Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data
Abstract: Human athletes demonstrate versatile and highly-dynamic tennis skills to successfully conduct competitive rallies with a high-speed tennis ball. However, reproducing such behaviors on humanoid robots is difficult, partially due to the lack of perfect humanoid action data or human kinematic motion data in tennis scenarios as reference. In this work, we propose LATENT, a system that Learns Athletic humanoid TEnnis skills from imperfect human motioN daTa. The imperfect human motion data consist only of motion fragments that capture the primitive skills used when playing tennis rather than precise and complete human-tennis motion sequences from real-world tennis matches, thereby significantly reducing the difficulty of data collection. Our key insight is that, despite being imperfect, such quasi-realistic data still provide priors about human primitive skills in tennis scenarios. With further correction and composition, we learn a humanoid policy that can consistently strike incoming balls under a wide range of conditions and return them to target locations, while preserving natural motion styles. We also propose a series of designs for robust sim-to-real transfer and deploy our policy on the Unitree G1 humanoid robot. Our method achieves surprising results in the real world and can stably sustain multi-shot rallies with human players. Project page: https://zzk273.github.io/LATENT/

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Paper in a nutshell
This paper shows how to teach a human‑shaped robot to play tennis—fast, smooth, and reliably—without needing perfect recordings of real tennis matches. The system is called LATENT. It learns basic tennis “building blocks” (like steps and swings) from short, imperfect clips of people moving, then smartly combines and slightly fixes them so the robot can chase a ball and hit it back to a target. The team trained the robot in simulation and then got it working on a real humanoid robot (Unitree G1), which can rally with human players.
What the researchers wanted to find out
Here are the simple questions they asked:
- Can a robot learn athletic tennis skills using only short, imperfect human motion clips, instead of full match data?
- How can the robot correct parts of the motion that are usually messy or hard to capture—especially the wrist and racket swing?
- How can the robot combine basic moves (steps, turns, swings) into longer, useful actions that return the ball accurately?
- Will skills learned in a simulator still work in the real world, where physics and sensors are a bit different?
How they did it (in plain language)
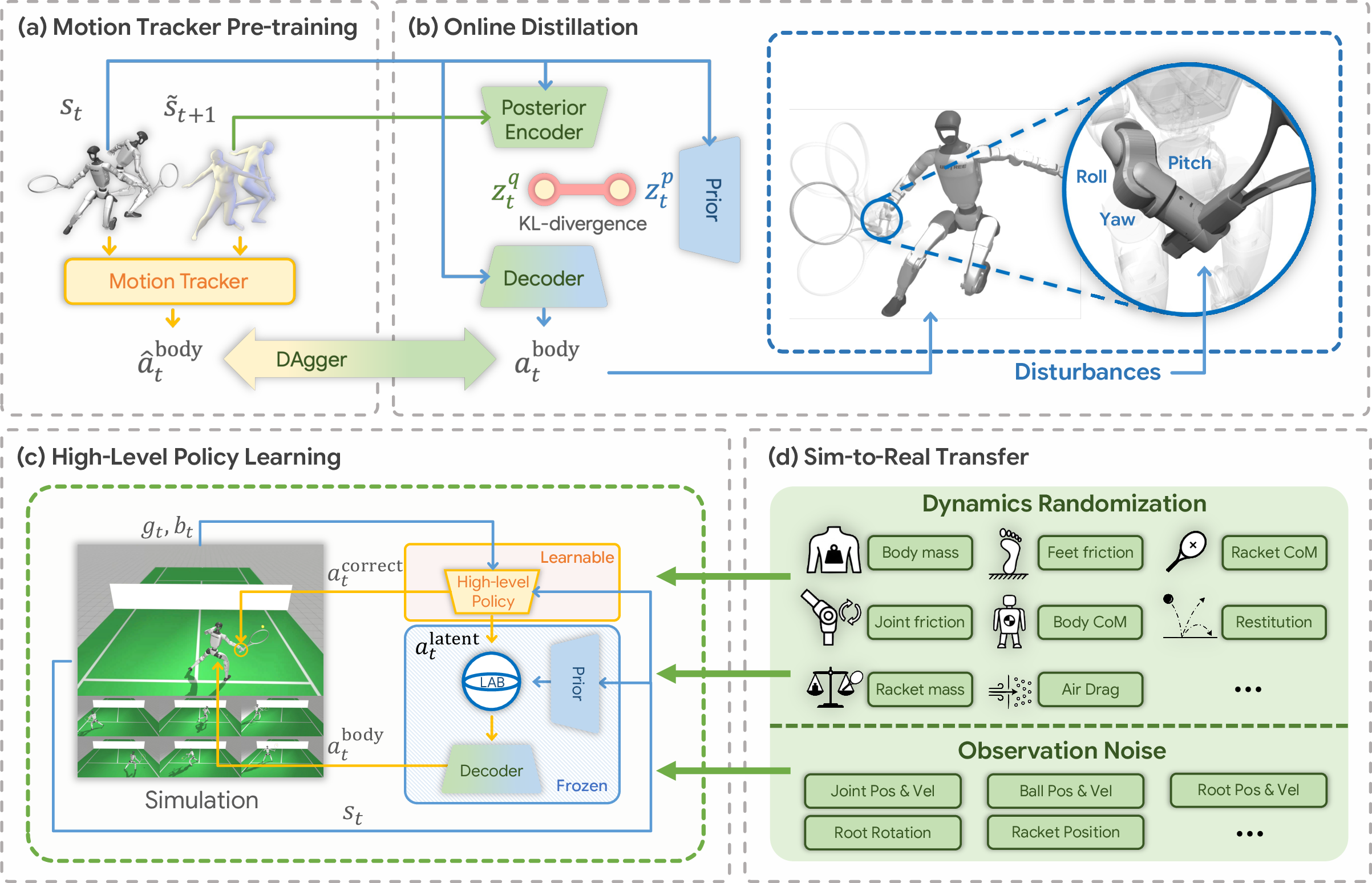
Think of their method as three big steps: gather simple moves, build a “playbook,” and train a planner.
