- The paper introduces a prompt-guided prefiltering method that uses TinyCLIP to generate spatial relevance maps for adaptive image compression.
- It employs localized Gaussian smoothing based on computed relevance scores to achieve 25.88% to 48.78% bitrate reductions while maintaining VQA accuracy.
- The approach functions as a plug-and-play preprocessor for edge devices, ensuring compatibility with existing codecs without requiring retraining.
Prompt-Guided Prefiltering for VLM Image Compression
Introduction
This work addresses the inefficiency of traditional human-centric image codecs in the context of edge-to-cloud Vision-LLM (VLM) deployments, particularly for open-ended, prompt-driven tasks. The standard codecs (JPEG, HEVC, VVC) retain significant amounts of task-irrelevant information, increasing bandwidth requirements without contributing to VLM accuracy. Existing Image Coding for Machines (ICM) methods either jointly optimize the codec and downstream tasks (requiring a fixed task in advance) or use prompt-agnostic semantic filtering, failing to generalize to the dynamically specified objectives common in VLM applications.
The primary innovation of this paper is a prompt-guided, lightweight, and codec-agnostic prefiltering module designed for compatibility with existing edge devices. This module employs TinyCLIP—a distilled CLIP variant—to generate prompt-informed spatial relevance maps, enabling local smoothing of less relevant regions while preserving semantic fidelity in critical areas, prior to encoding. The method is designed to be a plug-and-play preprocessor and does not require modification to either the encoder or cloud-based VLM decoder.
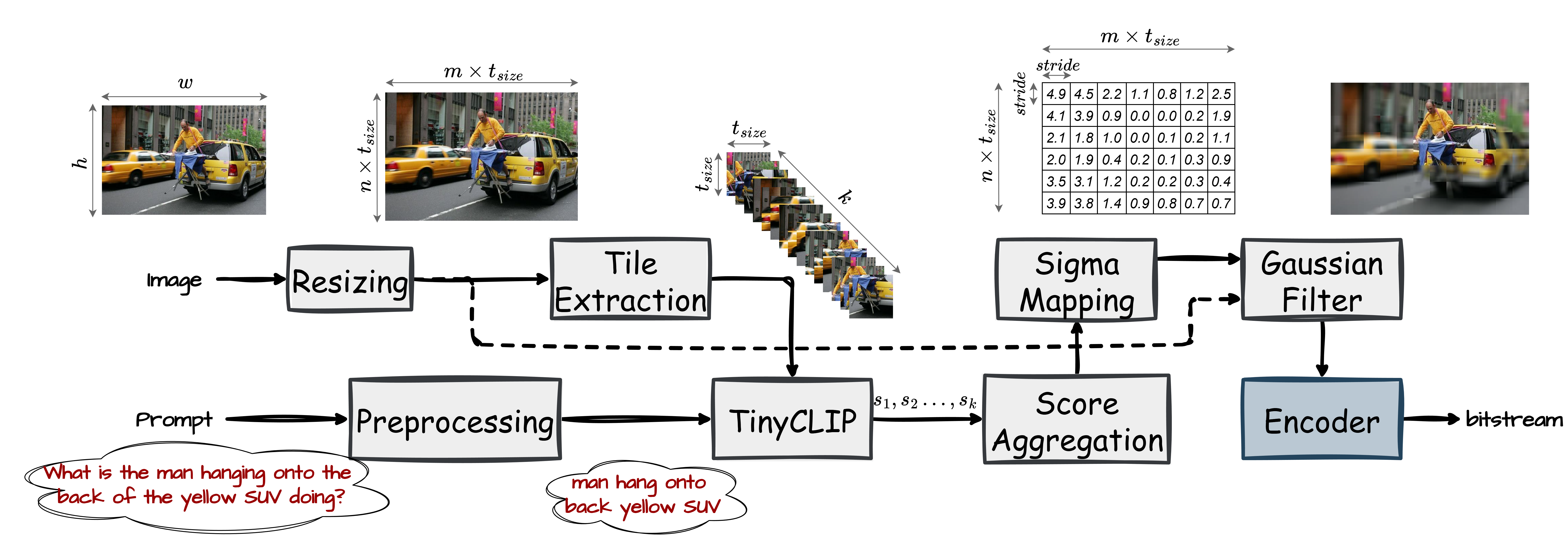
Figure 1: The overall block diagram of the proposed prompt-guided prefiltering and compression framework.
