SoftDTW-CUDA-Torch: Memory-Efficient GPU-Accelerated Soft Dynamic Time Warping for PyTorch
Abstract: We present softdtw-cuda-torch, an open-source PyTorch library for computing Soft Dynamic Time Warping (SoftDTW) on GPUs. Our implementation addresses three key limitations of existing GPU implementations of SoftDTW: a hard sequence-length cap of 1024, numerical instability in the backward pass for small smoothing parameters, and excessive GPU memory consumption from materializing pairwise distance tensors. We introduce (1) tiled anti-diagonal kernel execution that removes the sequence-length constraint, (2) a log-space back-ward pass that prevents floating-point overflow, and (3) a fused distance-computation mode that eliminates the O(BN M ) intermediate distance tensor, achieving up to 98% memory reduction compared to prior work. The library supports arbitrary sequence lengths, full PyTorch autograd integration, and Soft-DTW Barycenter computation. Code is available at https://github.com/BGU-CS-VIL/sdtw-cuda-torch.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new, faster, and more memory‑efficient computer library that helps compare and align time‑based data (like sounds, sensor readings, or motion) on a graphics card (GPU). The method it speeds up is called Soft Dynamic Time Warping (SoftDTW). The library is made for PyTorch, a popular tool used to build and train neural networks.
In short: the authors built a GPU tool that makes SoftDTW work on much longer sequences, uses far less memory, and stays stable even in tricky cases—so researchers can train models on real‑world time series more easily.
What questions were the authors trying to answer?
The authors asked how to fix three big problems in the best existing GPU code for SoftDTW:
- How can we remove the hard limit that stopped it from working on sequences longer than 1024 steps?
- How can we stop the training math (the “backward pass”) from breaking and producing NaNs when a “smoothness” knob (called gamma) is set small?
- How can we avoid using huge amounts of GPU memory to store a giant “all‑pairs distances” table?
Their goal was to solve all three problems without breaking how PyTorch expects things to work (so gradients still flow and training “just works”).
A quick, simple background
- Time series: a list of values over time (like a heartbeat signal or a song).
- DTW (Dynamic Time Warping): a classic way to measure how similar two time series are, even if one is “stretched” or “shifted” in time. Think of lining up two songs sung at different speeds.
- SoftDTW: a smooth, differentiable version of DTW. “Differentiable” means you can use it as a loss during neural network training because you can compute gradients.
- GPU: a processor good at doing many small tasks in parallel, great for speeding up math on large arrays.
How did they do it? (Methods explained simply)
To understand their improvements, imagine DTW/SoftDTW as filling a big grid, where each cell compares a moment from sequence A with a moment from sequence B. You fill the grid in a specific order so each cell can use results from its neighbors.
The authors designed three key tricks:
1. Tiled anti-diagonal execution (removes the 1024-step limit)
- The grid can be filled “anti-diagonal” by “anti-diagonal” (think stripes that run from top-right to bottom-left). Cells on the same stripe don’t depend on each other, so you can compute them at the same time.
- Older code tried to handle an entire stripe with one giant group of GPU threads, which hit the limit of 1024 threads.
- Their fix: split long stripes into smaller pieces (“tiles”) and launch several small groups of threads. It’s like breaking a super-long line of people into several shorter lines so all can be served. This removes the length cap entirely, so very long sequences now fit.
2. Log-space backward pass (prevents math overflow)
- During training, the “backward pass” computes how to adjust model weights. Some steps involve exponentials that can blow up to extremely large numbers when the smoothness knob gamma is small.
- Their fix: do the math in “log-space.” Instead of multiplying big numbers directly, they add their logarithms and use a stable “log-sum-exp” trick. It’s like keeping track of how many zeros a number has rather than writing out all the zeros—much safer and no overflows.
3. Fused distance computation (saves huge amounts of memory)
- The old way precomputed and stored a massive 3D table of distances between every pair of time points. That’s convenient but costs tons of memory.
- Their fix: compute distances “on the fly” inside the GPU kernels when needed, using a fast identity for squared distance. This “fused” mode trades some speed for a massive memory drop, often the difference between “out of memory” and “works fine.”
