- The paper demonstrates that LLMs spontaneously differentiate into a synergistic core for abstract reasoning and redundant modules for memory.
- It utilizes ΦID to decompose information flow, revealing phase transitions that mirror neurobiological energy and topological patterns.
- Ablation studies confirm that disrupting abstract-processing heads leads to catastrophic performance drops, highlighting their critical role.
Introduction
This essay provides a technical summary and analysis of "Spontaneous Functional Differentiation in LLMs: A Brain-Like Intelligence Economy" (2603.29735). The authors systematically investigate the internal information processing structure of LLMs, revealing parallels with neurobiological systems, specifically in the spontaneous emergence of functionally differentiated modules. The study leverages advanced tools from information theory—particularly Integrated Information Decomposition (ΦID)—to precisely localize and quantify synergistic (abstract-processing) and redundant (memory-transmission) components in transformer architectures such as Qwen3 and Gemma3. The work demonstrates that LLMs develop a dynamic, core-periphery organization optimized for both abstract reasoning and memory stability, and shows that this organization itself is task-adaptive and subject to phase transitions in response to increased complexity.
The analysis employs ΦID, an extension of Partial Information Decomposition (PID), to decompose time-delayed mutual information between subunits (e.g., attention heads) into unique, redundant, and synergistic atoms. This decomposition enables precise attribution of memory versus abstraction functions within the model.
The authors find that early and late layers of LLMs predominantly serve as memory storage and transmission layers, supporting lossless information flow. These layers exhibit redundancy, high plasticity, and provide stability against interference or ablation. In contrast, the middle layers form a synergistic core in which information from multiple channels is fused—effecting abstraction via nonlinear feature integration and producing new high-level representations not present in earlier layers.
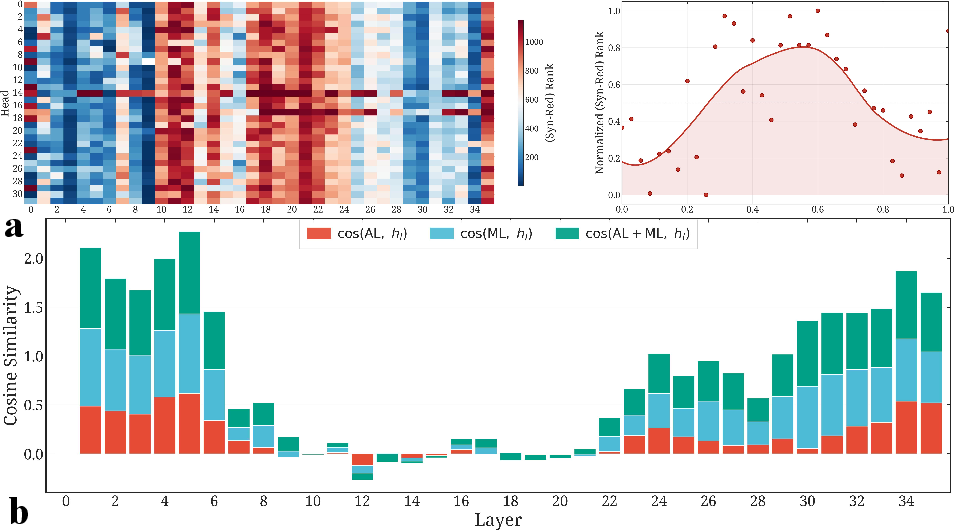
Figure 1: Distribution of abstract and memory components and sub layer residual flow contributions in Qwen3-8B-Base. Abstract-processing heads are concentrated in the middle layers, demarcating a synergistic core; early and late layers are memory dominated. The cosine similarity of residual flow shows a phase transition in the middle of the network.
The boundary between these modules is sharply defined, corresponding to an "inverted U" distribution of abstraction capability across layers. Residual flow analysis further reveals a mid-network phase transition: cosine similarity shifts from enhancement (memory) to orthogonalization/erasure (abstraction), back to enhancement, mirroring detokenization-tokenization findings in LLM interpretability studies.
Topological and Energetic Organization
The network structure of attention heads is mapped using graph-theoretic approaches. Abstract heads (middle layers) exhibit high global efficiency, forming an integrated core; memory heads (peripheral layers) show high modularity, clustering into independent redundancy-focused communities. This configuration mirrors the anatomical-functional organization of human brains where associative hubs drive abstraction and sensory/memory modules assure robust flow.
