Online Experiential Learning for Language Models
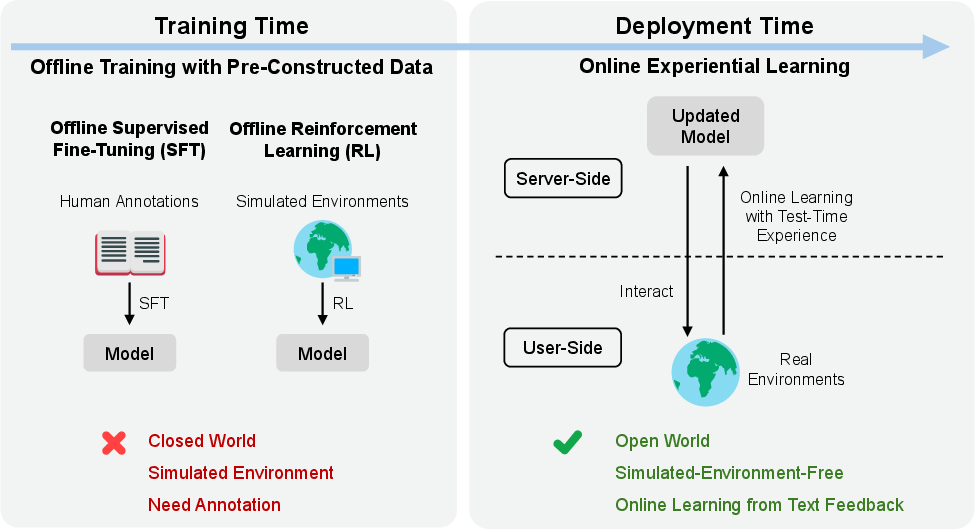
Abstract: The prevailing paradigm for improving LLMs relies on offline training with human annotations or simulated environments, leaving the rich experience accumulated during real-world deployment entirely unexploited. We propose Online Experiential Learning (OEL), a framework that enables LLMs to continuously improve from their own deployment experience. OEL operates in two stages: first, transferable experiential knowledge is extracted and accumulated from interaction trajectories collected on the user side; second, this knowledge is consolidated into model parameters via on-policy context distillation, requiring no access to the user-side environment. The two stages are iterated to form an online learning loop, where the improved model collects higher-quality trajectories that yield richer experiential knowledge for subsequent rounds. We evaluate OEL on text-based game environments across multiple model scales and both thinking and non-thinking variants. OEL achieves consistent improvements over successive iterations, enhancing both task accuracy and token efficiency while preserving out-of-distribution performance. Our analysis further shows that extracted experiential knowledge is significantly more effective than raw trajectories, and that on-policy consistency between the knowledge source and the policy model is critical for effective learning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for AI LLMs to keep getting better after they’ve been released into the real world. Instead of only learning from data prepared ahead of time by humans, the model learns from its own experiences while people use it. The authors call this idea “Online Experiential Learning” (OEL).
What questions did the researchers ask?
- Can a LLM improve by learning from the text feedback it gets during real use, without special rewards or extra labels from people?
- How can we turn messy interaction logs (what the model tried and what happened) into helpful tips the model can actually learn from?
- Can the model learn these tips in a way that keeps its general abilities while also making it better and more efficient at tasks?
- Is it better to learn from your own experiences than from someone else’s?
How did they do it?
Think of the model like a player learning a new video game:
- The model plays the game and keeps a diary of what it did and what happened next. Each “diary” is a trajectory—basically a step-by-step record of actions and the game’s text feedback (like “you hit a wall” or “you reached the goal”).
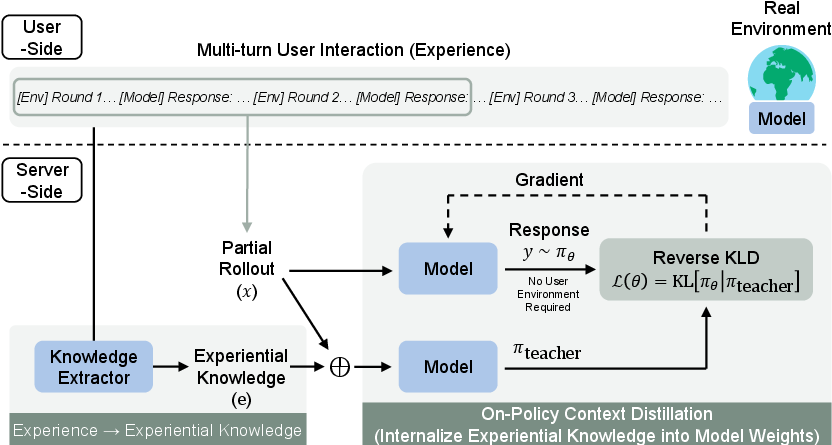
- Turning experiences into useful tips:
- The model reads its own diaries and writes down short, reusable “experience notes.” These are lessons like “Don’t try to walk through walls” or “If you see a hole, go around it.” The paper calls these notes “experiential knowledge.”
