- The paper introduces GazeCLIP, integrating semantic gaze priors with adaptive language prompt refinement to boost deepfake attribution and detection.
- It employs a multimodal pipeline combining visual perception, gaze-aware encoding, and language refinement to robustly handle unseen forgery methods.
- Experimental results show a 6.56% increase in attribution accuracy and a 5.32% boost in detection AUC, demonstrating its superior performance over state-of-the-art approaches.
GazeCLIP: Gaze-Guided CLIP with Adaptive-Enhanced Fine-Grained Language Prompts for Deepfake Attribution and Detection
Introduction and Motivation
The proliferation of high-fidelity generative models, particularly GANs and diffusion models, has led to rapidly increasing sophistication in face image manipulations (“deepfakes”), complicating the tasks of deepfake attribution (DFA) and detection (DFD). Traditional approaches for DFA and DFD demonstrate limited generalization to novel and advanced forgery techniques, principally due to their reliance on narrow visual cues and coarse-grained vision-language interactions. The integration of more fine-grained and semantic-level priors is necessary to advance the robustness and generalizability of forensics systems.
The GazeCLIP framework proposes a new direction at this intersection: the explicit incorporation of semantic gaze priors and adaptive fine-grained language prompt engineering within a CLIP-based vision-LLM, yielding strong improvements in both deepfake attribution and detection under open-world conditions with unseen forgeries. The method capitalizes on the finding that gaze reconstruction artifacts are not uniformly distributed across generative models, and that gaze trace distributions carry source-specific information valuable for both attribution and authenticity prediction.
GazeCLIP Architecture
GazeCLIP synergistically unites three novel modules: the Visual Perception Encoder (VPE), Gaze-Aware Image Encoder (GIE), and Language Refinement Encoder (LRE), operating over image, language, and gaze modalities for robust DFAD.
Visual Perception Encoder
The VPE is responsible for extracting both appearance and discriminative gaze features from the input facial image. Utilizing a frozen pre-trained ETH-XGaze estimator, the model observes significant FID (Fréchet Inception Distance) distributional differences between real and fake gaze vectors; diffusion models, in particular, yield gaze distributions closer to natural images than GANs.

Figure 1: Gaze-sensitive prior distributions display generator-dependent discrepancies, with higher FID scores reflecting increased divergence between real and synthesized gaze vectors across GAN, diffusion, and flow models.
The VPE architecture aggregates these gaze vectors with learned appearance tokens through a dedicated transformer (AGPM), yielding high-level and generative-source-sensitive embeddings that serve as robust priors for downstream tasks.
Gaze-Aware Image Encoder
The GIE modulates the standard frozen CLIP image transformer by introducing a novel Gaze Injector (GI) module, which integrates gaze-aware information with global image tokens. Only the global “class” token is used as a query to reduce computational overhead, and LoRA-based parameter-efficient adaptation is injected at selected transformer blocks to optimize transfer to the specific DFAD domain.
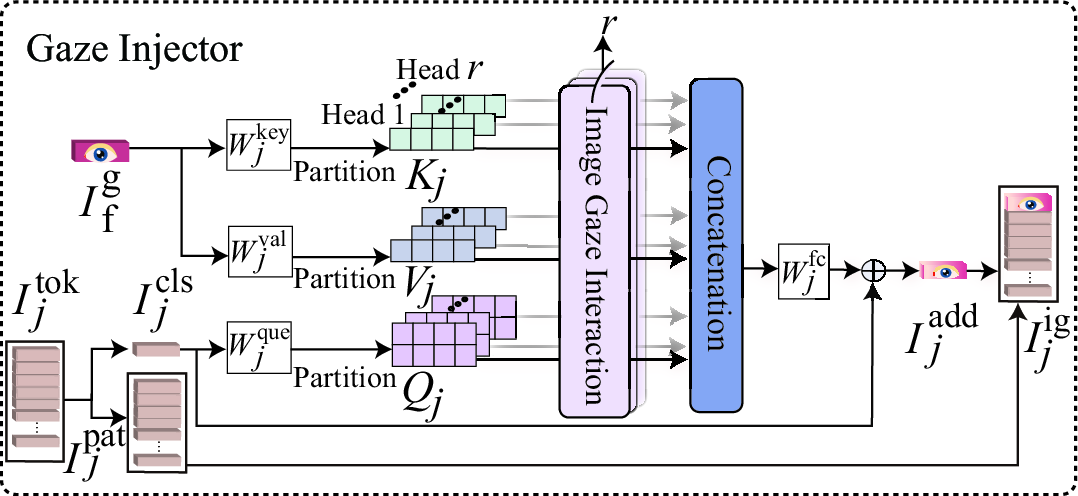
Figure 2: The gaze injector fuses only the global image class token with gaze features, efficiently propagating gaze-semantic information into the CLIP image backbone.
