- The paper systematically documents 30 agentic AI systems, detailing their technical, safety, and governance attributes.
- It refines agent classification using four key agency characteristics across chat, browser, and enterprise platforms.
- The study highlights significant gaps in safety evaluation and transparency, urging robust, standardized reporting mechanisms.
The 2025 AI Agent Index: Comprehensive Documentation and Analysis of Deployed Agentic AI Systems
Introduction and Context
The 2025 AI Agent Index systematically documents technical and safety features of thirty prominent agentic AI systems in production as of December 2025. The Index’s explicit objective is to provide a reference framework for the empirical state of the agentic AI ecosystem, addressing opacity and inconsistencies in available documentation that hinder research, policy, and governance activities. The investigation foregrounds core questions about the developers of impactful agentic AI, their domains of deployment, development and evaluation resources, and the implementation of safety guardrails.
A significant acceleration in agentic AI research and deployment is quantified, with 2025 seeing a pronounced growth in both the quantity and diversity of systems being released and discussed—evidenced by data on search volume and publication rates.
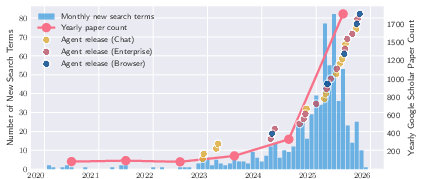
Figure 1: Interest in AI agents, as measured by Google search term volume and the number of academic papers, sharply increased through 2025.
The work builds on the inaugural 2024 Index, refining agent classification and deepening its field coverage, while consciously avoiding the imposition of a new, contentious definition of “agent.” Instead, its inclusion criteria are operationalized via four agency characteristics (autonomy, goal complexity, environmental interaction, generality), real-world impact, and practicality, focusing on highly capable, broadly impactful, and accessible systems.
Agent Selection, Categorization, and Annotation Methodology
Systems are classified into three principal interface modalities: chat applications with agentic tools, browser-based agents, and enterprise workflow automation platforms. Each offers distinct affordances and challenges regarding autonomy levels, user interaction, and external integration, aligning with task and risk profiles.
Selection is strictly criterion-based, ensuring included agents demonstrate at least intermediate autonomy, sustained multi-step planning, capacity for environmental change via APIs or direct actions, as well as cross-task generality. Impact is operationalized by developer market capitalization, public interest (search volume/GitHub stars), or developer prominence in foundational model/public safety initiatives. Only publicly accessible, off-the-shelf, general-purpose agents are indexed.
Human experts lead systematic annotation across six categories (product overview, company/accountability, technical capabilities, autonomy/control, ecosystem interaction, safety/evaluation), resulting in 45 documented fields per system. Annotations are strictly based on publicly accessible materials, direct correspondence with developers, and interface exploration. Consistency and factual accuracy are reinforced by protocolized labeling, cross-validation, LLM-assisted verification, and developer feedback cycles.
