HISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Abstract: Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every historical key for each query through a lightweight indexer, then computing attention only on the selected subset. While the downstream sparse attention itself scales favorably, the indexer must still scan the entire prefix for every query, introducing an per-layer bottleneck that grows prohibitively with context length. We propose HISA (Hierarchical Indexed Sparse Attention), a plug-and-play replacement for the indexer that rewrites the search path from a flat token scan into a two-stage hierarchical procedure: (1) a block-level coarse filtering stage that scores pooled block representations to discard irrelevant regions, followed by (2) a token-level refinement stage that applies the original indexer exclusively within the retained candidate blocks. HISA preserves the identical token-level top-sparse pattern consumed by the downstream Sparse MLA operator and requires no additional training. On kernel-level benchmarks, HISA achieves up to speedup at 64K context. On Needle-in-a-Haystack and LongBench, we directly replace the indexer in DeepSeek-V3.2 and GLM-5 with our HISA indexer, without any finetuning. HISA closely matches the original DSA in quality, while substantially outperforming block-sparse baselines.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces HISA, a faster way for LLMs to find the most important parts of very long texts. When LLMs read long inputs (like a big book), they use “attention” to decide which earlier words matter for the next word. Checking everything is slow. Newer “sparse attention” methods speed things up by picking only a small set of important tokens (tiny pieces of text). But the step that chooses those tokens (called the indexer) still scans everything, which becomes very slow as the text gets longer.
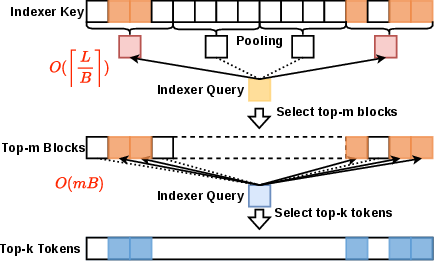
HISA fixes this by searching in two steps: first it quickly filters whole blocks (like chapters), then it looks closely at tokens (like pages) only within the promising blocks. This keeps the model’s final choices as precise as before, but makes the selection step much faster—without retraining the model.
The main questions the paper asks
- Can we make the token selection step much faster without changing which tokens are finally chosen for attention?
- Can we keep fine-grained (token-level) quality while avoiding scanning every single token?
- Can this work as a plug-and-play component that you can drop into existing models with no extra training?
How HISA works (in plain language)
Think of reading a very long book to answer a question.
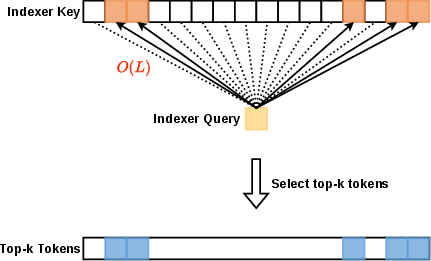
- Before (older method): For every question, you skim every page of everything you’ve read so far to find the best pages to revisit. That’s precise, but slow.
- HISA’s idea: 1) First skim chapter summaries to decide which few chapters are likely relevant. 2) Then, only within those chapters, skim the pages carefully to pick the top pages to read.
Translated to the model:
- Token: a tiny piece of text.
- Attention: the model “looking back” at earlier tokens to decide what matters next.
- Indexer: a quick scoring tool that estimates which tokens are worth attending to.
- Top‑k: pick the best k tokens.
HISA’s two stages:
- Block-level coarse filtering
- Split the long sequence into blocks (like chapters).
- Make a quick summary for each block (by averaging its “keys,” which you can think of as short vector summaries).
- Score these block summaries against the current question (query).
- Keep only the top m blocks that look most promising.
- Token-level refinement
- Now score individual tokens only inside those m blocks.
- Choose the final top‑k tokens from this smaller pool.
- The downstream attention uses exactly these k tokens—just like before.
Why this is faster: Instead of scoring all tokens every time, you score a small number of block summaries plus the tokens inside a few selected blocks. As the text gets longer, this saves a lot of work.
Important details:
- It’s plug‑and‑play: you don’t retrain the model or change how attention itself works.
- It preserves fine-grained choices: the final token list is still token-level, not block-level.
- It works best when the candidate capacity (m × block size) is at least k (so there are enough candidates to pick from).
