Grounding World Simulation Models in a Real-World Metropolis
Abstract: What if a world simulation model could render not an imagined environment but a city that actually exists? Prior generative world models synthesize visually plausible yet artificial environments by imagining all content. We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul. SWM anchors autoregressive video generation through retrieval-augmented conditioning on nearby street-view images. However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals. We address these challenges through cross-temporal pairing, a large-scale synthetic dataset enabling diverse camera trajectories, and a view interpolation pipeline that synthesizes coherent training videos from sparse street-view images. We further introduce a Virtual Lookahead Sink to stabilize long-horizon generation by continuously re-grounding each chunk to a retrieved image at a future location. We evaluate SWM against recent video world models across three cities: Seoul, Busan, and Ann Arbor. SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements and text-prompted scenario variations.
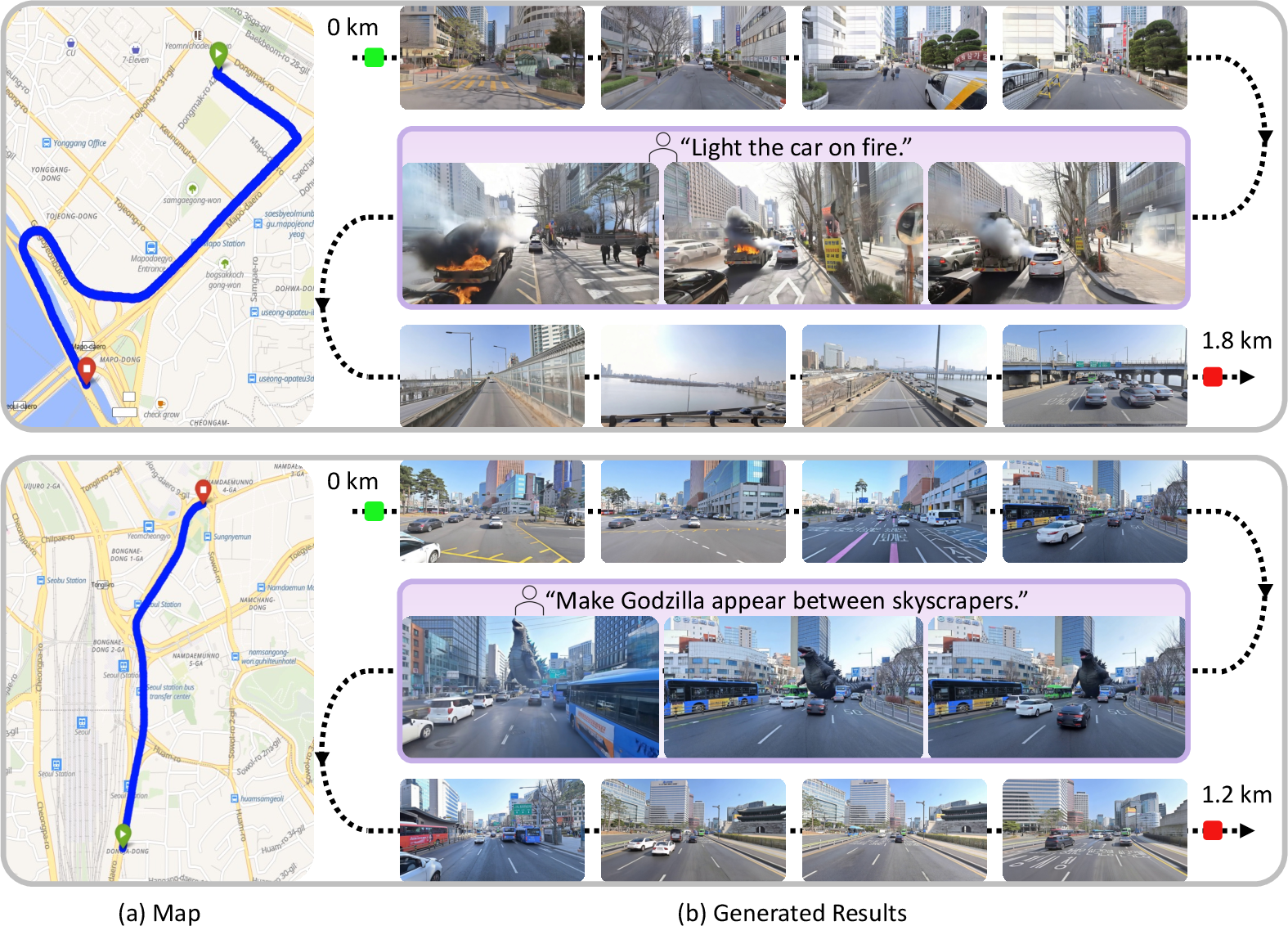






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces Seoul World Model (SWM), a computer system that can “imagine” and generate videos of real city streets—like Seoul—based on actual locations. Instead of inventing a made‑up world, SWM uses real street photos as guides so you can “travel” along a route and see what the city really looks like, while still allowing creative changes like different weather or time of day.
