Weight Tying Biases Token Embeddings Towards the Output Space
Abstract: Weight tying, i.e. sharing parameters between input and output embedding matrices, is common practice in LLM design, yet its impact on the learned embedding space remains poorly understood. In this paper, we show that tied embedding matrices align more closely with output (unembedding) matrices than with input embeddings of comparable untied models, indicating that the shared matrix is shaped primarily for output prediction rather than input representation. This unembedding bias arises because output gradients dominate early in training. Using tuned lens analysis, we show this negatively affects early-layer computations, which contribute less effectively to the residual stream. Scaling input gradients during training reduces this bias, providing causal evidence for the role of gradient imbalance. This is mechanistic evidence that weight tying optimizes the embedding matrix for output prediction, compromising its role in input representation. These results help explain why weight tying can harm performance at scale and have implications for training smaller LLMs, where the embedding matrix contributes substantially to total parameter count.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in plain words)
This paper looks at a common shortcut used when building LLMs called “weight tying.” That shortcut makes the model use the exact same set of numbers (called an embedding matrix) both to read words going in and to choose words coming out. The authors ask: does this shortcut quietly push the model to get better at talking (predicting the next word) but worse at listening (turning input words into useful internal signals)? They find that it does—and explain why.
The main questions the researchers asked
- When a model shares one set of weights for both reading and speaking, does that shared set end up shaped more for speaking than for reading?
- Does this imbalance make the first few layers of the model work less effectively?
- Why does this happen during training?
- Can we fix it by changing how the model learns?
How they tested it (with simple analogies)
Think of a LLM as a factory:
- The input embedding matrix is like a “word reader” that turns each word into a helpful internal code so the factory can reason.
- The output (unembedding) matrix is like a “word chooser” that takes the factory’s internal code and decides which word to say next.
Weight tying means using the same tool for both reading and choosing. The authors checked which job ends up shaping that shared tool.
They used four main approaches:
- Comparing shapes of spaces (alignment)
- Analogy: Imagine two maps of the same city drawn by different people. If you can rotate or stretch one map to match the other easily, they’re “aligned.”
- What they did: They compared the shared matrix in tied models to the separate input and output matrices from similar untied models. They tried simple transformations (none, rotation only, or any linear stretch/rotation) to see which pairing matched better.
- Tuned lens (seeing how well early layers “speak” the model’s final language)
- Analogy: If different workers in the factory each use their own slang, you might need a small translator to make them understood by the final speaker.
- What they did: They trained tiny “translators” for each layer to make that layer’s outputs predict the next word. If the translator still struggles (higher divergence), that layer is less compatible with the model’s final output space.
- Tracking how things change during training (checkpoints)
- Analogy: Take snapshots as the factory learns. Which tools are being reshaped faster?
- What they did: In models where input and output tools are separate, they measured how quickly each one changes from its starting point. This shows who’s “pulling” more during learning.
- Measuring where the learning signal comes from (gradients) and nudging it
- Analogy: Two people tug on a piece of clay—whoever pulls harder shapes it more. The strength of the pull is like the gradient.
- What they did: In tied models, they measured how much of the learning signal comes from the input side vs. the output side. Then they tried boosting the input side’s signal to see if that changes the shape of the shared tool.
What they found and why it matters
Here are the main results:
- The shared tool looks like the “word chooser,” not the “word reader.”