The joint image-gaze representations capture both global manipulations and subtle semantic details induced by generator artifacts, reflecting the conjecture that gaze priors enhance the generalization capacity of vision-LLMs in forensics tasks.
Language Refinement Encoder
Standard CLIP only leverages fixed prompt tokens; GazeCLIP introduces an LRE with an Adaptive-Enhanced Word Selector (AWS), a plug-and-play diagonal attention module that allows dynamic word-level weighting for fine-grained prompt refinement. The AWS is inserted before the self-attention mechanism in the transformer, as ablation indicates this maximizes improvements in attribution and detection accuracy.
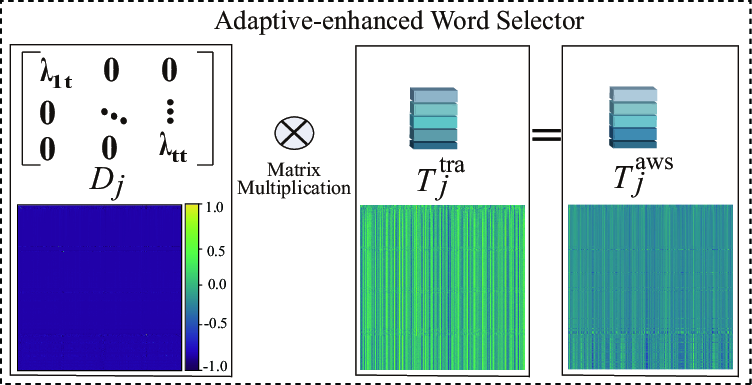
Figure 3: AWS dynamically emphasizes informative word-level embeddings, supporting precise and context-aware vision-language alignment.
This mechanism enables the model to prioritize high-value semantic cues for unseen generative methods, mitigating generator-specific biases in both attribution and detection.
End-to-End Pipeline
Given a face image, GazeCLIP splits it into local patches and extracts associated fine-grained language prompts. The VPE and GIE extract global- and gaze-aware visual forgery features, respectively, while the LRE produces refined semantic embeddings. These features are integrated and fed through a joint DFAD expert, yielding both source attribution and real/fake predictions.
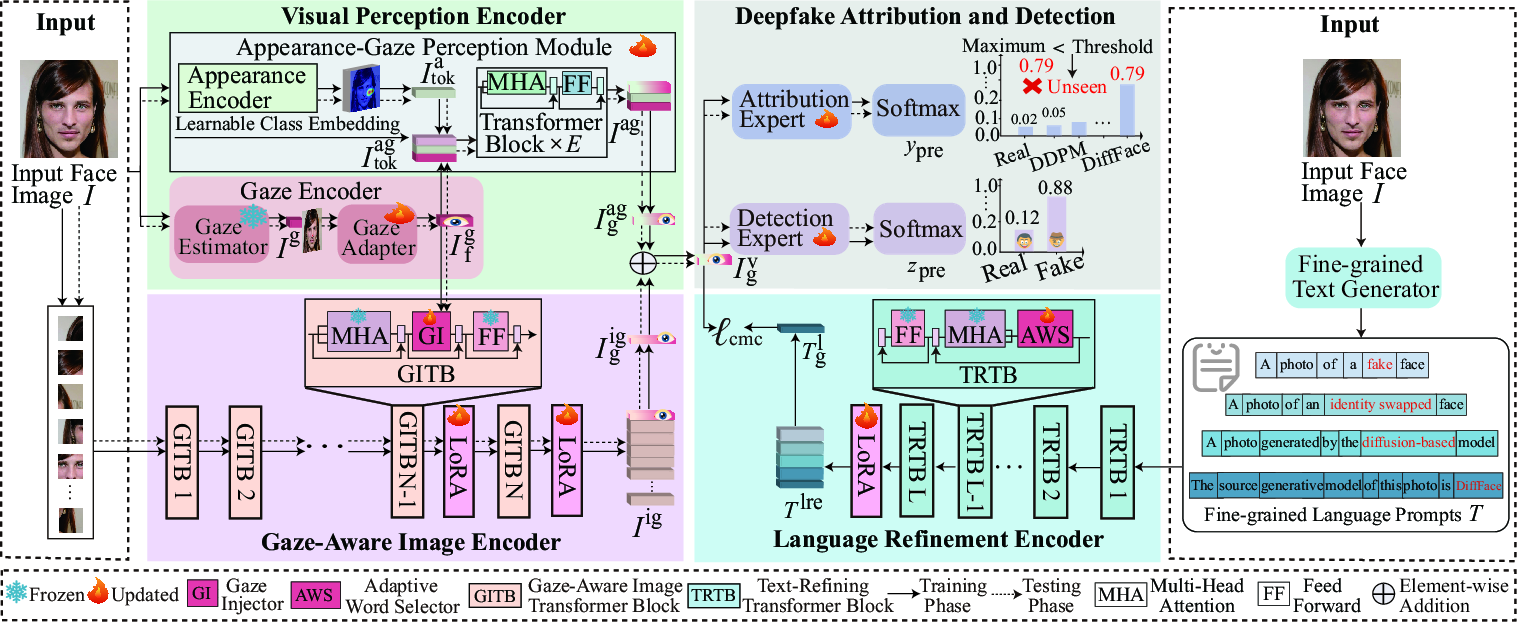
Figure 4: The full GazeCLIP workflow: faces are partitioned and passed through VPE (appearance/gaze), GIE (image-gaze fusion), and LRE (AWS-driven language), with cross-modal contrastive learning and DFAD expert heads.
