- The paper presents a model-free, offline framework leveraging goal-conditioned RL and graph search to plan STL-satisfying trajectories.
- It constructs a reachability graph via value-aware clustering and grid subsampling to enable robust zero-shot generalization across tasks.
- Empirical evaluations in the AntMaze environment show high planning success (95.58%) and execution rates (81.58%) with efficient computation under complex STL specifications.
GraSP-STL: A Graph-Based Framework for Zero-Shot STL Planning via Offline Goal-Conditioned RL
Introduction and Problem Statement
Signal Temporal Logic (STL) provides a rigorous formalism for specifying complex temporal behaviors, sequencing, and safety in control systems. Scaling STL-based control synthesis to high-dimensional nonlinear environments without access to system models or online interaction remains a significant challenge, particularly for zero-shot generalization to novel tasks. "GraSP-STL: A Graph-Based Framework for Zero-Shot Signal Temporal Logic Planning via Offline Goal-Conditioned Reinforcement Learning" (2603.29533) directly addresses this by introducing a method that operates solely from fragmented, offline datasets, without access to analytical dynamics, further interaction, or task-specific retraining.
The central goal is to synthesize, in a zero-shot fashion, control strategies whose executions robustly satisfy unseen STL specifications. This is accomplished through an integrated pipeline that leverages goal-conditioned RL for extracting a reusable notion of reachability, discretizes the state space into a sparse graph abstraction, and plans by graph search with formal STL robustness metrics.
Framework Overview
The proposed GraSP-STL pipeline consists of three key modules: offline goal-conditioned RL, reachability-based graph construction, and STL-guided graph search for planning. This separation decouples behavior learning from task specification, enabling compositional synthesis for arbitrary STL formulas.
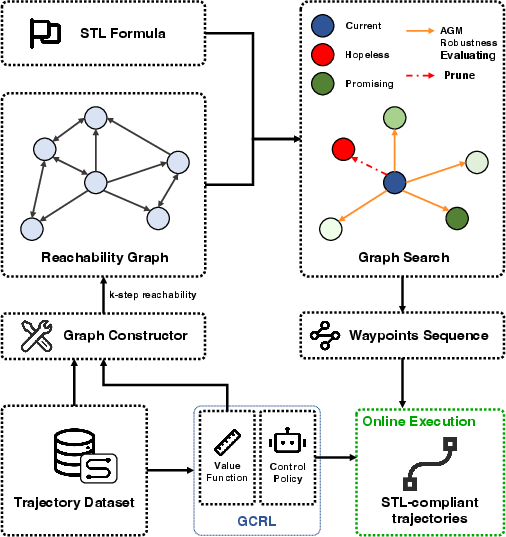
Figure 1: High-level architecture of GraSP-STL, illustrating the interplay between goal-conditioned value learning, graph-based abstraction, and STL-critical path planning.
The agent learns a goal-conditioned value function and associated policy from purely offline data. Utilizing this learned metric, a reachability-directed graph is constructed wherein nodes represent representative system states and edges capture feasible short-horizon transitions, parameterized by the value function. STL specification satisfaction is then formulated as a graph search problem: planning over waypoint sequences, evaluated under the Arithmetic-Geometric Mean (AGM) robustness framework and its interval extension for partial trajectories.
Goal-Conditioned Reachability and Policy Synthesis
The framework employs goal-conditioned RL to parameterize both a value function V(s,g) (interpreted as negative temporal distance between state s and goal g) and a goal-directed low-level policy. Training utilizes a weighted behavior cloning objective with advantage terms and directional alignment [hiql, ttgs]. The metric d^(s,g)=−V(s,g) serves as the backbone for inferring feasible transitions and constructing the planning graph.
The goal-conditioned policy is designed as a direction-aware controller that generates short-horizon trajectories to target states within a pre-defined horizon k, supporting modular waypoint following consistent with the graph abstraction.
Graph Abstraction and Construction
The reachability graph G=(V,E) is generated through geometric grid-based subsampling and value-aware clustering, producing nodes with improved spatial coverage and transition fidelity. Edges are instantiated between node pairs whose estimated goal distances are less than a threshold, further pruned by an angular diversity heuristic to ensure efficient exploration and long-horizon stitchability.
To guarantee planning feasibility, only the largest strongly connected component is retained, ensuring all waypoints are mutually reachable under the value-induced metric.