The main questions the researchers asked
- Can a video‑generating AI create long, continuous, realistic videos of a real city (not a fantasy world) as you move along a route on a map?
- Can it stay faithful to the city’s actual layout—roads, buildings, intersections—while still handling moving objects, weather, and user instructions (like “turn left” or “make it sunset”)?
- How can we stop the AI from drifting off course or getting less accurate as the video gets longer?
How the system works (in simple terms)
Think of SWM as a smart tour guide with a camera:
- It knows where you want to go on the map and what kind of camera motion to follow (like driving straight or turning).
- It looks up nearby street‑view photos (like the ones you see in online maps) to understand what the place really looks like.
- It then generates a smooth video, chunk by chunk, that shows what you’d see if you moved along that route.
Here are the key ideas that make this work:
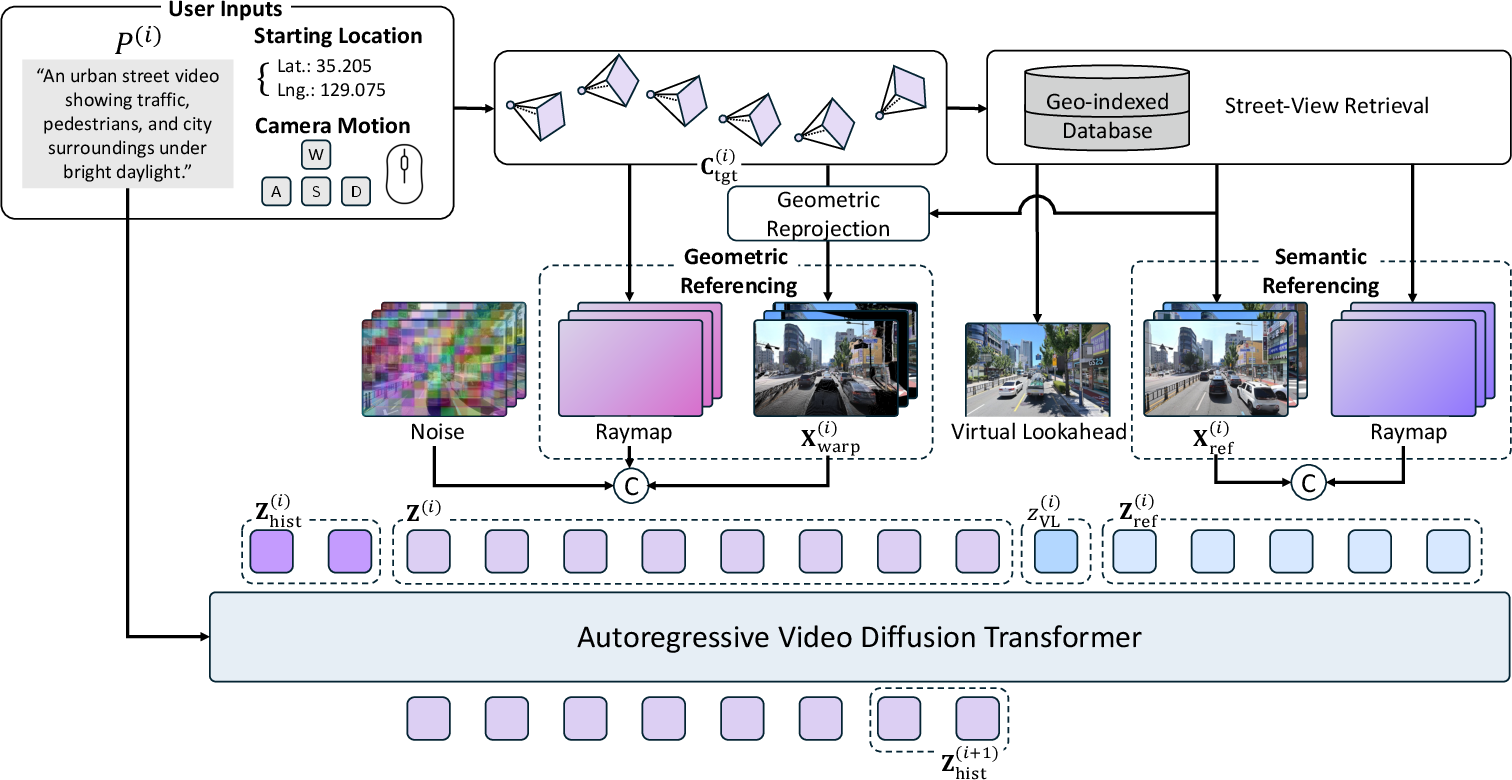
- Retrieval‑augmented generation: Imagine you’re drawing a street as you walk. To draw it correctly, you peek at nearby photos of the street. SWM does the same: it retrieves the closest street‑view images to guide its drawing.
- Handling photos taken at different times (cross‑temporal pairing): Street photos might be old—cars, people, or signs may have changed. SWM trains by pairing references and targets from different times so it learns to rely on permanent things (buildings, roads) and ignore temporary things (cars passing by).
