Foveated Diffusion: Efficient Spatially Adaptive Image and Video Generation
Abstract: Diffusion and flow matching models have unlocked unprecedented capabilities for creative content creation, such as interactive image and streaming video generation. The growing demand for higher resolutions, frame rates, and context lengths, however, makes efficient generation increasingly challenging, as computational complexity grows quadratically with the number of generated tokens. Our work seeks to optimize the efficiency of the generation process in settings where the user's gaze location is known or can be estimated, for example, by using eye tracking. In these settings, we leverage the eccentricity-dependent acuity of human vision: while a user perceives very high-resolution visual information in a small region around their gaze location (the foveal region), the ability to resolve detail quickly degrades in the periphery of the visual field. Our approach starts with a mask modeling the foveated resolution to allocate tokens non-uniformly, assigning higher token density to foveal regions and lower density to peripheral regions. An image or video is generated in a mixed-resolution token setting, yielding results perceptually indistinguishable from full-resolution generation, while drastically reducing the token count and generation time. To this end, we develop a principled mechanism for constructing mixed-resolution tokens directly from high-resolution data, allowing a foveated diffusion model to be post-trained from an existing base model while maintaining content consistency across resolutions. We validate our approach through extensive analysis and a carefully designed user study, demonstrating the efficacy of foveation as a practical and scalable axis for efficient generation.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a faster way for AI to make images and videos that still look great to people. The trick is to copy how human eyes work: we see very sharp detail only where we’re looking (the fovea), and things get blurrier in our side vision (the periphery). The authors use this idea to spend more computer power on the parts you’re actually looking at, and less on the rest—making generation quicker without hurting what you perceive.
The big idea in one sentence
Generate images and videos in “mixed resolution,” with high detail only near your gaze and lower detail farther away, so the AI does less work but you don’t notice a quality drop.
What questions did the researchers ask?
- Can we make image and video generation faster by matching human vision—high detail at the center of gaze, lower detail in the periphery?
- Can we do this inside modern AI models (Transformers used in diffusion and flow-matching) without breaking image quality?
- How much speed can we gain, and will people actually notice any difference?
How did they do it?
To follow the approach, it helps to translate a few technical ideas into everyday language:
- Tokens: Think of an image as a puzzle made of square pieces. In Transformer models, each piece is a “token.” More tokens = more computation.
- Diffusion/Flow matching: Imagine starting with TV static (random noise) and slowly un-blurring it into a real image, guided by a learned model.