What they tested and found
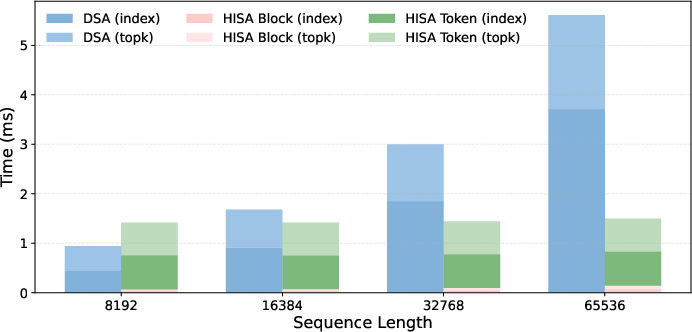
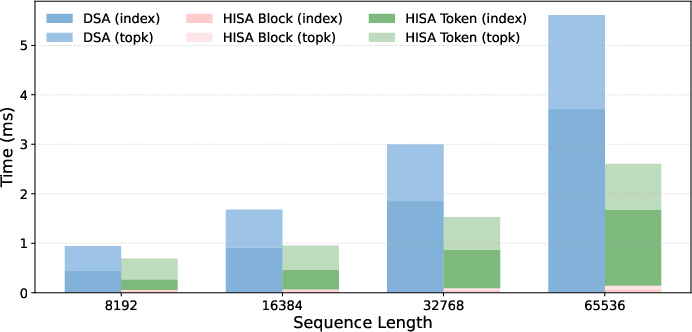
- Speed: In low-level (kernel) benchmarks, HISA sped up the indexing step by up to 3.75× at 64,000‑token contexts. That shows the indexer, not the attention computation itself, had become the bottleneck—and HISA removes much of that bottleneck.
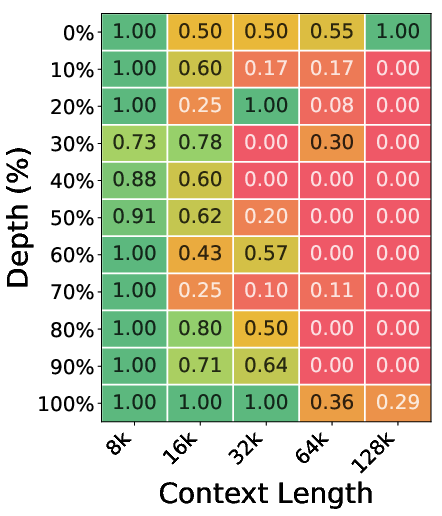
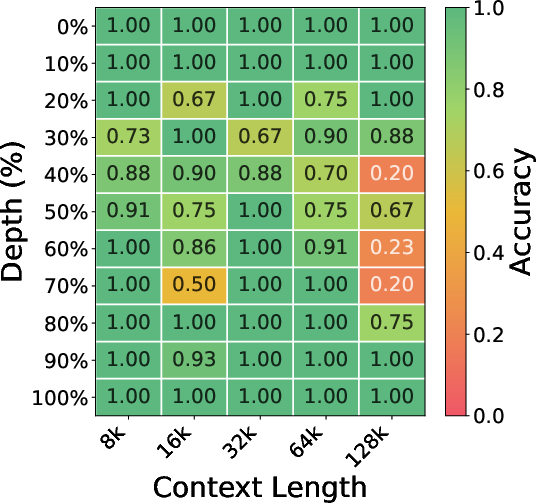
- Accuracy on retrieval tests (Needle-in-a-Haystack): They swapped in HISA for the indexer in two strong models (DeepSeek‑V3.2 and GLM‑5) without any extra training. HISA found the needed information almost as well as the original method across varying lengths and positions of the “needle.” It clearly beat simpler “block‑only” methods that don’t do token-level refinement.