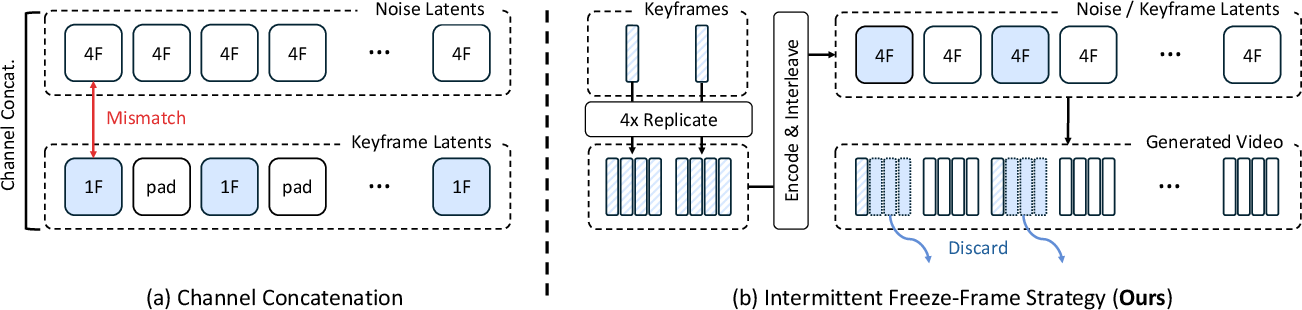
- Filling the gaps between far‑apart photos (view interpolation): Street‑view photos are spaced every few meters, not frame‑by‑frame like a video. SWM uses a “freeze‑frame” trick to turn those distant snapshots into smooth, in‑between frames. Think of it like repeating a key photo briefly, then blending gently to the next, so the motion looks natural.
- Adding variety with a synthetic city (simulated data): Real street‑view mostly looks like car routes. To teach SWM different camera paths (like walking or free‑moving camera shots), the team used a video‑game‑style city simulator (CARLA). This gave SWM lots of safe, varied practice.
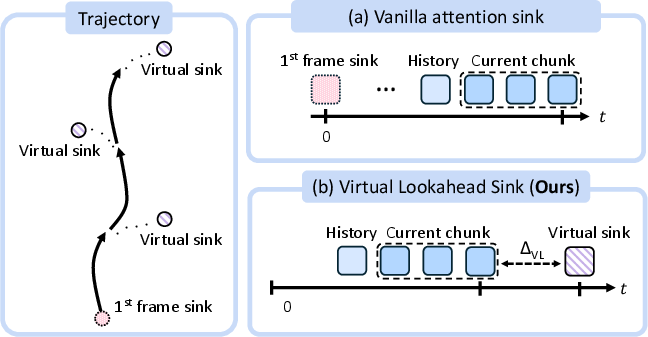
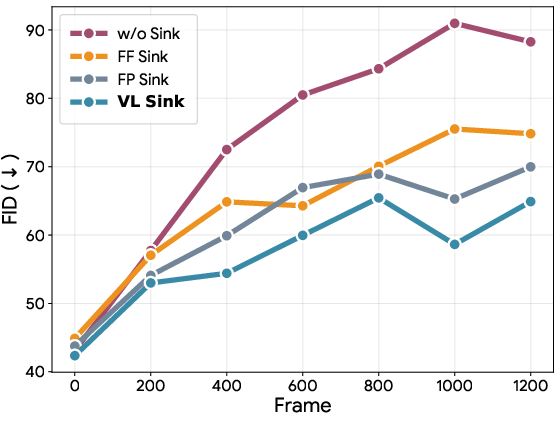
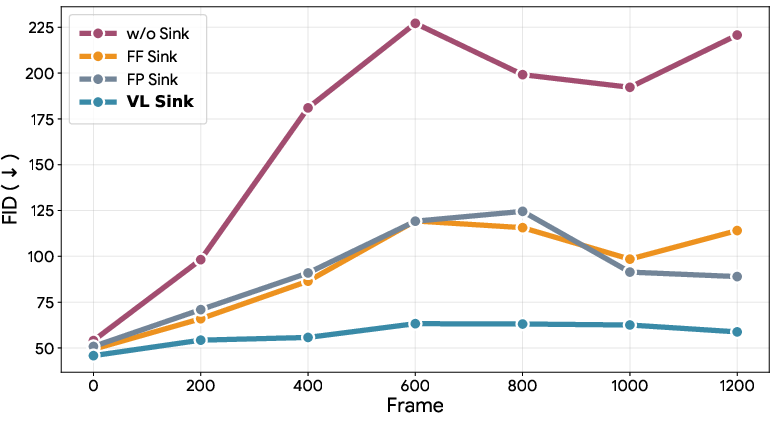
- Staying on course over long distances (Virtual Lookahead Sink): As you move, it’s easy for a model to slowly drift off and forget where it is. Traditional methods keep glancing back at the first frame as an “anchor,” but that becomes less useful as you get farther away. SWM instead looks ahead: it retrieves a photo from a spot a bit further along your route and uses that as a “future anchor”—like a GPS pin ahead that the model aims toward—keeping the video aligned over hundreds of meters.