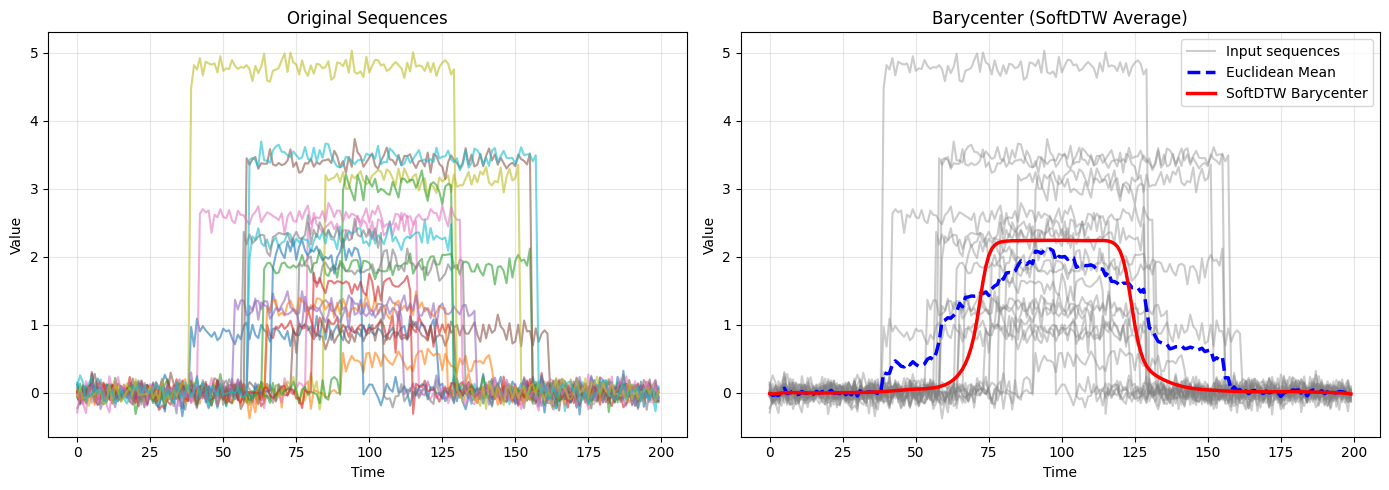
Bonus: SoftDTW barycenter (averaging in DTW space)
- They also include a way to find an “average” time series (a barycenter) that best matches a set of time series under SoftDTW. This is useful for clustering or summarizing many signals.
What did they find? Why it matters
Their benchmarks show:
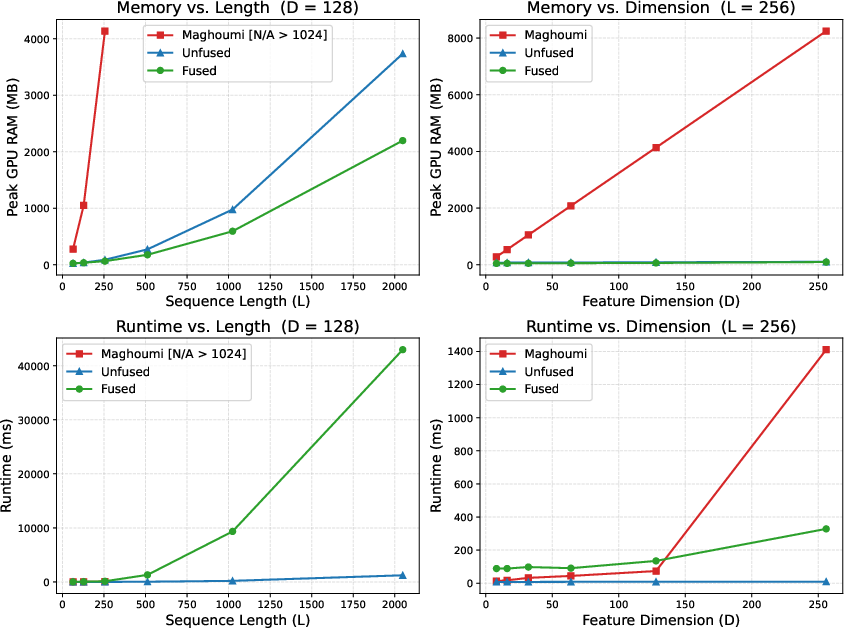
- No more 1024 length limit: their method works on much longer sequences directly on the GPU.