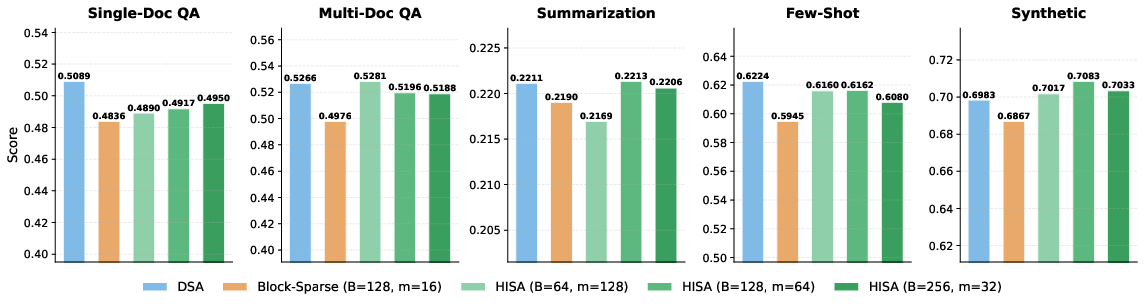
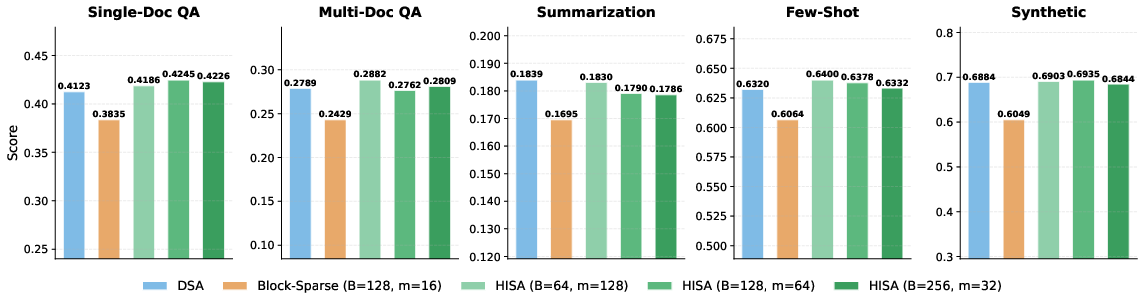
- Real tasks (LongBench): On a wide set of long‑context tasks (like question answering, summarization, few‑shot learning), HISA matched the original method’s quality closely and outperformed block‑only baselines—again with no fine‑tuning.
Why this matters:
- It keeps the careful, token-level selection quality that users want.
- It cuts down the most expensive part of long‑context processing.
- It works right away with existing models.
Why it’s important
LLMs are moving to extremely long context windows (128K to 1M tokens and beyond). With the old approach, the token-selection step (indexer) becomes as expensive as the attention itself. HISA changes the search path—chapters first, pages second—so the same quality is reached faster. That means:
- Lower latency (faster responses).
- Lower compute costs at long lengths.
- Better scalability for long documents, multi‑turn reasoning, and large inputs (code, books, long conversations).
Limitations and future directions (in simple terms)
- Block summaries can sometimes miss rare but important tokens (for example, if a block contains mixed topics). The authors suggest fixes like overlapping blocks, smarter pooling (like max instead of mean), or learning better block scorers during training.
- Integrating HISA into full production systems (with batching, speculative decoding, etc.) could bring even larger real‑world gains—this is future work.
Bottom line
HISA is a smarter, two-step way to find important tokens in very long inputs. It keeps the model’s precision, drops right into existing systems, and significantly speeds up the slowest part of sparse attention—all without retraining.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-up research.
- Absence of end-to-end serving benchmarks: no measurements of real throughput/latency under continuous batching, variable-length packed prompts, streaming decoding, or speculative decoding; results are limited to indexer kernel timings on a single GPU (A100).
- Limited hardware coverage: no evaluation on newer/datacenter (H100/B200/MI300) or consumer GPUs, nor CPUs; unclear portability and efficiency on different memory hierarchies and compiler stacks beyond TileLang.
- Unquantified memory overhead: representative (pooled) keys are said to be “negligible,” but there is no accounting of extra memory, bandwidth, and update costs across layers/steps, especially during long decoding with growing KV caches and packed batches.
- No theoretical recall guarantees: there is no formal bound relating block-level scores to token-level recall (i.e., probability that HISA recovers the DSA top-k set) nor conditions on m and B to ensure equivalence with DSA.
- Claim of “identical sparse pattern” is unproven: while the abstract suggests identical top-k outcomes, the main text and experiments show small accuracy differences; precise conditions for equivalence and worst-case failure modes are not established.
- Pooling choice underexplored: only mean pooling is used; no ablations on max/attention-weighted pooling, robust statistics, learned aggregators, or multi-representative per block; impact on blocks that straddle semantic boundaries is not quantified.