- Data collection: Instead of filming full tennis matches (which is hard), they recorded five amateur players doing short “primitive” skills in a small area (about 3 × 5 meters): forehands, backhands, side shuffles, crossover steps, and so on. These clips are imperfect—especially wrist motions—but they’re much easier to collect. They then “retargeted” (translated) these human motions to the robot’s joints.
- From clips to a “playbook” of moves (latent action space):
- Teacher–student training (online distillation): The tracker (teacher) shows how to act; the student learns a compressed version, like studying the essentials for quick recall.
- Variational bottleneck (simple idea): They squeeze the information so only the most useful parts of a move are kept, making the “playbook” small but expressive.
- State‑aware priors: The system also learns what kinds of moves are typical for each situation (for example, sprinting vs. swinging), so it knows what “normal” looks like in each state.
- A planner that picks and fixes moves in real time:
- Chooses items from the playbook to chase and hit the ball.
- Adds precise wrist corrections (directly controlling the racket hand) because wrist motions in the data are imprecise. This hybrid control keeps the legs and body stable while the planner fine‑tunes the swing.
- Learns through trial and error (reinforcement learning): The planner tries things in simulation and gets rewards for good returns (like points in a video game), learning to chain moves smoothly and hit targets.
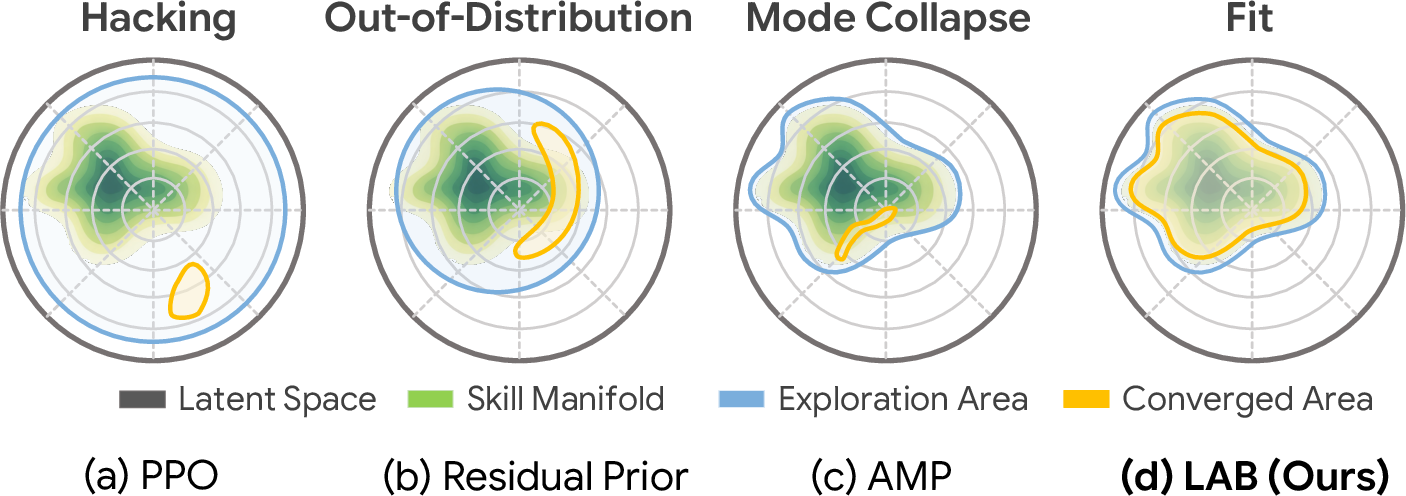
- Guardrails to keep motions natural (Latent Action Barrier): Without limits, the planner might pick weird combinations that technically work but look jerky. The “Latent Action Barrier” acts like guardrails, keeping choices close to the kinds of actions humans would do in each situation. It’s an adaptive “bubble” around normal actions—tight where precision matters, looser where variety is okay—so the robot stays smooth and stable.