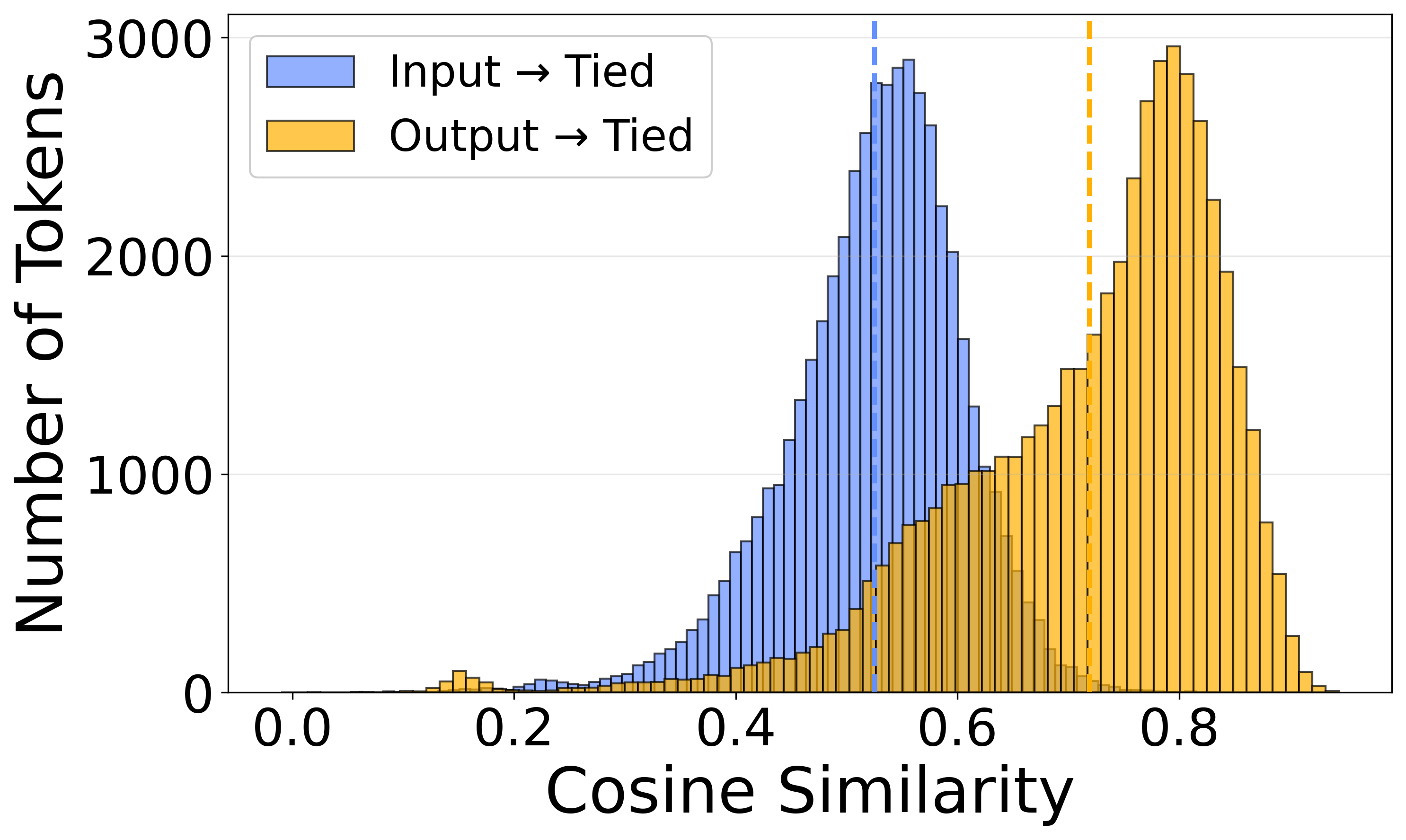
- The tied embedding matrix matches the output matrix from untied models more closely than it matches the input matrix. In other words, when you share, the tool becomes optimized for speaking (predicting words) rather than for reading (representing inputs).
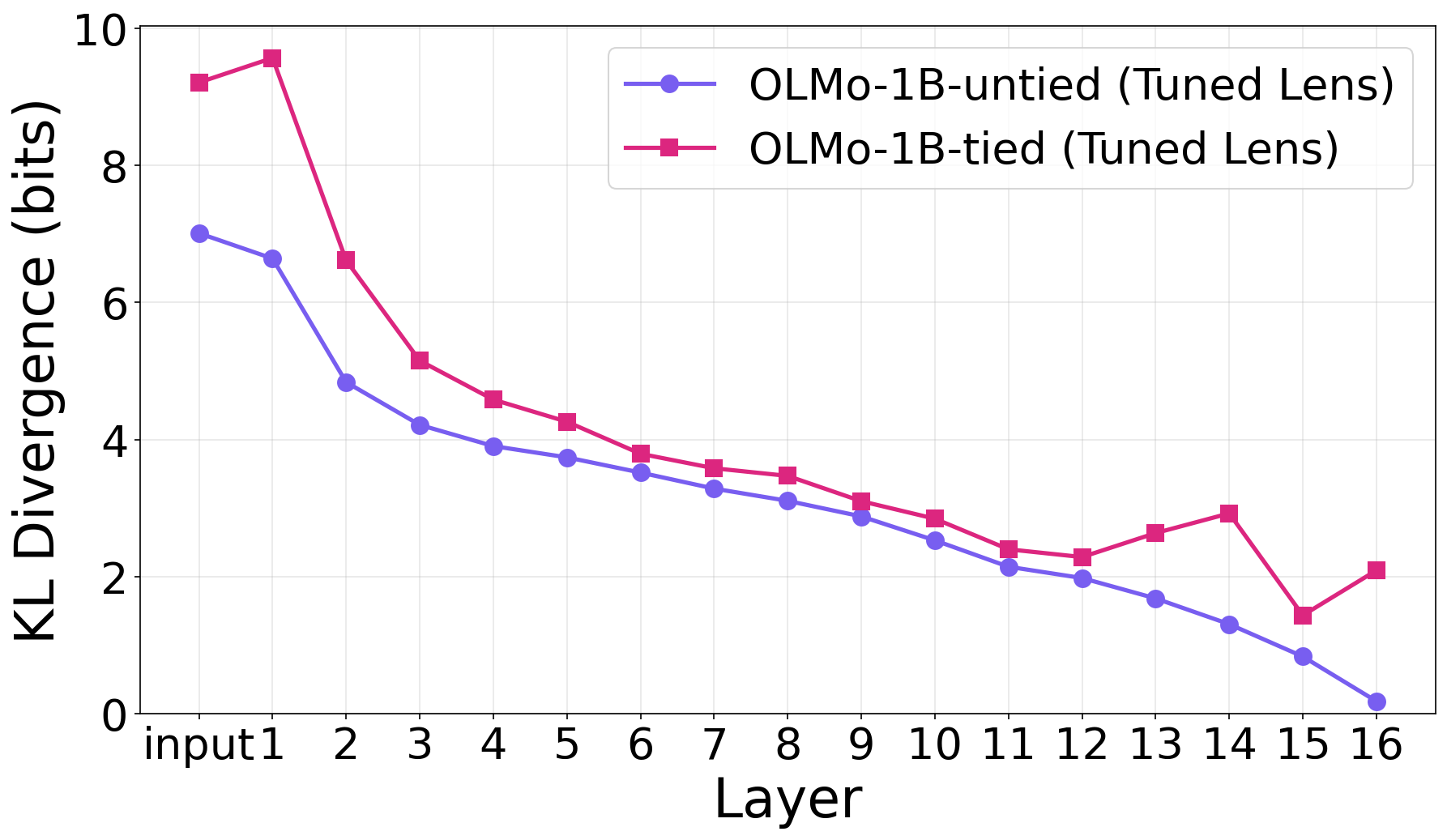