Benchmark, Evaluation Protocol, and Results
A major contribution of this work is the introduction of a fine-grained, open-set DFAD benchmark. The dataset spans ≈20 GAN, diffusion, and flow-based forgers, with clear splits into seen/unseen generators, real, and manipulated categories. The benchmark enforces generalization, requiring models to attribute and detect images from never-before-seen methods.
Experimental results demonstrate that GazeCLIP outperforms vision-only, standard CLIP, and state-of-the-art forensics/attribution methods by a considerable margin; for example, GazeCLIP improves attribution accuracy (ACC) by 6.56% and detection AUC by 5.32% over the previous leading approach on average. Notably, its performance advantage holds across robust evaluation settings with non-trivial in-the-wild and highly manipulated images.
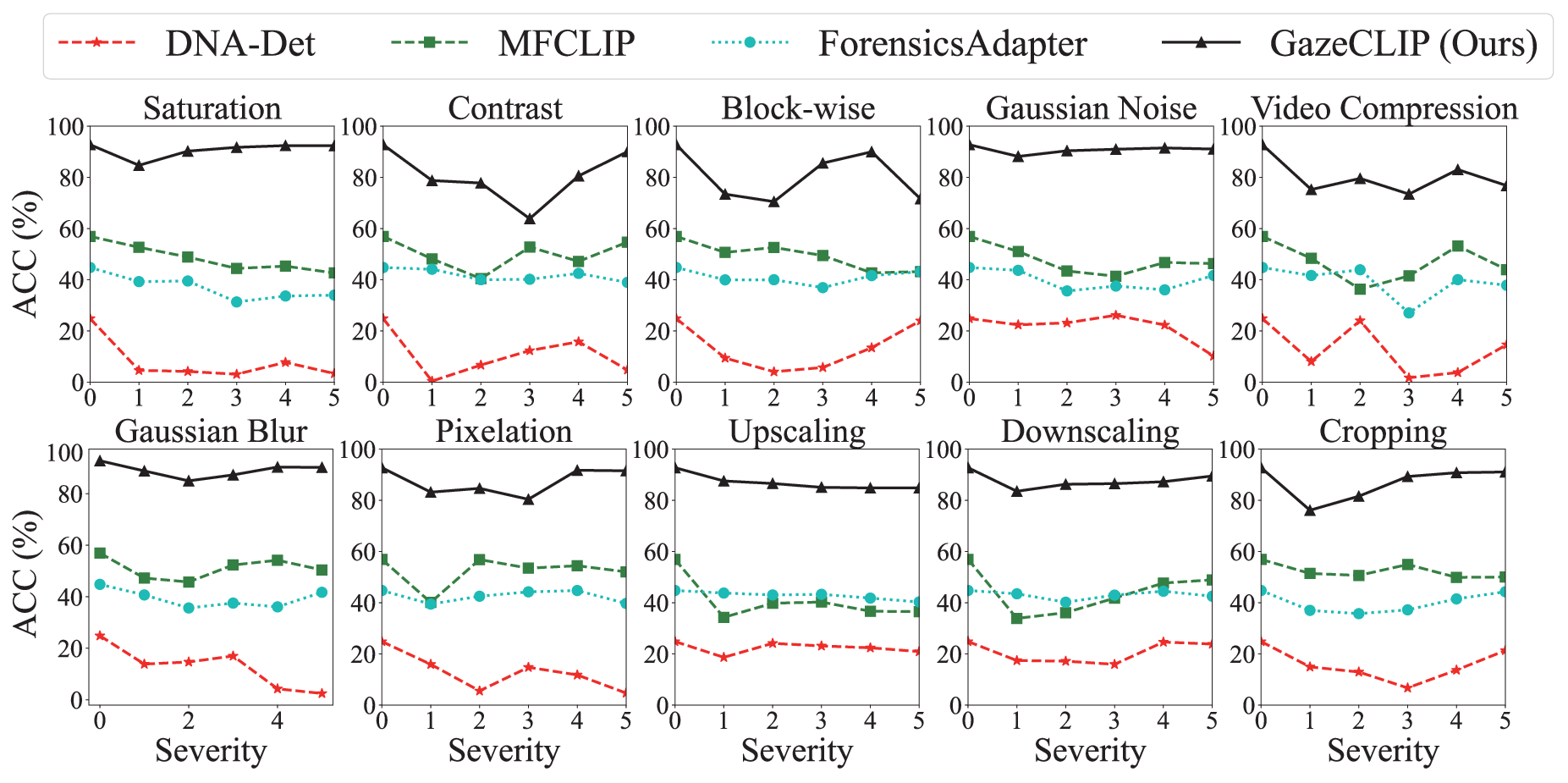
Figure 5: GazeCLIP exhibits marked robustness across increasing levels of input distortion in unseen datatypes, outperforming prior models on multiple perturbation types.
In ablation studies, the gaze-aware prior and AWS modules consistently yield double-digit improvements in attribution and detection ACC. The ETH-XGaze estimator is shown to produce discriminative, source-sensitive vectors compared to alternatives. Furthermore, prompt and feature visualizations indicate superior generator differentiation and clustering capacity when adaptive language and gaze priors are present.

Figure 6: Grad-CAM visualizations illustrate GazeCLIP’s (bottom row) improved coverage of manipulated facial regions relative to vanilla CLIP (middle row).