- Geometry and appearance guidance (two kinds of “references”):
- Geometric referencing: the model lines up a reference photo to the current camera view (like holding a postcard of a building and rotating it to match your perspective) to get the right layout.
- Semantic referencing: it also uses the original photos to keep textures and details (colors, signs, building materials) sharp and realistic.
What they found and why it matters
- SWM can generate long, stable videos that match real city layouts over routes reaching hundreds of meters (and even kilometers in demos).
- It follows intended camera motions better (e.g., turns, straight paths), keeps scenes consistent over time, and preserves the true shape of streets and buildings.
- It works not only in Seoul (its training city) but also generalizes to new cities it wasn’t trained on (Busan and Ann Arbor), showing strong cross‑city transfer.
- It supports creative controls: users can add text prompts like “make it sunset” or “light rain” while keeping the real‑world layout intact.
These results suggest SWM is better at staying grounded in reality than existing video world models that invent everything from scratch. It’s clearer, more stable, and more faithful to real locations.
Why this could be important
- Urban planning and design: visualize how new roads or buildings might look in a familiar, real layout.
- Safer testing for self‑driving and robotics: create realistic, location‑accurate scenarios without taking risks on real roads.
- Education and exploration: virtual field trips through real neighborhoods with different times of day or weather.
- Entertainment and AR/VR: mix real city backdrops with imaginative elements (e.g., festive lights, cinematic weather) while preserving true geography.
In short, Seoul World Model shows that video world simulators don’t have to live in imaginary worlds—they can be grounded in the real places we know, opening up practical and creative ways to see and plan our cities.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of the main uncertainties, omissions, and open research questions identified in the paper that future work could address.
- Geographic and cultural generalization: How well does SWM transfer to cities with very different urban morphology, signage, language, and infrastructure (e.g., dense European old towns, Middle Eastern cities, African cities), or to rural/suburban areas with sparse coverage?
- Reliance on street‑view availability: What are the failure modes in regions with limited, outdated, or no street‑view imagery (e.g., newly built roads, restricted areas, tunnels, underpasses, multi‑level interchanges)?
- Temporal mismatch and recency: How does the model behave when references are months/years out of date (construction, road closures, seasonal changes)? Can recency-aware retrieval or time-aware conditioning mitigate inconsistencies?
- Robustness to weather/season/time-of-day domain shifts: The model supports prompt-driven condition changes, but there is no systematic evaluation of robustness to large photometric shifts between references and desired outputs (e.g., day-to-night, summer-to-winter). How can one decouple geometry from appearance style at scale?
- Depth/pose estimation accuracy: The pipeline relies on monocular depth and pose from Depth Anything V3 with GPS scale alignment. What is the sensitivity to depth/pose errors, and would multi-view SfM/MVS or LiDAR-derived priors measurably improve geometric referencing and reduce splatting artifacts?
- Camera intrinsics and calibration: Panoramas are rendered into pinhole views with assumed intrinsics; how do unknown/variable intrinsics, lens distortion, and panorama stitching errors affect warping and downstream generation fidelity?
- Retrieval noise and GPS inaccuracies: Nearest-neighbor retrieval by GPS and simple coverage filters may be brittle under GPS drift or map-matching errors. Would visual-place recognition (e.g., NetVLAD/DELF variants) or learned geo-visual retrieval reduce mis-anchors?
- Reference fusion strategy: Geometric referencing uses only the single nearest reference per frame to avoid artifacts, while semantic referencing aggregates K references. What are principled multi-reference fusion methods (e.g., learned weighting, visibility reasoning, confidence-aware warping) that improve coverage without increasing artifacts?
- Lookahead sink sensitivity and conflicts: The Virtual Lookahead Sink relies on a retrieved future frame irrespective of text-driven style. How do conflicting prompts (e.g., “snowstorm” while sink shows summer) impact stability and controllability? What is the effect of the temporal offset hyperparameter and its schedule on long-horizon drift?
- Prompt editing over time: The system’s behavior under mid-trajectory prompt changes (e.g., new weather, time-of-day, or semantics) is not characterized. How to balance real-world grounding and prompt responsiveness without destabilizing geometry?
- Dynamic object modeling and control: Cross-temporal pairing encourages ignoring transients in references, but the paper does not show controllable generation of traffic agents and pedestrians. How can agent behaviors be modeled and controlled (e.g., via actions, traffic priors, or separate layers) while preserving geometric grounding?
- Interactive, multi-agent scenarios: The model focuses on camera-conditioned video. How to extend to interactive world simulation with controllable agents and physics that remain consistent with the real city layout?
- Memory and mapping beyond retrieval: SWM does not maintain a persistent 3D map or long-term scene memory; it relies on per-chunk retrieval. Can integrating online mapping (e.g., implicit radiance fields, Gaussians) improve revisit consistency, loop closures, and off-trajectory movements?
- Off-road and vertical navigation: While CARLA data adds non-driving trajectories, it remains unclear how the model behaves for free-camera paths not covered by street views (parks, alleys, elevated walkways, multi-level structures). What retrieval/conditioning is needed for vertical or unusual camera paths?