- Early layers work less smoothly in tied models.
- Using the tuned lens, early layers in tied models were harder to translate into good predictions (higher mismatch). This suggests those early layers are doing extra work because the input embeddings aren’t as well suited for building internal understanding.
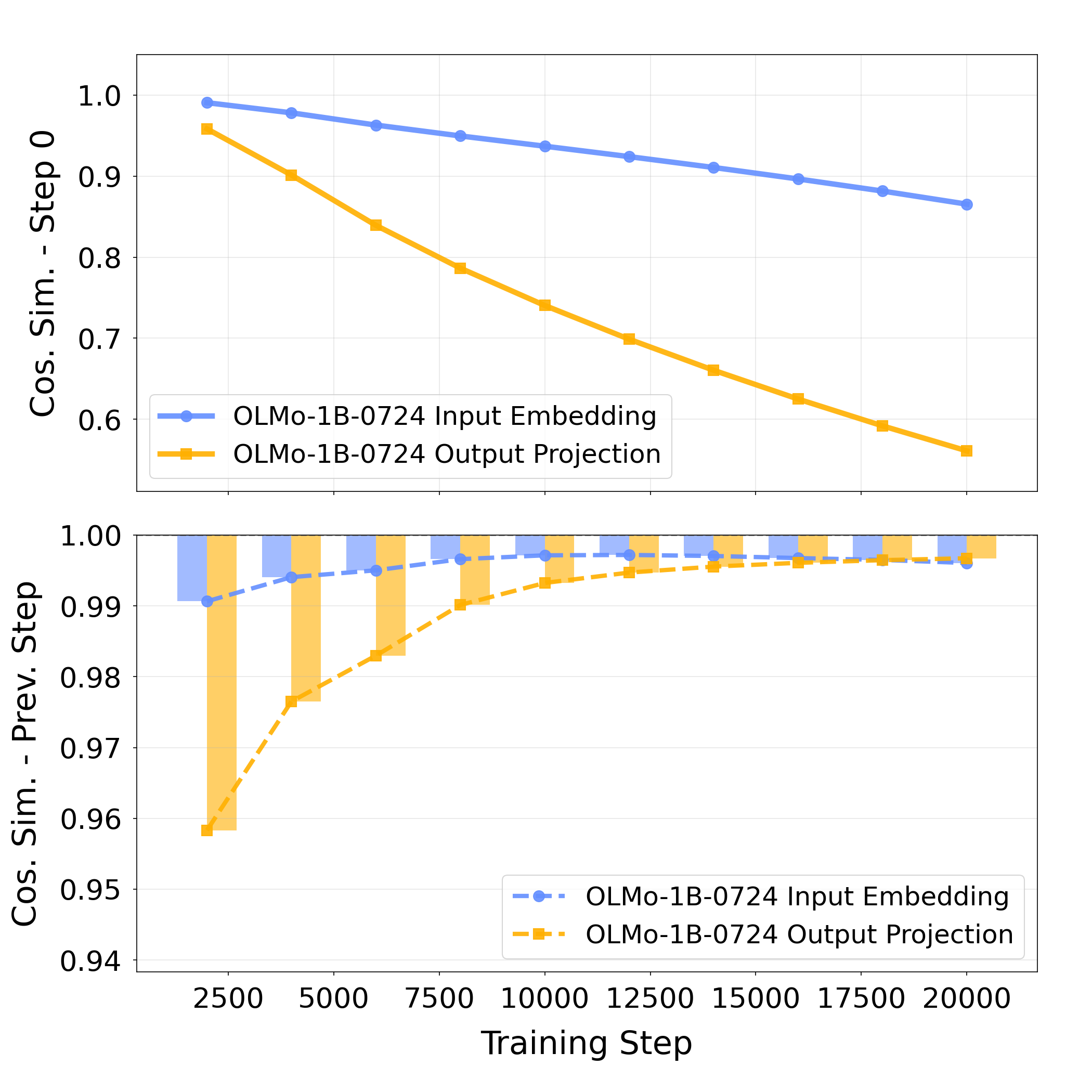
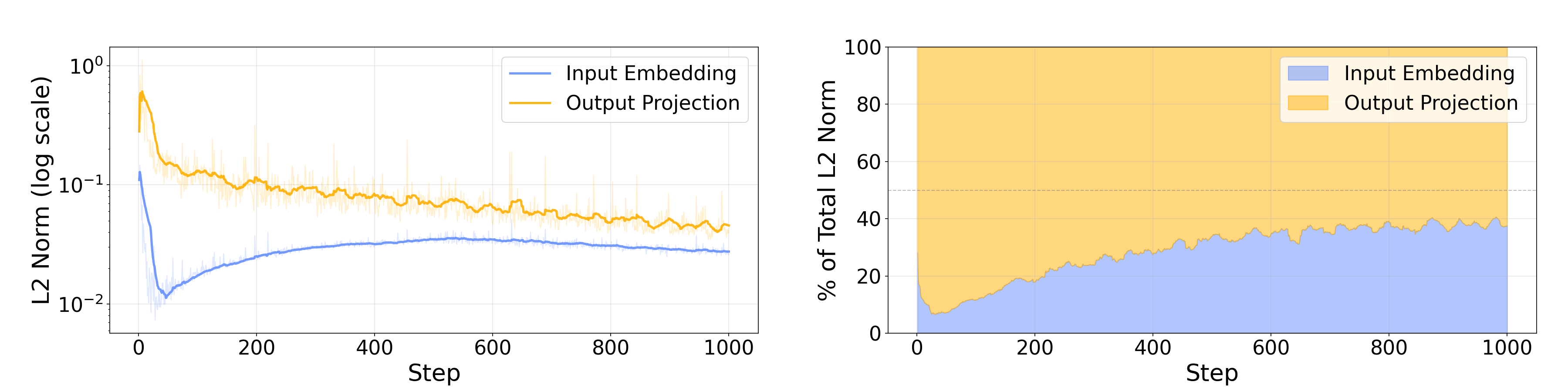
- During training, the output side pulls harder—especially early on.
- In untied models, the output matrix changes much faster than the input matrix at the start. In tied models, most of the learning signal that shapes the shared matrix comes from the output side (about 70% early in training). That explains why the shared tool ends up output-oriented.