- Fixed blocks vs. adaptive segmentation: blocks are fixed-size and causal; no study of overlapping windows, adaptive boundaries, or semantic segmentation to reduce cross-boundary information loss.
- Static hyperparameters: B and m are globally fixed; no adaptive per-layer/per-head/per-query budget allocation (e.g., entropy- or margin-based controllers) to trade speed for recall on the fly.
- Head-specific variability ignored: block selection is aggregated across indexing heads; no investigation of head-specific block filters or whether sharing a single coarse filter harms head-level specialization.
- Forced inclusion of first/last blocks unablated: always selecting these blocks may waste budget; effect on accuracy/latency and alternatives (e.g., learned/local windows) are not evaluated.
- Fragility in “many-blocks-few-tokens” regimes: when relevant tokens are thinly spread across many blocks, small m may miss them; no fallback strategies (e.g., dynamic m increase, second-chance rescue) or detection criteria are proposed.
- Decoding-time latency not reported: per-token end-to-end decoding latency and tail-latency distribution with long prefixes are not measured; interaction with KV growth and candidate maintenance cost is unclear.
- Layer-wise and depth-wise behavior: no analysis of which layers benefit most or suffer most from block pruning; no adaptive policies across layers or roles (e.g., early vs. late layers).
- Model coverage is narrow: only DeepSeek-V3.2 and GLM-5 are tested; generalization to different model sizes, training recipes (MHA, GQA, non-MLA attention), encoder/bi-directional settings, and domain-specialized LLMs is unknown.
- Task coverage is limited: outside Needle-in-a-Haystack and LongBench, there is no evaluation on other long-context suites (e.g., RULER, LV-Eval), long code generation, multi-hop reasoning, tool-use, or multi-turn agent traces.
- Multilingual and multimodal contexts: effectiveness is untested on non-English, mixed-language inputs, or interleaved modalities (e.g., images, audio tokens) where block semantics differ.
- Choice of k and budget trade-offs: experiments fix k=2048 (and a small set of candidate sizes); there is no systematic sweep of k, m, and B to map the quality–speed Pareto frontier across tasks and lengths.
- Interplay with other sparse methods: compatibility and compounding gains with cross-layer index reuse (IndexCache), block-sparse kernels (FlexPrefill/XAttention), or train-time sparse architectures (NSA/MoBA) are not explored.
- Robustness to precision/quantization: no results with FP8/INT8 KV/indexing keys or quantized block representatives; sensitivity to low-precision accumulation and activation choices (e.g., ReLU) is unknown.
- Packed-batch boundary handling: blocks may straddle sequence boundaries; aside from force-inclusion, there is no principled method to avoid cross-sequence contamination in pooled keys or to re-align blocks on boundaries.
- Update policy for pooled keys: incremental maintenance is asserted but not specified; frequency, amortized cost per token step, numerical drift, and synchronization with KV eviction/compaction are not analyzed.
- Formal complexity vs. realized speed: while asymptotic cost is reduced to O(L2/B + L m B), measured speedups are reported only up to 64K (kernel-level); scalability to 128K–1M with real workloads remains unverified.
- Safety/recall of rare but critical tokens: no metrics tracking “critical evidence miss” rates (e.g., factual needles, rare identifiers); per-query recall vs. DSA top-k is not reported (commented-out IoU analysis suggests this but is not included).
- Training-aware HISA left open: joint training of the block scorer (or pooled representations) to better align with token-level relevance is proposed but not implemented or evaluated.
- Interaction with local windows and sinks: how HISA complements fixed local windows/attention sinks or recency biases (e.g., QUEST, H2O) is not investigated; combined policies may alter optimal m/B.
- Memory/compute balance in MLA: only indexer latency is analyzed; end-to-end balance with Sparse MLA cost, gather/scatter overheads, and cache layout changes is not measured.
- Failure case diagnostics: no qualitative or quantitative analysis of queries where HISA diverges from DSA, nor guidance for detecting and mitigating such cases online.
- Reproducibility and release: it is unclear whether HISA kernels, configs, and evaluation scripts will be released for verification and extension by the community.
Practical Applications
Immediate Applications
These applications can be deployed now by swapping a DSA-style token indexer with HISA in long-context LLM inference stacks.