- Latent space and a VAE: Instead of building the image pixel-by-pixel, the model works in a compact “secret language” (latent space) where images are easier to handle. A VAE encodes an image into that language and decodes it back.
Here’s their approach, step by step:
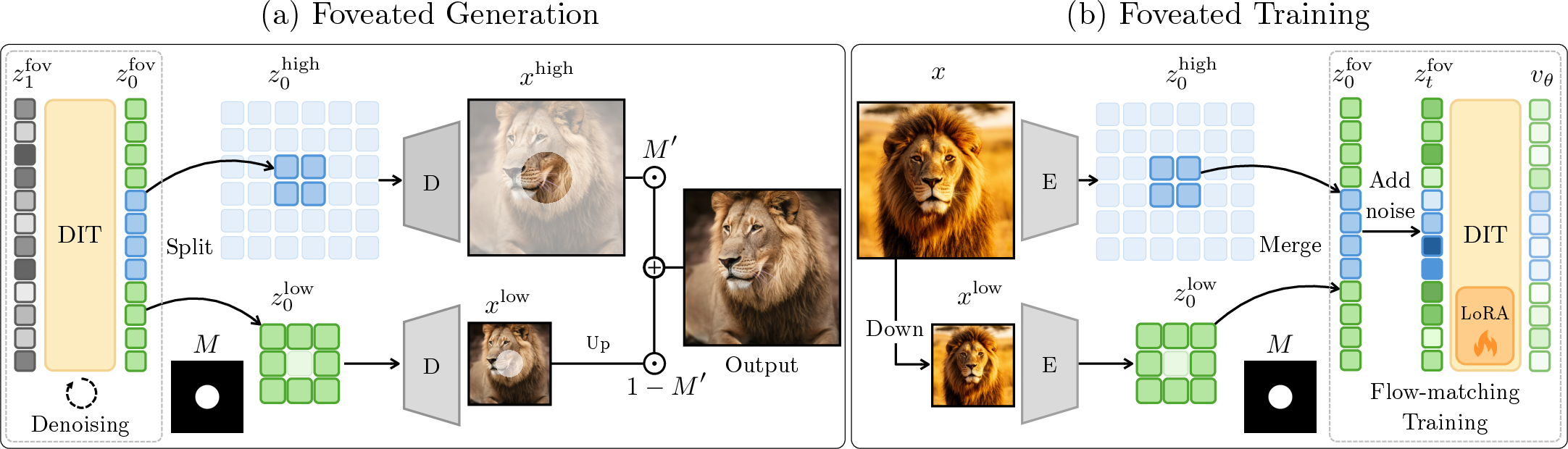
- Foveation mask (where to be sharp): They use a simple map that marks where your eye is looking (the “fovea”) and where it isn’t. The center gets high resolution; the rest gets lower resolution. This mask can come from eye tracking, a chosen region, or a saliency map (what’s likely to be interesting).
- Mixed-resolution tokens (pieces of different sizes): Near the gaze, they keep many small tokens (high detail). Farther out, they use fewer, bigger tokens (lower detail). This cuts the total number of tokens a lot, which matters because attention in Transformers gets expensive very fast as tokens grow (roughly like tokens squared).
- Teaching the model to handle mixed sizes: If you just mash high- and low-resolution tokens together without training, the model gets confused—things can duplicate or look misaligned. So they “post-train” (lightly fine-tune) an existing model:
- They make two versions of each training image: one high-res and one downsampled (low-res).
- They encode both into latent tokens and then “merge” them using the foveation mask (high-res tokens in the center, low-res tokens around).
- They train the model (with a method called flow matching) to transform noise into this mixed set of tokens smoothly.
- They also adjust how the model tracks “where each token belongs” so it stays accurate even when token sizes differ (a practical tweak to positional encoding).
- Putting it back together: After generation, they decode the high-res and low-res parts with the VAE and blend them into a single image (or video frame). You see sharp detail where you’re looking and smooth, plausible detail elsewhere.
- User testing: They ran a study where people compared results while fixating on a specific point (simulating where they look). The goal: check if people can tell the difference between full-resolution and the new foveated version.
What did they find, and why is it important?
- Faster generation with similar perceived quality:
- Images: up to about 2× faster.
- Videos: up to about 4× faster.
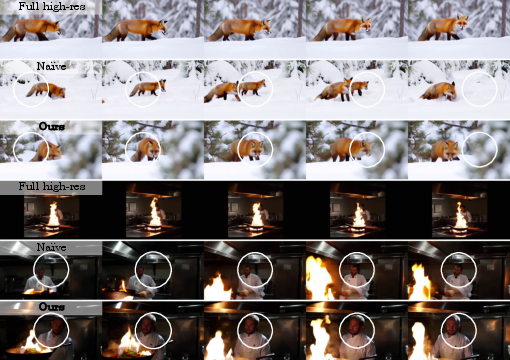
- People in the user study found the foveated results looked just as good as full-resolution most of the time, while a simple “naive” mixed-resolution trick (without proper training) produced visible mistakes.
- The naive approach fails: If you don’t fine-tune the model to handle mixed resolutions, you can get weird artifacts like duplicated objects, mismatched scales, or visible seams between regions.
- Flexible control: The method works with different mask shapes (like circles around gaze, saliency-based regions, or even bounding boxes) and can be used for both images and videos (for videos, the “fovea” can move across frames).
- Plays nicely with other speedups: This “foveation” trick reduces tokens (input size), which is a different axis from other Transformer speedups (like faster attention). You can combine them for even more gains.
Why it matters: As people want higher resolutions, longer videos, and more interactive experiences (like AR/VR or games), the cost of generation can explode. This method keeps things fast by focusing detail where you’ll actually notice it.
