- The paper introduces a lightweight Bayesian approximation that leverages a first-order Taylor method with an isotropic parameter covariance to quantify neural network uncertainty.
- It decomposes uncertainty into epistemic and aleatoric components, validating the squared gradient norm as a scalable and efficient proxy on synthetic and NLP tasks.
- The approach is up to two orders of magnitude faster than traditional uncertainty estimation methods, though calibration remains architecture-dependent.
Efficient Uncertainty Quantification in Neural Networks via Isotropic Gradient Norms
Introduction and Motivation
The paper "An Isotropic Approach to Efficient Uncertainty Quantification with Gradient Norms" (2603.29466) addresses the challenge of decomposing and quantifying predictive uncertainty in neural networks, especially in LLMs, without access to original training data or computationally expensive techniques. The approach targets the separation of aleatoric uncertainty (arising from irreducible label ambiguity) and epistemic uncertainty (due to parameter uncertainty), both of which are central in safety-critical applications demanding calibrated model trust.
The key innovation is a lightweight Bayesian approximation leveraging a first-order Taylor (delta) method with an isotropic parameter covariance assumption. This eliminates the need for ensembles, Monte Carlo sampling, or Hessian/Fisher Information Matrix computation over unavailable training data. Both uncertainty types can be accessed with a single forward-backward pass through an unmodified, pretrained model.
Methodology
Taylor Expansion and Isotropy
The predictive distribution p(y∣x,θ) is linearized around the parameter estimate θ∗:
p(yc∣x,θ)≈p(yc∣x,θ∗)+g⊤(θ−θ∗)
with g=∇θp(yc∣x,θ)∣θ∗. Consequently, the epistemic variance reduces to g⊤Cov[θ]g. Under the isotropy approximation, Cov[θ]≈I, yielding epistemic uncertainty as the squared gradient norm ∥g∥2.
Aleatoric uncertainty, via Taylor expansion on the Bernoulli variance p(1−p), further reduces to the variance under the point estimate.
Justification for Isotropy
One major theoretical contribution is a systematic justification for the isotropy assumption, which is often considered an oversimplification. The paper shows that using proxy data to estimate parameter covariance introduces structured, dataset-dependent distortions. Empirical results on both synthetic and NLP tasks confirm that proxy Hessians overfit their respective proxy-support domains, yielding spatially asymmetric uncertainty patterns, while the identity maintains symmetry.
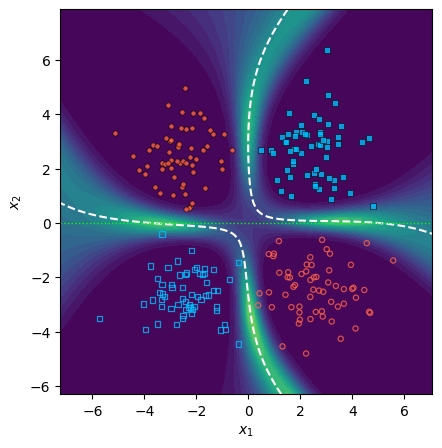
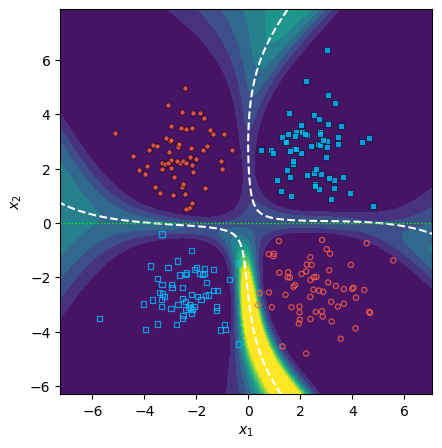
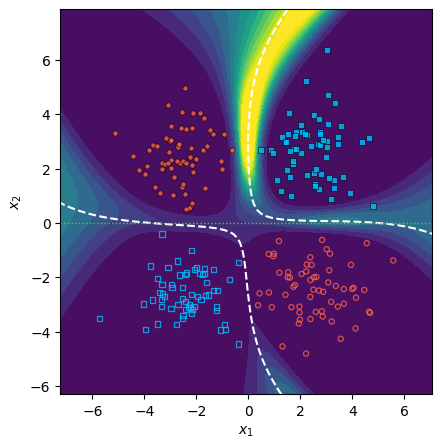
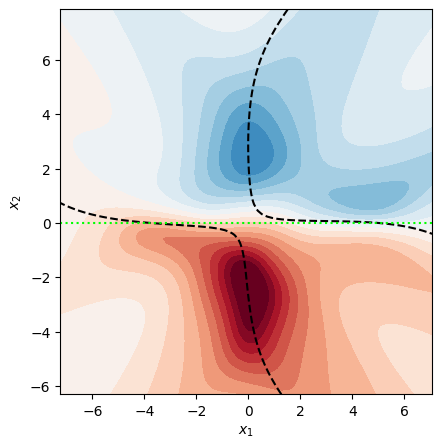
Figure 1: Epistemic uncertainty under identity covariance (C=I) respects task symmetry compared to proxy Hessian estimates.