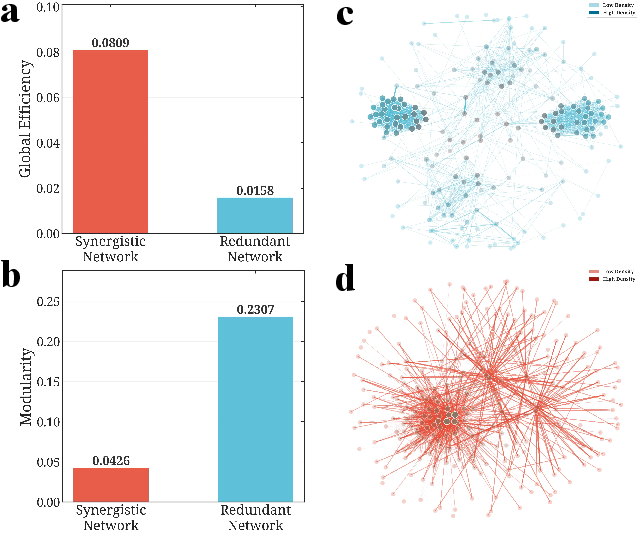
Figure 2: Topological properties of attention head networks. Abstract heads display high global efficiency, forming a centralized, brain-like synergistic core; memory heads exhibit modular clustering.
Energetic analysis—quantifying layerwise energy consumption—confirms that the synergistic (abstract) core is metabolically demanding, while peripheral memory modules minimize energy expenditure. This partition closely parallels glucose consumption profiles in functional brain imaging, with associative cortices outpacing primary sensory or storage regions.
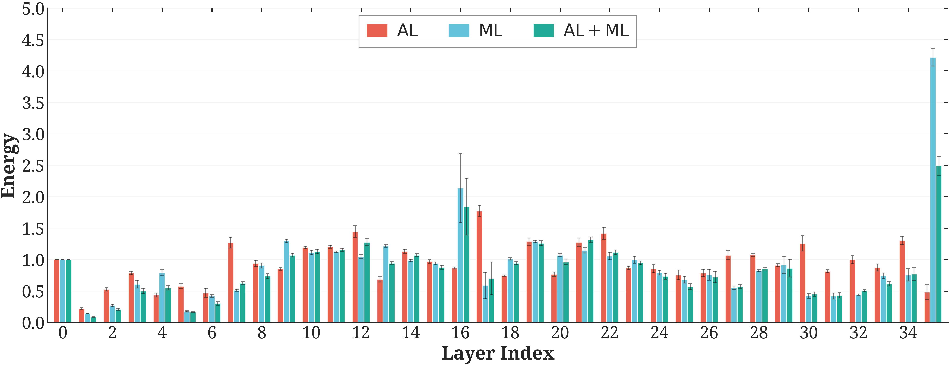
Figure 3: Energy consumption sharply peaks in middle (abstract) layers, recapitulating metabolic signatures of biological associative hubs.
Dynamic Functional Specialization and Task Adaptation
An essential claim is the dynamic, task-dependent emergence of this modular organization. For low-difficulty tasks, functional specialization is weakly expressed: abstraction and memory heads remain intermixed, allocating minimal energy and showing no phase boundary. As task complexity rises, the model undergoes a physical phase transition: heads cleanly cluster into separate memory and abstraction modules, a process akin to neurobiological differentiation during cognitive challenge.
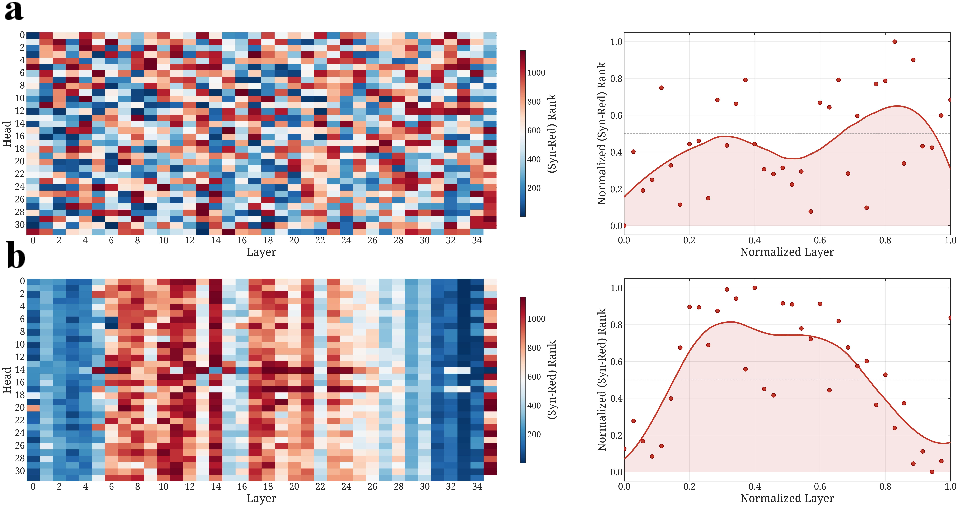
Figure 4: Functional embedding of attention heads on ARC tasks. Easy tasks result in intermixed heads; higher-difficulty tasks produce sharp functional clusters with a definitive boundary.
Layer skipping and integrated gradients are used to probe functional necessity: ablation or skipping of middle layers (synergistic core) results in significant downstream degradation; early and late layers are less essential, conferring robustness through redundancy.