- Stable training at small gamma: the log-space backward pass prevents numerical crashes.
- Huge memory savings: by computing distances on the fly (fused mode), peak GPU memory can drop by up to about 98% compared to the previous implementation.
- Speed vs. memory trade-off:
- Unfused mode (store distances) is faster but uses more memory.
- Fused mode (recompute distances) is slower (about 10–15× in their tests) but saves a lot of memory. This is often worth it when training on long sequences or big batches where memory is the bottleneck.
Why this matters: Many real datasets have long sequences or big batches. Before, people often had to shrink their data or switch to slow CPU code. Now they can keep things on the GPU, scale up, and still train models that use SoftDTW as a loss.
What does this mean for the future?
This work makes SoftDTW much more practical in everyday machine-learning tasks on time series:
- Researchers can train larger models on longer signals without running out of memory.
- SoftDTW becomes a more viable choice as a training loss for tasks like forecasting, alignment, and metric learning.
- The open-source library plugs into PyTorch autograd, so it’s easy to adopt.
- There’s room for even more speed: future improvements could add smarter caching, support for mixed precision (FP16/BF16), and fewer GPU launches for extra efficiency.
Bottom line: the paper turns a useful but limited tool into a robust, scalable one—unlocking better experiments and bigger models for time-series alignment and learning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored, framed to be concrete and actionable for future work.
- Forward-pass numerical stability: The paper stabilizes only the backward pass in log-space; it does not address potential overflow/underflow in the forward softmin. Implement a max-shift log-sum-exp variant for the forward softmin and quantify stability across very small regimes.
- DP-table memory footprint remains : Although the distance tensor is eliminated in fused mode, the DP table still scales with . Investigate rolling anti-diagonal buffers, checkpointing/recompute strategies, or two-pass backward derivations that avoid storing the full while preserving gradient correctness.
- Kernel launch overhead for very long sequences: Tiled execution issues Python-side launches. Prototype persistent kernels, cooperative groups, or CUDA Graphs to process all anti-diagonals within one capture, and measure end-to-end gains on long sequences (e.g., ).
- Fused-kernel optimization: The fused path is 10–15× slower. Explore shared-memory tiling of /, warp-level primitives, vectorized loads, register blocking, and using tensor cores for dot products in Eq. ; provide ablation studies isolating each optimization’s impact.
- Mixed precision support: Implement FP16/BF16/TF32 with AMP, dynamic loss scaling in the log-space backward, and compensated summation where needed. Validate gradient fidelity vs FP32 across , , and , and report speed/memory trade-offs.
- General pointwise costs beyond squared Euclidean: The fused mode assumes Eq. . Add a pluggable cost interface supporting cosine, Mahalanobis, Huber, learned neural metrics, and masked distances, and ensure efficient fused computation and correct autograd for each.
- Band constraints exploitation: While “bandwidth” appears in pseudocode, there is no empirical or implementation detail on Sakoe–Chiba or Itakura bands. Implement band pruning in both forward and log-space backward, quantify speed/memory reductions, and validate accuracy trade-offs.
- Variable-length ragged batching: The library assumes padded batches. Add support for per-pair lengths without padding (e.g., via segment descriptors and dynamic grids), and evaluate occupancy/throughput benefits vs padding.
- Normalized SoftDTW for unequal lengths: The normalized variant currently requires . Design and test normalization that works for (e.g., via continuous-time interpolation or length-aware normalization), and assess effects on training objectives.
- Multi-GPU and distributed scaling: Provide data/model-parallel versions with gradient aggregation, memory partitioning across devices, and performance characterization (scaling efficiency, communication overhead).