Methodology
The approach first preprocesses the prompt using standard NLP techniques (instructional phrase removal, stopword filtering, lemmatization, and part-of-speech prioritization) to fit TinyCLIP's context window constraints. The input image is resized and tessellated into tiles (typically 224×224) with adjustable overlap to optimize score map granularity and computation cost on edge hardware.
TinyCLIP encodes both the tiles and the processed prompt into embeddings. Normalized dot-product similarity is computed and scored via softmax, with logit scaling to control sharpness, yielding a per-tile relevance map. Overlapping regions' scores are averaged to build the final relevance map over the whole image.
Subsequently, exponential mapping translates the normalized relevance score per region into a local Gaussian smoothing strength (σ). Lower relevance induces high smoothing (aggressive compression gains); high relevance yields minimal smoothing, preserving prompt-critical details. The filtered image is then passed to any desired codec. The process is entirely upstream of the encoder and VLM—allowing production integration on resource-constrained edge devices without retraining or altering downstream infrastructure.
Experimental Results
Visualization of Prompt-Adaptive Filtering
A key advantage of the method is visualized in filtered outputs under distinct prompts, where the module dynamically identifies and preserves regions salient to each query, while smoothing extraneous image content. This directly contrasts with prompt-agnostic filtering approaches, which cannot adapt spatial attention based on textual intent.

Figure 2: Prompt-specific filtering visualization for a single image using three different prompts.
Rate-Accuracy Analysis
Evaluation is performed on three standard VQA benchmarks (MMBench, MME, SEEDBench) using VLMEvalKit, with two backbone VLMs: LLaVA-OV-7B and InternVL3-9B. Four codecs are considered: JPEG, HEVC, VVC, and the learned Image Codec of Cheng et al. The performance metric is rate–accuracy—the bitrate required to achieve equivalent VQA accuracy.
Across all tasks, integrating the prompt-guided prefiltering module yields consistent average bitrate reductions between 25.88% and 48.78% at fixed accuracy compared to codec-only baselines. The highest gains are observed for HEVC, VVC, and learned codecs, indicating strong synergy between low-pass suppression of non-salient features and advanced entropy coding techniques.
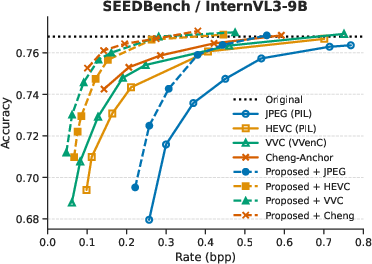
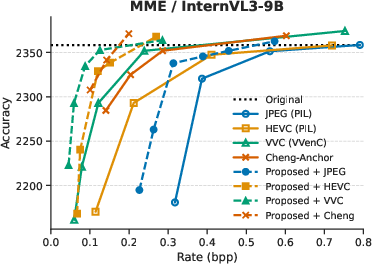
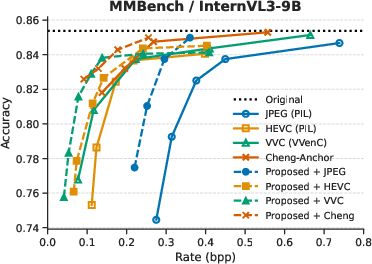
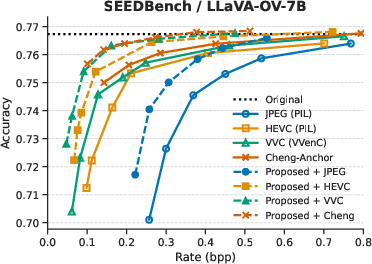
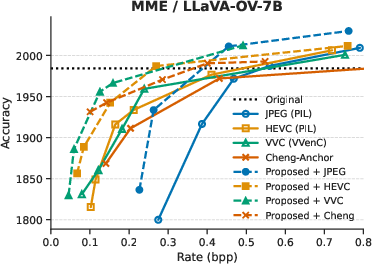
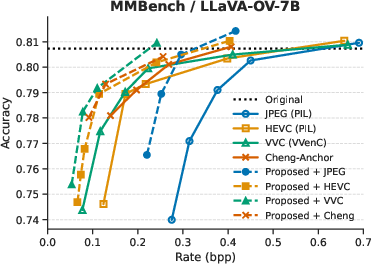
Figure 3: Rate–accuracy curves for InternVL3-9B and LLaVA-OV-7B across SEEDBench, MME, and MMBench benchmarks.