- This is important because raw diaries are long and messy. The notes are short, clear, and reusable across similar situations.
- Baking the tips into the model:
- The team uses a training step called “on-policy context distillation.” Here’s a simple analogy:
- Teacher: the model with the “experience notes” in front of it.
- Student: the same model, but without the notes.
- The student practices responding and tries to match the teacher’s answers. Over time, the student “absorbs” the teacher’s knowledge so it no longer needs the notes.
- “On-policy” just means the student is trained on the kind of answers it would actually produce—learning from its own attempts—so practice matches real use.
- The team uses a training step called “on-policy context distillation.” Here’s a simple analogy:
- Repeat the loop:
- After training, the improved model goes back out to play more. It collects better diaries, writes better notes, and learns even more. This creates a cycle of continuous improvement.
Important details:
- No reward scores or special human labels are needed—only the normal text feedback that the environment already gives.
- The server that trains the model doesn’t need live access to the user’s environment; it trains from the collected text histories.
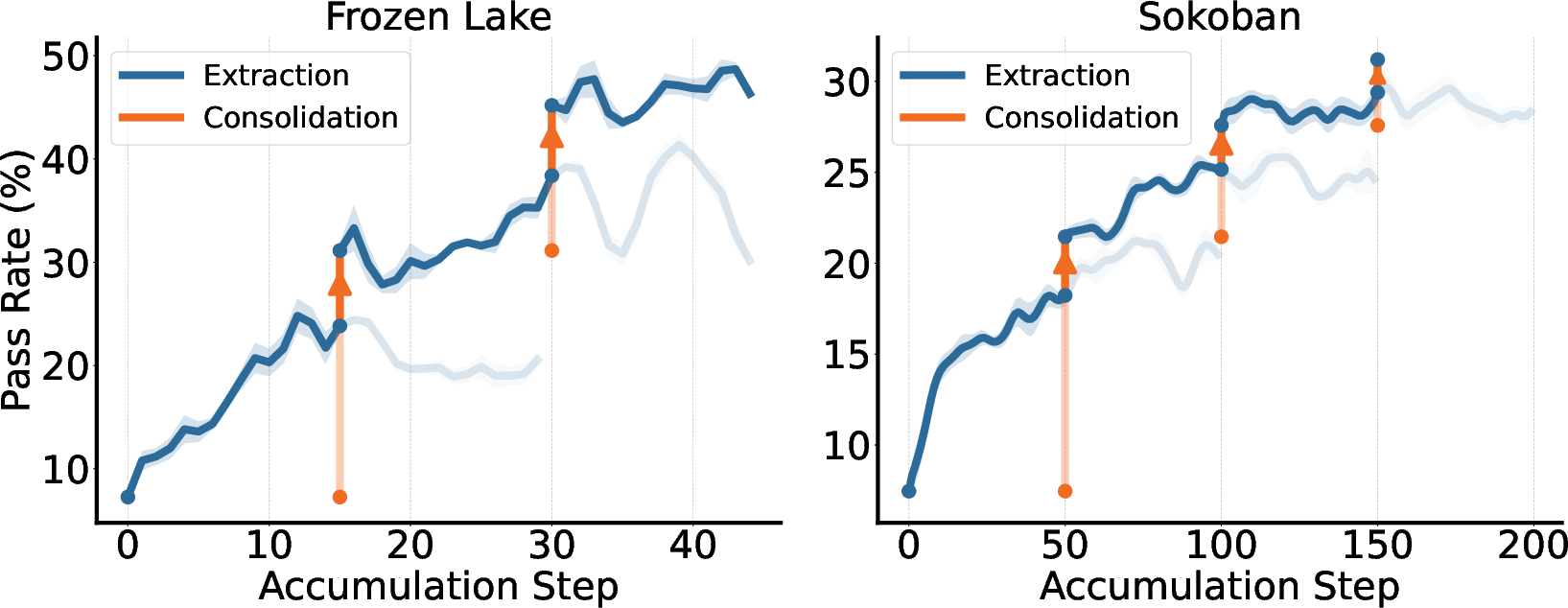
- The authors tested this on text-based games (like Frozen Lake and Sokoban), where the model has to plan moves using only text.
What did they find?