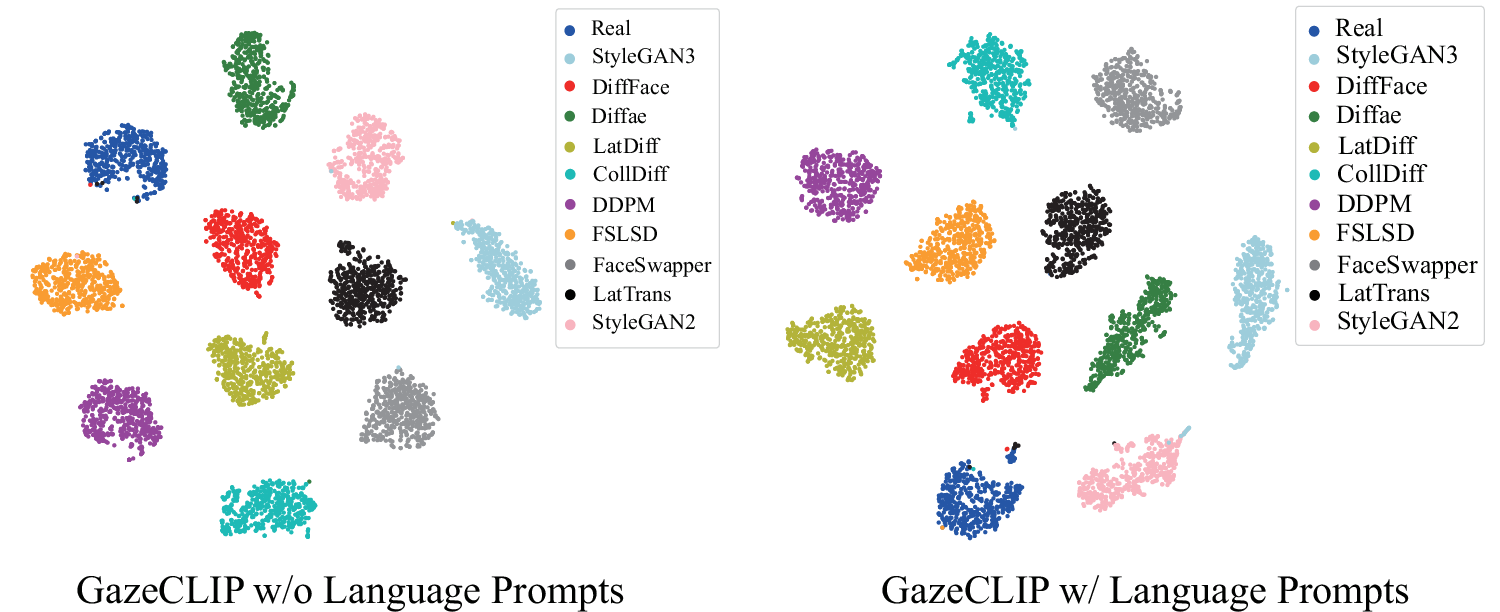
Figure 7: t-SNE projections reveal the increased inter-generator separation achieved with fine-grained language prompts.
Architectural Tradeoffs and Practical Considerations
GazeCLIP introduces a moderate overhead in parameter count and computational cost due to the added AWS and gaze pathways but remains within the bounds of efficient inference, maintaining 200M parameters and acceptable FLOPs for real-world deployment. LoRA adaptation ensures the majority of weights remain frozen, preventing catastrophic forgetting and promoting stable transfer even as new generator domains emerge.
Ablations reveal that placing AWS before self-attention, using only the global class token in the gaze injector, and leveraging multi-level text prompts cumulatively enhance robustness and attribution accuracy. The interplay between attribution and detection modules is also characterized: strengthening attribution improves detection, a nontrivial observation that has implications for future DFAD architectures.
Theoretical and Practical Implications
GazeCLIP’s results substantiate three major theoretical claims:
- Semantic gaze priors serve as highly transferable, generator-sensitive features, improving out-of-distribution detection and source tracing even in challenging real-world conditions.
- Fine-grained, AWS-driven language prompt engineering is critical to aligning vision-LLMs to domain-specific forensics tasks, surpassing traditional static prompt design.
- The joint handling of DFA and DFD under a unified framework introduces a synergy—attribution aids detection—which was underexploited in prior models.
Practically, GazeCLIP provides a blueprint for hybrid visual-semantic forensics, justifying further multimodal modeling for robust, future-proof detection and attribution, particularly as generative models become ever more adept at suppressing low-level artifacts.
Speculation and Future Research Directions
GazeCLIP paves the way for the automation of forensic prompt design (potentially with LLM-based controllers) and the broader fusion of physiological priors (pose, blink patterns, micro-expressions) in vision-LLMs. As deepfakes evolve towards semantic-level fidelity, future attribution and detection systems must transcend pixel- or frequency-based fingerprints, leveraging robust priors derived from the very nature of photorealism and perceptual invariants.
Further investigation of automated prompt discovery, cross-domain gaze/physiology modeling, and lightweight knowledge distillation for efficient deployment are natural continuations. Complementary use of anomaly detection and continual learning may further insulate systems against highly novel forgery attacks.
Conclusion
GazeCLIP introduces a principled, multimodal approach for deepfake attribution and detection, demonstrating that integrating gaze priors and adaptive fine-grained language prompts provides state-of-the-art generalization and robustness on new benchmarks. This work sharply redirects the trajectory of robust forensics from texture-level cues to high-level semantic and physiological representations, offering both empirical gains and conceptual advances for open-world attribution and detection research.