- If you boost the input’s learning signal, you can rebalance the tool a bit.
- When they multiplied the input-side learning signal, the shared embeddings shifted slightly toward input-like structure and away from output-like structure. This is causal evidence: change the pull, change the shape. But there wasn’t a clear overall performance gain—improving one side tends to hurt the other because it’s the same shared tool.
Why this matters:
- For small models, weight tying saves a lot of parameters, which is useful.
- For big models, the savings are small, but the cost of having a tool optimized more for speaking than reading can hurt performance. That’s why many larger modern models don’t tie these weights.
What this could mean going forward
- Design choice: For small LLMs, tying weights can still be a good idea because it saves many parameters. For large models, untying them is usually better for performance because each tool can specialize—one for reading, one for speaking.
- Training tricks: Rebalancing the learning signals might help reduce the downside of tying, though simple scaling didn’t give clear overall gains here. More clever training methods might find a better trade-off.
- Big picture: This paper explains a “why” behind a trend in today’s models: untying helps at scale because it avoids biasing the shared tool toward output and keeps early layers more effective.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored based on the paper’s methods and findings.
- Generalization across architectures and objectives: Do the observed gradient imbalance and “unembedding bias” hold in encoder-only (MLM), encoder–decoder, non-autoregressive, and Mixture-of-Experts models, and under different normalization schemes (pre-/post-LN)?
- Controlled, matched training runs: The OLMo tied vs untied runs differ in data versions; GPT-Neo vs Pythia and Qwen comparisons confound size and/or data. Run fully controlled experiments with identical data, tokenizer, architecture, optimizer, and seeds to isolate the effect of tying.
- Scaling-law boundary: Precisely identify the model-size threshold where untying becomes reliably beneficial by running matched tied/untied sweeps across many sizes (e.g., 70M→70B) with fixed compute budgets.
- Full-training dynamics: The analyses focus on early training (first 1k–20k steps). Do gradient contributions and tuned-lens KL gaps persist, vanish, or invert later in training and at convergence?
- Direct performance link: Quantify how early-layer KL penalties and embedding alignment differences translate to perplexity, calibration, and downstream task performance over training (not only structural metrics).
- Mechanistic source of imbalance: Decompose why output gradients dominate—measure per-layer Jacobian norms, gradient attenuation through depth, the role of LayerNorm/residual scaling, optimizer choices (AdamW vs Adafactor/Lion), learning-rate warmup, label smoothing, and softmax temperature.
- Tokenizer and vocabulary effects: Test how vocabulary size , tokenization scheme (BPE vs SentencePiece), and subword morphology affect gradient balance and the norm–frequency relationship; vary in controlled runs.
- Frequency- and token-type-specific impacts: Quantify how tying affects rare vs frequent tokens, function vs content words, and symbol classes; measure per-token gradient contributions and predictive accuracy/calibration by frequency band.
- Anisotropy explicitly measured: The paper cites prior anisotropy results but does not report isotropy/anisotropy metrics for its own runs. Measure spectral properties (eigenvalue spectra, participation ratios) and link them to tying and downstream performance.
- Causal link to early-layer utility: Beyond tuned-lens KL, use causal interventions (e.g., activation patching, layer ablations, logit attribution) to quantify how much early layers contribute to final logits under tied vs untied settings.
- Broader intervention space: The only intervention tried is constant input-gradient scaling (5×). Explore:
- Schedule-based scaling (warmup-only, cosine, or adaptive based on observed norm ratios).
- Separate learning-rate multipliers or optimizer hyperparameters for input vs output roles.
- Auxiliary objectives on input embeddings (contrastive/isotropy regularizers, alignment to early-layer subspaces).
- Partial tying (e.g., low-rank shared subspace, block-diagonal tying, per-frequency tying) to trade off roles more flexibly.
- Robustness and generalization: Assess how tying affects OOD generalization, adversarial susceptibility, calibration, and uncertainty estimation.
- Fine-tuning and instruction tuning: Does weight tying hinder adaptability during task-specific fine-tuning, RLHF, or domain adaptation relative to untied models?
- Data distribution sensitivity: How do corpus characteristics (domain mix, token frequency distributions, multilingual data) modulate gradient imbalance and the norm–frequency pattern?
- Optimizer and regularization effects: Test whether decoupled weight decay, gradient clipping, EMA, parameter noise, or different initialization schemes can mitigate output-gradient dominance.