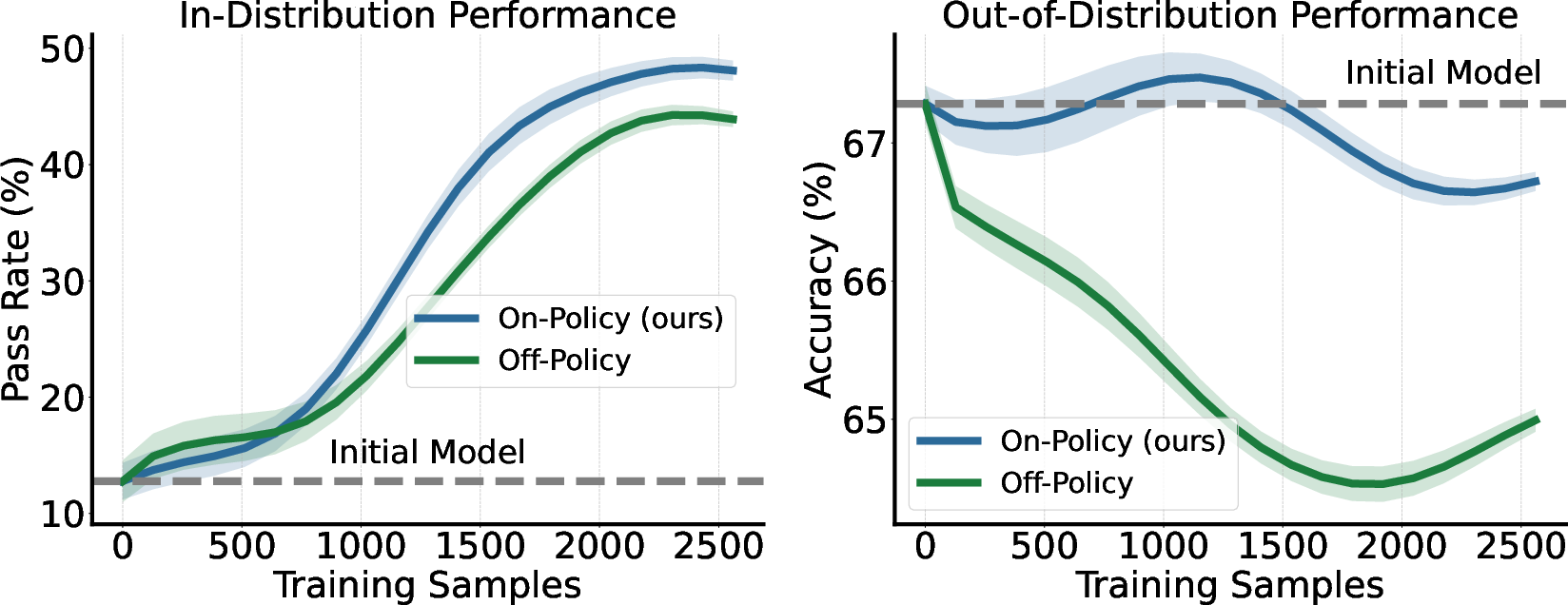
Across multiple model sizes and types, the OEL loop consistently helped. Here are the main results and why they matter:
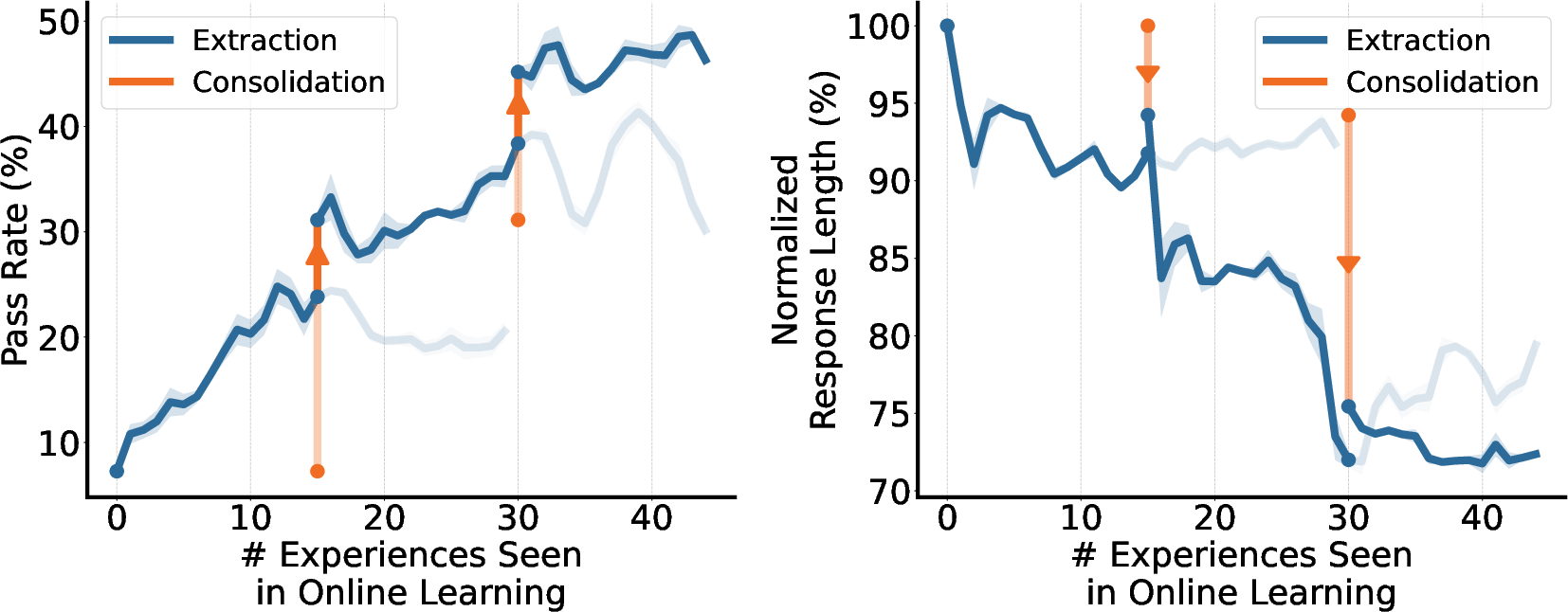
- Better task performance over time:
- With each cycle, the model solved more game levels (“higher pass rate”).