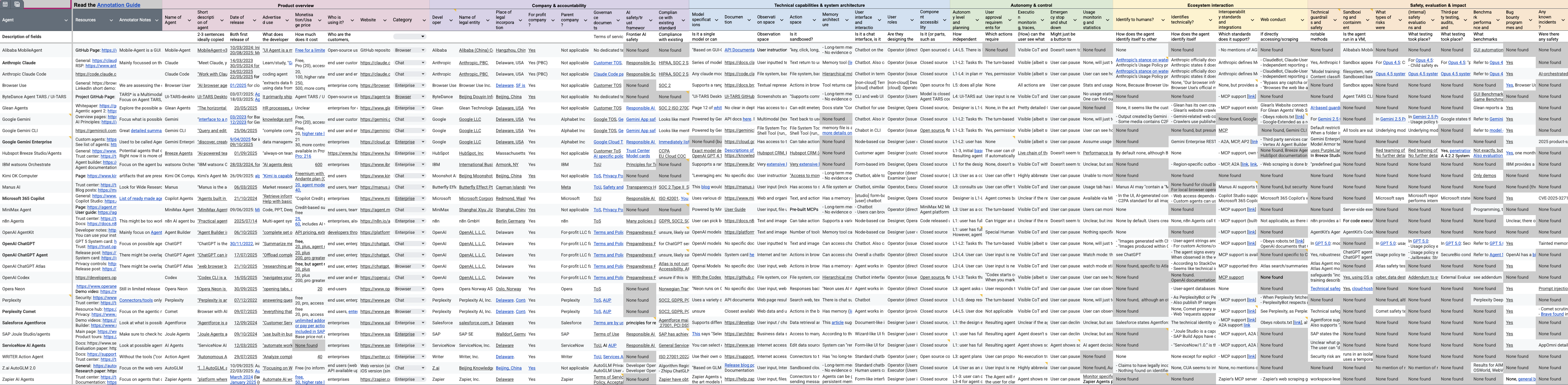
Figure 2: The Index provides detailed annotations for 30 agentic AI products covering a spectrum of technical, governance, and safety fields.
Key Findings and Ecosystem Trends
Product and Developer Landscape
Agent deployment has accelerated, particularly in 2024–2025, with chat interfaces and enterprise automation platforms predominating. Developers are heavily US- and China-centric; incorporation in the US (primarily Delaware) accounts for a majority, concentrated among large incumbents and leading startups.
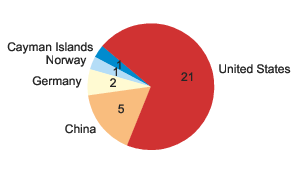
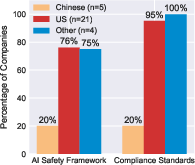
Figure 3: The majority of AI agent companies indexed are incorporated in the US, with significant but smaller representation from China.
Despite increasing product diversity, technical implementation shows consolidation: most agents utilize a small pool of proprietary, closed-source frontier models (primarily the GPT/Claude/Gemini families). Only Chinese providers and foundation model developers themselves operate their own models; model-agnostic, tool-rich platforms are largely the purview of enterprise-oriented offerings.
Autonomy, Transparency, and Control
Autonomy levels vary by agent class: consumer-facing chat agents typically offer L1–L3 autonomy, often with turnwise or gated decision points, whereas browser-based agents demonstrate L4–L5 autonomy, with minimal user intervention possible post-task initiation. Enterprise platforms bifurcate autonomy between human-in-the-loop (agent design) and fully autonomous execution (deployment), complicating static safety analysis.
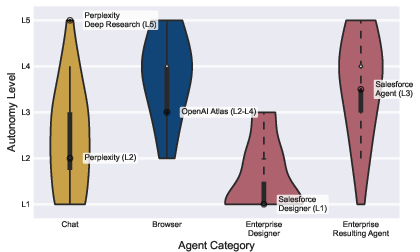
Figure 4: Agent autonomy distributions highlight interface-dependent divergence, with browser-based and enterprise-deployed agents skewing strongly autonomous.
User approval and intervention mechanisms are implemented idiosyncratically—ranging from mandatory confirmations for high-impact actions to fully autonomous workflows triggered via external signals. Execution monitoring and agent action traceability, while present in some systems, vary substantively in granularity and accessibility.
Safety, Evaluation, and Transparency: Gaps and Inconsistencies
A principal finding is the pervasive lack of agent-specific safety, evaluation, and social impact documentation—particularly acute among browser agents and enterprise automation platforms.