- Theoretical characterization: Develop a formal analysis of gradient norms in tied vs untied settings (e.g., expected magnitudes under cross-entropy with softmax and pre-LN transformers) to predict when and why output gradients dominate.
- Compute–memory trade-offs: Provide a quantitative cost–benefit analysis (training/inference speed, memory footprint, throughput) for tying vs untying across sizes to inform practical deployment decisions.
- Detailed downstream evaluation: The paper notes no consistent gains from simple scaling but defers details to the appendix. Systematically report task-level results (perplexity, QA, reasoning, multilingual transfer) to ground the structural findings in end-task performance.
- Longer-term gradient provenance: Extend gradient provenance logging beyond 1k steps and across training phases (warmup, plateau, late training) to determine if and when the gradient balance shifts.
- Interaction with logits/softmax head design: Explore whether alternatives like temperature scaling, label smoothing, or decoupled classifiers alter the gradient flow and reduce the unembedding bias.
Practical Applications
Practical Applications of “Weight Tying Biases Token Embeddings Towards the Output Space”
Below are actionable applications derived from the paper’s findings on weight tying, unembedding bias, and gradient dynamics in LLMs, organized by deployment horizon.
Immediate Applications
These can be implemented now using existing tooling (PyTorch/Hugging Face), open models (OLMo, Pythia), and standard MLOps practices.
- Model architecture selection guidelines
- What to do: Untie input/output embeddings for models ≳1B parameters; consider tying for sub‑billion models when parameter budget dominates.
- Sectors: Software/AI infrastructure; domain LLMs in healthcare, finance, education.
- Potential workflows/products: Updated model design checklists; templates in training repos that toggle tying by size; architecture config validators in internal CI.
- Assumptions/dependencies: Threshold depends on vocabulary size, model depth, and compute budget; paper shows mechanistic evidence but exact crossover point is context-dependent.
- Training-time gradient provenance monitoring
- What to do: Add hooks to track and alert on input vs output gradient norms for the shared embedding matrix (signal imbalance ≈70% output early in training).
- Sectors: MLOps, foundation-model training.
- Tools/products: PyTorch/HF add-on “Embedding Gradient Monitor” with rolling averages, dashboards, and alerts.
- Assumptions/dependencies: Requires access to training code/infra; negligible overhead if sampled periodically.
- Early-layer diagnostics with tuned lens and alignment tests
- What to do: Add tuned lens residual KL for early layers to your eval suite; run Procrustes/linear alignment and KNN overlap between tied/untied spaces to detect unembedding bias.
- Sectors: Model QA, safety, academia.
- Tools/products: Evaluation harness modules for “Early-Layer Health” (tuned-lens KL) and “Embedding Alignment Report” (identity/orthogonal/linear).
- Assumptions/dependencies: Additional compute for lens training; thresholding requires internal baselining.
- Fine-tuning controls for tied models
- What to do: Reduce the output gradient dominance during domain fine-tuning via: learning-rate multipliers for embeddings, partial freezing schedules, or modest input-gradient scaling (e.g., ×2–×5).
- Sectors: Healthcare and finance fine-tuning (where stability and representation quality matter), small/edge deployments.
- Tools/products: Fine-tuning recipes with embedding-specific LR multipliers; “embedding freeze-unfreeze” schedules; ablation-ready configs.
- Assumptions/dependencies: Paper shows structure shifts but no consistent downstream gains; must A/B test on task metrics and safety.
- On-device and robotics LLM builds under tight memory budgets
- What to do: Use tied embeddings to reduce parameters in micro/edge models but mitigate representational cost with small adapters, LR multipliers, or light input-gradient scaling.
- Sectors: Mobile AI, robotics, embedded systems.
- Tools/products: “Edge LLM Kit” recipes combining tying + adapters; latency/memory calculators incorporating embedding size trade-offs.
- Assumptions/dependencies: Trade-off between efficiency and early-layer quality; validate latency, battery impact, and task robustness.
- Model selection for adapters and PEFT
- What to do: Prefer untied-base models when training early-layer adapters, retrieval heads, or alignment modules that rely on high-quality early representations.
- Sectors: RAG pipelines, PEFT vendors, enterprise AI teams.
- Tools/products: Procurement checklists that flag “untied embeddings preferred” for adapter-heavy stacks.
- Assumptions/dependencies: Benefit strongest when early-layer representations are directly leveraged; confirm with tuned-lens KL.