What could this lead to?
- Better real-time experiences: Faster, high-quality visuals for AR/VR, eye-tracked headsets, and interactive tools where your gaze is known.
- Longer, richer content: More frames, higher resolution, or longer context without blowing up compute and memory.
- Energy and cost savings: Less computation means cheaper and greener generation.
- Broader use in robotics and simulation: Efficiently generate only what matters most for perception or task performance.
In short, this paper shows a practical way to make AI image and video generation smarter and faster by aligning it with how we see. It spends detail where your eyes care—and saves time and compute where they don’t—without you noticing a difference.
Knowledge Gaps
Below is a single, action-oriented list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research.
- Dependence on accurate, low-latency gaze input: robustness to eye-tracker noise, latency, missing data, and saccades is not quantified; acceptable error budgets for mask misalignment are unknown.
- Dynamic foveation during generation: procedures for changing the foveation mask mid-sampling (e.g., during saccades) without re-noising or quality loss are not specified.
- Temporal foveation for video: impact of moving fovea on temporal consistency (especially at fovea/periphery boundaries) and flicker artifacts is unstudied.
- End-to-end real-time viability: the paper reports speedups for denoising but does not quantify full pipeline latency (gaze capture, mask computation, token restructuring, VAE decode/compose) or memory savings.
- Generalization across architectures: demonstrated on specific DiT/flow-matching models with VAEs; applicability to U-Net-based diffusion, rectified flow, standard DDPM/Score sampling, and different VAEs is not evaluated.
- Full-resolution capability after post-training: whether LoRA-adapted models retain original full-res quality (catastrophic forgetting) is not reported.
- Token downsampling limited to d=2 and two resolutions: no exploration of larger/variable downsampling factors, multi-scale rings, or continuous eccentricity-to-resolution mappings; optimal allocation strategies remain unknown.
- Boundary consistency: while qualitative examples look good, there is no quantitative measurement of seams or scale shifts at high–low resolution boundaries or ablation of blending strategies.
- Positional embedding choices: only a RoPE adaptation (per Wu et al.) is used; comparative studies with other positional encodings, indexing strategies, and their theoretical/empirical effects on mixed-resolution attention are missing.
- Mixed-resolution attention design: potential attention imbalance (e.g., high-res queries over/under-attending to low-res keys) is not analyzed; ablations on attention masks or weighting are absent.
- Construction of low-res targets: the choice to encode Down(x) via the VAE (vs. pooling in latent space or learned downsamplers) is not ablated; distributional mismatch and its downstream effects are unknown.
- Upsampling/downsampling operators: sensitivity to bicubic vs. other filters or learned super-resolution modules in the periphery is not evaluated.
- Training data and scale: image fine-tuning uses ~90k samples and LoRA rank 32; generalization to larger, more diverse datasets and higher LoRA ranks or full fine-tuning is untested.
- Mask design and saliency guidance: exact saliency methods, their reliability, and comparisons among mask strategies (random, saliency-guided, bounding boxes, task-driven) are not provided.
- Mapping from visual angle to pixels: practical calibration of eccentricity-based masks (display size, FOV, viewing distance) is not addressed, limiting deployment realism in AR/VR.
- Robustness to wrong or adversarial masks: failure modes when the mask does not include salient content or is adversarially chosen are not studied; graceful degradation strategies are unspecified.
- Video quality metrics: speedups are reported for videos, but perceptual/temporal metrics (e.g., FVD, VMAF, user studies) for foveated videos are absent.
- Perceptual evaluation depth: the user study protocol is only briefly described (and truncated); sample size, statistical power, viewing conditions, and generalization to free-viewing are unclear.
- Foveation-aware metrics: reliance on global metrics (FID, Precision, CLIP) ignores eccentricity; development and validation of foveation-weighted perceptual metrics is left open.
- Prompt alignment and global structure: while CLIP scores are reported, deeper evaluations (object counts, spatial layout, text rendering) under aggressive periphery reduction are missing.
