- The paper demonstrates that model capability is the primary factor in LLM performance, overshadowing the benefits of inference-time prompt diversity.
- It employs extensive experiments on 50 IMO-level problems to reveal that diverse prompting reduces accuracy compared to a well-tuned baseline.
- The study implies that investing in model architecture and training yields far greater gains than complex prompt engineering or ensemble methods.
Model Capability as the Primary Bottleneck: Lessons from Inference-Time Optimization at AIMO 3
Introduction
The paper "Model Capability Dominates: Inference-Time Optimization Lessons from AIMO 3" (2603.27844) systematically investigates the effectiveness of inference-time optimization techniques—specifically prompt diversity—in competitive mathematics problem solving with LLMs. Relying on empirical evidence from an extensive evaluation on 50 IMO-level problems under strict resource and time constraints, the work demonstrates that model intrinsic capability is the decisive factor; inference-time interventions such as prompt diversity and sampling strategies offer negligible improvement once a modern LLM is operated at optimal temperature. This challenges prevailing assumptions about decorrelation via prompt engineering and establishes a rigorous empirical boundary for the efficacy of inference-time optimization in capability-limited hardware regimes.
Self-Consistency and the Limits of Ensemble Voting
The standard for IMO-style reasoning with LLMs is majority voting over N inference attempts ("self-consistency"), motivated by the Condorcet Jury Theorem: as N increases, an independent voter ensemble with per-attempt accuracy p>0.5 asymptotically approaches perfect accuracy. Empirically, however, errors among LLM attempts are not independent. Correlated mistakes diminish the effective sample size: the effective number of voters is given by Neff=N/(1+(N−1)ρ), where ρ is mean pairwise error correlation. Even with moderate correlation, increasing N confers much less benefit than theory predicts.
Testing Prompt Diversity: The Diverse Prompt Mixer
A natural remedy is to assign structurally distinct reasoning strategies to each sampled attempt, hypothesizing that such "diverse prompting" would decorrelate errors and thus boost ensemble accuracy. This Diverse Prompt Mixer was implemented with four complementary system prompts: an original step-by-step protocol, "Small Cases First," "Work Backwards," and "Classify Then Solve." Systematic experiments allocated various mixes of these strategies to the N-attempt ensemble, both in isolation and as mixtures.
The empirical results are unambiguous: increasing prompt diversity consistently decreases performance (Figure 1).
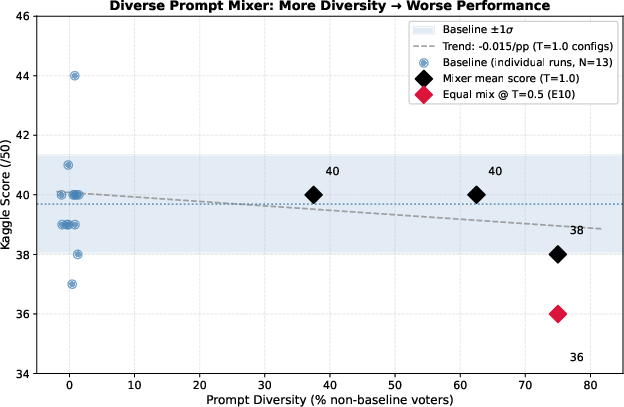
Figure 1: Prompt diversity versus score on gpt-oss-120b; increasing diversity monotonically degrades performance relative to the baseline prompt.
All alternate strategies underperform relative to the baseline prompt, and replacing any of the baseline with diverse prompts monotonically reduces score. Even the most promising alternate strategies (e.g., code-first) fail upon repeated trials.
Analysis: Why Prompt Diversity Fails
High-Temperature Sampling and Stochastic Decorrelation
At T=1.0, high-temperature generation is already sufficient to decorrelate sampled outputs. Empirical estimates of ρ^ (pairwise error correlation) are consistently negative or near zero, eliminating any marginal utility that prompt diversity could provide (Figure 2).