- Making it work in real life (sim‑to‑real):
- Dynamics randomization: Randomly changing things like friction, mass, ball bounciness, and air drag in the simulator, so the robot learns to handle many conditions (like practicing in different “weathers”).
- Observation noise and delay: Adding sensor noise, dropped frames, and delays during training, then using a short sliding window to estimate the ball’s speed more reliably.
- Real setup: A Unitree G1 robot with a 3D‑printed racket mount. An optical system tracks the robot and ball positions to provide accurate real‑time information.
What they found and why it matters
- In simulation, LATENT beat several strong baselines on:
- Success rate (more returned balls land near the target),
- Accuracy (smaller landing error),
- Smoothness (less jittery motions),
- Hardware safety (lower joint torques).
- Two parts were critical:
- Wrist correction: Without it, success dropped a lot because the wrist swing is key to clean hits.
- Latent Action Barrier: Without guardrails, the planner made jittery, unnatural sequences, hurting both looks and performance.
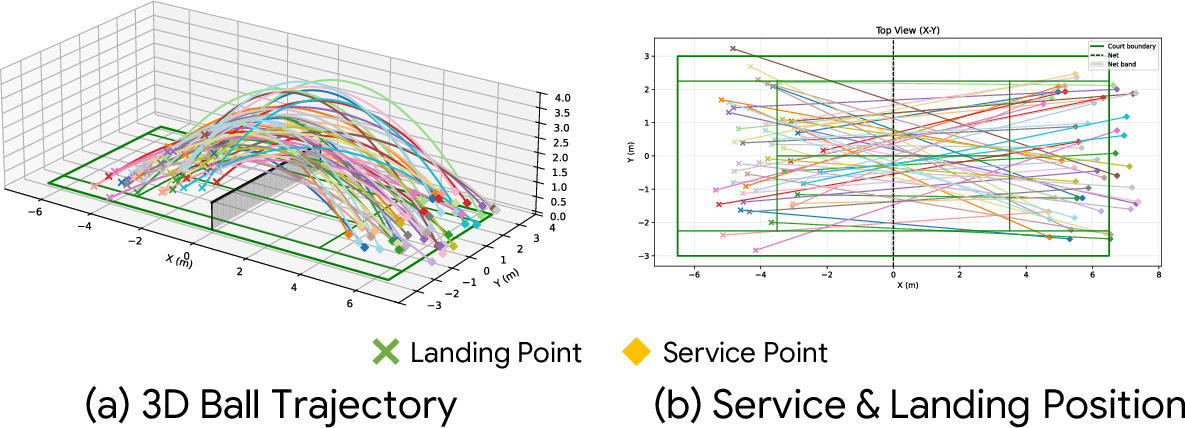
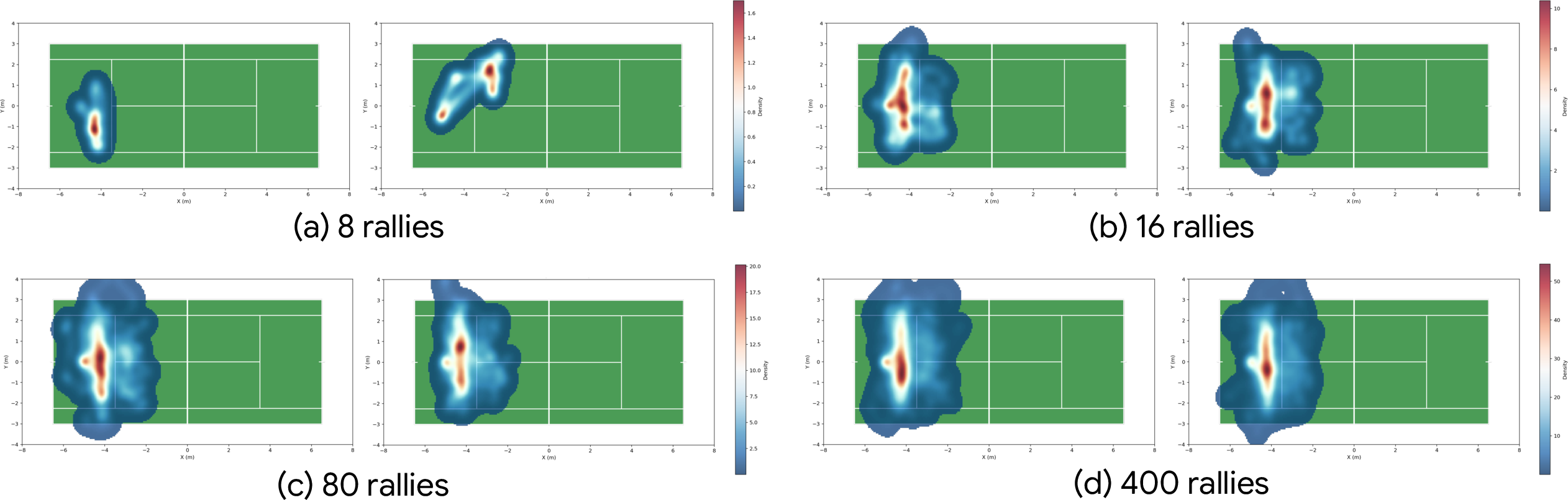
- In the real world, the robot:
- Returned multiple balls in a row,
- Used different strokes across different court areas,
- Handled fast balls (over 15 m/s),
- Performed much better when both dynamics randomization and observation noise were used during training.
