- The paper presents a unified framework that hierarchically parses multimodal data into structured, traceable knowledge, enabling robust logical reasoning.
- It leverages a progressive three-layer parsing scheme integrating holistic detection, fine-grained recognition, and multi-level interpretation.
- Experimental results on OmniParsingBench demonstrate significant improvements in accuracy and reasoning across images, documents, audio, and video.
Logics-Parsing-Omni: A Unified Framework for Fine-Grained Multimodal Parsing
Introduction
Logics-Parsing-Omni ("Logics-Parsing-Omni Technical Report" (2603.09677)) introduces a comprehensive multimodal parsing system addressing the long-standing challenge of unifying fine-grained perception and high-level semantic cognition across documents, images, and audio-visual data. The core innovation lies in a principled hierarchical framework—Omni Parsing—that enforces strictly structured, locatable, and traceable transformation of unstructured multimodal signals into machine-actionable knowledge. The paper systematizes three progressive parsing layers (L1 holistic detection, L2 fine-grained recognition, L3 multi-level interpreting) and instantiates this architecture in the Logics-Parsing-Omni MLLM. Substantial improvements are demonstrated across diverse benchmarks, notably OmniParsingBench, validating the efficacy of joint pixel/signal-level accuracy and logical reasoning.
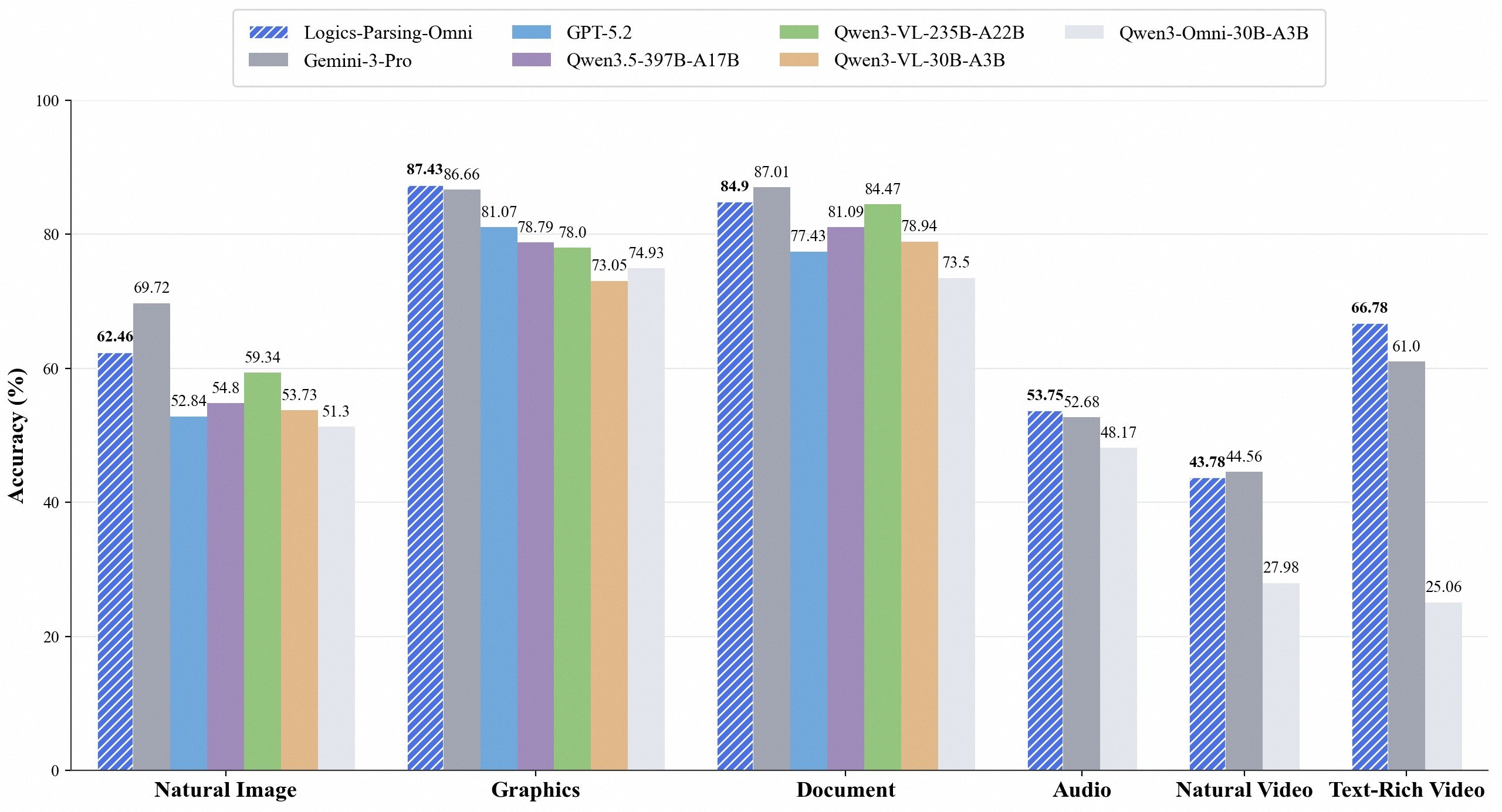
Figure 1: OmniParsingBench performance of Logics-Parsing-Omni across natural images, graphics, documents, audio, and video.
