- The paper demonstrates that slab-partitioned systolic arrays can adapt to varied GEMM shapes, enabling up to 8.52× speedup for LLM workloads.
- It details a flexible fusion and power gating mechanism that reduces energy-delay product by up to 93% for suboptimal matrix dimensions.
- The design incurs minimal hardware overhead with less than a 5.5% area increase compared to monolithic systolic arrays like TPUv4.
SISA: Scale-In Systolic Array for GEMM Acceleration
Introduction
The proliferation of LLMs and other DL models has established General Matrix-Matrix Multiplication (GEMM) as a fundamental primitive in contemporary AI hardware. Conventional systolic array (SA) architectures—exemplified by monolithic, fixed-size arrays as in TPUv4—exhibit optimal compute efficiency only for square or large, regular GEMM shapes. However, prevalent LLM workloads induce high variability and skewness in matrix dimensions, leading to extensive underutilization of processing elements (PEs). This architectural inefficiency is pronounced in prompt-prefill scenarios, for which token sequence lengths are typically small, producing tall-skinny or short-wide matrices.
SISA (Scale-In Systolic Array) introduces a slab-based architectural paradigm, where a square SA is partitioned into independently schedulable horizontal slabs. Slabs can operate independently, be power-gated, or fused at runtime—enabling robust adaptation to a wide spectrum of GEMM shapes without incurring the memory and area penalties typical of alternative reconfigurable or pod-based SAs.
SISA Architecture
SISA employs a regular n×n SA partitioned along the vertical axis into k horizontal slabs, each slab encompassing a contiguous subset of rows. Each slab is equipped with slab-local activation and weight buffers. Slabs can be operated in three modes: independently for highly-skewed, small-M GEMMs, fused into taller logical slabs for intermediate M, or as a fully-monolithic array for large-M computations. Output is routed to a global output buffer organized for minimal bandwidth contention. All buffer organizations support double buffering for data movement overlap.
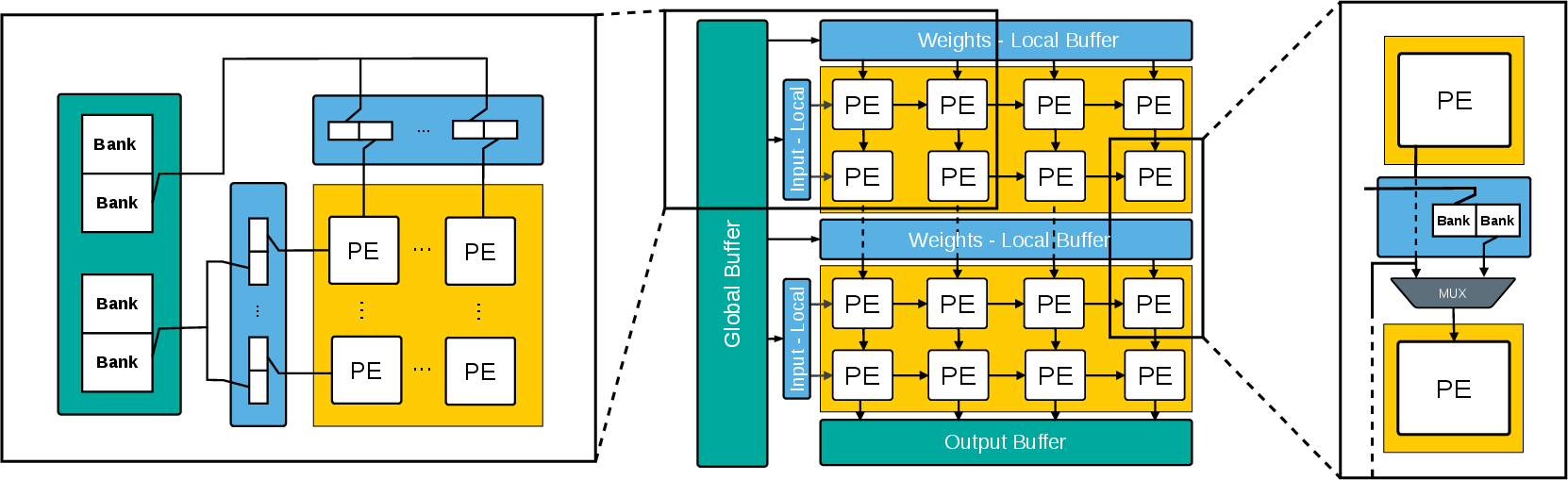
Figure 1: High-level SISA architecture, showing memory hierarchy and the slab fusion mechanism.
The fusion and bypass mechanisms in SISA employ lightweight multiplexers for inter-slab forwarding of weights, allowing tiled compositions along the height dimension with minimal critical-path impact. Power-gating is realized at slab granularity, decreasing leakage for underutilized configurations—particularly relevant when real-world workloads have short-token sequences and thus require only subsets of the array.
Scheduling and Tiling
GEMM workloads are decomposed into tiles mapped onto slabs, exposing parallelism across multiple slabs for batched decode or short prompts. The tiling routine statically maps tiles given buffer constraints and slab configuration. For best-case utilization, when M matches a slab's height, all PEs within each slab are engaged in independent tile processing over the N dimension. For taller GEMMs (M>hslab), slabs are fused until the computation fits, trading off parallelism for improved intra-slab data reuse. With M>n, the full array is fused; residual computations are processed using slab-aligned, possibly power-gated executions.