Why this matters: It shows robots can learn impressive, athletic skills from easy‑to‑collect, imperfect data. You don’t need perfect full‑match motion capture. With the right “playbook + planner + guardrails” recipe, a humanoid can move naturally, react quickly, and hit accurately.
What this could lead to
- Practical training: Sports‑style robot skills become more reachable because collecting short, basic motion clips is simple and cheap.
- Beyond tennis: The same idea—learn from imperfect snippets, then correct and compose them—could help robots in soccer, parkour, basketball, or other dynamic tasks.
- Next steps:
- Replace the motion‑capture system with onboard cameras, so the robot “sees” on its own.
- Train multi‑agent strategies for full, competitive matches, aiming for human‑level tactics and decision‑making.
In short, LATENT is a smart way to teach robots athletic skills: start with rough human examples, build a compact playbook, let a planner pick and fix moves with guardrails, and practice under lots of varied conditions so it works for real.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed as concrete directions future researchers could act on:
- Data coverage and quality:
- Quantify how the limited, 5-hour dataset of amateur players and a small mocap volume affects skill coverage (e.g., explosive sprints, recovery steps, deep backcourt runs) and generalization; evaluate performance as a function of data volume, skill diversity, and player expertise.
- Assess whether critical primitives are underrepresented (e.g., serves, volleys, overheads, approach shots, split steps, recovery footwork) and add targeted data collection for these.
- Study cross-embodiment retargeting artifacts beyond the right wrist (e.g., elbow/shoulder coupling), and the impact of retargeting errors on learned latent spaces and downstream control.
- Wrist and ball–racket interaction modeling:
- Replace the “ignore-and-correct” right wrist approach with physically grounded wrist/forearm modeling and/or force/IMU sensing on the racket to learn contact-aware corrections, measuring gains in landing accuracy and stability.
- Incorporate and evaluate ball spin and Magnus effects in simulation (and sensing in real), moving beyond simple air-drag and restitution; measure robustness to topspin, slice, and sidespin.
- Model racket-string compliance and dwell time (e.g., via spring-damper contact models) and test whether contact realism improves control predictability and landing accuracy.
- Latent action space design and usage:
- Analyze sensitivity to latent dimensionality, conditional prior capacity, and the latent action barrier scale λ; provide guidelines/auto-tuning for balancing exploration vs. motion naturalness.
- Investigate whether the latent action barrier restricts discovery of novel compositions or high-agility motions; compare with state-dependent adaptive barriers or schedule-based relaxation.
- Evaluate interpretability and coverage of the learned latent space (e.g., clustering by primitives, mode collapse, posterior collapse) and its effect on downstream task performance.
- Policy architecture and memory:
- Examine whether a memoryless high-level policy limits rally consistency (timing, anticipation, recovery); test recurrent or transformer policies for long-horizon control and predictive timing.
- Quantify the contribution of anticipatory control (e.g., predicting ball bounce/strike time) vs. reactive control, and whether explicit strike-time prediction modules improve reliability.
- Task formulation and realism:
- Move beyond scripted, single-agent “return to target” episodes (eight balls, 2 s spacing) to multi-agent settings that include opponent strategy, variable timing, and tactical shot selection.
- Add serves, volleys at net, and quick change-of-direction rallies; report success under higher ball speeds (20–30 m/s), shorter reaction times, and tighter net-clearance margins.