- Architecture coverage and portability: Benchmarks target a single GTX 1080. Extend evaluation to Ampere/Ada/Hopper (CUDA 12+), and explore ROCm/AMD support. Report performance portability, occupancy, and memory behavior across architectures.
- Non-square sequence benchmarking: Current results use . Characterize runtime/memory and kernel efficiency for skewed lengths (e.g., or ), and adapt tiling/scheduling accordingly.
- End-to-end training impact: Benchmarks are micro-level. Measure effects within real models and tasks (forecasting, speech, motion) on throughput, memory, and task metrics, comparing fused vs unfused and AMP vs FP32.
- Alignment outputs and path extraction: The gradient matrix is computed but an API for expected alignment matrices or sampled alignment paths is not described. Expose alignment outputs and validate them against DTW as .
- Learning or differentiating w.r.t. : Provide gradients w.r.t. , enable -annealing schedules, and study how influences optimization, stability, and alignment quality; include recommended ranges per task.
- Barycenter scalability and robustness: Analyze convergence properties, sensitivity to , initialization strategies, and robustness to outliers. Add support for unequal-length series, large , and batched barycenter computation; compare against DBA and other baselines.
- Handling missing data and masks: Add masked SoftDTW that ignores or penalizes missing entries, ensure numerical stability in log-space, and maintain fused efficiency with masks.
- PyTorch 2.x integration: The tiled Python loop may hinder torch.compile/TorchScript and CUDA Graph capture. Provide a C++/CUDA extension path that is graph-capture friendly, and quantify performance gains.
- Further memory profiling and allocator behavior: Peak memory reporting does not analyze fragmentation or allocator overhead. Integrate detailed memory profiling (PyTorch CUDA caching allocator, fragmentation metrics) and provide guidance to avoid pathological allocations.
- High-dimensional features: Evaluate performance and memory behavior for very large (e.g., ) and optimize dot-product computation (e.g., via cuBLASLt tiling or tensor cores), including an analysis of arithmetic intensity and bandwidth bounds.
- Formal correctness and gradient checks: Provide rigorous gradient checks and error bounds showing equivalence of log-space and linear-space backward (where numerically feasible), across a wide sweep of sizes, , and costs.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases enabled by the paper’s GPU-accelerated, memory-efficient, and numerically stable SoftDTW for PyTorch, with sector linkages, indicative tools/workflows, and key assumptions.
- Scalable SoftDTW loss for deep time-series learning (forecasting, seq2seq, metric learning)
- Sectors: healthcare (ECG/EEG), energy (load forecasting), finance (price/action series), retail/operations (demand), industrial IoT
- Tools/workflows: drop-in PyTorch loss module leveraging autograd; choose unfused mode for speed or fused mode for tight memory budgets; train larger batches or longer sequences than previously possible
- Assumptions/dependencies: requires CUDA-capable GPU and PyTorch; O(NM) DP complexity remains; fused mode trades speed for memory; modelers must tune γ; runtime acceptable for offline training
- GPU-accelerated DTW/SoftDTW retrieval, clustering, and prototyping
- Sectors: audio/music (cover song detection, melody matching), speech (utterance similarity), IoT logs (pattern retrieval), geospatial/transport (trajectory similarity)
- Tools/workflows: batch SoftDTW distance computation on GPU for indexing/search; SoftDTW-barycenter-based k-means to form prototypes; scalable evaluation pipelines for similarity search