- Diversity and mode coverage: impact of mixed-resolution tokenization on output diversity/recall is not assessed (e.g., precision–recall curves, intra-class diversity).
- Combination with other accelerations: empirical evaluation of additivity or interference with token merging, KV-caching, sparse/linear attention, and distillation is not presented.
- Sampling schedules and step allocation: whether different noise schedules or fewer denoising steps can be used in the periphery (adaptive step budgets) remains unexplored.
- Updating and refining previously peripheral regions: mechanisms to refine low-res areas to high-res later (e.g., after gaze shift) without artifacts or content drift are not described.
- Long-context and high-res scalability: behavior at 4K+ images or long-form video contexts is not evaluated; memory/computation scaling studies are missing.
- Task/utility trade-offs: for tasks where peripheral cues matter (navigation, situational awareness), the impact of reduced peripheral resolution on downstream performance is unquantified.
- Safety and bias considerations: reduced peripheral detail might obscure context or amplify biases; no safety evaluation or guidelines are discussed.
- Multi-user / multi-fovea scenarios: handling multiple simultaneous foveas (collaborative settings), stereo HMDs, and per-eye masks is unaddressed.
- Robustness across domains: adaptation to non-natural imagery (e.g., medical, diagrams, UI text) where peripheral detail is critical is not tested.
- Theoretical error bounds: no model relating token ratio, eccentricity profile, and perceptual error is provided; principled budget allocation remains an open problem.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now by pairing the paper’s foveated tokenization, mixed-resolution RoPE, and lightweight LoRA post-training with existing diffusion/flow-matching models. Each item notes sectors, potential tools/products/workflows, and feasibility dependencies.
- AR/VR real-time content acceleration (2× image, 4× video speedups)
- Sectors: gaming, entertainment, XR platforms
- What: Gaze-contingent image/video generation for dynamic backgrounds, effects, and scene dressing that remain perceptually indistinguishable to the viewer while cutting compute cost/latency.
- Tools/workflows:
- SDK integrating eye tracking (OpenXR/WebXR) → foveation mask → mixed-resolution tokenization → adapted RoPE → LoRA-tuned DiT → VAE decode/blend.
- Runtime knobs for token ratio vs. quality; mask smoothing around saccades; fallback to centered masks when gaze unavailable.
- Assumptions/dependencies: HMDs with low-latency eye tracking; ability to fine-tune (LoRA) target models; inference stack that supports variable-length token sequences and RoPE modifications.
- On-device mobile generative effects with pointer/region focus
- Sectors: consumer software, social media, cameras
- What: Use touch/cursor-driven masks as a proxy for gaze to accelerate on-device filters (stylization, background generation, inpainting) where the user is actively focusing.
- Tools/workflows: Mobile inference (e.g., PyTorch Mobile/ONNX), quantized DiTs with LoRA foveated adapters; UI that maps touch focus to masks.
- Assumptions/dependencies: No eye tracker needed; must handle frequent mask updates and guard against boundary artifacts.
- Interactive creative tools with focus-aware generation
- Sectors: design, media/creative software
- What: Foveated diffusion inside image/video editors for live preview, inpainting, and iterative prompting with a “focus ring” following the user’s zoom/brush or cursor.
- Tools/workflows: Plugins for ComfyUI/Automatic1111/Node-based editors; per-iteration mask control; batch decoding of HR/LR regions and blending.
- Assumptions/dependencies: Access to base latent diffusion models (e.g., FLUX/Wan); minimal UI changes to capture focus.
- Game engines: runtime generative texture and VFX synthesis
- Sectors: gaming, real-time engines (Unity/Unreal)
- What: Foveation-guided generation for textures, decals, skyboxes, and VFX near the crosshair/gaze; reduce compute while retaining fidelity where players look.
- Tools/workflows: Engine plugin bridging render loop with a lightweight inference service; per-frame mask updates; integration with existing foveated rasterization/shading.
- Assumptions/dependencies: Stable latency budgets; mask generation from gaze or view center; content safety/consistency checks across frames.