Further, large model Hessian spectra are dominated by a bulk near zero, such that the damped inverse Hessian is essentially proportional to I as width increases—a phenomenon confirmed by recent spectral and influence function analyses.
Empirical Evaluation
Synthetic Validation and Scaling
On synthetic classification and regression tasks, the squared gradient norm tracks Monte Carlo ground-truth uncertainty with high rank correlation for classification (Spearman θ∗0 to θ∗1), with correspondence improving at larger model scales. These results confirm that the isotropy-induced error diminishes with parameter count, aligning with theory.
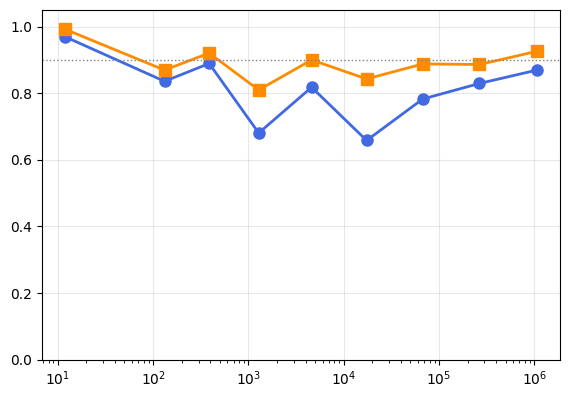
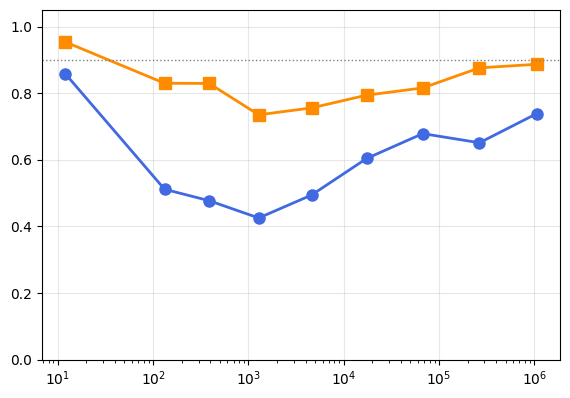
Figure 2: Spearman correlation between the gradient norm estimate and true epistemic uncertainty increases with model size.
For regression, where the posterior is often more anisotropic, the approach is less accurate, and Laplace approximations outperform the isotropic gradient norm.
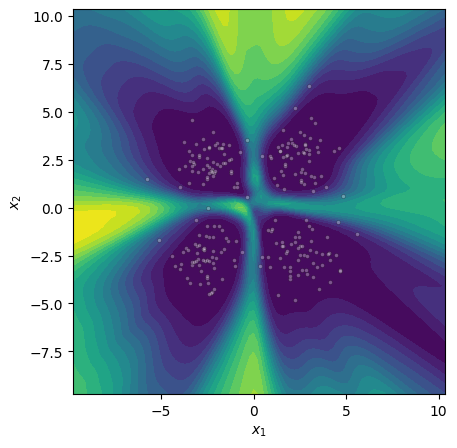
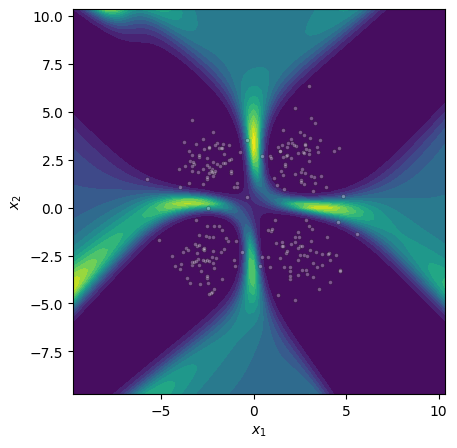
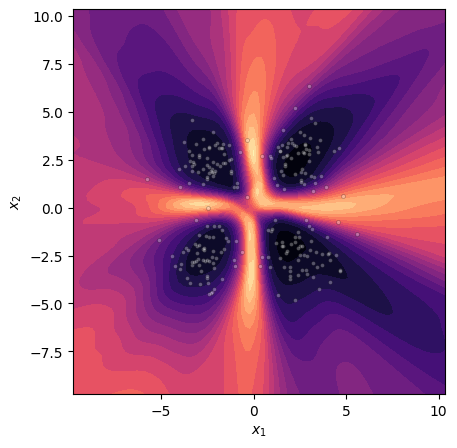
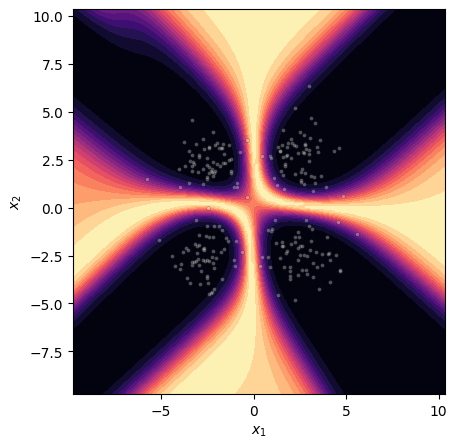
Figure 3: Visualization of Bayesian epistemic uncertainty (MCMC reference) in a synthetic setting.
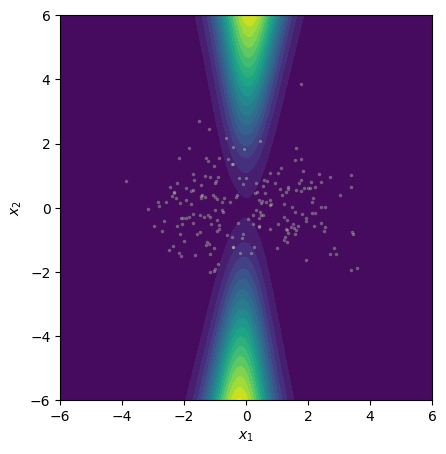
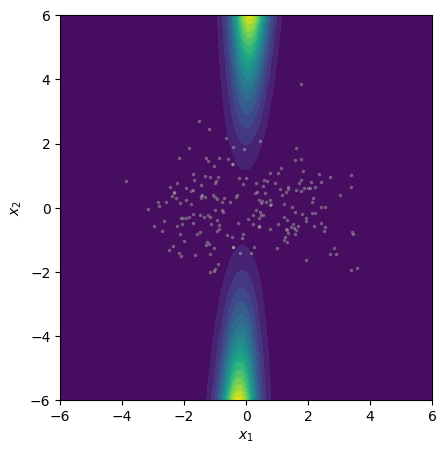
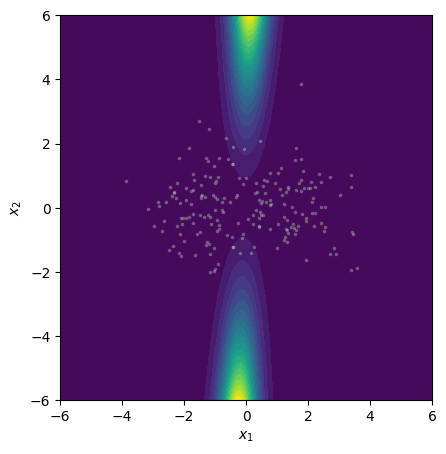
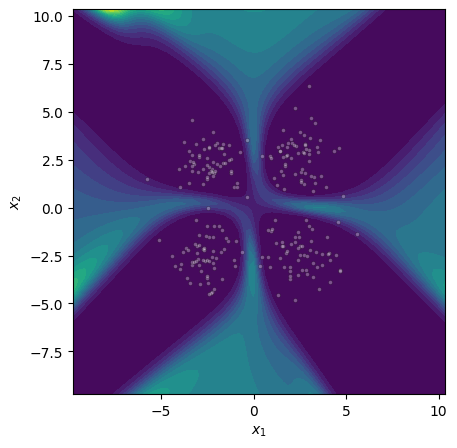
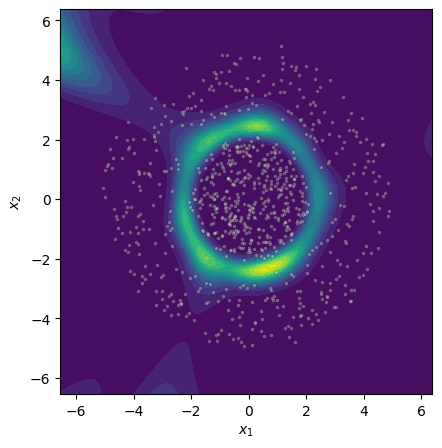
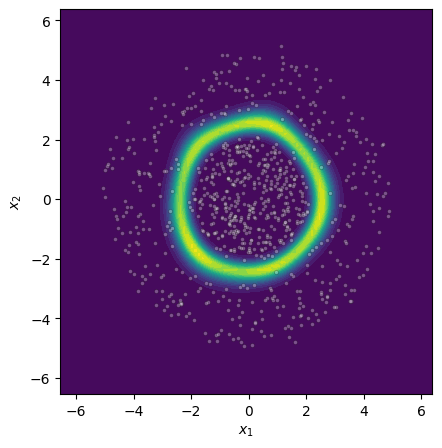
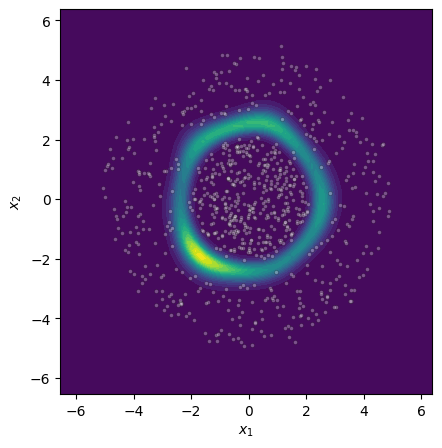