- Assumptions/dependencies: large-scale retrieval remains compute-heavy due to O(NM); for very long sequences, tiled kernels add launch overhead; precomputed embeddings often needed to keep D small
- Video/audio synchronization and temporal alignment at scale
- Sectors: media production (multi-cam sync), sports analytics, surveillance, AR/VR, video understanding
- Tools/workflows: extract frame/audio features (CNNs or spectral features) and align streams with SoftDTW without the 1024-length cap; exploit fused mode to fit long synchronized sequences in memory
- Assumptions/dependencies: feature quality strongly affects alignment; long sequences incur many kernel launches (tiled path); for real-time sync, performance may be insufficient without further optimizations
- Biomedical signal alignment and averaging (template building with SoftDTW barycenter)
- Sectors: healthcare (ECG/EEG/PPG alignment, morphology averaging), wearable analytics
- Tools/workflows: compute SoftDTW barycenters as robust “average” waveforms for reference templates; align patient-specific signals to canonical profiles for QA or anomaly screening
- Assumptions/dependencies: offline/nearline use is preferred; data quality and preprocessing (denoising, normalization) are critical; normalized SoftDTW for unequal lengths may require padding
- Robotics and autonomy: multi-sensor temporal alignment (offline mapping, log analysis)
- Sectors: robotics, autonomous vehicles, UAVs
- Tools/workflows: align IMU–camera–LiDAR logs, event streams, or learned embeddings using SoftDTW on GPUs; use unfused mode for faster batch alignment during mapping or dataset curation
- Assumptions/dependencies: latency constraints limit on-robot online use; offline pipelines are immediately feasible; compute budget and GPU memory determine batch size
- Predictive maintenance and manufacturing QA
- Sectors: manufacturing, process industries
- Tools/workflows: align and compare machine telemetry against failure or fault signatures; cluster cycles with SoftDTW barycenters to create canonical cycle profiles; anomaly scoring by distance to prototype
- Assumptions/dependencies: deployment practical on edge servers or Jetson-class devices with CUDA; fused mode enables longer traces but is slower; real-time scoring may need precomputed templates
- Cost-efficient training and experimentation on commodity GPUs
- Sectors: software/ML platforms, MLOps
- Tools/workflows: run memory-heavy SoftDTW experiments on smaller/cheaper GPUs (e.g., 8–12 GB) using fused distances; integrate with PyTorch Lightning/Hydra training pipelines and schedulers
- Assumptions/dependencies: training time increases with fused mode; practitioners must balance wall-clock vs. memory constraints; cluster schedulers may need updated resource requests
- Academic benchmarking, teaching, and reproducibility
- Sectors: academia, education
- Tools/workflows: fair comparisons on long sequences (no 1024 cap); reproducible labs/tutorials where students integrate a differentiable alignment loss; use barycenters for hands-on clustering demos
- Assumptions/dependencies: adoption in course materials or benchmark suites is straightforward; requires CUDA-enabled infrastructure in labs or cloud credits
- Cloud/SaaS similarity services
- Sectors: software/SaaS, analytics platforms
- Tools/workflows: wrap softdtw-cuda-torch as a microservice to provide time-series alignment/retrieval APIs; auto-scale instances with memory-aware deployment (fused vs. unfused per request)
- Assumptions/dependencies: service-level latency and cost targets dictate mode selection; GPU-backed instances required; request batching strategies impact throughput
Long-Term Applications
The following opportunities need additional research, engineering, or scaling (e.g., persistent kernels, mixed precision, new variants) before broad deployment.