- Cloud inference cost and energy reduction for generative services
- Sectors: AI platforms, cloud providers, sustainability/FinOps
- What: Lower GPU-hours/$ and energy by serving mixed-resolution generation for human-facing outputs (previews, interactive experiences).
- Tools/workflows: A/B rollout with foveated LoRA adapters; autoscaling per token ratio; combined with FlashAttention/KV caching.
- Assumptions/dependencies: User acceptance testing; SLA tuning for latency/quality; model license permitting fine-tuning.
- Telepresence and video conferencing effects
- Sectors: communications, enterprise tools
- What: Foveated background synthesis/replacement and effects that prioritize the user’s fixation area (face, shared content region) to save compute.
- Tools/workflows: Desktop/mobile SDKs mapping face/attention detectors to masks; guardrails to preserve facial regions at HR by default.
- Assumptions/dependencies: Accurate attention estimation from webcam; robust blending around HR/LR boundaries.
- Robotics operator UIs and simulation previews
- Sectors: robotics, industrial, training sims
- What: Foveated overlays and generative sim content in teleop dashboards where operators focus, yielding reduced latency and compute.
- Tools/workflows: Operator gaze integration; saliency fallback; per-task mask templates.
- Assumptions/dependencies: Sub-50 ms E2E latency; clear policy to never downsample safety-critical cues.
- Education and training in XR
- Sectors: education, workforce training
- What: Gaze-centered high-fidelity generation for immersive lessons while keeping peripheral synthesis lightweight to run on modest hardware.
- Tools/workflows: Eye tracking → mask scheduler aligned to lesson flow; content-author tools to pin critical regions as HR.
- Assumptions/dependencies: Reliable HMDs; instructors can annotate must-be-HR elements to avoid hiding key details.
- Research: token-efficiency benchmarking and perceptual QA
- Sectors: academia, R&D labs
- What: Use the method as a testbed to study compute–quality tradeoffs and build eccentricity-aware metrics and user studies.
- Tools/workflows: Open-source reference implementation; scripts for mask generation, RoPE alignment, and mixed-resolution training.
- Assumptions/dependencies: Access to evaluation cohorts; standardized prompts/datasets.
Long-Term Applications
These use cases require further research, scaling, hardware co-design, validation, or standardization before broad deployment.
- Fully generative XR worlds at 60–120 FPS with gaze-contingent budgets
- Sectors: gaming, entertainment, XR platforms
- What: End-to-end generative scenes/world models updated in real time with foveation steering all DiT compute.
- Dependencies: Faster denoisers/solvers, model distillation, predictive saccade modeling, and robust video consistency across frames.
- Multi-user cloud XR with per-user foveated generation
- Sectors: cloud streaming, telecom
- What: Render different HR regions per viewer in shared scenes; tile-based delivery and per-client masks.
- Dependencies: Multi-stream orchestration; bandwidth/latency guarantees; server-side privacy protections for gaze.
- Automotive HUDs and driver assistance overlays
- Sectors: automotive, safety
- What: Gaze-aware, generatively enhanced HUD content focusing high fidelity only where the driver looks.
- Dependencies: Rigorous safety validation; standards for not downsampling safety-critical signals; fail-safe fallbacks when gaze unavailable.
- Surgical and clinical AR assistance
- Sectors: healthcare
- What: Surgeon-gaze-contingent overlays where only the foveal region is synthesized at maximum resolution to reduce device compute/heat.
- Dependencies: Clinical trials, regulatory approval, strict controls to prevent loss of critical peripheral information; certified datasets/models.
- Operating system–level foveated generative compositor for AR glasses
- Sectors: hardware/OS, consumer electronics
- What: System service that routes gaze masks to apps, enforces privacy, and orchestrates mixed-resolution generation across apps.
- Dependencies: Vendor support; cross-app scheduling; standards for mask APIs and GPU resource sharing.
- Hardware co-design for mixed-resolution attention
- Sectors: semiconductors, edge AI
- What: Accelerators and kernels that natively support variable-length, mixed-resolution token streams to maximize the paper’s gains.
- Dependencies: Compiler/runtime support; vendor adoption; benchmarks proving ROI.