- Documentation and governance updates
- What to do: Disclose tying policy, early-layer KL, and gradient imbalance metrics in model cards; add procurement questions about embedding coupling.
- Sectors: Policy/compliance, safety, enterprise procurement.
- Tools/products: Model card templates with “Embedding Coupling” and “Early-Layer Health” sections.
- Assumptions/dependencies: Voluntary adoption; standardization may emerge via industry consortia.
- Energy/compute budgeting heuristics
- What to do: Consider untying for large models to avoid early-layer “first-layer penalty” that may slow convergence; track tokens-to-target-perplexity with vs without tying.
- Sectors: Cloud training ops, sustainability teams.
- Tools/products: Training dashboards incorporating “tokens-to-target” and early-layer KL as leading indicators of convergence.
- Assumptions/dependencies: Paper provides mechanistic rationale but not quantified energy savings; requires internal measurement.
Long-Term Applications
These require further research, scaling studies, or productization.
- Dynamic coupling schedules (train-time tying policies)
- What to explore: Start tied then untie after early stabilization, or vice versa; staged dual-matrix training with gradual interpolation; task-aware schedules.
- Sectors: Foundation-model training, AutoML.
- Tools/products: “Coupling Scheduler” optimizer plugin that adapts tying status based on gradient provenance and tuned-lens KL.
- Assumptions/dependencies: New optimizer hooks and stability research; validation on larger scales and tasks.
- Gradient-balancing optimizers
- What to explore: Adaptive mechanisms that equalize contributions from input/output pathways to shared parameters (not just constant scaling); extend beyond embeddings to other shared modules.
- Sectors: Optimizer research, training platform vendors.
- Tools/products: “BalancedGrad” optimizer/regularizer with per-pathway control.
- Assumptions/dependencies: Must avoid harming output head learning; requires theory and extensive benchmarks.
- Architecture/search assistants for embedding policies
- What to explore: NAS or design assistants that recommend tie/untie decisions given constraints (params, latency, memory, domain).
- Sectors: AutoML, MLE tooling.
- Tools/products: Config generators that suggest coupling policy, LR multipliers, and schedules based on a spec.
- Assumptions/dependencies: Needs meta-datasets of training outcomes across scales and domains.
- Cross-modal and multilingual generalization
- What to explore: Apply findings to vision transformers, speech-text models, multilingual LMs; test if tying hurts early-stage representation quality across modalities/languages.
- Sectors: Multimodal AI, ASR, translation.
- Tools/products: Modality-agnostic “Embedding Coupling Analysis” suite; tuned lens extensions to multimodal heads.
- Assumptions/dependencies: Different heads/losses may change gradient balance; requires new metrics and adapters.
- Release gating via early-layer health metrics
- What to explore: Use tuned-lens KL gaps and alignment scores as quality gates for foundation-model releases; correlate with downstream robustness and safety.
- Sectors: Model governance, safety, policy.
- Tools/products: “Early-Layer Health” certification; compliance dashboards for internal sign-off.
- Assumptions/dependencies: Community-accepted thresholds and correlations to real-world safety still developing.
- Compression pipelines that keep embeddings untied
- What to explore: Replace tying with pruning, quantization, and distillation to meet parameter limits while preserving representational benefits of untying.
- Sectors: Edge AI, mobile, robotics.
- Tools/products: “Untie-then-Compress” workflows; distillation strategies preserving early-layer features.
- Assumptions/dependencies: Compression may reintroduce anisotropy; must audit with alignment/kl metrics.
- Educational and mechanistic interpretability labs
- What to explore: Curricula and lab kits demonstrating gradient dominance, tuned lens, and alignment analyses; broaden mechanistic understanding in academia and industry training.
- Sectors: Academia, workforce upskilling.
- Tools/products: Reproducible notebooks on OLMo/Pythia; interactive dashboards.
- Assumptions/dependencies: Access to compute/checkpoints; open data where possible.
- Library and framework support
- What to explore: First-class APIs for safe gradient hooks, embedding-tying policies, tuned-lens training, and alignment metrics in major frameworks.
- Sectors: Open-source ecosystems (PyTorch, Hugging Face).
- Tools/products: Built-in “EmbeddingCouplingPolicy,” “GradientProvenance,” and “TunedLens” modules.
- Assumptions/dependencies: Community maintenance and performance engineering.
