- The paper demonstrates a scalable, bilingual AI teaching assistant leveraging a retrieval-augmented generation pipeline to support coding education in Africa.
- It integrates fine-tuned Sentence-BERT, ElasticSearch, and GPT-4 synthesis with strict pedagogical constraints to provide context-aware hints and suggestions.
- Evaluation shows an overall 85.7% accuracy with high community acceptance, underscoring the benefits of human oversight in AI-driven educational platforms.
Kwame 2.0: Human-in-the-Loop Generative AI Teaching Assistant for Scaling Coding Education in Africa
System Architecture and Technical Approach
Kwame 2.0 embodies a retrieval-augmented generation (RAG) pipeline integrating sentence-level semantic search and LLM-based answer generation, tailored for bilingual (English–French) support within the SuaCode mobile coding platform targeting African learners. The system leverages fine-tuned Sentence-BERT embeddings for content retrieval and ElasticSearch for top-k passage selection, using cosine similarity to match student queries with relevant course material. These retrieved passages—including lesson notes, code snippets, and attached images—serve as contextual input for GPT-4-driven answer synthesis. All responses cite the source materials to ground answers and mitigate hallucination risks intrinsic to LLMs.
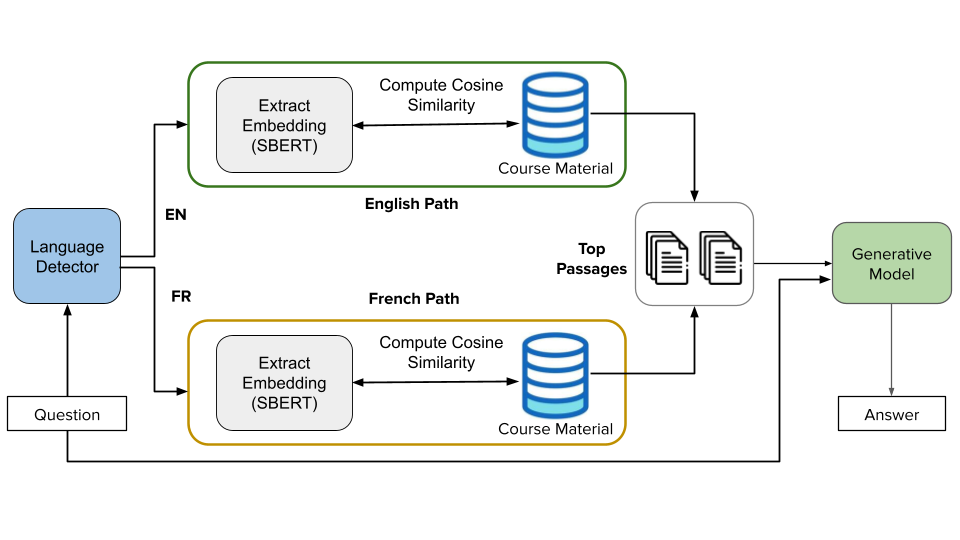
Figure 1: Architecture of Kwame 2.0 illustrating integration of RAG components—language detection, embedding computation, passage retrieval, and generative answer synthesis.
Prompt engineering forms another technical cornerstone: the system is explicitly restricted to providing hints and suggestions, avoiding direct code solutions to preserve pedagogical efficacy and deter academic dishonesty. The prompt formulation is depicted below.