- Low-latency/real-time SoftDTW via persistent kernels or CUDA graphs
- Sectors: robotics (online synchronization), high-frequency trading, streaming analytics, real-time media sync
- Tools/products: persistent-kernel SoftDTW operator; CUDA-graph-captured pipelines for amortized launch overhead; ROS/TensorRT integrations for streaming
- Assumptions/dependencies: kernel redesign to cut per-diagonal launch overhead; careful memory tiling/caching; maintain numerical stability in log-space; benchmarking on embedded GPUs
- Mixed-precision (FP16/BF16) SoftDTW for throughput and memory gains
- Sectors: edge AI (wearables, mobile robotics), cloud training at scale
- Tools/products: tensor-core-optimized kernels; autocast-friendly PyTorch modules; reduced VRAM footprints enabling larger L or B
- Assumptions/dependencies: guard against precision-related instability despite log-space backward; calibration for γ and scaling factors; verify gradient fidelity
- Optimized fused kernels with shared-memory tiling and caching
- Sectors: all compute-sensitive verticals (media, robotics, finance)
- Tools/products: kernels that reuse X/Y tiles across diagonals to shrink the fused/unfused runtime gap; kernel-auto-tuner that selects tile sizes per GPU
- Assumptions/dependencies: nontrivial CUDA engineering and portability across architectures; may interact with autograd memory semantics
- Normalized SoftDTW for unequal sequence lengths (production-ready)
- Sectors: information retrieval, healthcare (variable-length episodes), mobility (variable trip durations)
- Tools/products: robust normalized SoftDTW with padding/interpolation strategies; API that abstracts length handling and edge effects
- Assumptions/dependencies: algorithmic extension and careful benchmarking to avoid bias; evaluate impact of interpolation on downstream tasks
- Large-scale dataset curation and summarization with SoftDTW barycenters
- Sectors: data management, healthcare registries, MLOps (dataset versioning)
- Tools/products: barycenter-based summarizers to produce canonical templates, data deduplication, or cohort representatives; integration with data lineage tools
- Assumptions/dependencies: compute remains O(KNM) for K sequences—needs scaling strategies (mini-batch, approximate DP, multi-GPU)
- Cross-modal alignment training (e.g., audio–video, sensor fusion)
- Sectors: multimodal AI, AR/VR, autonomous systems
- Tools/products: end-to-end differentiable alignment modules combining learned embeddings with SoftDTW loss; curriculum strategies for small γ
- Assumptions/dependencies: high-quality encoders; further runtime/memory optimizations for very long modalities
- Edge deployment on embedded GPUs (Jetson, Orin) for on-device analytics
- Sectors: smart manufacturing, smart homes/cities, mobile health
- Tools/products: lightweight SoftDTW operators using mixed precision and kernel optimizations; offline maintenance scheduling and on-device pattern matching
- Assumptions/dependencies: stringent latency and power budgets; tuned kernels for embedded memory hierarchies; possibly quantization-aware design
- Government/public policy analytics at national scale
- sap amuse on real-time Early Warning Systems: epidemic curves, energy demand, mobility changes
- Laurations: time series alignment for heterogeneous signals across regions to support policy response
- Tools Parsons host i.e., cluster-based Soft sop pipeline with memory-optimized GPU nodes; repeatable notebooks for analysts
- Assumptions/dependencies: access to secure HPC/GPU infrastructure; governance around sensitive data; further optimization to meet throughput/latency targets
Notes on Sector-Specific Tools and Workflows (Cross-Cutting)
- Potential products:
- PyTorch-native SoftDTW Loss + Barycenter package with Lightning callbacks and HuggingFace Hub examples
- A SoftDTW GPU microservice (REST/gRPC) with mode auto-selection (fused vs. unfused) and request batching
- SoftDTW-enabled clustering (k-means with barycenter) for tslearn/sktime adapters
- Common dependencies and feasibility constraints:
- CUDA-enabled GPUs and PyTorch are required
- Fused mode drastically cuts memory but is 10–15× slower than unfused; choose per use case
- O(NM) scaling persists; extreme-length sequences may remain costly without bandwidth constraints or approximations
- Log-space backward removes gradient overflow for small γ but does not fix ill-posed training objectives
- For unequal-length normalization, padding/interpolation or algorithmic extensions are needed for robust deployment
Glossary
- Adam optimizer: A popular stochastic optimization algorithm for training neural networks that adapts learning rates per parameter using estimates of first and second moments. "via Adam optimizer"
- anti-diagonal: The set of cells in a matrix with constant i + j index; in DP for DTW, cells on the same anti-diagonal can be processed in parallel. "Cells on the same anti-diagonal are mutually independent:"
- autograd: Automatic differentiation system (here, PyTorch’s) that records operations to compute gradients via backpropagation. "full PyTorch autograd integration,"
- bandwidth constraint: A restriction that limits DTW alignments to a diagonal band to reduce complexity. "no bandwidth constraint,"
- barycenter: The average (Fréchet mean) of a set of time series under DTW/SoftDTW, found by minimizing aggregate distances. "We additionally provide a gradient-based SoftDTW barycenter"
- batched matrix multiplication: Performing many matrix multiplications in parallel as a single operation to leverage optimized kernels. "computed upfront via batched matrix multiplication"
- BF16: Brain floating point, a 16-bit floating-point format with a larger exponent than FP16, useful for training stability and performance. "FP16 or BF16 support could further reduce memory and improve throughput on modern GPUs with tensor cores."
