Reflected diffusion models adapt to low-dimensional data
Published 25 Mar 2026 in math.ST and stat.ML | (2603.24495v1)
Abstract: While the mathematical foundations of score-based generative models are increasingly well understood for unconstrained Euclidean spaces, many practical applications involve data restricted to bounded domains. This paper provides a statistical analysis of reflected diffusion models on the hypercube $[0,1]D$ for target distributions supported on $d$-dimensional linear subspaces. A primary challenge in this setting is the absence of Gaussian transition kernels, which play a central role in standard theory in $\mathbb{R}D$. By employing an easily implementable infinite series expansion of the transition densities, we develop analytic tools to bound the score function and its approximation by sparse ReLU networks. For target densities with Sobolev smoothness $α$, we establish a convergence rate in the $1$-Wasserstein distance of order $n{-\frac{α+1-δ}{2α+d}}$ for arbitrarily small $δ> 0$, demonstrating that the generative algorithm fully adapts to the intrinsic dimension $d$. These results confirm that the presence of reflecting boundaries does not degrade the fundamental statistical efficiency of the diffusion paradigm, matching the almost optimal rates known for unconstrained settings.
The paper demonstrates that reflected diffusion models achieve nearly optimal convergence rates in 1-Wasserstein distance when the target lies on a low-dimensional manifold.
It develops an explicit series expansion for transition densities and precise bounds on the score gradient, crucial for controlling estimation errors.
Sparse ReLU neural networks are employed for score function approximation, confirming that boundary reflections do not introduce statistical inefficiency.
Statistical Adaptivity of Reflected Diffusion Models to Low-Dimensional Data
Introduction
The paper "Reflected diffusion models adapt to low-dimensional data" (2603.24495) provides a rigorous analysis of score-based generative models constructed via reflected Brownian motion on bounded domains, specifically the hypercube [0,1]D. The authors analyze convergence properties when the target probability distribution is supported on compact, low-dimensional linear subspaces embedded in the ambient high-dimensional space. The work is motivated by practical scenarios where real-world datasets possess low intrinsic dimensionality relative to their ambient representation due to the manifold hypothesis. The central technical challenge addressed lies in the absence of Gaussian transition kernels for reflected Brownian motion, a structural property that underpins most minimax theory for unconstrained diffusion models.
Problem Setting and Formulation
The generative modelling framework consists of a forward SDE:
dXt=dBt+n(Xt)dLt,X0∼μ,
where n(x) is the inward-pointing normal vector at the boundary of [0,1]D, and Lt is the associated local time ensuring reflection at the boundary. The support of μ is a compact, d-dimensional manifold M⊂[0,1]D, with d≪D.
The reverse-time SDE for sample generation involves the time-inhomogeneous drift s0(x,t)=∇logpt(x), corresponding to the (unknown) score of the forward process’s density. Approximation of the score function is performed via empirical denoising score matching using sparse ReLU neural networks. The error metric of choice is the 1-Wasserstein distance between the law of the generative model at terminal time and the target measure μ, enabling proper comparison even when the target is singular.
Key Techniques: Series Expansions and Score Estimation
The absence of Gaussian kernels necessitates developing an explicit infinite series expansion for the transition densities of the reflected Brownian motion. Specifically, the transition from y to x in [0,1]D is represented as an alternating sum over the integer lattice, involving sign alternations and reflections of the path. Lemma~\ref{lem:explicit_score}, formalized in the paper, provides closed-form expressions for the transition density and its gradient:
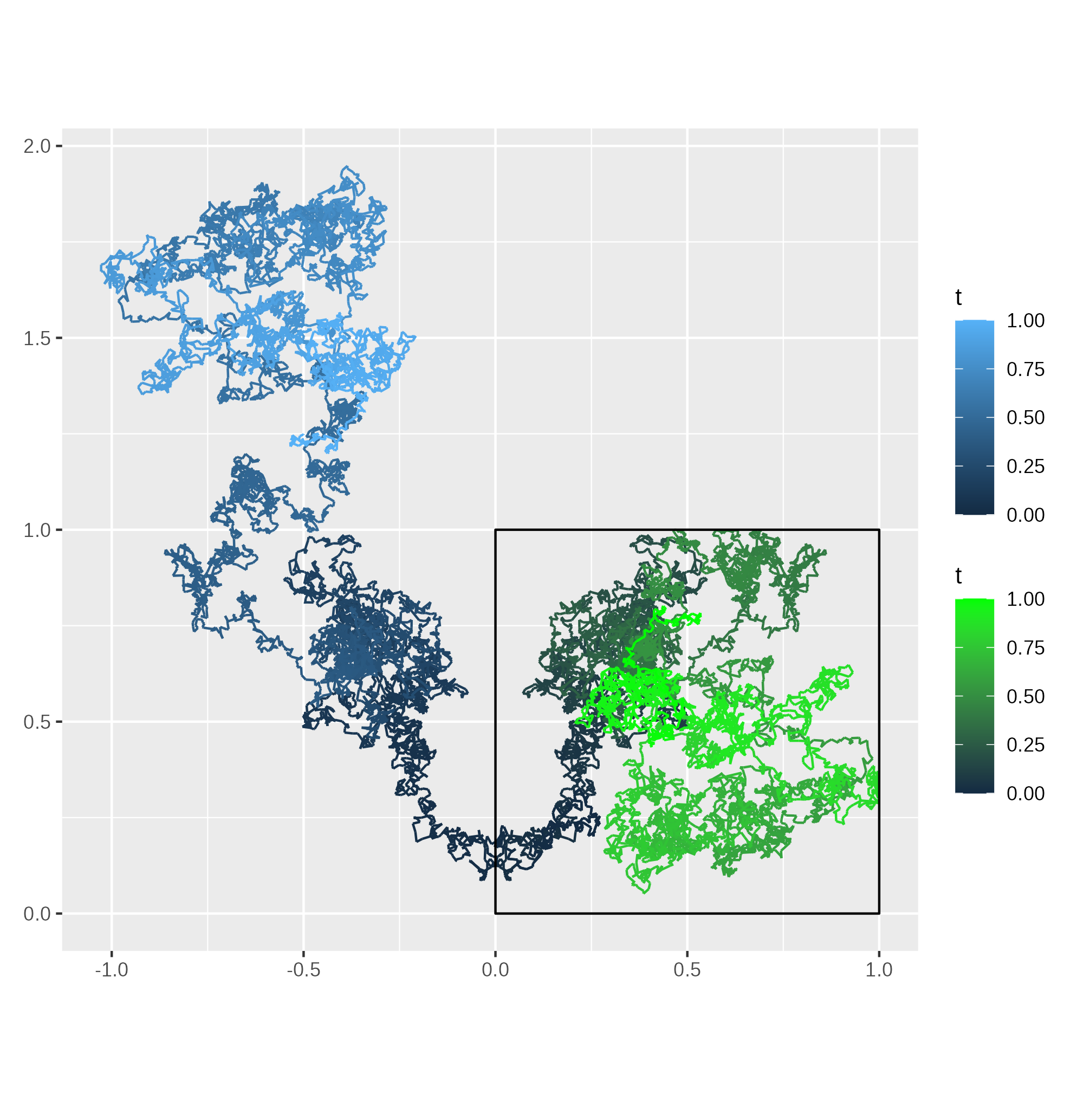
Figure 1: Simulation of a reflected Brownian motion (green) and its non-reflected version (blue).
This analytic handle allows the authors to derive upper and lower bounds on ∣∇logpt(x)∣ as a function of both t and the location of x relative to M, including the sharp spatial growth required for analysis of estimator complexity and error.