- Why it matters: It shows the model can truly learn from experience, not just from pre-made training data.
- More efficient answers:
- The model needed fewer words to reach the right answer after a few rounds.
- Why it matters: Shorter responses can be faster and cheaper while staying accurate.
- Keeps general skills:
- Their training method helped the model improve on the games without losing performance on unrelated tests (this helps avoid “forgetting”).
- Why it matters: You don’t want a model that gets better at one thing but worse at others.
- “Experience notes” beat raw logs:
- Teaching the model with clean, extracted tips worked much better than using the raw interaction histories.
- Why it matters: Summarizing experience into lessons is key for effective learning.
- Learning from your own experience works best:
- A model learned more from notes extracted from its own games than from notes made by a larger, stronger model.
- Why it matters: Tips must match the learner’s abilities and style; personalized experience helps.
- Works for different sizes:
- Bigger models tended to achieve higher scores, but all sizes improved round after round.
- Why it matters: The approach scales and is broadly useful.
Why does this matter?
- Continuous improvement after deployment:
- Instead of staying frozen, models can keep learning safely and practically from real use.
- Less need for costly labels or reward systems:
- No extra reward models, human grading, or simulations are required—just the normal text feedback the model already gets.
- Efficient and practical:
- Training happens on the server using collected text; the model doesn’t need live access to user environments.
- Broad potential:
- This could help assistants, tutors, coders, and other AI tools steadily improve as they’re used, while keeping their general knowledge.
In short, this paper shows a simple but powerful idea: let models learn from their own experiences by turning those experiences into clear lessons and then baking those lessons into the model. It’s like keeping a smart learning journal—one that makes the model better, faster, and more reliable over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of unresolved issues the paper leaves open. Each item is phrased to be concrete and actionable for follow-up research.
- External validity: Results are limited to two small, text-based games (Frozen Lake, Sokoban) with short horizons (≤5 turns). It remains unknown how OEL scales to complex, long-horizon, partially observable, or real-world agent tasks (tool use, coding, web interaction, robotics).
- Non-stationary environments: The framework does not address how to maintain performance as deployment environments evolve (concept drift), nor how to detect, adapt to, or rollback from distribution shifts during continuous updates.
- Broader OOD robustness: OOD retention is evaluated only on IF-Eval; impacts on reasoning, math/code, multilingual, safety, and long-context capabilities remain unmeasured across many rounds.
- Exploration–exploitation balance: Iterative “better policy → better trajectories” may reduce exploration and entrench suboptimal strategies. No mechanisms or diagnostics are provided to preserve diversity (e.g., scheduled temperature, stochasticity, intrinsic motivation).
- Multi-turn/sequence-level learning: Consolidation uses single-turn, token-level reverse KL on student rollouts; the method does not exploit multi-turn credit assignment or sequence-level objectives that could better capture long-horizon dependencies.
- Teacher choice and schedule: The teacher is a frozen initial model conditioned on knowledge. It is unknown whether using an EMA teacher, periodically refreshed teacher, ensemble teachers, or a stronger external teacher would yield better stability and gains.
- Objective design and stability: Reverse KL is mode-seeking and trained on student tokens; the paper lacks analysis of instability, mode collapse, or coverage loss, and does not compare against mixed KLs, trust-region constraints, or entropy regularization.
- Knowledge extraction reliability: Extraction uses the same model () without verification. There is no mechanism to detect hallucinated or incorrect “experiential knowledge,” quantify its quality, or mitigate error propagation across rounds.
- Knowledge selection and aggregation: The method generates K accumulated knowledge sets with different seeds and samples one uniformly. There is no deduplication, conflict resolution, ranking, clustering, or quality-weighted aggregation across runs.