STL Specification Planning via Graph Search
High-level planning is cast as an augmented graph search problem where each node encodes both a graph state and the STL monitor state. Robustness intervals for STL specifications, particularly under the AGM semantics, are computed incrementally; the method extends [ahmad2026rrt] to support nested temporal operators, maintaining soundness and computational tractability.
The search employs aggressive but practical pruning strategies (upper-bound interval, dominance-based) and prioritization heuristics to accelerate search while maintaining feasibility guarantees. Successors include both spatial transitions and explicit wait actions, required for adequate handling of G, F, and compositional formulas.
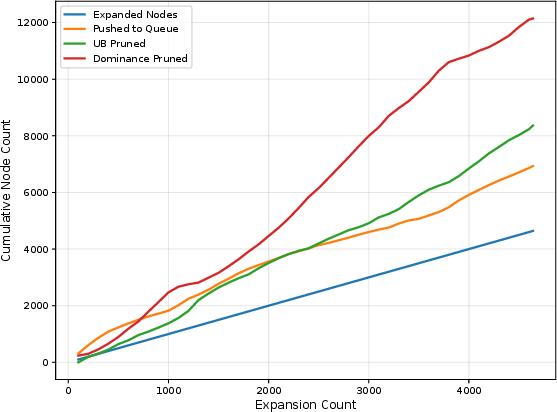
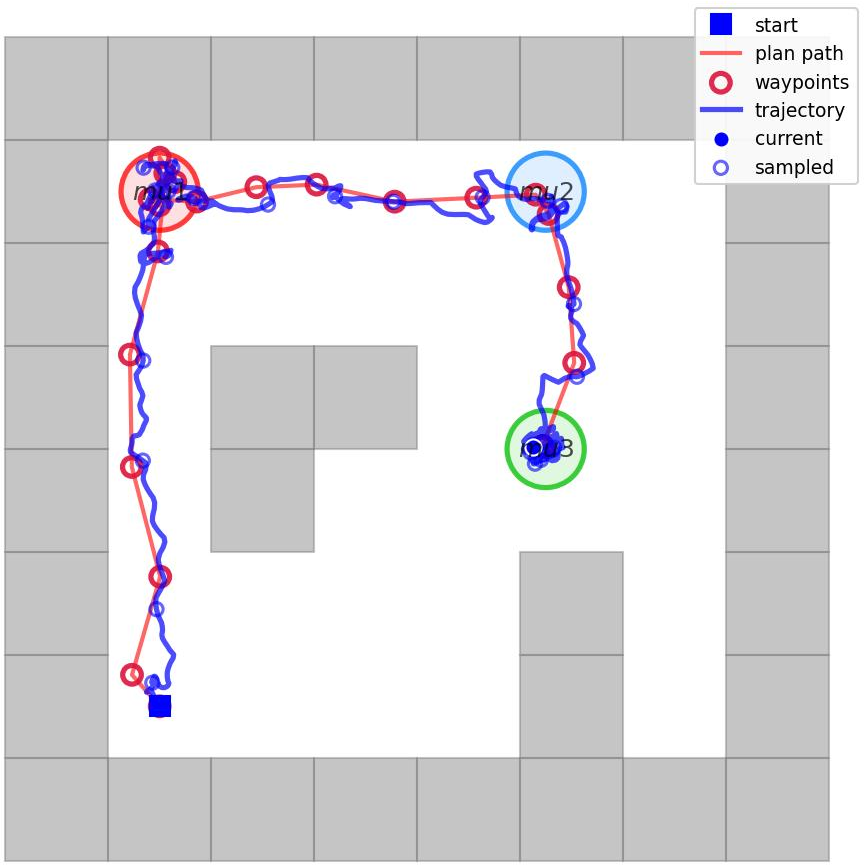
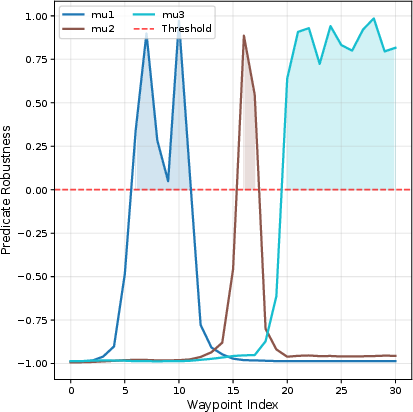
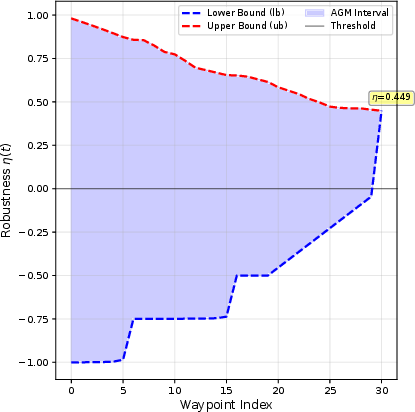
Figure 2: Planning statistics demonstrating the effectiveness of incremental robustness and dominance-based pruning for a nontrivial STL specification.