Score function estimation leverages the denoising score matching principle, where the minimization objective on each time interval is
E[∣s(Xt,t)−∇logqt(X0,Xt)∣2],
with qt the forward transition density from X0 to Xt. The neural network estimator is constructed as a piecewise composition of sub-interval-specific networks, each optimizing the empirical loss.
Main Statistical Results
The authors prove that the reflected diffusion generative scheme achieves a convergence rate in 1-Wasserstein distance given by
O(n−(α+1−δ)/(2α+d)),
for target densities in a Sobolev class of smoothness α supported in a d-dimensional manifold, and arbitrarily small δ>0. This matches (up to δ-slackness) rates for unconstrained diffusion models with unconstrained Gaussian kernels in RD—except that the ambient dimension D is replaced by the intrinsic dimensiond.
The analysis decomposes the total error into truncation (early stopping), initialization (stationary versus target marginal), and the main score approximation error. Upper bounds for the first two are shown to decay as Dt and exponentially fast in time with constants depending polynomially on D, while the main contribution is dominated by the score estimation term, for which neural network approximation rates are precisely characterized.
A significant and explicit claim of the paper is that reflection at the domain boundary does NOT introduce statistical inefficiency in the regime studied: the reflected setting adapts to the data’s intrinsic geometry as effectively as unconstrained models, under the relevant regularity assumptions.
Neural Network Complexity and Approximation
A central technical component is the demonstration that the score function (which inherits singularity in small t and high curvature from reflection and low-dimensional geometry) can be approximated by sparse ReLU networks with parameter counts and depth depending polynomially on n, logarithmically on D, and polynomially on the inverse of the target error. Separate constructions are provided as t→0 (concentration near M) and in large t (regularization by the diffusion), ensuring adaptability to multi-scale behavior inherent in the problem.
Theoretical and Practical Implications
The results have both theoretical and practical significance. From a theoretical perspective, the findings unify the statistical analysis of generative models under reflecting constraints with unconstrained theory, solidifying the manifold adaptivity phenomenon. In practice, the explicit construction of the empirical denoising score matching loss for reflected diffusions (and the associated tractable series representations and efficient approximations) provides a concrete recipe for building boundary-respecting generative models—critical for applications such as image and simulation data, where boundary constraints are non-negotiable.
On the neural estimation side, the scaling of complexity with the intrinsic dimension confirms, in a reflected process framework, what has been empirically and heuristically suggested in deep generative modeling for high-dimensional but structurally simple data.
Future Directions
The paper notes several natural extensions:
General Manifolds: The linear subspace constraint on M could be substantially relaxed to treat general Ck-smooth embedded submanifolds, though the analytic and approximation challenges increase due to lack of global coordinates.
Discretization and Numerical Error: The analysis is performed in the idealized setting with exact SDE solutions. Quantifying the additional error due to Euler or projected schemes for numerical sample generation with reflections is an open question.
Minimaxity and Lower Bounds: While almost optimal rates are achieved, fully closing the δ-inefficiency and extending to settings with minimal regularity (e.g., non-smooth densities, heavy tails) would round out the statistical theory.
Conclusion
This work delivers a comprehensive non-asymptotic error analysis of reflected diffusion generative models, demonstrating that reflection at the boundary does not impair adaptivity to low-dimensional geometric structure. The results provide a robust theoretical justification for manifold-aware generative modeling on bounded domains, and the methods developed open the door to practical implementations and further statistical refinement in boundary-respecting score-based models.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.