Unified Taxonomy and Framework
The Omni Parsing framework introduces a taxonomy and training methodology that decomposes multimodal parsing into three hierarchical levels:
- L1—Holistic Detection: Spatio-temporal grounding and coarse classification for precise localization.
- L2—Fine-grained Recognition: Structured entity parsing including symbolization (OCR/ASR), attribute extraction, and precise knowledge association.
- L3—Multi-level Interpreting: Logical reasoning, constructing evidence-based semantic chains from local parsed units to global coherent descriptions.
This progressive scheme bridges perception and cognition, integrating spatial-temporal grounding with domain-conditioned reasoning. A standard JSON output schema spans all levels.
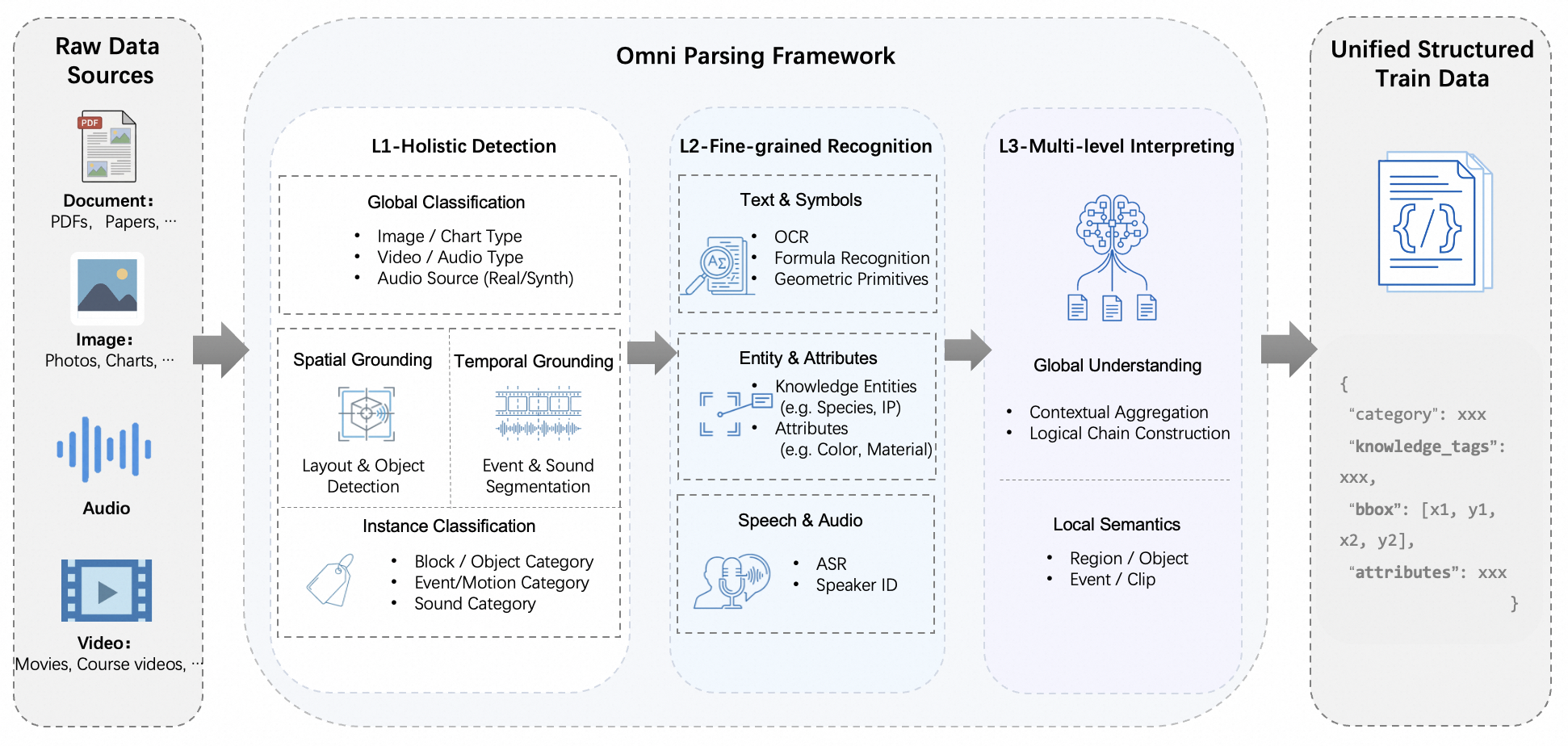
Figure 2: The Omni Parsing Framework stages, transforming raw multi-modal data into unified, structured knowledge with three levels of semantic enrichment.