- Format design: The impact of structured vs unstructured knowledge is not systematically studied (beyond feasibility). It is unknown which schemas, ontologies, or task-specific templates maximize transfer and consolidation efficiency.
- Relevance retrieval: Experiential knowledge is sampled uniformly for all prefixes. There is no retrieval or routing to select knowledge relevant to a given prefix/task, leaving open negative transfer and context interference.
- Context-length saturation: Accumulation saturates due to context limits (). The paper does not explore compressive summarization, retrieval-augmented memory, deduplication, or long-context models to overcome this bottleneck.
- Negative transfer across tasks: The method merges experiences from multiple trajectories/environments without guardrails. How to prevent interference, scope knowledge to tasks, and modularize or isolate domain-specific experience remains open.
- Continual learning guarantees: There is no theoretical analysis of convergence, monotonic improvement, stability across iterations, or conditions under which OEL degrades capabilities.
- Sample/compute efficiency: The work lacks a cost–benefit analysis (tokens, compute, wall-clock) and comparisons to alternatives (SFT on trajectories, reflection-only, RLHF/RLAIF, offline/online RL from textual feedback).
- Longer horizons and deeper interaction budgets: Experiments cap per-episode turns and response length. The impact of longer rollouts, deeper decision trees, and persistent states on extraction and consolidation remains untested.
- Real-world deployment logistics: The paper does not address update cadence, A/B testing, shadow deployment, rollback, and safety gates required to productionize an online learning loop.
- Privacy, security, and governance: User-side trajectories can contain sensitive data. The work does not provide anonymization, filtering, differential privacy, federated variants, data minimization, or consent mechanisms.
- Poisoning and adversarial feedback: OEL trusts textual feedback. The framework lacks defenses against malicious environments/users injecting misleading “experience” to corrupt knowledge and the policy.
- Evaluation of knowledge correctness: There is no human or automatic evaluation of extracted items for factuality, faithfulness to environment dynamics, or utility; no automated validators or rule-checkers are used.
- Robustness to parser/format failure: Structured extraction relies on a fixed marker (“-- EXPERIENCE ITEM:”). The paper does not address recovery from formatting errors, schema drift, or multilingual content.
- Chain-of-thought handling: For thinking models, reasoning is discarded and only answers are kept as knowledge. The trade-off between including distilled rationales vs answer-only signals, and their effect on safety and generalization, is unexplored.
- Teacher–student mismatch over rounds: As the student improves, a frozen teacher may become suboptimal. The impact of this mismatch on learning dynamics and potential performance ceilings is not analyzed.
- Cross-scale transfer: It is unclear how well experiential knowledge transfers between model sizes (small→large, large→small), domains, or architectures, and whether alignment/matching layers are required.
- Scheduling of loop components: The paper fixes numbers of trajectories, extraction steps, and consolidation steps per round; optimal scheduling, adaptive stopping, and budget allocation policies are not studied.
- Metric completeness for “efficiency”: Token-length reductions are reported, but not step-to-goal, wall-clock latency, energy, or compute efficiency; disentangling “shorter outputs” from true reasoning efficiency is unaddressed.
- Handling ambiguous/noisy outcomes: Many real environments provide partial, inconsistent, or delayed signals. The method assumes informative textual feedback; robustness to ambiguity and uncertainty quantification is untested.
- Federated/edge OEL: Centralized collection of trajectories may be impractical. Federated or on-device extraction/consolidation with tight communication/privacy constraints remains an open systems direction.
- Safety and alignment drift: Iteratively internalizing deployment experience could accumulate unsafe or biased behaviors. The paper does not include safety evaluations, red-teaming, or constraint-based training during consolidation.
- Data routing across environments: When mixing trajectories from multiple environments/users, there is no mechanism to route or tag experience by environment, task, or user segment to guide targeted consolidation.
- Catastrophic forgetting over many rounds: While on-policy distillation helps on a single OOD benchmark, long-run drift and retention across many more rounds and domains is not characterized.
- Theoretical link to policy improvement: The intuition that a knowledge-conditioned teacher “acts like a reward” is not formalized. Conditions under which reverse KL to the teacher provably improves environment performance are unknown.
- Instrumentation requirements: The approach assumes access to clean interaction logs and textual feedback. The practicality of instrumenting heterogeneous real systems to produce such logs is not discussed.
Practical Applications
Practical Applications of Online Experiential Learning (OEL)
Below are actionable applications derived from the paper’s framework, findings, and innovations. Each application is categorized by deployment horizon, linked to relevant sectors, and includes potential tools/products/workflows and assumptions or dependencies that may affect feasibility.
Immediate Applications
The following use cases can be prototyped or deployed now with existing LLMs, logging infrastructure, and the open-source OEL implementation.