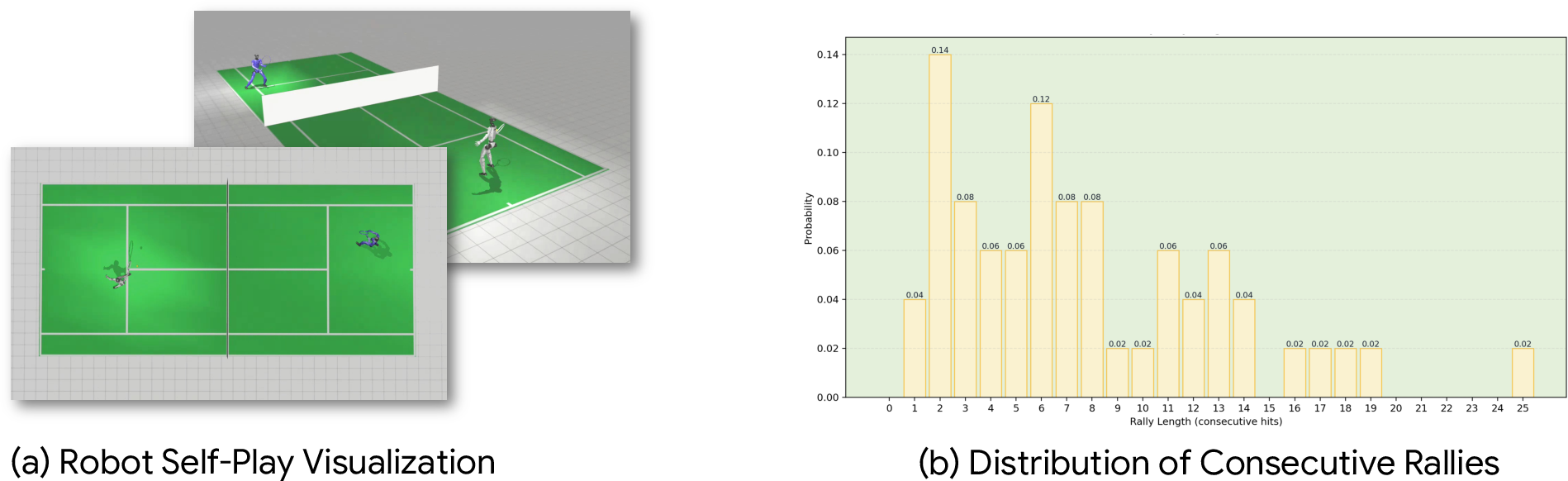
- Track and report rally-length distributions, time-to-recover, and success under “pressure” conditions (e.g., consecutive fast balls) to reflect competitive match dynamics.
- Sim-to-real transfer and robustness:
- Replace hand-tuned domain randomization ranges with data-driven identification (or online adaptation) of court friction, restitution, and aerodynamic parameters; quantify gains over pure randomization.
- Evaluate robustness across different rackets (mass/CoM), ball types/pressure levels, court surfaces (hard/clay/grass), net heights/tensions, and environmental conditions (wind).
- Study failure modes under rare events (ball skids, net cords, mis-tracks) and design recovery behaviors; measure performance drops and recovery times.
- Sensing and state estimation:
- Remove dependence on optical motion capture for deployment by integrating onboard perception (e.g., stereo/RGBD + high-speed ball tracking, radar) and quantify the sim-to-real degradation.
- Replace heuristic observation noise models with empirically measured noise/latency distributions from the deployed sensor stack; compare uniform-noise modeling to learned noise models.
- Analyze end-to-end latency budgets (sensing → estimation → policy → actuation) and their contribution to miss rates; test latency-aware policies and predictive state estimation.
- Control and hardware considerations:
- Report controller frequency limits and investigate whether higher-frequency wrist/arm controllers or time-critical sub-controllers improve contact timing and landing accuracy.
- Study energy/torque/thermal profiles and hardware wear under prolonged high-intensity rallies; propose safety envelopes and adaptive torque constraints.
- Quantify self-collision and joint-limit events in the wild and refine penalty terms or add constraint handling that guarantees feasibility.
- Evaluation breadth and statistical power:
- Increase real-world trial counts beyond 20 rallies and report confidence intervals; stratify results by ball speed, spin, launch angle, and starting robot pose to enable reproducibility.
- Provide explicit distributions of ball speeds and landing errors in real-world tests; clarify whether “peak velocities > 15 m/s” were achieved during evaluation.
- Generalization and portability:
- Test transfer to other humanoid platforms with different mass distributions and joint limits; evaluate how much retraining vs. fine-tuning is required.
- Assess how easily new primitives can be added (few-shot augmentation) and whether the latent/action correction setup scales without destabilizing previously learned skills.
- Reward design and objectives:
- Examine sensitivity to reward weights (especially many regularization terms) and whether learned rewards or curriculum learning can reduce hand-tuning.
- Add explicit objectives for style preservation and human-likeness (e.g., motion similarity metrics) rather than relying only on smoothness/torque proxies.
- Data and reproducibility:
- Clarify availability of the collected motion fragments; if not released, provide synthetic or anonymized datasets and detailed retargeting scripts to improve reproducibility.
- Release full training/evaluation protocols (ball-launch distributions, court setup, sensor specs, latency measurements) to enable fair comparisons.
- Safety and human–robot interaction:
- Analyze human safety during close-proximity rallies (near-net exchanges, mis-hits); define safety zones, emergency stops, and behavior under prediction failures.
- Explore interaction-aware policies that adapt shot power and placement based on human position and safety constraints.