Figure 4: Epistemic uncertainty for three binary classification tasks; MCMC, gradient norm, and Laplace approximations show strong visual concordance on linear and nonlinear benchmarks.
Downstream QA: Correctness Prediction
In question answering with LLMs, the paper finds that epistemic and aleatoric uncertainty signals have benchmark-dependent utility for correctness prediction:
- On TruthfulQA, which involves inherent ambiguity and epistemic conflict, the combined uncertainty estimate yields the highest mean AUROC (0.63) across four models, outperforming entropy and self-assessment baselines.
- On TriviaQA, focused on factual recall, the combined gradient-based signals fall to chance, while model self-assessment outperforms other approaches.
This dichotomy highlights that parameter uncertainty ("epistemic") encodes signals fundamentally distinct from token-level entropy-based self-assessment. Notably, the gradient-based approach is up to two orders of magnitude faster than entropy-based or self-assessment methods, requiring only a single backward pass after generation.
Theoretical Implications
This work re-frames the uncertainty estimation problem for LLMs by favoring the epistemic-aleatoric variance decomposition and showing that, at realistic (billion-scale) model widths, the identity covariance is well-justified both theoretically and empirically. The argument generalizes recently popular heuristics for training influence estimation, out-of-distribution detection, and data pruning, all of which are shown to perform well under similar isotropy assumptions.
Practical Impact and Limitations
The method offers a computationally efficient pathway to uncertainty quantification in very large neural models without the need for modifications, retraining, or access to training corpora. However, the absolute magnitude of the squared gradient norm is architecture-dependent and not readily interpretable across models. The isotropy assumption is least precise at intermediate scales or in highly anisotropic posterior settings, and downstream calibration transfers poorly between models; any thresholding or ranking must be tailored per-architecture.
Future Directions
Potential developments involve relaxing the isotropy assumption via structure-aware normalizations when sufficient model or corpus information is available or integrating these principled uncertainty estimates in downstream applications like OOD detection, selective prediction, trust calibration, and safety mitigation strategies for LLMs. Further work is needed on robust cross-model calibration and expanded empirical study in more diverse, real-world NLP tasks.
Conclusion
The paper provides a formal, validated, and computationally practical method for epistemic and aleatoric uncertainty quantification using gradient norms under an isotropic assumption (2603.29466). The method demonstrates strong agreement with Bayesian reference estimates, scalability to large models, resilience to data availability gaps, and clear delineation of the regimes and limitations in which parameter-level uncertainty is informative. This work sets a foundation for efficient uncertainty estimation in contemporary large-scale neural modeling, especially LLMs, where classical Bayesian and Hessian-based methods are infeasible.