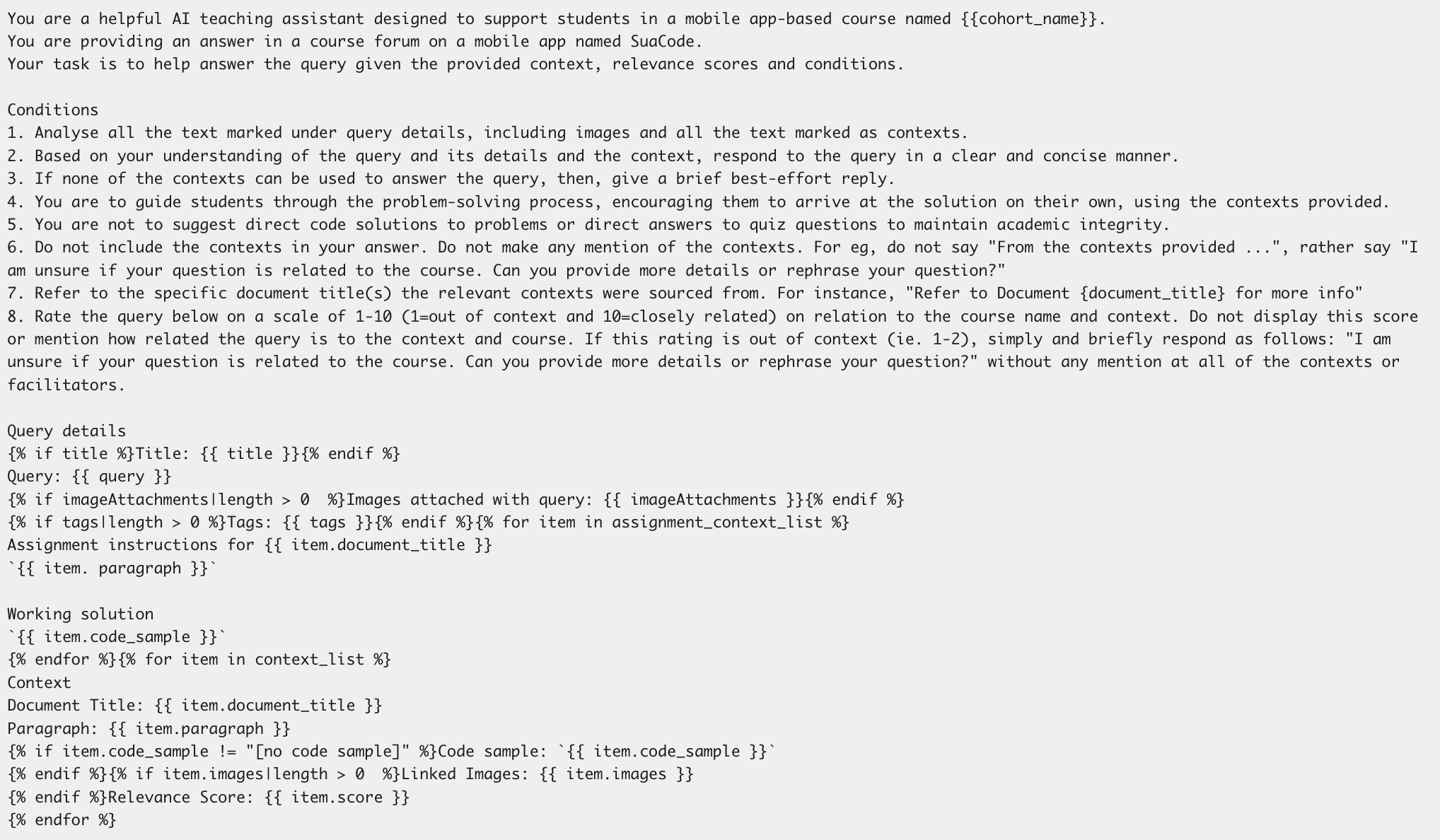
Figure 2: Prompt for Kwame 2.0 enforcing response constraints and contextual citation requirements.
Personalization is an implicit emergent property, as Kwame 2.0 delivers tailored replies to learner introductions, enhancing perceived engagement despite absence of explicit onboarding design. System responses are published in cohort-specific forums, enabling community-driven oversight, upvoting, and answer acceptance workflows.
Deployment and Operational Context
Kwame 2.0 was deployed as a forum-based facilitator across 15 monthly SuaCode cohorts from October 2024 to December 2025, encompassing 3,717 enrollments from 35 African countries. The deployment context featured cohort-level community forums where the AI teaching assistant, facilitators, and learners collaboratively addressed queries. Human-in-the-loop supervision safeguards the learning process: while Kwame 2.0 provides rapid answers, facilitators and peers moderate content quality, supply missing information, and correct errors. This hybrid model capitalizes on AI scalability and latency advantages while maintaining reliability through human expertise.