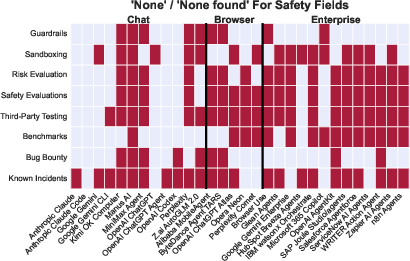
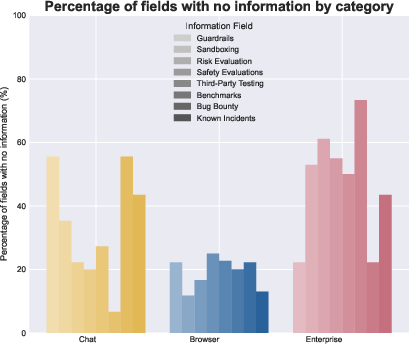
Figure 5: Safety-relevant documentation and transparency are frequently absent, especially concerning real-world agent behavior and evaluation practices.
Only a minority of agents provide system cards, detailed red-teaming results, or agent-specific risk assessments. Technical guardrails (sandboxing, permissioning, containment) when present are documented sparsely, especially for agents instantiated through builder platforms where responsibility is delegated. Benchmark reporting emphasizes capability metrics over holistic risk profiles; third-party testing and red teaming are rare outside of a few major labs.
Incident reporting is similarly uneven. Known security vulnerabilities (notably prompt injection in browser agents) are disclosed in only a few cases, and documentation is typically post hoc and non-systematic.
Ecosystemic and Governance Complexity
Agent ecosystem architecture is highly fragmented. Most agent developers are, in practice, orchestrators of foundation model outputs layered with proprietary or semi-open tool integrations and post-processing logic. This results in distributed control and blurred accountability—making valid, deployment-relevant evaluation of agentic risk challenging.
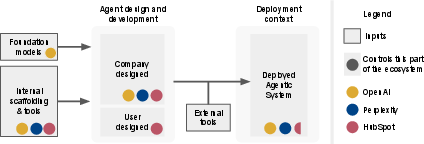
Figure 6: Fragmented control and modular dependencies pose persistent barriers to comprehensive agent evaluation, with no single stakeholder overseeing the full agentic stack.
Interoperability is increasing (e.g., wide MCP support), but identification, provenance signaling, and compliance with web interaction norms remain inconsistent. Browser-based agents often disregard robots.txt, justified by arguments drawing analogies to human-user delegation, but this position is facing increased regulatory and legal scrutiny.
Implications, Challenges, and Directions
The Index’s documentation exposes critical areas of concern for the AI safety and research community:
- Evaluation Validity: Most agent safety evaluation is focused at the model level, not at the agent configuration or deployment context, despite risks and behaviors commonly arising from tool integration, autonomy levels, and user-specified workflows.
- Transparency and Safety Asymmetry: There is a documented pattern of selective reporting, particularly with respect to safety and evaluation—a weaker but analogous trend to “ethics-washing,” where the existence of high-level frameworks substitutes for empirical evidence of risk mitigation or robustness.
- Ecosystemic Bottlenecks: The high degree of model concentration raises issues of platform dependency, single points of failure, and coordination problems in incident response and safety rollback.
- Web Governance Tensions: Browser-agent strategies toward identification and compliance are diverging from established web norms, with litigation signaling increasing contestation around scraping, provenance, and user/agent standing.
These findings have cascading implications for both regulatory and technical approaches to agent oversight. There is an apparent need for improved and standardized reporting at the agent (not only model) level, more robust ecosystem-wide provenance and identification standards (e.g., cryptographic signing), and mechanisms for distributed accountability in complex, multi-layered agent deployments. As agentic capability outpaces the maturation of safety, evaluation, and governance practices, these gaps urgently warrant focused attention.
Conclusion
The 2025 AI Agent Index establishes a baseline for documentation and transparency within the field of agentic AI, revealing clear trends in deployment, architecture, and governance while rigorously highlighting substantial deficiencies in safety disclosure and empirical evaluation. As agentic AI becomes more capable and entrenched in high-impact domains, addressing the transparency, evaluation, and accountability gaps exposed here will be central to both technical and policy progress. Future developments should prioritize richer, deployment-oriented evaluation, robust provenance mechanisms, and coordinated stakeholder governance to manage the complexities of the fragmented agent ecosystem.