- LLM serving acceleration for long contexts (32K–128K+)
- Sectors: software/cloud, AI platforms
- What: Replace the DSA token indexer in deployments of DeepSeek‑V3.2 or GLM‑5 to reduce prefill latency and cost while preserving quality on long inputs (e.g., agentic reasoning, long-document QA).
- Tools/products/workflows: HISA kernel module (TileLang or Triton/TensorRT-LLM reimplementation), “HISA-enabled” vLLM/TGI plugin, KV-cache maintenance of block-level pooled keys, operational knobs for B (block size), m (top-m blocks), k (final tokens).
- Assumptions/dependencies: Model uses a DSA-like token-level indexer and Sparse MLA (or an equivalent token-indexed sparse attention); ensure mB ≥ k; end-to-end gains depend on the rest of the serving stack (continuous batching, sparse MLA implementation).
- Cost and energy reduction in production LLM APIs
- Sectors: cloud providers, MLOps/FinOps, sustainability
- What: Lower GPU-hours per request and carbon footprint for long-context endpoints without retraining.
- Tools/products/workflows: Throughput/latency dashboards that break down indexer vs attention time, autoscaling that adapts m by load, tokens-per-Joule reporting.
- Assumptions/dependencies: Kernel-level speedups translate to E2E only when sparse MLA and KV management are not dominant bottlenecks.
- Enterprise document understanding on lengthy artifacts
- Sectors: legal (eDiscovery, contract review), finance (10‑K/earnings), compliance/audit, government records
- What: Faster long-document QA/summarization by inserting HISA into existing LLM pipelines.
- Tools/products/workflows: “HISA mode” for long PDF/record processors; policy-compliant on-prem inference bundles.
- Assumptions/dependencies: Privacy-preserving deployments; benchmark parity holds on domain workloads; careful tuning of B, m for document lengths.
- Long-thread analytics and customer support
- Sectors: CX/CRM, customer success, service desks
- What: Summarize and reason over multi-thousand-message threads with reduced latency.
- Tools/products/workflows: Helpdesk copilots with HISA-backed inference; SLA policies that cap candidate budget (mB) for predictable latency.
- Assumptions/dependencies: Token budgets chosen to meet accuracy SLAs; continuous batching integration.
- Code assistants over large repositories
- Sectors: software engineering, devtools
- What: Improve responsiveness for repo-level QA, refactoring suggestions, and multi-file reasoning.
- Tools/products/workflows: IDE extensions with “long-context fast mode”; CI bots that run HISA-enabled checks across codebases.
- Assumptions/dependencies: Long-context model quality on code; repository chunking interacts well with block partitioning.
- Healthcare longitudinal summarization
- Sectors: healthcare/biomed
- What: Summarize years of EHR notes and labs with lower compute while maintaining fidelity.
- Tools/products/workflows: On-prem hospital LLM services with HISA; clinical note ingestion pipelines.
- Assumptions/dependencies: Domain-tuned LLMs; strict PHI security; confirm no quality regressions in safety-critical settings.
- Meeting, media, and multimodal transcripts
- Sectors: productivity, media
- What: Summarize multi-hour transcripts/scripts at lower cost.
- Tools/products/workflows: Meeting assistants with “hierarchical indexer” switch; batch post-processing of archives.
- Assumptions/dependencies: Current HISA is validated on text; multimodal use requires appropriate tokenization and pooling per modality.
- Academic long-context experimentation on limited budgets
- Sectors: academia, non-profits
- What: Run LongBench-/NIAH-style studies more cheaply; enable larger sweeps and ablations.
- Tools/products/workflows: Open-source HISA kernels, config recipes for B/m/k, reproducible evaluation harnesses.
- Assumptions/dependencies: Build/compile toolchain (TileLang/Triton) available; model architectures expose the indexer interface.
- Edge and low-memory GPU inference
- Sectors: edge/embedded, SMBs
- What: Make long-context features more feasible on L4/T4/A10G-class GPUs by cutting indexer overhead.
- Tools/products/workflows: Device-aware presets (smaller m at longer L), watchdogs that shrink m under load.
- Assumptions/dependencies: KV cache memory still scales with context; HISA does not reduce KV size.
- RAG pipelines that concatenate many retrieved chunks
- Sectors: search, knowledge management
- What: Keep long concatenated contexts tractable at inference time.