- Evaluation breadth and rigor: Only two held-out cities (30 sequences each) are used for benchmarking. Larger, more diverse benchmarks and user studies are needed to quantify spatial faithfulness, prompt adherence, and perceived realism across broader conditions.
- Metrics for spatial faithfulness: FID/FVD and masked PSNR/LPIPS may not fully capture geographic correctness. Can map-aligned metrics (e.g., 2D/3D landmark consistency, building footprint IoU, route adherence) provide more direct measures of spatial fidelity?
- Camera-following error estimation: The paper does not detail how rotation/translation errors are computed from generated videos (e.g., pose re-estimation vs. proxy flow). Clearer methodology and ablations on errors due to pose recovery would strengthen claims.
- Interpolation pipeline side effects: The intermittent freeze-frame strategy matches the VAE’s temporal compression but may bias motion statistics. What artifacts or motion smoothness biases does this introduce, and are there alternative latent-aligned interpolation schemes?
- Resolution and scalability: The paper does not explore scaling to higher resolutions, longer sequences, or real-time constraints under heavy retrieval/conditioning. What are the compute/memory trade-offs and caching strategies for city-scale deployment?
- Failure case analysis: There is limited qualitative/quantitative analysis of typical failures (e.g., ghosting from warping errors, texture bleeding, sink-induced style reversion, retrieval gaps, occlusions). A taxonomy would help target future improvements.
- Domain shift from training data: SWM is trained predominantly on Seoul images (and CARLA/Waymo for diversity). How much does training city bias affect color palettes, signage, and structural priors when applied elsewhere, and can domain adaptation alleviate this?
- Legal/ethical and privacy considerations: While de-identification is mentioned, the paper does not discuss licensing constraints of using proprietary map imagery for training/generation, or risks of re-identifying blurred content and misuse (e.g., disaster simulations in real neighborhoods).
- Data and code availability: It is unclear whether the street-view dataset, retrieval index, or annotations can be released. Without reproducible data, how can others validate and extend SWM in different locales?
- Integration of GIS priors: Building footprints, road graphs, elevation models, and semantic maps are unused. Can incorporating GIS layers improve geometry, occlusion handling, and route adherence, particularly where imagery is sparse?
- Multimodal controls and disentanglement: Beyond text and camera, the system lacks explicit controls for time-of-day, weather, season, or style that are disentangled from geometry. How to design control knobs with guarantees on preserving spatial layout?
- Robustness to occlusions and view-dependent effects: The forward-splatting approach is sensitive to depth noise and occlusions. Are there learned occlusion reasoning modules or differentiable renderers that reduce artifacts under large baselines?
- Baseline comparison fairness: Many baselines are not designed for real-world grounding. A more controlled comparison to geometry-aware re-rendering (e.g., CityGaussian/NeRF pipelines) and retrieval-augmented video models would clarify where generative vs. reconstruction approaches excel.
- Safety and physical plausibility: Prompted extreme scenarios (e.g., floods) are shown qualitatively but not evaluated for physical plausibility or safety. How to enforce constraints ensuring plausible dynamics and prevent harmful or misleading outputs?
- Uncertainty estimation and confidence cues: Users are not informed when references are sparse or misaligned. How can the system communicate uncertainty, degrade gracefully, or fall back to alternative modes when grounding is weak?
Practical Applications
Overview
The paper introduces Seoul World Model (SWM), a retrieval‑augmented video world model that generates long‑horizon, street‑accurate simulations grounded in real urban environments. Key innovations include:
- Retrieval‑augmented conditioning on nearby street‑view images (geometry and appearance).
- Cross‑temporal pairing to disentangle persistent structure from transient content.
- A view interpolation pipeline (intermittent freeze‑frame) that converts sparse street‑view keyframes into temporally coherent training videos.
- A Virtual Lookahead Sink that stabilizes long‑horizon generation by continuously re‑anchoring each chunk to a retrieved future location.
- Complementary geometric (depth‑aware warping) and semantic (appearance) referencing during generation.
These capabilities enable spatially faithful, temporally consistent city‑scale videos controllable by text prompts and camera trajectories, with demonstrated generalization beyond the training city.
Immediate Applications
Below are near‑term, deployable use cases that leverage SWM’s current performance characteristics.
- Location‑grounded previsualization for media and games
- Sectors: media & entertainment, advertising, game development, software tools
- What it enables: Rapidly storyboard long camera moves along real streets; preview time‑of‑day/weather/season changes via text; plan shoots and gameplay sequences without permits or site visits.
- Potential tools/workflows:
- “Grounded Previs” plug‑ins for Unreal/Blender/DaVinci Resolve/Premiere.
- Location‑based shot planner that generates route‑accurate scouting videos.
- Assumptions & dependencies:
- Rights to use and re‑render street‑view imagery; privacy compliance.
- Sufficient coverage and recency of street‑view data for target areas.
- Compute capacity for long‑horizon video generation.