Notes on feasibility and dependencies across applications:
- The paper’s evidence spans OLMo, Pythia, and Qwen families; results may vary for MoE, non-autoregressive, or heavily regularized architectures.
- Input-gradient scaling changed embedding structure but did not yield consistent downstream performance improvements; any intervention should be validated on target tasks and safety metrics.
- Some diagnostics (tuned lens) add compute overhead; practical use may require lightweight approximations or periodic sampling.
- Data, tokenizer, and vocabulary differences can affect gradient balance and alignment signatures; baselining on internal stacks is recommended.
Glossary
- Affine transformation: A linear mapping composed of a matrix multiplication plus a bias, used to translate representations between spaces. "The tuned lens \citep{belrose2023tunedlens} addresses this limitation by learning an affine transformation for each layer:"
- Anisotropy: Directional non-uniformity in a representation space where some directions have disproportionately large variance. "exhibit less anisotropy in their representation spaces compared to tied models"
- Cross-entropy loss: A standard objective in classification and language modeling that measures the difference between predicted and true distributions. "optimizing directly for cross-entropy loss."
- Gradient hooks: Mechanisms attached to model components to observe or modify gradients during backpropagation. "using gradient hooks to multiply input-layer gradients by a scaling factor before they accumulate into the shared embedding matrix."
- Gradient imbalance: A training situation where different parts of a model receive unequal gradient magnitudes, biasing learning. "providing causal evidence for the role of gradient imbalance."
- K-nearest neighbors (KNN) overlap: A similarity measure comparing neighborhoods of points across embedding spaces by overlapping nearest neighbors. "we instead use KNN overlap and spectral distance analysis (Appendix~\ref{app:appendix-knn})."
- Kullback–Leibler (KL) divergence: A measure of divergence between two probability distributions, often used to assess predictive alignment. "The residual KL divergence after training indicates how well each layer's representations align with the output space,"
- Linear alignment: Fitting an unconstrained linear mapping between embedding spaces to compare them in a shared basis. "Per-token cosine similarity (after linear alignment) between the tied embedding matrix and the untied input (blue) and output (orange) matrices for two OLMo-1B training runs (tied and untied)."
- Logit lens: A technique that projects intermediate hidden states to token logits using the output projection matrix to inspect layerwise predictions. "The logit lens, introduced by \citet{nostalgebraist2020logitlens}, projects hidden states from intermediate layers into vocabulary distributions by applying the model's unembedding matrix ."
- Norm-frequency relationship: The empirical relationship between token embedding norms and token frequency in a corpus. "Norm-frequency relationship for OLMo-1B after 10k steps (20B tokens)."
- Orthogonal Procrustes analysis: A method to find the best rotation (orthogonal transform) aligning two vector spaces while preserving distances and angles. "With a Procrustes analysis \citep{schonemann1966}, which preserves distances and angles, we test whether the spaces differ only by a rotation transformation."
- Output projection matrix: The parameter matrix that maps final hidden states to vocabulary logits for prediction. "sharing parameters between the input embedding matrix and the output projection matrix improves performance while reducing parameter count in recurrent models."
- Residual stream: The running sum of layer outputs in a transformer that carries information forward across layers. "as the residual stream accumulates updates from each layer."
- Spectral distance: A comparison of embedding spaces based on their eigenvalue spectra (or related spectral properties) to assess structural similarity. "we instead use KNN overlap and spectral distance analysis (Appendix~\ref{app:appendix-knn})."
- Tuned lens: An extension of the logit lens that learns per-layer affine translators to better align intermediate representations with the output space. "The tuned lens (Section~\ref{subsec:logit-tuned-lens}) trains an affine translator at each layer to minimize the KL divergence between the translated hidden state's prediction distribution and the model's final output distribution."
- Unembedding bias: The tendency of a tied embedding matrix to become more similar to the output (unembedding) space than the input space due to training dynamics. "This unembedding bias arises because output gradients dominate early in training."
- Unembedding matrix: The matrix that projects hidden states back to vocabulary logits for next-token prediction. "The unembedding matrix serves a different function: it projects the final hidden states back to vocabulary-sized logits for next-token prediction."
- Weight tying: Sharing parameters between input and output embedding matrices so that one matrix serves both roles. "Weight tying, i.e. sharing parameters between input and output embedding matrices, is common practice in LLM design, yet its impact on the learned embedding space remains poorly understood."
Collections
Sign up for free to add this paper to one or more collections.