- Standardization of foveated generation interfaces and privacy
- Sectors: policy, standards bodies
- What: Extend OpenXR/WebXR and ML inference APIs to specify foveation masks; codify gaze-data handling as sensitive biometric.
- Dependencies: Industry consensus; privacy regulation alignment (consent, on-device processing, retention limits).
- Saliency- or intent-driven foveation without eye trackers
- Sectors: consumer software, web
- What: Replace eye tracking with robust, prediction-based masks (saliency, cursor dynamics, head pose).
- Dependencies: More accurate and low-latency saliency/intent models; user studies to validate comfort/quality.
- Cross-modal adaptive tokenization (beyond vision)
- Sectors: multimodal AI, accessibility
- What: Temporal/spatially adaptive token allocation for audio/video/3D based on attention or task salience.
- Dependencies: New architectures and training schemes; perceptual metrics for other modalities.
- Advertising and personalized media
- Sectors: ad-tech, streaming media
- What: Gaze-contingent, dynamically generated creatives where only attended areas are HR, lowering cost at scale.
- Dependencies: Consent frameworks; bias/fairness audits; ad platform integrations.
- Benchmarks and metrics for eccentricity-aware quality
- Sectors: academia, standards
- What: Community datasets and evaluation protocols that weight perceptual quality by eccentricity and viewing behavior.
- Dependencies: Public datasets with consented gaze traces; tools for reproducible user studies.
Notes on Feasibility, Assumptions, and Dependencies
When planning deployments, consider these cross-cutting factors:
- Input signals for masks
- Eye tracking (best quality but requires hardware); alternatives include cursor/touch focus, saliency maps, bounding boxes, or task annotations.
- Low-latency tracking (<20–50 ms) and mask stability are critical to avoid perceptible boundary artifacts.
- Model and stack requirements
- Works best with latent DiT-based models and VAEs; requires mixed-resolution RoPE alignment and LoRA post-training with foveated targets.
- Inference framework must support variable sequence lengths and HR/LR decode/blend workflows.
- Quality and safety
- Always keep safety-/task-critical regions in HR; add hysteresis or padding around the fovea to mask saccade jitter.
- Validate with perceptually aligned user studies rather than pixel-uniform metrics alone (the paper shows HPSv2.1 better reflects human preference than FID in this setting).
- Privacy and compliance
- Treat gaze as sensitive biometric data; minimize collection, prefer on-device processing, and obtain explicit consent.
- Provide opt-out/fallback paths (centered masks or saliency) if gaze is not available or user declines.
- Business impact
- Expect 2× (images) to 4× (videos) speedups at ~25–30% token ratios, compounding with attention optimizations (e.g., FlashAttention, KV caching) for material cost and energy savings.
These applications translate the paper’s foveation-aware token allocation, mixed-resolution RoPE, and post-training method into practical workflows across sectors, balancing deployment readiness with constraints and responsible design.
Glossary
- Bicubic downsampling: An image resampling method that reduces resolution using bicubic interpolation. "The low-resolution token sequence is obtained by bicubically downsampling the image and encoding it:"
- CLIP score: A text–image alignment metric computed with CLIP to assess prompt compliance. "and measure prompt alignment using CLIP score \cite{radford2021clip}."
- Cross-attention: A transformer mechanism where queries attend to a different set of key/value tokens (e.g., conditioning). "However, the computational cost of DiTs is quadratic with respect to the input token count due to the expensive self- and cross-attention mechanisms \cite{vaswani2017attention}."
- Diffusion models: Generative models that synthesize data by iteratively transforming noise toward the data distribution via learned denoising dynamics. "Diffusion models have fundamentally reshaped visual generative modeling, setting new standards in photorealism, diversity, and controllability for both images and videos."
- Diffusion Transformer (DiT): A transformer-based architecture tailored for diffusion/flow matching generation in latent or pixel space. "Almost all modern diffusion and flow matching models are built on top of the Diffusion Transformer (DiT) architecture \cite{peebles2023dit}."