- Continuous self-improving customer support chatbots
- Sector: software, consumer services, enterprise IT
- Tools/products/workflows: deploy chatbots that log multi-turn interactions; run server-side “experiential knowledge extraction” to produce structured items (e.g., “EXPERIENCE ITEM: When shipping address contains PO Box, use carrier X”); perform on-policy context distillation to internalize these items; iterate weekly; monitor OOD performance to mitigate forgetting
- Assumptions/dependencies: reliable textual feedback from CRM/helpdesk systems (resolution messages, escalation notes); data governance and privacy compliance; trajectory filtering and safety checks to avoid learning from adversarial or erroneous interactions
- Developer co-pilots and DevOps assistants that learn from errors and CI/CD logs
- Sector: software engineering, DevOps
- Tools/products/workflows: instrument IDE and CI pipelines to collect trajectories (compile errors, test failures, deployment rollbacks); extract structured remediation heuristics; consolidate into the assistant to reduce trial-and-error and token usage; nightly OEL rounds integrated with MLOps (evaluation gating, rollback procedures)
- Assumptions/dependencies: mapping non-text signals (exit codes, stack traces) into textual feedback; adequate telemetry and consent; safeguards against memorizing secrets in logs; compute budget for periodic consolidation
- Enterprise knowledge-base maintenance via experience distillation
- Sector: knowledge management, enterprise operations
- Tools/products/workflows: “Experience Hub” that ingests tickets/runbooks/incidents, outputs structured experiential items and consolidates them into a domain model; reduces reliance on long retrieval contexts by compressing relevant know-how into weights; regular drift audits
- Assumptions/dependencies: high-quality, diverse trajectories; deduplication and conflict resolution of experiential items; validation workflows to prevent propagating incorrect practices
- Adaptive tutoring systems that learn local curricula and common misconceptions
- Sector: education (K–12, higher ed, corporate training)
- Tools/products/workflows: capture student–tutor interaction trajectories (questions, corrections, misconceptions); extract knowledge like “If student confuses A with B, use analogy C”; consolidate to improve accuracy and reduce verbosity (token efficiency); monitor OOD tasks to avoid overfitting
- Assumptions/dependencies: student privacy and parental consent; guardrails to avoid reinforcing misconceptions; in-platform logging of textual feedback from students/teachers
- Healthcare operational assistants for workflow guidance (non-diagnostic)
- Sector: healthcare administration, revenue cycle, EHR operations
- Tools/products/workflows: assistants learn from textual feedback such as “order rejected due to missing ICD code” or “prior authorization needed”; extract institutional policies as experiential items; consolidate to streamline documentation and scheduling
- Assumptions/dependencies: HIPAA-compliant logging and de-identification; clear scoping to non-clinical decision support; safety review and audit; robust filtering of noisy EHR messages
- Finance operations and compliance copilot
- Sector: finance (banking operations, AML/KYC, back office)
- Tools/products/workflows: ingest textual error/status feedback (e.g., “KYC incomplete: missing document X”); extract workflow fixes and compliance steps; consolidate into a copilot that reduces resolution time and tokens
- Assumptions/dependencies: strong audit trails and versioning; regulator-approved governance; protection against learning from rare, idiosyncratic cases that could reduce generalization
- Public-sector service chatbots that adapt to policy changes
- Sector: government/policy, public services
- Tools/products/workflows: capture interactions and agency-issued textual updates; extract new policy rules as experiential items; consolidate while monitoring OOD performance to limit forgetting; use gating to prevent unsafe drift
- Assumptions/dependencies: transparent change control; independent evaluation and red-teaming; mechanisms to prevent policy misapplication or data poisoning
- Game and interactive narrative agents that improve with play
- Sector: gaming, interactive entertainment
- Tools/products/workflows: apply OEL’s loop to game agents; log moves and textual state descriptions; extract strategies; consolidate to increase pass rates and reduce token usage; ship as “self-optimizing” agents
- Assumptions/dependencies: game state must be available as textual feedback; generalized strategies may not transfer across titles without adaptation
- Cost optimization through token-efficiency gains
- Sector: any LLM-heavy application
- Tools/products/workflows: use OEL consolidation to internalize reasoning patterns, reducing average response length and API costs; instrument cost dashboards to quantify savings
- Assumptions/dependencies: consistent token-length reductions without harming utility; budget for periodic retraining; guard against terse but incomplete responses
Long-Term Applications
These use cases require further research, scaling, multimodal extensions, stronger safety/federation primitives, or broader organizational adoption.