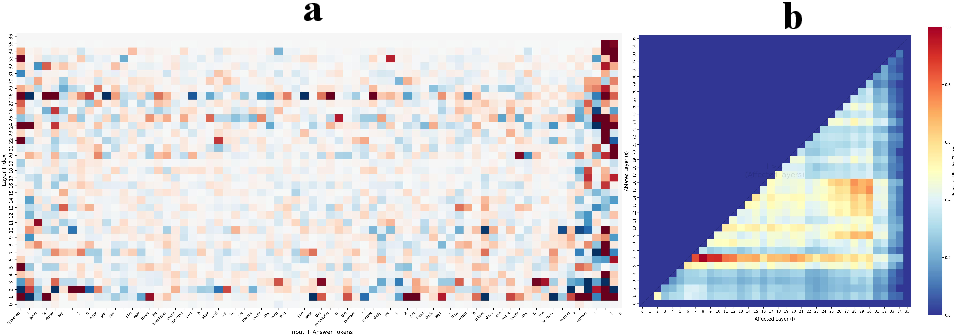
Figure 5: (a) Integrated gradients highlight logic-driving layers. (b) Skipping middle layers yields non-local, catastrophic impact, underlining their necessity for complex reasoning.
Ablation studies further reveal that performance is dominated by a small subset of critical abstract heads; loss of these induces catastrophic collapse, while memory or random head ablation is much less disruptive.
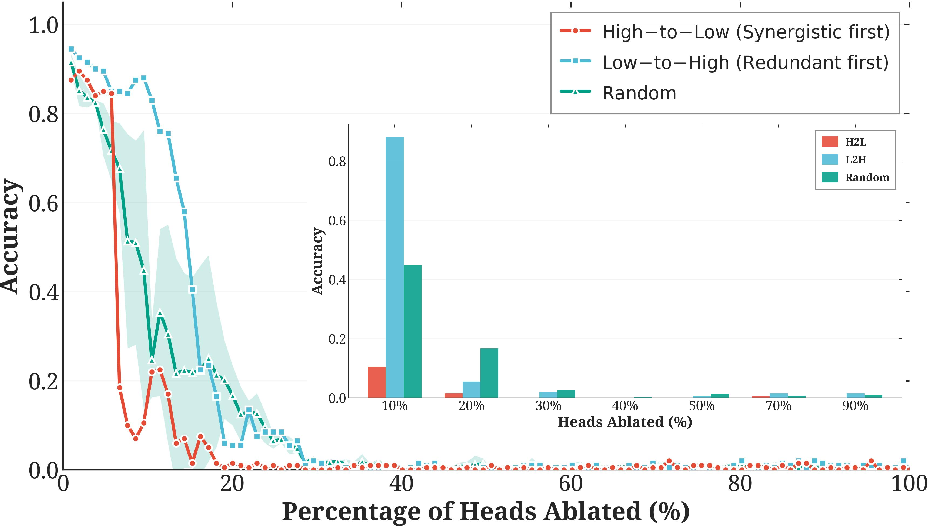
Figure 6: Performance impact of head ablation. Removing abstract heads causes a collapse, with effects far exceeding those from memory or random head removal.
Implications and Future Directions
This work offers strong empirical evidence that deep transformer LLMs independently evolve a robust division of labor analogous to mammalian brains: a small, high-efficiency, energy-consuming synergistic core for abstract reasoning; and peripheral, redundant modules for memory relay and error correction. The neurobiological parallels are both structural (modularity, efficiency) and functional (energy allocation, adaptive reorganization).
Theoretical Implications:
The findings support a model where LLMs are not uniform stateless compressors, but exhibit localized computational specialization with emergent properties (e.g., phase transitions) under increasing cognitive load. This reinforces recent theoretical work suggesting that abstract, high-level reasoning circuits exist within specific subspaces or subnetworks, in tension with overparameterization and redundancy-based robustness. Techniques such as ΦID thus offer powerful tools for localizing and quantifying these effects, linking machine intelligence to theories of consciousness and brain function.
Practical Implications:
For LLM scaling, the results validate keeping parameter redundancy for generalization and stability but also argue for targeted allocation of resources to layers responsible for abstract reasoning. Ablation and energy studies indicate that model pruning or compression should be contextually sensitive, avoiding disruption of the synergistic core. Furthermore, these results can guide more transparent explanations of LLM decision-making and more efficient architectures inspired by biological constraints.
Speculative Perspectives:
Future research may generalize these findings across architectures, modalities, and training regimens, examining the universality of spontaneous functional differentiation. Efficiency of ΦID computation remains a bottleneck, motivating development of scalable proxies. The deep analogy between cortical organization and deep network function suggests new avenues for interpretable AI, for neuroscientific data analysis, and ultimately for hybrid architectures that deliberately mix redundant relay with specialized, energy-intensive abstraction.
Conclusion
The study rigorously documents the spontaneous emergence of functionally differentiated modules in LLMs, paralleling neurobiological organization. Through precise information-theoretic decomposition, it reveals a dynamic, energy-sensitive partition into memory and abstract-processing components, with phase transitions and catastrophic sensitivity to core ablation, especially as task complexity increases. These structural and energetic patterns illuminate theoretical and practical strategies for understanding, interpreting, and further developing both artificial and biological cognitive architectures.

