- The paper introduces LLaVA-DyMoE, a dynamic MoE framework that employs token assignment guidance (TAG) and routing score regularization (RSR) to counter catastrophic forgetting.
- It provides a token-centric analysis by categorizing input tokens into new, old, and ambiguous, thereby preventing routing-drift during continual learning.
- Empirical results demonstrate a 7.4% accuracy improvement and a 12.0% reduction in forgetting, validating its efficacy over state-of-the-art methods.
Dynamic Mixture of Experts with Drift-Aware Token Assignment for Continual Learning in LVLMs
Introduction
This paper addresses the persistence of catastrophic forgetting in Large Vision LLMs (LVLMs) under the Multimodal Continual Instruction Tuning (MCIT) regime, despite the widespread adoption of the Mixture of Experts (MoE) architecture. While previous approaches leverage modular expansion (i.e., adding new experts and router parameters per incoming task), they remain susceptible to forgetting via routing-drift: new or ambiguous tokens in incoming tasks corrupt the established routing policy, causing old inputs to be misrouted and degrading prior-task performance. This work proposes LLaVA-DyMoE, a dynamic MoE method with drift-aware token assignment, integrating token-level assignment guidance (TAG) and routing score regularization (RSR) to alleviate routing-drift and stabilize continual learning.
Analysis of Token Assignment and Routing-Drift
The authors perform a token-centric diagnostic of catastrophic forgetting in dynamic MoE expansion. Despite freezing old experts and routers, training new routers on incoming data causes old-task tokens to become increasingly attracted to new experts, producing measurable accuracy deterioration on prior tasks. At the crux is the assignment ambiguity of tokens during new-task learning. The empirical analysis partitions new-task tokens into three categories:
- New Tokens: Clearly favored by new experts, contribute constructively to new-task acquisition with minimal forgetting.
- Old Tokens: Resemble prior data, best handled by old experts. Their spurious activation of new experts, especially when not fully suppressed, is a key vector for forgetting.
- Ambiguous Tokens: Equivocal affinity to both old and new expert groups. When default MoE routing assigns them to new experts, they degrade the old-task routing mapping without positive impact on new-task learning.
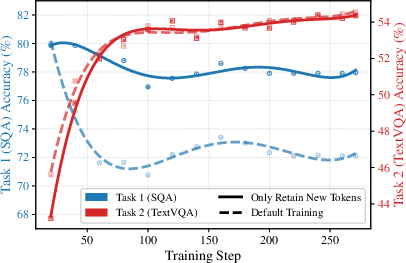
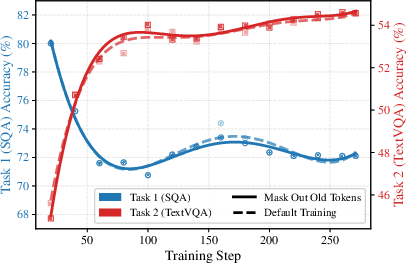
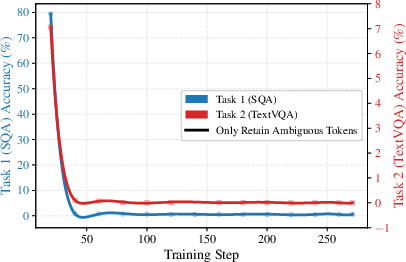
Figure 1: The forgetting (task 1 accuracy drop) and new-task acquisition (task 2 accuracy gain) are decomposed by routing token type, highlighting the detrimental role of ambiguous and old tokens in exacerbating catastrophic forgetting.
The analysis demonstrates that naive expansion—assigning all new-task tokens to new experts—induces irreversible drift in old-task routing behavior. Effective mitigation must act directly at the token routing level.
LLaVA-DyMoE: Dynamic MoE with Drift-Aware Token Assignment
LLaVA-DyMoE introduces dynamic per-layer MoE expansion with two core algorithmic innovations:
Token Assignment Guidance (TAG)
TAG explicitly enumerates old and new expert groups after each expansion. For each input token, it computes group-wise routing score statistics and quantifies ambiguity by the relative score difference. An ambiguity threshold τ is used:
- Only non-ambiguous, new-favoring tokens are permitted activation of new experts.
- Ambiguous and old-favoring tokens are forcibly assigned to old experts; activation of new experts is supressed (−∞).
- The assignment policy is injected into training, leaving inference unconstrained.
This mechanism prevents ambiguous tokens—those empirically shown to offer minimal new-task gain and maximum forgetting risk—from distorting new routers.
Routing Score Regularization (RSR)
Two auxiliary losses regularize expert group utilization:
- Exclusivity Loss (Lexc): Penalizes simultaneous high activations for both old and new expert groups per token, enforcing sharper token-to-group allocation.
- Specialization Loss (Lspe): Explicitly drives increased utilization and specialization within new experts conditional on tokens that are unambiguously new.
The learning objective combines the instruction tuning task loss, standard MoE auxiliary load-balancing, and the new RSR components, controlled by scalar hyperparameters.
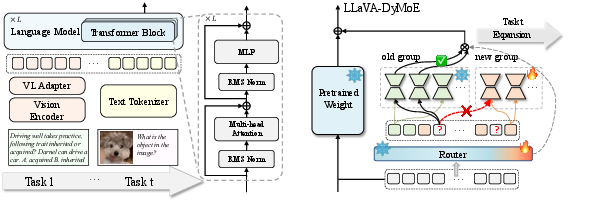
Figure 2: Schematic of LLaVA-DyMoE: as each new task arrives, the MoE dynamically adds new expert groups and routers (orange). TAG restricts token assignment, while RSR enhances group separation and specialization.