The evidence anchoring mechanism strictly aligns high-level semantic output with grounded, low-level perceptual data, achieving a strict compositionality not present in monolithic approaches. This design enables robust logical induction and reliable verification for rigorous downstream tasks.
Multimodal Dataset Construction
Extensive, high-quality data curation underpins model success. The four core modalities—Document, Image, Audio, Video—are uniformly structured and annotated for progressive parsing:
- Document: Normalized page-level layout parsing enriched with logical recovery for dense diagrams and embedded elements.
- Image: Single-image and multi-image (difference analysis) parsing, with composite data for knowledge-aware elements, including authoritative entity linking.
- Graphics: Complex chart and geometric figure parsing with reverse-engineering to explicit symbolic structures (e.g., HTML tables, Mermaid diagrams) and topological reasoning.
- Audio: Speaker-attributed transcription combined with dense non-speech acoustic event detection, producing high-resolution aligned semantic chunks.
- Video: Exhaustive annotation of temporal segments, object/actor/action states, camera motion, and multi-modal temporally aligned narratives. Special emphasis is placed on camera-aware natural video and text-rich educational video.
The corpus explicitly balances atomic capabilities (broad coverage, 16M samples) and high-precision, instruction-rich supervision for deep reasoning (5M samples).
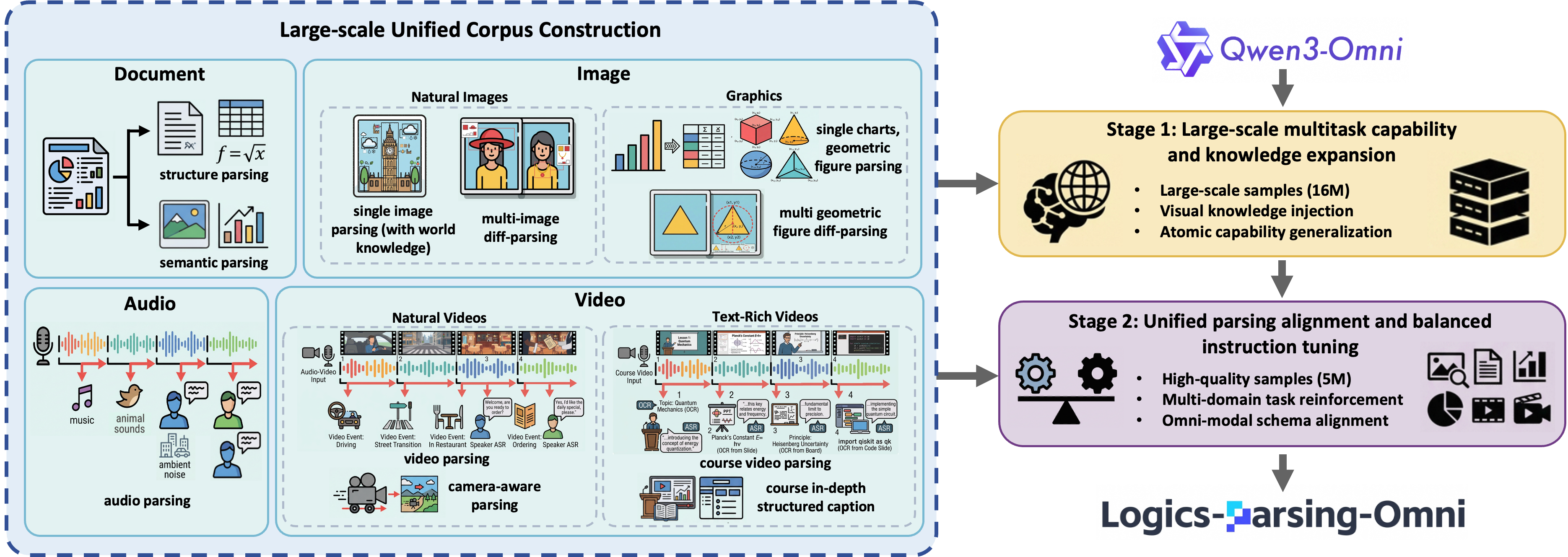
Figure 3: Construction of the unified multi-modal corpus and the two-stage progressive training pipeline.
