applicability to privacy-sensitive domains and regulatory compliance.