- Privacy-preserving OEL via federated/on-device extraction and consolidation
- Sector: consumer devices, healthcare, finance
- Tools/products/workflows: on-device experiential extraction; federated or differentially private on-policy distillation; cross-silo aggregation of experiential items; personalizable model variants
- Assumptions/dependencies: efficient on-device inference/training; robust privacy guarantees; reconciliation of heterogeneous experiential knowledge across silos
- Multimodal OEL for robotics and UI agents
- Sector: robotics, RPA, autonomous UI agents
- Tools/products/workflows: extend OEL to handle non-text feedback (sensor streams, screenshots) via multimodal teachers; convert environment signals to rich textual or multimodal feedback; consolidate to improve dexterity and reliability over time
- Assumptions/dependencies: high-quality multimodal encoders; safe deployment frameworks; conversion fidelity from raw signals to learnable feedback; extensive evaluation for safety-critical tasks
- End-to-end autonomous enterprise workflows (self-optimizing RPA)
- Sector: enterprise ops, supply chain, procurement
- Tools/products/workflows: instrument entire workflows (forms, approvals, error messages) as trajectories; extract cross-step heuristics; consolidate into agents that reduce manual escalations and rework
- Assumptions/dependencies: robust exception handling; change management; layered access controls; avoidance of compounding learned errors across steps
- Safety hardening through continuous red-team feedback internalization
- Sector: AI safety, platform governance
- Tools/products/workflows: pipeline to ingest red-team textual findings; extract safety “do-not” patterns; on-policy distillation to reduce unsafe responses while maintaining OOD performance; automated safety regression suites
- Assumptions/dependencies: poisoning-resistant extraction; strong curation to avoid overfitting to test artifacts; transparent trade-offs between safety and utility
- Domain-wide experience commons and benchmarking
- Sector: academia, standards bodies
- Tools/products/workflows: shared repositories of anonymized trajectories and experiential items; OEL benchmarks across domains; standardized OOD metrics to study forgetting and generalization
- Assumptions/dependencies: community participation and governance; legal frameworks for trajectory sharing; reproducible evaluation pipelines
- Regulatory frameworks for continuous-learning systems
- Sector: policy/regulation, compliance
- Tools/products/workflows: change-control standards (documentation of each consolidation round), auditability of experiential items, safety/quality gates; guidelines for acceptable continuous training without reward models
- Assumptions/dependencies: regulator acceptance; sector-specific risk analyses; harmonization with existing model risk management practices
- Industrial incident analysis assistants (energy, manufacturing)
- Sector: energy, manufacturing, utilities
- Tools/products/workflows: ingest operator logs and incident narratives; extract preventative and corrective experiential items; consolidate to improve guidance for shift crews and reduce downtime
- Assumptions/dependencies: sufficient textual feedback quality; handling of rare events; alignment with safety standards and human oversight
- Personalized productivity assistants with per-user experience consolidation
- Sector: consumer productivity
- Tools/products/workflows: on-device experience capture (email drafts, calendar flows, preferred styles); extract preferences and shortcuts; consolidate into lightweight personal models that reduce tokens and clicks
- Assumptions/dependencies: consent and privacy; fairness (avoid amplifying biases); cost-effective periodic consolidation; cross-device synchronization
- Cross-model experience transfer with on-policy consistency controls
- Sector: model tooling vendors
- Tools/products/workflows: mechanisms to assess when experiential knowledge from stronger models is transferable; automated checks for on-policy consistency to avoid mismatched strategies in smaller models
- Assumptions/dependencies: reliable metrics for transferability and mismatch detection; tooling to adapt experiential items to target model capacity
In all cases, OEL’s feasibility hinges on several shared assumptions: environments must provide informative textual feedback; organizations must establish logging, privacy, and curation pipelines; periodic server-side consolidation requires compute budgets; and safety/quality gates are needed to prevent drift and catastrophic forgetting. The paper’s demonstrated benefits—online performance gains, token-efficiency improvements, and better OOD preservation via on-policy distillation—make OEL a practical blueprint for continuous, reward-free improvement across a wide range of text-centered applications.
Glossary
- Catastrophic forgetting: A degradation in performance on previously learned tasks when a model is trained on new data. "mitigating catastrophic forgetting compared to off-policy alternatives."
- Context distillation: Training a model to internalize information provided in context so that long prompts are no longer needed at inference time. "Context distillation aims to compress in-context knowledge into model parameters, removing the need to provide lengthy contexts at inference time"
- Context window: The maximum amount of text a model can condition on at once. "the context window becomes increasingly occupied, limiting the model's capacity to absorb and leverage additional knowledge through in-context learning alone."
- Context-conditioned teacher: A teacher model that receives additional context (e.g., knowledge) during training to guide a student. "between the context-free student model and the context-conditioned teacher"
- Context-free student: A student model trained to perform without extra context that the teacher receives. "between the context-free student model and the context-conditioned teacher"
- Experiential knowledge: Summarized, transferable insights extracted from interaction histories that can guide future behavior. "transferable experiential knowledge is extracted and accumulated from interaction trajectories collected on the user side"
- Forward KL divergence: A divergence measure D_KL(p||q) that encourages covering the teacher’s distribution when training a student model. "using forward KL divergence on teacher-generated data."