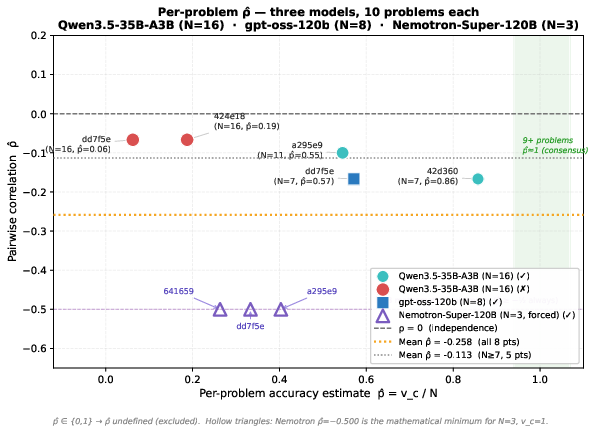
Figure 2: Per-problem ρ^ versus N0 across three models; all computed points show N1, indicating no empirical room for diversity-driven decorrelation.
Thus, stochastic sampling rather than prompt structure is responsible for the observed diversity in responses.
Tradeoff: Accuracy versus Decorrelation
Because alternate prompts yield structurally weaker strategies, they do reduce error correlation but at the cost of significantly lowering per-attempt accuracy N2. The net effect is negative—diverse prompts dilute the effectiveness of the ensemble, as the intended decorrelation does not compensate for the accuracy loss.
Model Capability Overshadows Inference-Time Optimization
The most pronounced finding is the magnitude of the "capability gap." Across models with varying architecture and number of parameters (e.g., gpt-oss-120b, Nemotron-Super-120B, Qwen3.5-35B-A3B), the strongest numerical result is that a 17-point difference in leaderboard score between the leading and alternative models dwarfs any prompt-level or sampling intervention, which shifts scores by at most ±2 points (Figure 3).
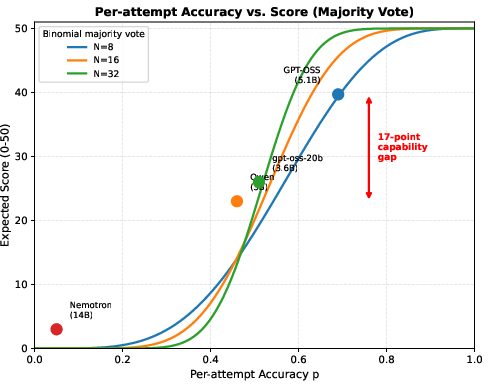
Figure 3: Model capability dominates; the score/accuracy gap between models is an order of magnitude larger than any inference-time optimization.
Comprehensive Ablations and Cross-Model Validation
A set of 23 targeted experiments modifying parameters such as temperature, prompt mix, sample count, and strategy confirms no experimental configuration reliably outperforms the well-tuned baseline (Figure 4).
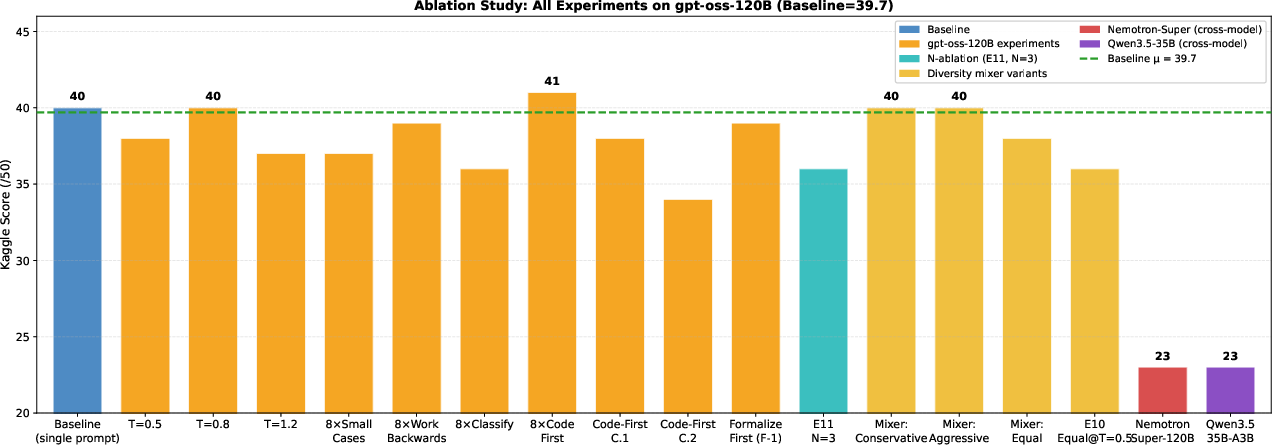
Figure 4: Complete ablation across all experiments reveals a flat optimization landscape—no intervention reliably beats the baseline mean.