- Tools/products/workflows: RAG orchestrators with automatic HISA activation when prompt length exceeds a threshold; m tuned by number of chunks.
- Assumptions/dependencies: Retrieval quality remains primary driver; HISA optimizes compute, not retrieval ranking.
Long-Term Applications
These require further research, scaling, or engineering to be production-ready.
- Training-aware hierarchical indexers
- Sectors: AI model development
- What: Jointly learn block-level scoring, adaptive/overlapping block boundaries, or alternative pooling (max, learned attention) to reduce coarse-filter miss risk.
- Tools/products/workflows: Finetuning recipes that expose block scorers; distillation from flat indexers.
- Assumptions/dependencies: Access to training data and compute; ensure stability across layers and tasks.
- End-to-end serving integration at scale
- Sectors: cloud/serving systems
- What: Fuse HISA with continuous batching, speculative decoding, paged KV cache, and admission control for consistent tail latency at 128K–1M tokens.
- Tools/products/workflows: vLLM/TGI/TensorRT-LLM native operators; scheduler that co-optimizes m per request; telemetry for adaptation.
- Assumptions/dependencies: Careful scheduling to avoid regressions when other components dominate; extensive production A/B testing.
- Hardware co-design for hierarchical search
- Sectors: semiconductors, systems
- What: NPU/ASIC primitives for block pooling maintenance, block scoring, and fast top‑m/TopK; memory layouts that co-store pooled keys with KV.
- Tools/products/workflows: ISA extensions, fused kernels, on-chip reduction units for pooling; compiler support in TVM/Triton.
- Assumptions/dependencies: Vendor adoption; sufficient demand for long-context acceleration.
- Million-token and “lifetime memory” assistants
- Sectors: consumer apps, enterprise knowledge platforms
- What: Personal or organizational copilots that reason over persistent histories at million-token scales by hierarchical indexing.
- Tools/products/workflows: Sliding-window + HISA hybrids; dynamic m schedules over time; memory governance policies.
- Assumptions/dependencies: Robust quality at ultra-long contexts; storage and privacy controls; evaluation beyond NIAH/LongBench.
- Multimodal long-sequence processing
- Sectors: vision, speech, robotics, autonomous driving
- What: Apply hierarchical indexers to frames/clips (video), spectrogram chunks (audio), or trajectories (robotics) before token-level refinement.
- Tools/products/workflows: Modality-specific pooling (e.g., temporal max/mean, keyframe attention), cross-modal block scoring.
- Assumptions/dependencies: Architectural adaptation to non-text tokens; new benchmarks; causal masking semantics per modality.
- Adaptive, workload-aware sparsity controllers
- Sectors: MLOps, AIOps
- What: Auto-tune B, m, k online to meet SLOs and budgets, or vary by task (e.g., summarization vs coding).
- Tools/products/workflows: Control-plane agents using latency/accuracy feedback, bandit/RL policies, per-tenant policies.
- Assumptions/dependencies: Reliable online metrics; safe exploration without QoS violations.
- Cross-layer and cross-step index reuse
- Sectors: AI systems
- What: Combine HISA with IndexCache-style reuse to amortize indexing across layers/time steps.
- Tools/products/workflows: Reuse caches keyed by query similarity; invalidation policies; heuristics for diffusion across layers.
- Assumptions/dependencies: Stability of sparse patterns across layers/steps; safeguards against stale selections.
- API standardization for sparse indexers
- Sectors: ecosystem/standards, open source
- What: Define a “bring-your-own-indexer” interface for LLMs (inputs: q/k; outputs: token indices), enabling drop-in hierarchical methods.
- Tools/products/workflows: Reference adapters for PyTorch/ONNX, conformance tests, model cards that disclose sparsity behavior.
- Assumptions/dependencies: Community consensus; backward compatibility with existing KV cache layouts.
- Privacy and policy frameworks for sparse inference
- Sectors: policy/regulation, public sector
- What: Procurement and compliance guidelines that recognize energy-efficient long-context inference; audits of sparsity patterns for leakage risks.
- Tools/products/workflows: Metrics like tokens-per-Joule and “sparsity compliance” badges; red-teaming for side-channel risks in index outputs.
- Assumptions/dependencies: Standardized measurement; risk models for sparse attention disclosures.
- On-device and XR assistants with private long-context
- Sectors: mobile/edge, XR
- What: Local assistants that process extended personal histories or session transcripts offline via hierarchical sparsity.