Training Paradigm
Logics-Parsing-Omni is initialized from Qwen3-Omni-30B-A3B and trained via a two-stage protocol:
- Panoramic Cognitive Foundation (Scale-first SFT): Exposes the model to diverse, large-scale multi-source labeled data to learn atomic structural fidelity, world knowledge associations, and pure pattern recognition.
- Unified Parsing Alignment (Dense Instruction SFT): Applies balanced, high-density, instruction-focused supervision, enforcing strict adherence to structured schemas and instruction following, correcting for the bias induced by uneven data scale.
All model components—LLM, vision and audio encoders—are updated end-to-end; long-context (up to 56k tokens), multimodal sequence packing, and task-optimized data partitioning ensure robust generalization without empirical mode collapse.
Benchmarking and Experimental Analysis
OmniParsingBench is proposed as a rigorous, granular, multi-domain evaluation suite aligning precisely with the three-level parsing taxonomy.
- Natural Images: Evaluated for localization accuracy, semantic fidelity, and hallucination resistance (CaptionQA protocol). Logics-Parsing-Omni outperforms all open-weight baselines (Overall: 62.46, Cognition: 74.38), yielding SOTA on global caption factuality and knowledge mention tasks.
- Graphics (Charts & Geometry): Dominates both perception (Location 86.30) and cognition (Avg. 92.19) metrics via explicit structure anchoring, outperforming Gemini-3-Pro and GPT-5.2 on complex structural reasoning.
- Document: Achieves high robustness on LogicsDocBench and OmniDocBench-v1.5, rivaling the best specialized VLMs and surpassing all open-weight models, demonstrating end-to-end multi-element extraction and reading order recovery.
- Audio: Establishes new SOTA on audio event detection, timestamp alignment, and semantic QA (Overall: 53.75), with robust timestamped JSON outputs and natural event chaining.
- Video: Shows overwhelming advantage in camera motion recognition (Camera acc. 60.69 vs. next-best 33.79), robust low-level audio-visual temporal alignment, and global semantic synthesis (Text-Rich Video: Overall 66.78, Cognition 79.03).

Figure 4: Showcase of the diverse, cross-modal parsing capabilities of Logics-Parsing-Omni.

Figure 5: Qualitative examples of camera-aware video parsing, highlighting structured detection of fine-grained motion events.
Ablations and Data-Driven Methodology Insights
Ablation studies systematically validate that the inclusion of explicit fine-grained perception data is essential—caption-only fine-tuning often hurts logical reasoning, while structured parsing data yields substantial gains (+12.7 on graphics recognition, up to +22.8 on logical reasoning). This substantiates the thesis that granular, locatable perception is prerequisite for trustworthy semantic cognition.
Practical and Theoretical Implications
Logics-Parsing-Omni demonstrates the feasibility and efficacy of integrating structured, evidence-anchored perception with complex multimodal reasoning at scale. The framework is compatible with both closed and open-source LLM backbones and sets a rigorous template for evaluating and improving MLLMs' reliability and transparency in knowledge-intensive tasks. Its approach to evidence alignment and traceable signal grounding directly enables cross-modal RAG, machine reasoning, and robust multi-domain QA.
On the practical side, this work paves the way for trustworthy deployment of MLLMs in enterprise scenarios (e.g., automated document processing, educational content understanding, advanced multimedia search/QA). The standardized output schema and strict grounding also favor transparent regulatory audits and integration into tool-use agents.
Theoretically, the joint treatment of perception and cognition—neither purely bottom-up nor top-down—suggests explicit intermediate representations are critical for scalable, reliable, high-fidelity multimodal reasoning. The clear performance gap between monolithic captioning and structured parsing points to new directions in compositional generalization, knowledge graph induction, and interpretable AI pipelines.
Speculation on Future Directions
- Cross-modal continual learning: Extending the anchoring paradigm to online and lifelong scenarios, adapting to dynamic knowledge distributions.
- Schema generalization: Adapting or extending the output schema for specialized domains, including medical or legal content parsing.
- Enhanced knowledge grounding: Incorporating external retrieval and identifier disambiguation for open-world knowledge entity linking.
- Efficient scaling: Investigating sparse or modular model architectures to improve training/runtime efficiency without sacrificing cross-modal fidelity.
- Formal verification of reasoning chains: Leveraging the pipeline’s explicit grounding to support formal audit and neural-symbolic reasoning.
Conclusion
Logics-Parsing-Omni establishes a rigorous paradigm and delivers a strong open-weight MLLM that unifies fine-grained perception and high-level reasoning across all major modalities. The evidence-anchored progressive parsing approach, highly curated dataset, and robust benchmark suite validate that structured perception is indispensable for logical induction and semantic reliability. This work sets a new reference point for both evaluation and system design in knowledge-intensive multimodal understanding (2603.09677).