This tiling and scheduling logic ensures that SISA retains high utilization across the variable GEMM shapes naturally encountered in LLMs, with minimal hardware complexity and modest buffer overheads compared with aggressive multi-pod or fully reconfigurable designs.
Empirical Results
SISA was synthesized for a 128×128 BF16 PE array, targeting comparable technology and on-chip memory budgets as TPUv4 and ReDas. The core empirical findings emphasize several strong claims:
- Speedup: SISA provides up to k0 speedup for small k1 GEMMs over a monolithic TPU baseline. This advantage is most significant for interactive LLM workloads with short prompts, where matrix shape mismatch is acute.
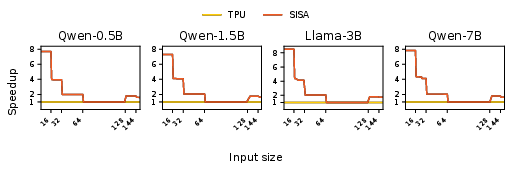
Figure 2: SISA speedup versus TPU baseline across sequence lengths and LLM models.
- Energy-Delay Product (EDP): In the same regime, SISA delivers up to 93% EDP reduction; the average EDP gain persists across most sequence lengths below k2.
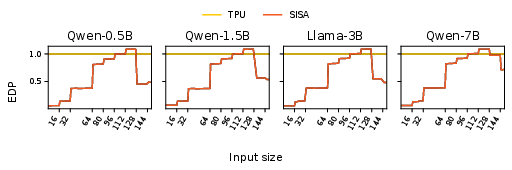
Figure 3: SISA normalized EDP versus TPU. Substantial gains for typical LLM workload sizes.
- Worst-Case Penalty: For square/large k3 GEMMs, SISA's overhead is limited to an 8.47% EDP delta, attributable to buffer-multiplexing and minor leakage from additional SRAM and gating logic.
- Area Efficiency: The architectural overhead, including slab fusion/power-gating and more complex buffering, leads to less than 5.5% total area increase over a baseline TPU implementation. This is markedly below the 70%+ per-PE area and k4 per-PE power overhead reported in ReDas for INT8, which only worsens for BF16.
- Comparison with ReDas: Across k5 to k6, SISA achieves up to k7 speedup versus ReDas, with negligible scenarios where SISA is outperformed—generally limited to specific intermediate k8 where ReDas' coarse-granularity reshaping is optimal.
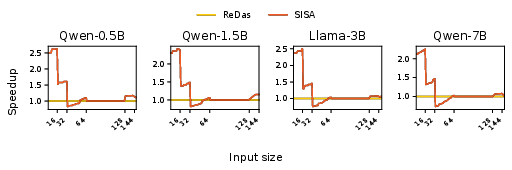
Figure 4: Speedup of SISA compared to ReDas, emphasizing consistent gains especially for small-batch and skewed GEMMs.
- Layer-Wise Latency: For Qwen2.5-0.5B, at small k9 (best-case) SISA realizes substantial latency reduction across all GEMM layers, whereas for unfavorably-shaped M0 SISA and ReDas are nearly matched, confirming the adaptability and steady lower-bound latency profile of SISA.
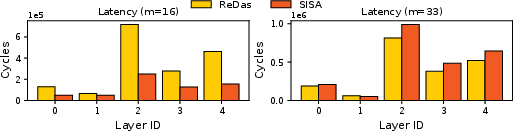
Figure 5: Latency analysis of Qwen2.5-0.5B layers at best and worst case, weighted by layer occurrence.
Implications and Future Directions
SISA addresses a fundamental architectural inefficiency—SA underutilization—prevalent in LLM-serving scenarios where prompt lengths (and thus matrix outer dimensions) are variable and often much smaller than the array's height. The design integrates lightweight adaptation strategies (slab partitioning, power-gating, efficient fusion) with minimal cost to hardware complexity and area.
Practically, SISA enables accelerator vendors and datacenter operators to provision fewer cycles (and therefore joules) for popular workloads, particularly under realistic QoS constraints with small to moderate batch sizes. The theoretical implication is the demonstration that slab-level parallelism, when carefully orchestrated, can realize finer-grained adaptation to skewed matrix shapes without the prohibitive area/power overheads of pod-based or highly-dynamic designs.
Future development in SA-based accelerators will likely combine SISA-like granularity (slab-based partitioning) with improved interconnect and global control strategies, possibly integrating workload-adaptive reconfiguration in conjunction with memory-side compression or partitioned attestation for multi-tenant regimes. Additional extension to SISA could focus on support for mixed-precision execution, dynamic sparsity exploitation, or further SRAM/DRAM interface optimization to close the remaining efficiency gap in boundary cases.
Conclusion
SISA demonstrates that a modestly-complex slab-partitioned SA can deliver substantial speedup and energy efficiency improvements for GEMM-centric workloads manifesting high matrix-shape skewness, with concrete gains over both monolithic (e.g., TPUv4) and flexible but area-heavy (e.g., ReDas) baselines. Its performance, power, and area profiles underscore its suitability for modern AI inference (especially LLM prefill/decode) deployments where resource underutilization is both common and expensive. The SISA design provides a compelling architectural reference point for next-generation GEMM accelerators prioritizing scalable utilization and minimal overhead across highly dynamic inference workloads (2603.29913).