- Eccentricity-dependent acuity: The dependence of perceived visual resolution on retinal eccentricity, with lower acuity farther from gaze. "we leverage the eccentricity-dependent acuity of human vision: while a user perceives very high-resolution visual information in a small region around their gaze location (the foveal region), the ability to resolve detail quickly degrades in the periphery of the visual field."
- Eccentricity-dependent token allocation: Assigning more tokens near the fovea and fewer in the periphery based on human acuity falloff. "Our key idea is eccentricity-dependent token allocation: given a foveation mask that defines the high-acuity foveal region, we allocate higher token density near the fovea and progressively fewer tokens toward the periphery, enabling spatially adaptive computation aligned with human perceptual sensitivity."
- Flow matching: A continuous-time generative training paradigm that learns a velocity field transporting a simple prior to the data via optimal transport. "Flow matching \cite{lipman2023flow} reformulates diffusion as a continuous-time optimal transport problem between the data distribution and a simple prior, usually a Gaussian distribution ."
- Foveal region: The small central area of highest visual acuity around the gaze point. "humans are able to perceive very high-resolution visual information in a small region around their gaze location (the foveal region) but their ability to resolve detail rapidly degrades in the visual periphery"
- Foveated Diffusion: The paper’s proposed framework for mixed-resolution, gaze-contingent diffusion/flow generation that reduces tokens while preserving perceptual quality. "With this work, we introduce the concept of Foveated Diffusion and develop a practical framework for post-training existing image or video generation models for foveated visual generation."
- Foveated rendering: A gaze-contingent rendering strategy that allocates higher resolution near the fixation point and lower resolution in the periphery to save compute. "Foveated rendering refers to the spatially adaptive computation where computational resources are allocated unevenly across the image according to a specified user gaze location."
- Foveation mask: A (typically binary) spatial map indicating which regions should be synthesized at high vs. low resolution based on gaze/eccentricity. "Our framework starts with a foveation mask that guides the spatial layout of non-uniformly distributed tokens over the image or video frame that we wish to generate."
- Fréchet Inception Distance (FID): A generative quality metric measuring distributional distance between generated and real image features. "FID may not be a reliable metric for evaluating foveated visual generation, as the naïve baseline, despite exhibiting clear structural artifacts (see Fig. \ref{fig:baseline_image}), even outperforms full high-resolution generation."
- Gaussian splats: A point-based scene representation that renders scenes using anisotropic Gaussian primitives. "to accelerate the rendering of Neural Radiance Fields (NeRFs) \cite{mildenhall2020nerf} and Gaussian splats \cite{kerbl3Dgaussians} for immersive displays."
- HPSv2.1: A human preference–based metric for assessing perceived quality of generated images. "Importantly, our method significantly surpasses the naïve baseline on a human preferenceâaligned metric HPSv2.1 \cite{wu2023hps}, reinforcing the perceptual, human-centered focus of our approach."
- KV caching: Caching transformer key/value tensors to reduce repeated attention computation across timesteps or frames. "Existing techniques for reducing the computational cost of Diffusion Transformers (DiTs) include hardware-aware optimizations \cite{dao2022flashattention}, sparse-attention mechanisms \cite{zhang2025spargeattn, xi2025sparsevideogen}, KV caching \cite{yin2025causvid, huang2025selfforcing}, and token merging \cite{bolya2022tome, lu2025toma}."
- Latent space: A compressed feature space where images/videos are encoded for more efficient training and sampling. "Modern large-scale diffusion models operate in a compressed latent space to improve computational efficiency \cite{peebles2023dit, rombach2022latent}."
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning approach that injects low-rank updates into pretrained weights. "All models are fine-tuned using Low-Rank Adaptation (LoRA) \cite{hu2022lora} with rank 32."
- Mixed-resolution tokenization: Representing different regions with tokens at different spatial scales to reduce sequence length. "We develop a simple yet highly effective mixed-resolution tokenization scheme, accompanied by a suitable modification of Rotary Positional Embeddings (RoPE)~\cite{su2024roformer,wu2025crpa}, along with a post-training strategy that transforms high-resolution pretrained models into foveated generative models."