Experimental Results
GraSP-STL is evaluated in the high-dimensional AntMaze environment from OGBench [park2025ogbench], featuring an 8-DoF quadruped navigating complex mazes under diverse, randomly instantiated STL specifications (12 templates, 2400 tasks). The offline dataset consists of 10,000 task-agnostic trajectories.

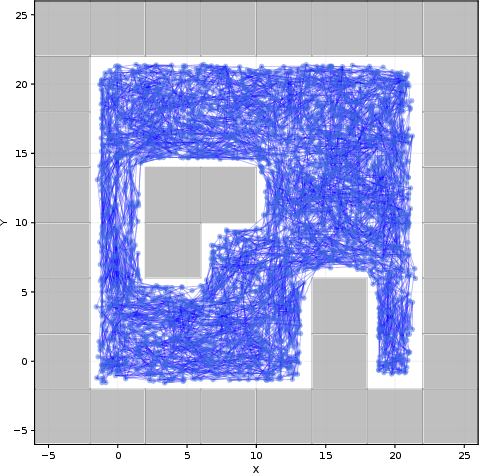
Figure 3: The test environment, displaying the spatial structure and state-space coverage critical for evaluating STL task satisfaction.
GraSP-STL delivers high planning and execution success rates across all specification classes, with overall PSR (planning success rate) of 95.58% and ESR (execution success rate) of 81.58%. Planning remains tractable with mean computation times under 10 seconds even for temporally and logically complex cases (e.g., nested or branching STL templates). The average waypoint following error remains at 0.5 units, indicating tight low-level execution alignment.
Strong STL robustness is shown on advanced tasks involving nested and branching temporal operators (e.g., GF, multi-goal sequencing, persistence). The search procedure demonstrates effective frontier reduction through pruning/heuristics, enabling synthesis in high-dimensional, long-horizon scenarios. A salient limitation remains in tasks requiring persistence (G) with tight time windows, where both planning and execution rates degrade due to compounded reachability constraints and minimal slack.
Practical and Theoretical Implications
The principal theoretical implication is the demonstration that STL-based planning with formal satisfaction guarantees is achievable in a fully model-free, offline-only regime. The combination of reusable reachability structure learning and graph-based abstraction enables compositional, zero-shot generalization to arbitrary temporal logic formulas—contrasting with prior RL and end-to-end methods that are task-bound or lack traceability/interpretablity.
On the practical side, GraSP-STL offers a scalable approach for synthesizing complex behaviors in robotic or cyber-physical systems where system models are unavailable and online experimentation is costly or unsafe. The explicit use of STL robustness enables traceable verification and diagnosis of plan infeasibility, critical for safety-critical deployment.
Future Directions
Potential future work includes integrating slack-aware optimization to handle excessive temporal tightness, adaptive graph refinement to improve execution robustness, and extending the method to multi-agent and uncertainty-quantified settings. The approach is amenable to integration with higher-fidelity simulators and richer observation spaces (e.g., raw perception), provided that sufficient offline coverage is available. The use of alternative logic robustness semantics (beyond AGM) or more expressive abstraction methods (hypergraphs or neural planners) presents further research avenues.
Conclusion
GraSP-STL establishes a graph-based, zero-shot framework for STL-constrained planning grounded in offline goal-conditioned RL and formal interval robustness. The approach demonstrates strong empirical results on challenging, long-horizon STL tasks, combining tractable search, effective abstraction, and robust execution. The modularity of the framework positions it as a compelling foundation for future research in formally-specified, data-driven sequential decision making under minimal assumptions.