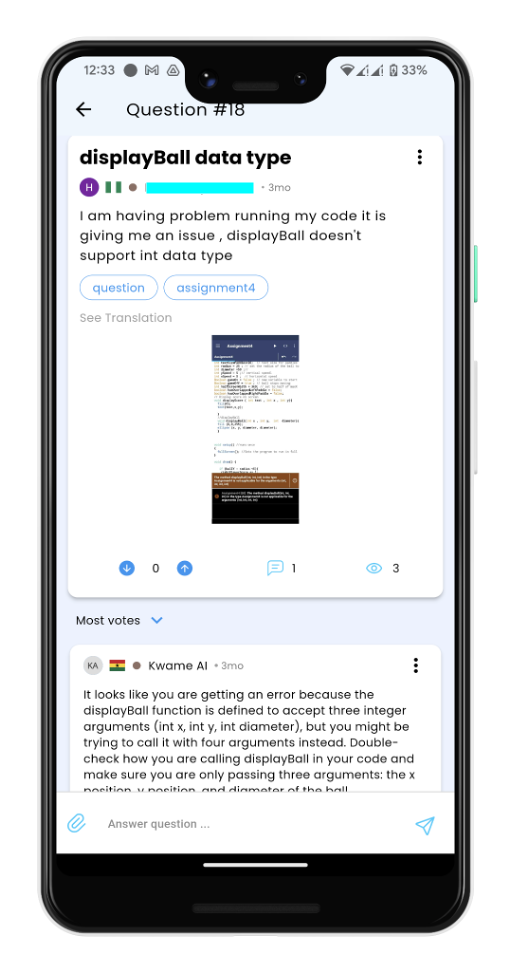
Figure 3: Screenshots of Kwame 2.0 operating within the SuaCode course forum, displaying bilingual engagement and community interaction.
Evaluation and Empirical Metrics
A rigorous evaluation spanned quantitative community ratings and expert-driven accuracy annotation. Helpfulness was assessed by upvotes/downvotes and accepted answers in the forum; expert evaluation categorized questions as curriculum or administrative and judged AI responses for correctness.
Kwame 2.0 demonstrated high accuracy on curriculum questions: 97.6% correctness, compared to 46.9% for administrative queries. This discrepancy originates from gaps in indexed administrative information. Overall, 76.7% accuracy was achieved on valid questions, with human participants compensating for AI shortcomings—38.6% of incorrect or missing AI answers were subsequently resolved by facilitators or learners. Aggregate accuracy for combined AI and community responses reached 85.7%. Notably, most accepted forum answers (83.3%) were provided by Kwame 2.0, and the majority of upvoted responses (69%) stemmed from the AI assistant.
Kwame 2.0's instantaneity and coverage for curriculum content produced consistently high-quality support, while the forum's human-in-the-loop architecture eliminated common LLM failure modes on administrative issues. The results establish that a RAG-based generative TA can deliver substantial assistance in resource-constrained environments with minimal latency, provided human oversight to resolve persistent AI gaps. These empirical outcomes underscore the synergistic effectiveness of AI-human cooperation, especially in regions lacking teaching staff infrastructure.
Practical and Theoretical Implications
Kwame 2.0's deployment validates the feasibility of scaling individualized, bilingual AI-driven coding support across diverse African contexts. The integration of retrieval-augmented generation with human-in-the-loop workflows is shown to be effective for mitigating inaccuracies inherent in LLMs. In practice, such systems may substantially reduce dropout rates, democratize coding education, and build sustained engagement in regions with limited access to expert human facilitators.
From a theoretical standpoint, the results further the argument for hybrid pedagogical models combining generative AI and social/cognitive scaffolding via community oversight. The sharply differential accuracy on curriculum versus administrative queries highlights the necessity for dynamic, updatable knowledge indexing, and suggests future directions for combining administrative ontologies with LLM-driven interfaces.
Speculation on Future Developments
Prospective work includes qualitative studies on learner experience, evolving prompt strategies to further restrict undesired responses, and integration of automatic administrative information updates to bolster coverage on non-curricular questions. Long-term, the architectural paradigm introduced by Kwame 2.0 could generalize to other domains where scalable, reliable AI teaching assistance is required, particularly in settings characterized by low bandwidth, limited human oversight, and diverse linguistic requirements.
Conclusion
Kwame 2.0 represents a robust implementation of a RAG-based, bilingual AI teaching assistant, validated through longitudinal deployment in large-scale, resource-constrained African coding education contexts (2603.29159). The empirical evidence supports the efficacy of human-in-the-loop AI systems in maintaining high accuracy and rapid support, especially for curriculum-driven queries. The model significantly improves educational access and quality for underrepresented populations, establishing a pragmatic blueprint for future AI-enabled learning assistance in similar contexts.