- Virtual tourism and neighborhood exploration
- Sectors: tourism, consumer mapping, real estate, education
- What it enables: Interactive map‑based “drive/walk the route” experiences with stylized or seasonal variants grounded in real streets.
- Potential tools/workflows:
- Web/mobile “City Explorer” apps; real estate neighborhood previews with time‑of‑day variants.
- Assumptions & dependencies:
- Streaming inference costs and latency; licensing for map/street‑view data.
- Clear communication that content is generative (not necessarily current).
- Urban planning outreach and public communication
- Sectors: municipal planning, civil engineering, public policy
- What it enables: Visual narratives of proposed street changes, pedestrianization, or traffic calming along actual routes to improve public engagement.
- Potential tools/workflows:
- “Planner’s Storyboard” that turns GIS routes into grounded videos with overlaid design annotations.
- Assumptions & dependencies:
- Not a CAD/engineering‑accurate simulator; visual communication aid only.
- Up‑to‑date street‑view for credibility; policy teams must add disclaimers.
- Navigation and mapping UX prototyping
- Sectors: mapping/navigation software, HMI design
- What it enables: Route preview videos that follow actual geometry; test different instruction styles or camera behaviors before shipping UI changes.
- Potential tools/workflows:
- “Route Preview Generator” API integrated with routing engines.
- Assumptions & dependencies:
- Requires accurate target camera trajectories; care with dynamic content that may not match current traffic.
- Synthetic data augmentation for perception models
- Sectors: autonomous driving, ADAS, computer vision research
- What it enables: Location‑accurate, long‑horizon synthetic videos with rare conditions (fog, snow, events) for perception pre‑training and robustness tests.
- Potential tools/workflows:
- “Grounded Scenario Synthesizer” that outputs videos and auto‑captions; optional static‑region masks for training.
- Assumptions & dependencies:
- Domain gap to real video remains; synthetic labels for dynamic agents may be missing or approximate.
- Street‑view interpolation for mapping operations
- Sectors: mapping, geospatial data operations
- What it enables: Fill temporal gaps between sparse street‑view captures with smooth, operator‑friendly previews to speed QA and labeling.
- Potential tools/workflows:
- “StreetView Interpolator” for internal map QA UIs that renders drive‑throughs from sparse panoramas.
- Assumptions & dependencies:
- Interpolations are generative—not ground truth—so use as assistive visualization only.
- OOH/retail sightline visualization
- Sectors: advertising (out‑of‑home), retail site planning
- What it enables: Simulate drive‑by/walk‑by visibility along real routes to evaluate placements.
- Potential tools/workflows:
- “Sightline Preview” that generates route videos with virtual asset overlays.
- Assumptions & dependencies:
- Dynamic occlusions and traffic vary from reality; treat as an indicative preview.
- Classroom virtual field studies
- Sectors: education (geography, architecture, urban studies)
- What it enables: Explore urban morphology, street sections, and camera geometry in known neighborhoods with controllable scenarios.
- Potential tools/workflows:
- Lightweight notebooks and lesson packs using pre‑generated videos; campus GIS integrations.
- Assumptions & dependencies:
- Clear pedagogy on what is real vs. synthesized; rights for educational redistribution.
- Creator tools for localized storytelling
- Sectors: consumer apps, social media
- What it enables: Users generate stylized drives/walks of their own city with text prompts for music videos, vignettes, or explainers.
- Potential tools/workflows:
- Mobile “CityStory” app with route pickers and prompt presets.
- Assumptions & dependencies:
- Compute costs for consumer scale; content moderation and privacy safeguards.
Long‑Term Applications
These use cases require further modeling advances (e.g., interactive dynamics, multi‑agent behavior), broader data integration, or infrastructure.
- City‑scale interactive digital twins with live data
- Sectors: smart cities, urban planning, mobility management, energy/telecom
- What it could enable: Real‑location digital twins blending SWM’s grounded visuals with live traffic, IoT, and weather to visualize interventions or incidents at street‑level.
- Potential tools/workflows:
- “Operational Twin Viewer” with APIs to traffic, transit, and sensor feeds; planner consoles for what‑if analysis.
- Assumptions & dependencies:
- Integration with authoritative GIS/3D assets; validated physics and multi‑agent models; governance for public deployment.
- Closed‑loop autonomous driving simulation on real streets
- Sectors: AV/ADAS, robotics
- What it could enable: Action‑conditioned, long‑horizon rollouts on real routes with controllable agents and weather for policy evaluation and RL.
- Potential tools/workflows:
- “Grounded World Model Sim” with action APIs, scenario catalogs, and evaluation harnesses.
- Assumptions & dependencies:
- Stronger action modeling and agent dynamics; calibrated sensor simulation; safety validation; licensing for target regions.
- AR navigation with predictive, scene‑consistent previews
- Sectors: AR/VR, consumer navigation
- What it could enable: On‑device or edge‑streamed next‑turn previews that remain consistent with the real environment and user’s path.
- Potential tools/workflows:
- “Predictive AR Navigator” using SWM’s Virtual Lookahead Sink for stable future anchoring.