- IF-Eval: A benchmark for instruction-following evaluation used to assess out-of-distribution performance. "we report prompt-level strict accuracy on IF-Eval"
- In-context learning: The ability of a model to adapt its behavior using information provided in the prompt without updating parameters. "through in-context learning alone."
- In-distribution: Data or tasks drawn from the same distribution as the training set. "The on-policy context distillation used in OEL achieves better in-distribution performance"
- Inference efficiency: How efficiently a model produces answers, often measured by response length or tokens used. "improves not only task accuracy but also inference efficiency"
- Interaction trajectories: Sequences of states, actions, and feedback collected during model-environment interactions. "interaction trajectories collected on the user side"
- Knowledge-conditioned teacher: A teacher model that is provided with extracted knowledge alongside inputs to guide training. "match the knowledge-conditioned output of a teacher"
- Knowledge context: The auxiliary information (e.g., extracted knowledge) supplied in the prompt during training or inference. "without requiring the knowledge context at inference time."
- Mode-covering behavior: A tendency to cover many modes of a distribution (often linked with forward KL), potentially over-generalizing. "these off-policy methods can suffer from mode-covering behavior"
- Mode-seeking behavior: A tendency to focus on high-probability modes of a distribution (often linked with reverse KL). "Minimizing the reverse KL divergence encourages mode-seeking behavior."
- Off-policy context distillation: Distillation where training data are generated by a teacher (with context) rather than by the student’s current policy. "off-policy context distillation uses the teacher model equipped with experiential knowledge in context to generate responses"
- Off-policy training: Learning from data generated by a different policy than the one currently being optimized. "this constitutes off-policy training."
- On-policy consistency: Aligning the source of experience with the same policy/model that is being trained to ensure effective transfer. "on-policy consistency between the knowledge source and the policy model is critical"
- On-policy context distillation: A distillation approach where the student trains on its own rollouts while matching a (knowledge-conditioned) teacher. "consolidated into the model parameters via on-policy context distillation"
- On-policy distillation: Distillation that trains students on their own generated trajectories to reduce train–inference mismatch. "On-policy distillation methods train student models on their own generated trajectories"
- On-policy learning: Learning directly from data generated by the current policy, reducing distribution shift. "Notably, OEL enables on-policy learning using only textual environment feedback"
- Online Experiential Learning (OEL): A framework where a model continuously learns from deployment interactions by extracting and consolidating experience. "We propose Online Experiential Learning (OEL), a framework that enables LLMs to continuously improve from their own deployment experience."
- Out-of-distribution performance: How well a model performs on tasks/data different from those seen during training. "while preserving out-of-distribution performance"
- Partial rollout prefixes: Truncated histories from interaction trajectories used as inputs for single-turn training. "we extract all partial rollout prefixes "
- Policy model: The model whose behavior (policy) generates actions and is optimized during learning. "on-policy consistency between the knowledge source and the policy model is critical"
- Prompt-level strict accuracy: An accuracy metric that requires exact adherence to instructions at the prompt level. "we report prompt-level strict accuracy on IF-Eval"
- Reverse KL divergence: A divergence measure D_KL(q||p) used to make the student match the teacher in a mode-seeking way. "through reverse KL divergence"
- Reward model: A learned model that provides scalar reward signals to guide training. "requiring no reward model or verifiable reward"
- Reward-free: A learning setting that does not rely on scalar reward signals or reward models. "Crucially, this approach is reward-free"
- Single-turn rollouts: Generating only one action/response from a given prefix during training instead of full multi-turn episodes. "the model performs single-turn rollouts"
- Student model: The model being trained to imitate or match a teacher’s behavior or outputs. "train a student model to imitate the outputs of a context-conditioned teacher"
- Supervised fine-tuning (SFT): Post-training with labeled data to adapt a pre-trained model to target tasks. "supervised fine-tuning with human annotations (SFT)"
- Teacher model: A reference model whose outputs guide training of a student, often augmented with additional context. "the teacher model augmented with experiential knowledge"
- TextArena: A platform for text-based environments used for evaluating interactive agents. "both implemented within TextArena"
- Textual environment feedback: Natural language descriptions of outcomes or state changes returned by the environment. "The entire process relies solely on textual environment feedback"
- Thinking model: An LLM variant that generates intermediate reasoning traces before answers. "We use thinking models Qwen3-1.7B, Qwen3-4B, and Qwen3-8B"
- Token efficiency: Achieving goals with fewer generated tokens, indicating more concise reasoning or responses. "enhancing both task accuracy and token efficiency"
- Verifiable reward: A reward signal that can be deterministically computed or checked from the environment. "requiring no reward model or verifiable reward"
Collections
Sign up for free to add this paper to one or more collections.