- Tools/products/workflows: Quantized models plus HISA; compute-aware m scheduling; intermittent pooling updates when idle.
- Assumptions/dependencies: Tight memory/thermal budgets; robust, low-power kernels; acceptable quality at small m.
Notes on feasibility and dependencies (common to many applications)
- Correctness/quality relies on sufficient candidate capacity (mB ≥ k) and reasonable block pooling; mean pooling can blur boundaries—adaptive or overlapping blocks mitigate this.
- Reported gains are kernel-level; end-to-end speedups vary with the serving stack (sparse MLA operator, KV paging, batching).
- Hyperparameters (B, m, k) must be tuned per workload; conservative defaults reduce risk at modest speedups.
- HISA is most beneficial for ultra-long contexts; for short contexts, it degrades gracefully to DSA behavior with minimal overhead.
Glossary
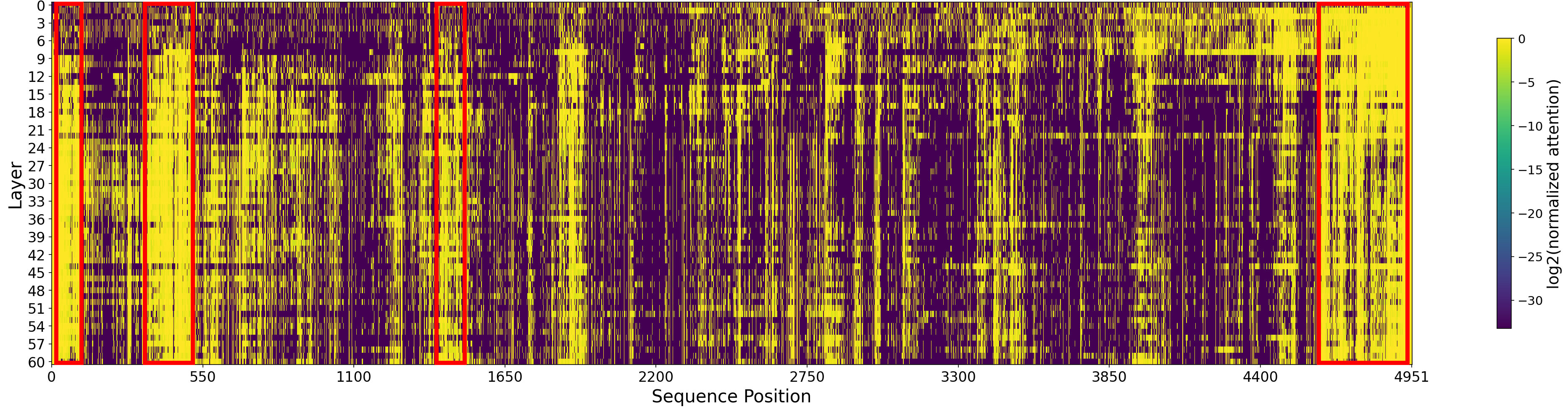
- Attention sink: A persistent position in the sequence that absorbs attention to stabilize long-context inference. "Following MoBA~\citep{lu2025moba}, the first and the last blocks are always included in , as they contain the attention sink and local contexts."
- Block sparse attention: An attention pattern that selects and computes over fixed-size blocks rather than individual tokens. "Block sparse attention partitions sequences into fixed-size blocks and restricts computation to selected blocks, mapping naturally to GPU tiled matrix multiplications."
- Block-level coarse filtering: A fast first-stage selection that scores block summaries to prune irrelevant regions before finer token-level scoring. "Stage 1: Block-level coarse filtering."
- Candidate pool: The restricted set of tokens considered in the second-stage scoring after block pruning. "The token-level indexer then scores at most tokens from the candidate blocks using the same scoring mechanism as the original DSA indexer, except that the candidate pool is restricted to the tokens within the selected blocks rather than the full set of tokens considered in DSA."
- Causal mask: A masking scheme that enforces autoregressive ordering by preventing attention to future positions. "All block selections strictly respect the causal mask: only blocks that precede the query position , together with the block containing position , are considered eligible."
- Causal prefix length: The number of preceding tokens available for a query in causal (autoregressive) attention. "Let denote the causal prefix length for a query position ."