- Assumptions & dependencies:
- Low‑latency inference on mobile/edge; constant localization; frequently refreshed street‑view; privacy‑preserving overlays.
- Emergency response training and risk communication
- Sectors: public safety, insurance, climate adaptation
- What it could enable: Location‑specific trainings (floods, fires, mass events) with immersive, multi‑agency drills and community risk education.
- Potential tools/workflows:
- VR training modules with hazard models and scripted multi‑agent behaviors; public portals for scenario communication.
- Assumptions & dependencies:
- Scientific coupling to hazard/impact models; clear disclaimers; community consent and ethical guidelines.
- Sidewalk‑ and campus‑scale robotics (delivery, inspection)
- Sectors: logistics, facilities, utilities
- What it could enable: Policy learning and route planning in real layouts for last‑meter logistics or inspection robots, before deployment.
- Potential tools/workflows:
- “Grounded RL Gym” with sidewalk trajectories and dynamic obstacles.
- Assumptions & dependencies:
- Accurate micro‑geometry and traversability semantics; multi‑agent physics; high‑res, up‑to‑date data.
- Telecom and utility network planning
- Sectors: telecom, energy, infrastructure
- What it could enable: Street‑level visualization of small cell placements, pole attachments, or micro‑mobility infrastructure in realistic contexts.
- Potential tools/workflows:
- “Streetscape Planner” that previews deployments along routes and intersections.
- Assumptions & dependencies:
- Requires precise 3D geometry (e.g., LiDAR/mesh fusion) beyond current monocular depth; regulatory data overlays.
- Real estate and streetscape transformation previews
- Sectors: real estate, architecture, municipal design review
- What it could enable: Neighborhood‑scale visualization of proposed developments, façade changes, or streetscape improvements for stakeholders.
- Potential tools/workflows:
- Integration with BIM/CAD for asset insertion; public review kiosks.
- Assumptions & dependencies:
- CAD‑level accuracy and lighting realism; permissions for showing proposed assets.
- Cultural heritage and temporal reconstructions
- Sectors: cultural heritage, archives, education
- What it could enable: Reconstructions of historical streetscapes by conditioning on archival imagery and text, enabling temporal “walk‑throughs.”
- Potential tools/workflows:
- “Time‑Travel Viewer” blending multi‑temporal references via cross‑temporal pairing.
- Assumptions & dependencies:
- Curated historical datasets; robust domain adaptation.
- City‑scale gaming and mixed‑reality experiences
- Sectors: gaming, location‑based entertainment
- What it could enable: Games that leverage real‑city backdrops with controllable scenarios and long‑horizon camera freedom.
- Potential tools/workflows:
- SDKs for grounded world‑model‑based level generation.
- Assumptions & dependencies:
- Licensing of city imagery; scalability and cost for real‑time rendering.
Cross‑cutting Assumptions and Dependencies
- Data availability and rights: Access to high‑coverage, recent street‑view panoramas; legal/licensing and privacy compliance (faces/plates already blurred in source).
- Geometric accuracy: Depth/pose estimates are monocular and scaled via GPS; some applications need higher‑fidelity 3D (e.g., LiDAR fusion).
- Temporal mismatch: Cross‑temporal pairing reduces reliance on transients, but dynamic objects will not perfectly match reality; communicate uncertainty.
- Compute and latency: Long‑horizon diffusion transformers are compute‑intensive; real‑time or mobile use needs optimization/edge offload.
- Generalization: While SWM generalized to Busan and Ann Arbor in tests, quality may drop with different architecture styles, signage, or camera norms; per‑city fine‑tuning and retrieval quality matter.
- Safety/ethics: For public‑facing or policy uses, maintain clear disclaimers; avoid misuse in surveillance; ensure accessibility and inclusivity in public communications.
By grounding world simulation in real geography and extending stability over hundreds of meters, SWM enables immediate visualization and content workflows today, while laying the foundation for interactive, city‑scale digital twins and closed‑loop simulations in the future.
Glossary
- 3D scene representations: Persistent 3D structures maintained across frames to ensure spatial consistency during generation. "3D scene representations maintained across generation"
- 3D VAE: A variational autoencoder that encodes/decodes videos across spatial and temporal dimensions into a latent space. "via a 3D VAE."