These gaps point to concrete next steps in data collection, modeling of contact and aerodynamics, latent space/prior design, sensing and latency handling, task realism, robustness testing, evaluation methodology, and safe human–robot sports interaction.
Practical Applications
Immediate Applications
The following use cases can be deployed now with the paper’s current methods and hardware assumptions (e.g., Unitree G1-class humanoids, optical motion capture for state estimation, and the provided training pipeline).
- Humanoid tennis practice partner in controlled training facilities
- Sector: Sports robotics, Sports training
- Tools/products/workflows: G1-based “robot sparring partner” using LATENT; facility workflow: collect primitive strokes in a 3×5 m mocap area → train latent space with LAB → deploy with motion-capture tracking and ball launcher; scheduler for forehand/backhand drills and target zones
- Assumptions/dependencies: Optical motion capture for both robot and ball; safety barriers and supervision; compatible humanoid with sufficient torque and 50 Hz control; indoor court with controlled lighting; initial compute and sim setup (8 GPUs) for training
- Sports equipment R&D and quality testing under high-speed impacts
- Sector: Sporting goods, Test & measurement
- Tools/products/workflows: Robotic striking test rig driven by LATENT to reproduce repeatable, human-like contact dynamics on rackets, strings, and balls; automated test plans (speed, angle, spin)
- Assumptions/dependencies: Controlled lab setting; safety enclosures; calibrated ball launcher and tracking; periodic re-training for new rackets/balls
- Robotics SDK for learning from imperfect demonstrations
- Sector: Software/Robotics platforms
- Tools/products/workflows: LATENT-based “imperfect demo to latent controller” SDK featuring (i) correctable latent action spaces, (ii) latent action barrier (LAB), (iii) online distillation (DAgger + conditional VAE prior), and (iv) sim-to-real recipe (randomization + observation noise); packaged for MuJoCo JAX/PPO
- Assumptions/dependencies: Access to primitive-skill fragments (mocap), physics engine (MuJoCo), PD-controlled actuators; integration and support for different humanoid kinematics
- Domain-randomization recipe for fast projectile/contact tasks
- Sector: Robotics, Simulation software
- Tools/products/workflows: Pre-tuned dynamics randomization + observation noise modules for high-speed balls (tennis/table tennis/badminton); plug-in for physics-based training pipelines; velocity-averaging observers for noisy ball tracking
- Assumptions/dependencies: Physics engine capable of 2 kHz simulation; validated parameter ranges (drag, restitution, damping); motion capture or high-fidelity tracking during deployment
- Rapid prototyping for other striking sports in labs (table tennis, badminton)
- Sector: Sports robotics, R&D
- Tools/products/workflows: Transfer LATENT pipeline by collecting minimal primitives (serve, forehand/backhand drives, lunges) in a small mocap volume; apply LAB + wrist correction; deploy with lab-grade ball tracking
- Assumptions/dependencies: Sport-specific racket/end-effector attachment; updated physics randomization ranges; new primitive data; safe lab setup
- Physically plausible athletic motion generation for games and animation
- Sector: Media, Gaming, VFX
- Tools/products/workflows: Use the correctable latent action space and LAB as a motion generator to synthesize dynamic athletic sequences from imperfect mocap fragments, with improved physical plausibility compared to kinematic-only pipelines
- Assumptions/dependencies: Offline use (no robot needed); integration into DCC tools/game engines; retargeting tools for digital characters
- Academic benchmark and teaching platform for learning from imperfect data
- Sector: Academia, Education
- Tools/products/workflows: Open-source code + small-footprint primitive-capture protocol (3×5 m) as a teaching lab; coursework on hierarchical control, online distillation, and sim-to-real transfer; reproducible rally tasks in simulation
- Assumptions/dependencies: GPU cluster or cloud credits for training; students/researchers familiar with RL toolchains
- Human–robot co-play safety research testbed
- Sector: Academia, Standards research, Policy pilots
- Tools/products/workflows: Controlled multi-shot rally scenarios to study human-robot interaction safety under high-speed motion; evaluation of net clearance constraints and torque/acceleration limits
- Assumptions/dependencies: Institutional review and safety protocols; monitored environments; well-defined termination criteria in control policy (falls, out-of-bounds)
- Portable primitive-skill capture kits
- Sector: Motion capture vendors, Robotics integrators
- Tools/products/workflows: Commercial 3×5 m mocap kits and SOPs for capturing primitive skills quickly in clubs or labs; retargeting scripts to humanoids
- Assumptions/dependencies: Reliable marker tracking in small spaces; standardized retargeting pipelines (e.g., LocoMuJoCo); data license agreements
Long-Term Applications
The following use cases require further research, scaling, or engineering (e.g., on-board perception, multi-agent strategy, cost/safety maturity).