- Compression ratio: The ratio between total blocks and selected blocks used to control sparsity in the first-stage filter. "a fixed compression ratio of ."
- Continuous batching: An inference scheduling technique that dynamically batches requests to improve throughput. "integrating HISA into a full inference serving stack (e.g., with continuous batching and speculative decoding)"
- Coarse-to-fine search: A hierarchical search strategy that first prunes at coarse granularity (blocks) and then refines at fine granularity (tokens). "HISA replaces the flat prefix scan with a two-stage coarse-to-fine search."
- DeepSeek Sparse Attention (DSA): A token-level sparse attention framework that selects top-k tokens via a lightweight indexer before sparse computation. "Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every historical key for each query through a lightweight indexer, then computing attention only on the selected subset."
- Drop-in replacement: A component that can be swapped into an existing system without retraining or architectural changes. "HISA is therefore a drop-in replacement that requires no retraining, no architectural changes to the attention mechanism, and no modification to the KV cache layout."
- Gating weights: Per-head scalars that modulate the contribution of indexing heads in the scoring function. "The indexer maintains lightweight indexing keys , indexing queries for indexing heads, and per-head gating weights ."
- Hierarchical Indexed Sparse Attention (HISA): A two-stage indexing method that first filters at block level and then refines at token level to accelerate sparse attention. "We propose HISA (Hierarchical Indexed Sparse Attention), a plug-and-play replacement for the indexer that rewrites the search path from a flat token scan into a two-stage hierarchical procedure"
- Indexer: A lightweight scoring module that ranks keys for each query to select a sparse set of tokens. "a lightweight indexer scores every historical token for each query"
- KV cache: The stored keys and values from previous tokens used to speed up autoregressive attention. "no modification to the KV cache layout."
- Latent MLA entry: A shared per-token representation used by Multi-Head Latent Attention in MQA mode. "Let denote the latent MLA entry associated with token ."
- LongBench: A benchmark suite for evaluating long-context understanding across diverse tasks. "LongBench~\citep{bai2024longbench} is a comprehensive benchmark for long-context understanding, covering single-document QA, multi-document QA, summarization, few-shot learning, and synthetic retrieval tasks."
- Mean pooling: An aggregation method that averages vectors (here, token keys) to form a block representative. "A pooled representative vector is computed for each block via mean pooling over its constituent indexing keys."
- Multi-Query Attention (MQA): An attention variant where multiple heads share a single key–value per token to reduce memory/computation. "Sparse MLA adopts the MQA mode of MLA, in which each token stores a single latent key--value entry shared across all query heads for efficiency."
- Needle-in-a-Haystack (NIAH): A stress test for retrieving a planted fact within long distractor contexts. "The Needle-in-a-Haystack (NIAH) test~\citep{kamradt2023needle} evaluates a model's ability to retrieve a specific fact (the "needle") embedded at a controlled position within a long distractor context (the "haystack")."
- Packed sequences: Concatenated variable-length sequences arranged into fixed-size blocks for efficient batched processing. "batched prefill with packed sequences of varying lengths"
- Prefill latency: The time cost to process the prompt (prefix) before token-by-token decoding starts. "the quadratic cost of self-attention becomes a dominant bottleneck in both prefill latency and memory consumption"
- Sparse MLA operator: The downstream attention computation that consumes the selected token indices to perform sparse attention. "the downstream Sparse MLA operator remains entirely unchanged."
- Sparse pattern: The set of selected token indices determining where attention is computed sparsely. "HISA preserves the identical token-level top- sparse pattern consumed by the downstream Sparse MLA operator"
- TileLang: A tile-based GPU programming framework used to implement optimized kernels. "We provide optimized TileLang GPU kernel implementations for both stages of HISA"
- Top-k: Selecting the k highest-scoring items (here, token indices) according to a scoring function. "The indexer then selects the top- token indices"
- Token-level refinement: The second-stage scoring that re-ranks tokens within selected blocks to produce the final sparse set. "Stage 2: Token-level refinement."
- Token-level sparse attention: An approach that sparsifies attention at individual token granularity rather than at block granularity. "Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection"
- Speculative decoding: An inference technique that accelerates generation by proposing and verifying multiple tokens ahead. "integrating HISA into a full inference serving stack (e.g., with continuous batching and speculative decoding)"
Collections
Sign up for free to add this paper to one or more collections.