- 6-DoF: Six degrees of freedom describing a camera’s 3D position and orientation. "6-DoF camera poses"
- AdamW: An Adam optimizer variant with decoupled weight decay for more stable training. "We train with AdamW~\cite{loshchilov2017decoupled}"
- attention sink: A fixed set of tokens or a frame kept in attention to stabilize long-range generation. "an attention sink, a fixed global context frame"
- autoregressive generation: Generating sequences in chunks conditioned on previously generated outputs, potentially accumulating errors. "Autoregressive generation accumulates errors across chunks"
- autoregressive video generation: Generating video frames sequentially based on prior frames and context. "anchors autoregressive video generation"
- CARLA: An open-source Unreal Engine-based simulator for urban driving used to synthesize data. "from CARLA~\cite{dosovitskiy2017carla}"
- channel-wise concatenated: Combining feature or latent channels along the channel dimension for conditioning. "channel-wise concatenated with the noisy target latent"
- cross-temporal pairing: Training strategy that pairs references and targets from different times to disentangle static structure from transient content. "We address this with cross-temporal pairing"
- depth-based forward splatting: Reprojecting reference pixels into a target view by forward-projecting 3D points derived from depth. "via depth-based forward splatting"
- depth-based reprojection filtering: Selecting references by reprojecting depth to ensure adequate coverage in the target view. "depth-based reprojection filtering retains only those"
- Diffusion Transformer (DiT): A diffusion model architecture using transformer blocks for scalable video generation. "We build on a pretrained Diffusion Transformer (DiT)"
- equi-angular pinhole views: Multiple pinhole camera views spaced uniformly in angle around a panorama. "8 equi-angular pinhole views"
- exposure bias: Error introduced when models are trained with ground-truth inputs but tested with their own predictions. "suffer from exposure bias"
- FID: Fréchet Inception Distance; a metric for visual quality comparing distribution of generated and real images. "Visual and temporal quality is measured with FID"
- First-Frame attention sink: An attention sink that uses the first generated frame as a persistent global anchor. "with a conventional First-Frame (FF) attention sink"
- First-Position Sink: Using a retrieved image at the first temporal position as a global anchor instead of the initial frame. "with a First-Position (FP) Sink"
- forcing-based distillation: Training with strategies like teacher forcing to align model predictions under supervised conditions. "world models trained with forcing-based distillation"
- FVD: Fréchet Video Distance; a metric for temporal fidelity and visual quality in generated videos. "and FVD"
- geo-indexed database: A database of images indexed by geographic coordinates for location-aware retrieval. "retrieved from a geo-indexed database"
- geometric referencing: Conditioning by reprojecting reference images into target views to provide spatial layout cues. "Geometric referencing supports camera alignment"
- joint video-3D prediction: Generating both video and 3D information together to maintain geometric consistency. "through joint video-3D prediction"
- KV cache: Key-value cache storing past attention states to accelerate autoregressive transformer generation. "in KV cache"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric measuring similarity of image patches. "LPIPS~\cite{lpips}"
- masked PSNR: Peak Signal-to-Noise Ratio computed only on masked (e.g., static) regions to assess structural fidelity. "with masked PSNR"
- metric-scale depth maps: Depth estimates aligned to real-world metric scale for accurate geometric reasoning. "with metric-scale depth maps"
- nearest-neighbor search: Retrieving items closest in a feature or coordinate space, here along the target trajectory. "nearest-neighbor search identifies candidate street-view locations"
- novel view synthesis: Rendering images from new camera viewpoints based on inferred 3D scene structure. "In novel view synthesis"
- ODE initialization: Initializing self-forcing or sampling via an ordinary-differential-equation-based deterministic process. "we first perform ODE initialization"
- persistent global anchors: Long-lived tokens or frames kept across generation to preserve long-range consistency. "persistent global anchors such as attention sinks"
- pinhole view: A camera model rendering a perspective image without lens distortion. "rendered into a pinhole view:"
- Plücker ray embeddings: Encoding camera rays using Plücker coordinates for geometry-aware conditioning. "via Pl\"ucker ray embeddings"
- point clouds: Sets of 3D points representing scene geometry, often used for consistent novel view rendering. "render point clouds from predicted depth"
- Retrieval-augmented conditioning: Conditioning generation on retrieved external references to ground outputs in real data. "through retrieval-augmented conditioning"
- Retrieval-augmented generation: Generating content while conditioning on retrieved references to guide structure and appearance. "SWM performs retrieval-augmented generation"
- RoPE (Rotary Position Embedding): A sinusoidal positional encoding scheme that rotates query/key vectors to encode relative positions. "RoPE~\cite{su2024roformer} temporal position embedding"
- SAM3: A segmentation model used here to isolate moving objects for masked metrics. "by applying SAM3~\cite{sam3}"
- Self-Forcing: A training/generation regime where the model conditions on its own past outputs rather than ground truth. "For the Self-Forcing (SF) variant"
- streaming formulations: Generating long videos chunk-by-chunk with limited context for scalability. "autoregressive and streaming formulations"
- Teacher Forcing: Training strategy where ground-truth previous outputs are fed during generation steps. "Teacher Forcing~\cite{Williams1989ALA}"
- temporal compression: Reducing temporal resolution by aggregating frames, as done by the video VAE encoder. "the 3D VAE's temporal compression"
- temporal misalignment: Mismatch in time between references and targets causing inconsistencies in dynamic content. "Temporal misalignment."
- VBench: A comprehensive benchmark suite for evaluating video generative models, including image quality. "Image Quality from VBench"
- Virtual Lookahead Sink: A dynamically updated future-frame anchor retrieved from nearby locations to stabilize long-horizon generation. "We further introduce a Virtual Lookahead Sink"
- view interpolation: Synthesizing intermediate frames between sparse views to create temporally coherent video. "a view interpolation pipeline"
Collections
Sign up for free to add this paper to one or more collections.