- Neural Radiance Fields (NeRFs): Neural scene representations that model view-dependent radiance and density for novel view synthesis. "to accelerate the rendering of Neural Radiance Fields (NeRFs) \cite{mildenhall2020nerf} and Gaussian splats \cite{kerbl3Dgaussians} for immersive displays."
- Ordinary Differential Equation (ODE): A differential equation used here to deterministically integrate the learned flow during sampling. "At inference time, data samples are generated through sampling $\latent[1]$ and solving the flow ODE: $\frac{d}{dt} z_t = v_\theta(\latent[t], t)$."
- Optimal transport: A mathematical framework for transforming one probability distribution into another with minimal cost. "Flow matching \cite{lipman2023flow} reformulates diffusion as a continuous-time optimal transport problem between the data distribution and a simple prior, usually a Gaussian distribution ."
- Rotary Positional Embeddings (RoPE): A positional encoding that rotates feature pairs to encode token positions, adapted here for mixed resolutions. "We develop a simple yet highly effective mixed-resolution tokenization scheme, accompanied by a suitable modification of Rotary Positional Embeddings (RoPE)~\cite{su2024roformer,wu2025crpa}, along with a post-training strategy that transforms high-resolution pretrained models into foveated generative models."
- Saliency maps: Maps estimating visually important regions, often used to prioritize high-resolution processing. "However, distinct from our gaze-contingent perspective, these works typically rely on saliency maps to characterize high-resolution regions."
- Self-attention: A transformer mechanism where tokens attend to other tokens in the same sequence to aggregate context. "However, the computational cost of DiTs is quadratic with respect to the input token count due to the expensive self- and cross-attention mechanisms \cite{vaswani2017attention}."
- Sparse-attention mechanisms: Attention variants that reduce complexity by limiting attention to a subset of token pairs. "Existing techniques for reducing the computational cost of Diffusion Transformers (DiTs) include hardware-aware optimizations \cite{dao2022flashattention}, sparse-attention mechanisms \cite{zhang2025spargeattn, xi2025sparsevideogen}, KV caching \cite{yin2025causvid, huang2025selfforcing}, and token merging \cite{bolya2022tome, lu2025toma}."
- Spatiotemporal (3D) attention: Attention operating jointly across spatial and temporal dimensions in video models. "Video models achieve higher speedup due to the higher computational cost of spatiotemporal (3D) attention operations."
- Token merging: Techniques that combine similar tokens to shorten sequences and reduce compute. "Existing techniques for reducing the computational cost of Diffusion Transformers (DiTs) include hardware-aware optimizations \cite{dao2022flashattention}, sparse-attention mechanisms \cite{zhang2025spargeattn, xi2025sparsevideogen}, KV caching \cite{yin2025causvid, huang2025selfforcing}, and token merging \cite{bolya2022tome, lu2025toma}."
- Token Ratio: The fraction of the reduced token sequence length relative to the full sequence length. "We define Token Ratio as the proportion of the reduced sequence relative to the full sequence and measure the resulting computational savings compared to full high-resolution generation as Speedup."
- Two-Alternative Forced Choice (2AFC): A psychophysics experimental protocol where participants choose the preferred stimulus between two options. "We therefore perform a Two-Alternative Forced Choice (2AFC) user study under a pseudo-eye-tracked protocol."
- Variational autoencoder (VAE): A generative encoder–decoder model used here to map images/videos to and from a latent space. "a variational autoencoder (VAE) \cite{Diederik_2019}, consisting of an encoder and a decoder , maps it into a latent representation (images) or (videos, with additional frame dimension ), where the diffusion process is defined."
- Velocity field: In flow matching, the learned vector field that specifies how to transport latent variables over time. "flow matching learns a velocity field that deterministically transports samples along straight-line paths in latent space."
- Visual eccentricity: The distance from the gaze center on the retina, used to model acuity falloff and drive foveation masks. "Formally, we define a binary foveation mask constructed from visual eccentricity, where denotes high-resolution (HR) regions near the fovea and denotes low-resolution (LR) peripheral regions."
Collections
Sign up for free to add this paper to one or more collections.