- Fully autonomous humanoid tennis opponent without external motion capture
- Sector: Sports robotics, Consumer robotics
- Tools/products/workflows: On-board perception stack (multi-camera/radar/LiDAR), real-time ball spin/trajectory estimation, and state estimation integrated with LATENT control; robust outdoor operation on courts
- Assumptions/dependencies: Low-latency, high-accuracy perception; robust lighting/weather handling; stronger actuators and reliable power; advanced safety envelopes and geofencing
- Competitive-level match play with tactics via multi-agent learning
- Sector: Sports robotics, AI research
- Tools/products/workflows: Multi-agent RL on top of LATENT primitives for rally strategy, shot selection, and opponent modeling; curricula for serve/return patterns; tournament-mode behavior
- Assumptions/dependencies: Scalable self-play infrastructure; game-theoretic evaluation; human-safety-certified behaviors
- General-purpose athletic humanoids across multiple sports (soccer goalkeeping, baseball batting, parkour)
- Sector: Robotics (entertainment, training, research)
- Tools/products/workflows: Reuse of the correctable latent action space + LAB to compose new primitive libraries (jumps, dives, sprints, swings) and adapt sim-to-real randomization for new dynamics/aerodynamics
- Assumptions/dependencies: Adequate actuation and robustness for higher-impact motions; domain-specific perception and contact models; expanded primitive datasets
- Home exergaming and training companions
- Sector: Consumer robotics, Fitness
- Tools/products/workflows: Cost-reduced humanoids or simplified end-effectors that mimic rallies (e.g., with foam balls) for safe home workouts and games; adaptive difficulty using latent policy correction
- Assumptions/dependencies: Significant hardware cost reduction; compact, safe play areas; soft equipment; simplified perception; clear liability frameworks
- Rehabilitation and coaching systems with personalized motor learning
- Sector: Healthcare, Education
- Tools/products/workflows: LATENT-driven robot that demonstrates individualized, human-like primitives and adjusts corrections for a patient’s or student’s needs; quantitative feedback on form and timing
- Assumptions/dependencies: Clinical validation and regulatory approvals; therapist-in-the-loop workflows; safe low-speed modes and fail-safes
- Exoskeleton/prosthetic controllers inspired by latent primitives + corrective layers
- Sector: Medical devices, Assistive robotics
- Tools/products/workflows: Controller architectures that encode reusable primitives (e.g., gait, reach) with online corrective components; learning from imperfect patient demonstrations
- Assumptions/dependencies: Hardware integration; real-time safety guarantees; clinical trials and regulatory pathways; adaptation from humanoid joints to human biomechanics
- Standards and regulations for athletic robots in public spaces
- Sector: Policy, Standards bodies, Facility management
- Tools/products/workflows: Net-clearance and impact-velocity limits; shared-space HRI protocols; certification procedures for sports robots operating in clubs or events
- Assumptions/dependencies: Multi-stakeholder consensus (manufacturers, insurers, venues); risk assessment frameworks; incident reporting systems
- Motion primitive library marketplace and interoperability standards
- Sector: Software platforms, Robotics ecosystem
- Tools/products/workflows: Shared repositories of primitive mocap fragments and latent models with standard interfaces for different humanoids; licensing and validation badges
- Assumptions/dependencies: IP agreements; cross-robot retargeting standards; benchmarking and quality metrics
- Live entertainment and broadcasting with athletic humanoids
- Sector: Media/Entertainment, Theme parks
- Tools/products/workflows: Show routines featuring dynamic strikes and rallies; reenactment of historic plays; audience-safe choreography based on LAB-constrained motions
- Assumptions/dependencies: High reliability and safety margins; operator oversight; contingency shutdowns; robust perception in stage lighting
- Advanced sim-to-real methodologies for fast aerodynamics and contacts
- Sector: Robotics R&D, Simulation software
- Tools/products/workflows: Beyond randomization—hybrid identification + uncertainty modeling for spin, drag, and complex contact; generalized to drones intercepting objects or high-speed inspection
- Assumptions/dependencies: New sensing for ground-truth aerodynamic parameters; scalable identification pipelines; tight integration with dynamics engines
Notes on cross-cutting feasibility factors
- Hardware: Requires a capable humanoid (e.g., Unitree G1 or similar), accurate PD control, and robust wrist/end-effector attachments for striking tasks.
- Sensing: Current deployment relies on optical motion capture for robot and ball; migrating to on-board perception (cameras, IMUs, radar) is an active dependency for broader deployment.
- Training compute: Replicating results needs GPU resources and engineering expertise in RL/simulation.
- Safety: High-speed interactions mandate physical barriers, speed limits, and HRI protocols; regulatory/insurance considerations apply for public-facing use.
- Data: Minimal but targeted primitive-skill capture is key; sector-specific primitives must be collected and retargeted carefully.
- Transferability: Domain randomization ranges must be tuned per environment and sport; additional system identification may be needed for extreme conditions (e.g., outdoor wind).