Component Analysis and Ablation
Ablation studies demonstrate that the TinyCLIP component is critical—its removal increases bitrate by approximately 70% even relative to alternative smoothing or downsampling baselines, confirming the value of prompt-driven spatial selection. Overlapping tile extraction, prompt preprocessing, and model capacity decisions are shown to additionally modulate bitrate-accuracy tradeoffs at lower, but still significant, levels. A 57M parameter TinyCLIP model was optimal for this setting.
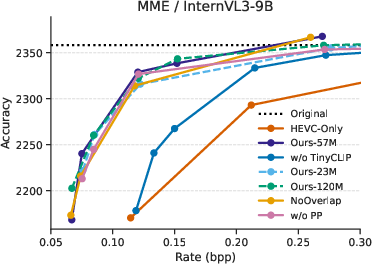
Figure 4: Rate–accuracy curves for InternVL3-9B on the MME dataset, illustrating component contributions via ablations.
Simple alternatives (whole-image Gaussian filtering, aggressive downsampling) provide marginal bitrate gains but degrade VQA accuracy at higher compression ratios or task complexities, reaffirming the necessity of semantically adaptive filtering.
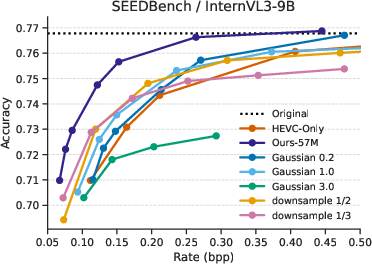
Figure 5: Rate–accuracy curves for InternVL3-9B on SEEDBench dataset, including whole-image filtering and downsampling baselines.
Theoretical and Practical Implications
This work establishes that prompt-guided, localized image prefiltering substantially enhances rate–accuracy efficiency for VLM-based downstream applications. Crucially, it demonstrates that retaining only the semantic content relevant to the specific prompt maximally exploits modern codecs and enables robust operation with existing edge-hardware bottlenecks. As open-vocabulary, multi-task VLMs proliferate in cloud-centric ecosystems, this framework addresses a key bottleneck for real-time systems and bandwidth-sensitive deployments.
The codec-agnostic, modular design ensures forward compatibility with future advances in both learned and standard codecs. The empirical optimality of moderately sized TinyCLIP variants underlines that high-fidelity prompt adaptation does not necessitate the deployment of large VLM backbones at the edge.
Future Directions
Potential avenues for extension include (i) improved multimodal relevance modeling beyond shallow text-vision affinity, (ii) dynamic adjustment of the tile grid and filtering kernel size for scene-adaptive bandwidth optimization, and (iii) integration with token pruning or downstream feature injecting for further reductions in effective transmission requirements. Combining prompt-guided prefiltering with hierarchical, task-specific codecs may yield even higher compression efficiency.
Further, as VLMs extend to non-visual modalities and more complex compositional tasks, expanding the filtering module to incorporate broader context cues (e.g., temporal or sensor metadata) may be critical. Finally, investigating adversarial robustness and privacy properties of prompt-guided filtering remains an open field.
Conclusion
Prompt-guided prefiltering for VLM image compression establishes a new standard in achievable bitrate savings for open-ended, prompt-driven edge-to-cloud pipelines, achieving 28–47% compression gains without loss in VQA accuracy using a lightweight, deployable, and codec-agnostic architecture. This method effectively bridges the gap between bandwidth-constrained edge devices and the high variability of real-world VLM tasks, and provides a scalable platform for deployment as VLM bandwidth demands continue to grow (2604.00314).