- CUDA __syncthreads(): A CUDA intrinsic that provides a barrier synchronization among threads in the same block. "using __syncthreads()."
- CUDA-graph: A CUDA feature that captures a sequence of GPU operations as a graph for efficient replay with reduced launch overhead. "A persistent-kernel or CUDA-graph approach could amortize this overhead."
- CUDA thread-block limit: The hardware-imposed maximum number of threads per CUDA block (commonly 1024), which constrains kernel designs. "Maghoumi's implementation is unavailable for (CUDA thread-block limit)"
- diffeomorphic: Referring to smooth, invertible mappings with smooth inverses; used here in temporal alignment models. "Diffeomorphic Temporal Alignment Networks (DTAN)"
- Dynamic Time Warping (DTW): An algorithm measuring similarity of temporal sequences by nonlinearly aligning them to minimize cumulative distance. "Dynamic Time Warping (DTW)~\cite{sakoe1978dynamic} is a classical algorithm"
- FP16: IEEE half-precision (16-bit) floating-point format that reduces memory and can accelerate tensor-core operations. "FP16 or BF16 support could further reduce memory and improve throughput on modern GPUs with tensor cores."
- FP32: IEEE single-precision (32-bit) floating-point format commonly used for training and inference. "The current implementation operates in FP32."
- fused distance computation: Computing distances on-the-fly inside the kernel to avoid storing the full pairwise distance tensor, saving memory at some runtime cost. "a fused distance-computation mode that eliminates the intermediate distance tensor"
- implicit synchronization barrier: Using host-side (CPU) sequencing of kernel launches to enforce ordering across GPU computations without explicit device-wide barriers. "using the host-side sequential ordering of kernel launches as an implicit synchronization barrier"
- Jacobian: The matrix of all first-order partial derivatives of a vector-valued function, used to propagate gradients to inputs. "composed with the distance function's own Jacobian"
- log-space: Performing computations on logarithms of quantities to improve numerical stability and avoid overflow/underflow. "a log-space backward pass that prevents floating-point overflow"
- logsumexp: A numerically stable operation computing log(exp(a)+exp(b)+...), typically implemented by subtracting the maximum before exponentiation. "The numerically stable is"
- max-shift trick: Stabilization technique that subtracts the maximum value before exponentiation in log-domain sums to prevent overflow. "where the max-shift trick keeps values numerically bounded regardless of~."
- normalized SoftDTW variant: A SoftDTW-based loss adjusted by subtracting self-similarities to remove scale effects, often requiring equal-length sequences. "The normalized SoftDTW variant ~\cite{blondel2021differentiable} currently requires ."
- Numba CUDA: A Python JIT compilation framework enabling CUDA kernels to be written in Python and compiled for GPUs. "with PyTorch and Numba CUDA."
- persistent-kernel: A long-running CUDA kernel that processes multiple tasks/steps, reducing kernel launch overhead and improving throughput. "A persistent-kernel or CUDA-graph approach could amortize this overhead."
- Soft-DTW: A differentiable relaxation of DTW that replaces the hard min with a soft minimum controlled by a temperature parameter. "Cuturi and Blondel~\cite{cuturi2017soft} introduced Soft-DTW, a differentiable relaxation"
- soft-minimum: The smooth approximation to the minimum function used in SoftDTW’s recurrence, controlled by a temperature parameter γ. "the soft-minimum is"
- tensor cores: Specialized matrix-multiply units in modern GPUs that accelerate mixed-precision linear algebra. "modern GPUs with tensor cores."
- tiled anti-diagonal kernel execution: Decomposing long anti-diagonals into tiles processed across multiple kernel launches/blocks to remove thread-per-block limits. "tiled anti-diagonal kernel execution that removes the sequence-length constraint,"
Collections
Sign up for free to add this paper to one or more collections.