Glossary
- Adversarial training: A learning setup where a policy is trained alongside a discriminator to match expert-like behaviors or distributions. "incorporates human motion prior through adversarial training."
- Air-drag coefficient: A parameter that scales aerodynamic drag forces on a moving object. "the air-drag coefficient "
- Armature: An inertia-like parameter on joints used in physics engines that affects acceleration and torque response. "we introduce randomization in friction, armature, mass, and center of mass."
- Center of mass (CoM): The point representing the average position of mass in a body; critical for balance and dynamics. "we introduce randomization in friction, armature, mass, and center of mass."
- Conditional variational information bottleneck: A representation learning approach that constrains information through a latent variable conditioned on inputs to promote compact, task-relevant features. "an encoder-decoder framework with a conditional variational information bottleneck"
- DAgger: An imitation learning algorithm (Dataset Aggregation) that iteratively aggregates expert labels over learner-induced states. "is the supervision loss of DAgger~\cite{ross2011reduction}, an online distillation method."
- Degrees of freedom (DoFs): The number of independent ways a robot can move (e.g., joint angles). "Due to the high degrees of freedom (DoFs) of humanoid robots,"
- Dynamics randomization: Randomizing physical parameters during simulation to improve robustness and transfer to real-world dynamics. "we introduce dynamics randomization of the humanoid and the tennis ball"
- Embodiment gap: The mismatch between the morphology and capabilities of humans and robots that complicates motion transfer. "cross-embodiment gap"
- Finite differencing: A numerical method to estimate derivatives (e.g., velocity from position) by discrete differences over time. "compute its velocity via finite differencing."
- Hierarchical humanoid control: A control architecture with multiple layers (e.g., high-level planner and low-level controller) for complex behaviors. "hierarchical humanoid control with latent action spaces"
- Imitation learning: Learning policies by mimicking expert demonstrations rather than relying solely on trial-and-error. "for direct imitation learning,"
- KL-divergence: A measure of divergence between probability distributions, often used as a regularizer in variational models. "The KL-divergence loss:"
- Latent action barrier (LAB): A constraint that limits latent action exploration around a prior, scaled by uncertainty, to preserve naturalness. "within a Latent Action Barrier around the prior's mean"
- Latent action space: A compact, learned space of action codes representing reusable primitive skills. "learning a latent action space that encodes reusable primitive skills"
- Learnable conditional prior: A state-dependent prior distribution over latent variables parameterized by a neural network. "we utilize a learnable conditional prior"
- Mahalanobis distance: A distance metric that accounts for covariance, enabling scale-aware constraints in latent spaces. "we design the barrier based on the Mahalanobis distance rather than the Euclidean distance"
- Monocular videos: Videos captured from a single camera view, used here for motion extraction. "extract human motion data from monocular videos"
- Motion retargeting: Adapting motion captured from one body (human) to another (humanoid) with different kinematics. "human-to-humanoid retargeting"
- MuJoCo JAX: A JAX-accelerated version of the MuJoCo physics engine for high-speed differentiable simulation. "MuJoCo JAX"
- Observation noise: Noise injected into sensed observations to model real-world estimation errors. "observation noise applied to both the robot and the tennis ball."
- Online distillation: Training a student policy to imitate a teacher during rollouts, aggregating data from the student’s state distribution. "via online distillation"
- Optical motion capture: A system of cameras and reflective markers used to record precise 3D human motion. "within an optical motion capture system."
- Posterior variational encoder: A network that outputs the posterior distribution over latent codes conditioned on inputs. "a posterior variational encoder"
- Projected gravity: The gravity vector expressed in the robot’s local/body frame, used as part of state input. "projected gravity"
- Proportional–derivative (PD) controller: A feedback controller that computes torques from proportional and derivative terms of error. "fed into a PD controller to compute actuator torques."
- Proprioception: Internal sensing of the robot’s own body state (e.g., joint positions and velocities). "humanoid proprioception state"
- Residual action space: Representing actions as residuals around a baseline (e.g., prior mean) to guide exploration. "can be formed as a residual action space"
- Residual force (on the root): Extra forces applied to a robot’s base/root to compensate for modeling or control errors. "residual force on the root"
- Sim-to-real gap: Discrepancies between simulated and real-world dynamics that hinder transfer. "sim-to-real gap of the overall system."
- Sim-to-real transfer: Deploying a policy learned in simulation on real hardware. "sim-to-real transfer"
- Skill embeddings: Learned latent representations of primitive skills for reuse in downstream tasks. "learn reusable adversarially trained skill embeddings"
- Tangential damping: Damping applied along the tangential direction during contact (e.g., ball-ground), affecting sliding behavior. "Ball-ground tangential damping"
- VAE-style latent action space: A latent action representation learned using a variational autoencoder approach. "VAE-style latent action space"
Collections
Sign up for free to add this paper to one or more collections.