These findings replicate across major open math LLMs. For instance, ablations on Qwen3.5-35B-A3B confirm that neither ensemble size nor elaborate prompt modifications systematically raise scores (Figure 5).
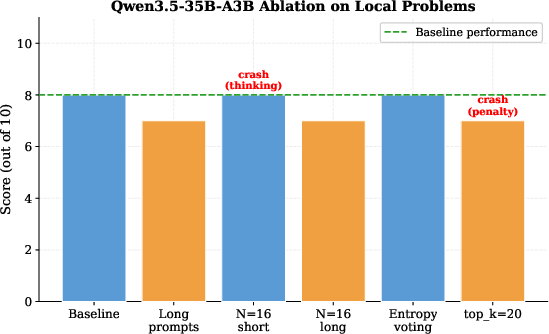
Figure 5: Qwen3.5-35B-A3B ablation: no prompt or parameter change exceeds the baseline on local or LB tasks.
Implications for AIMO Competition Strategy
Tracking the evolution of top scores and ensemble sizes in the AIMO competitions, the trend is explicit: returns from majority-vote ensemble size diminish as model N3 increases (Figure 6). The effective regime for inference-time optimization is diminishing as models become more capable.
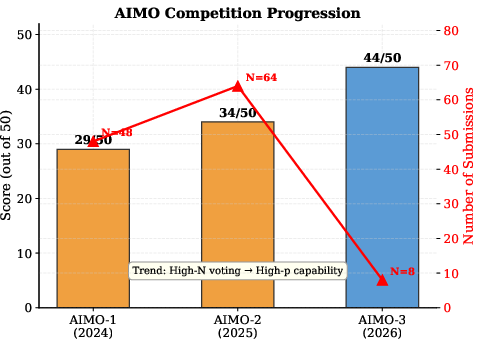
Figure 6: AIMO competition progression: higher scores are achieved via increased model capability and reduced N4; inference-time tricks wane as models improve.
Statistical and Infrastructure Noise Analysis
Variance in scores arises both from the inherent stochasticity of model sampling and from external factors such as infrastructure contention (as established elsewhere [anthropic2026infranoise]). Multiple-run means and empirical variances are thus essential to robust evaluation. Each submission can be viewed as a lottery ticket, and prompt diversity does not raise the probability of extreme high scores (Figure 7).
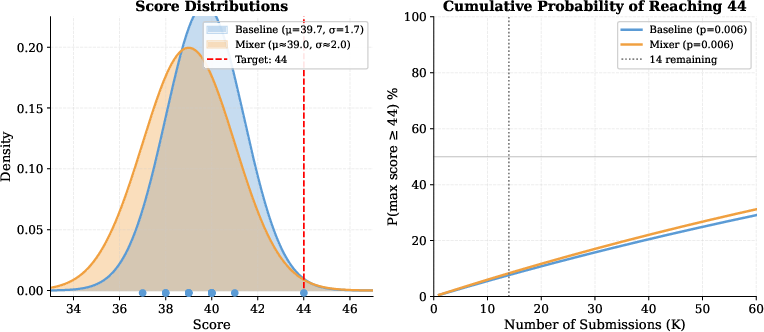
Figure 7: Score distributions for baseline and mixer; prompt mixing does not affect the probability of extreme high (e.g., ≥44) scores.
Conditions for Prompt Diversity Utility and Future Outlook
Prompt diversity might become beneficial in settings where: (i) temperature is low (insufficient randomization), (ii) the problem set is less challenging so even weak strategies achieve high N5, or (iii) the model exhibits prompt robustness to diverse reasoning scaffolds (which current math LLMs do not, due to limited prompt-format diversity in training). This highlights a future direction: training models specifically for prompt robustness with Mixture-of-Formats data (as confirmed by [mof2025]), possibly restoring the value of inference-time prompt mixing in broader regimes.
Conclusion
This paper establishes that for competitive mathematical reasoning, model capability is the overwhelming determinant of performance under fixed compute and resource constraints. Once basic system parameters are optimized—sampling temperature, ensemble size, and strong baseline prompt—further inference-time interventions, including prompt diversity, confer minimal or negative returns. For practical deployment and competition, investment in model architecture and training is orders of magnitude more valuable than advanced prompt or ensemble engineering. This finding sets a clear empirical threshold for the class of inference-time optimizations most relevant to contemporary LLM-driven mathematical reasoning systems.