Experimental Results
Comprehensive evaluation on the CoIN benchmark (8 vision-language QA tasks, 569k train / 261k test) is conducted. LLaVA-DyMoE is compared to baseline continual learning (IncMoELoRA, O-LoRA, EWC, LWF), as well as specialized data-based replay and state-of-the-art MCIT methods.
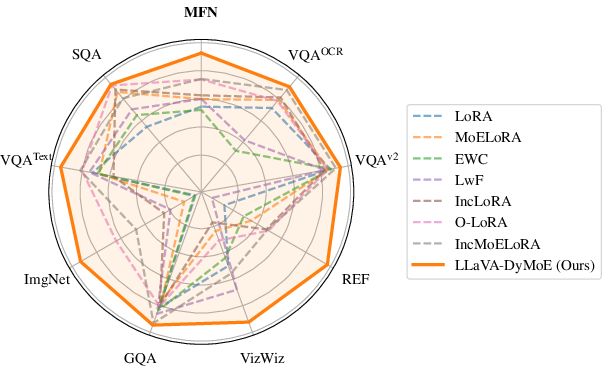
Figure 3: Per-task and aggregated accuracy after all incremental task training. LLaVA-DyMoE consistently eclipses all prior models on both new-task acquisition and knowledge retention metrics.
Key empirical findings:
- Mean Final Accuracy (MFN) improvement: +7.4% over best baseline (57.0% vs. 49.7% for IncMoELoRA).
- Backward Transfer (BWT) improvement: 12.0% reduction in forgetting (−4.7% vs. −16.7% for IncMoELoRA).
- Orthogonality of gains: DyMoE can be naively combined with replay paradigms or task-specific routing for additive improvements.
- Ablation: Removal of TAG or either RSR term recapitulates loss in old-task performance, confirming their efficacy.
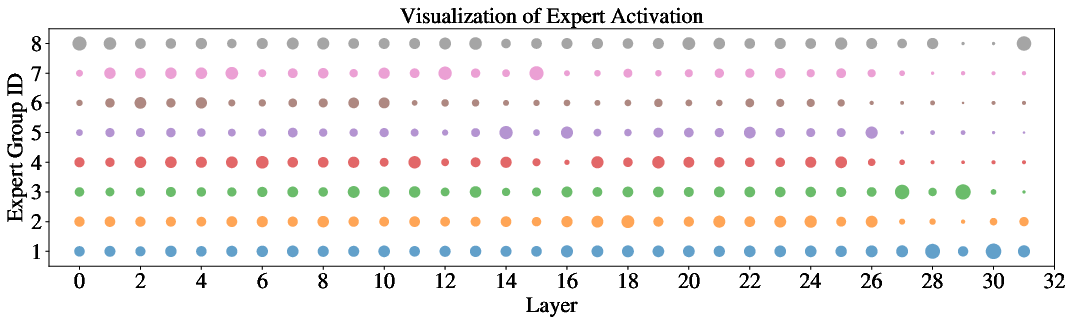
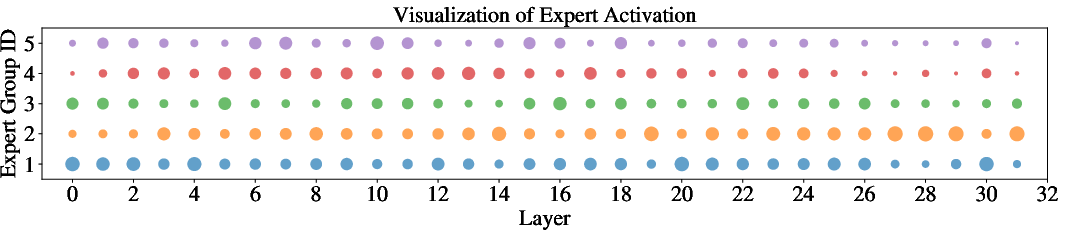
Figure 4: Post-hoc expert activation patterns per layer/task reveal that DyMoE yields marked expert specialization and low cross-group activation, validating the impact of assignment regularization.

Figure 5: Qualitative comparison (ScienceQA/ImageNet) after all-task training reveals that DyMoE preserves fine-grained, domain-specific knowledge often forgotten by standard incremental MoE.
Theoretical and Practical Implications
On the theoretical front, the work uncovers a granular, token-level mechanism at the root of catastrophic forgetting in modular continual learning, moving beyond architectural expansion to explain why modularity alone is insufficient. It links the stability-plasticity dilemma to "token's dilemma"—the ambiguous assignment of high-density regions in the representation space that co-activate both old and new experts.
Practically, LLaVA-DyMoE is highly efficient (negligible runtime increase at training, zero cost at inference), architecture-agnostic, and modular. It enables robust continual learning with frozen model cores—a property critical for scaling-up MCIT in resource-constrained or privacy-limited settings.
Future Directions
Potential avenues for research include scaling drift-aware assignment to even larger-scale or more temporally extended sequences of tasks, adaptive or data-driven tuning of the assignment ambiguity threshold, and fine-grained integration with other forms of modular ensembling. Investigations into richer group structure (e.g., hierarchical experts) and connections to continual unsupervised or self-supervised multimodal learning are also promising.
Conclusion
LLaVA-DyMoE demonstrates that targeted, token-level control of expert assignment in dynamic MoE architectures can effectively reconcile continual plasticity with knowledge stability in LVLMs. By directly addressing the assignment ambiguity that drives routing-drift, it sets a new performance bar for MCIT and provides a theoretically grounded approach applicable to a broad class of modular continual learning systems.

